Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
理解してほしいVision Transformer / plz-understand-ViT
Search
shun74
June 23, 2022
Programming
810
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
理解してほしいVision Transformer / plz-understand-ViT
Easy to understand explanation form NN to ViT.
shun74
June 23, 2022
More Decks by shun74
See All by shun74
深度推定モデルの自己教師あり学習/self-supervised-depth
shun74
0
530
GPUでステレオマッチング / Stereo-matching with GPU
shun74
0
1.2k
卒業研究の進め方 / How to preceed with the research
shun74
1
600
Barcode Recognition / pharmacode-decoder
shun74
0
1.1k
Vision Transformer講座 / Vision Transformer Presentation
shun74
1
770
ニューラルネットの1bit化 / 1bit-neural-network
shun74
0
1k
Defocus Map Estimation From a Single Image Based on Two-Parameter Defocus Model / two-parameter-defocus-model
shun74
0
410
Other Decks in Programming
See All in Programming
torikago - Ruby::Boxで照らすモジュラモノリスの実行境界
se4weed
1
300
霧の中の代数的エフェクト
funnyycat
1
450
<title><a id="</title>君はこのHTMLをパースできるか"></a></title> #雑LT_study
pizzacat83
0
130
Laravel Boostに学ぶ、AIにPHPを書かせる技術 〜OSSの実装から蒸留するエージェント制御の王道〜
kentaroutakeda
3
620
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
160
型も通る、synthも通る、それでも危ない 〜AIのCDKの権限とコストを機械で検証する〜 / It Passes Type Checks, It Passes Synth Checks, but It’s Still Risky — Automatically Verifying Permissions and Costs in AI’s CDK —
seike460
PRO
1
500
Claude Team Plan導入・ガイド
tk3fftk
0
250
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
200
生成AIで帳票OCRが「簡単に」作れる時代になった?
kon_shou
0
180
Prismを使った型安全な暗号化_関数型まつり2026
_fhhmm
0
160
AWS DevOps AgentのAzure接続機能を検証して見えた活用法/Use Cases Verified for the AWS DevOps Agent's Azure Connectivity Feature
masakiokuda
0
180
Lean は証明の正しさを確認するためだけのツールって思ってませんか?
inoueasei
1
130
Featured
See All Featured
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
The agentic SEO stack - context over prompts
schlessera
0
860
Ruling the World: When Life Gets Gamed
codingconduct
0
290
The Pragmatic Product Professional
lauravandoore
37
7.4k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
190
Crafting Experiences
bethany
1
230
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.7k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
420
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
430
Transcript
理解してほしい VisionTransformer B4 佐藤 駿
はじめに • 機械学習を全く知らない人でも理解できるように解説します 目次 • 機械学習 • ニューラルネット • 畳み込みニューラルネット
(CNN) • Vision Transformer (ViT) • Attention • CNN vs ViT • ViTとCNNのいいとこどり例
機械学習とは • みんながAIっていってるやつ • ある入力に対して予測という形で出力を行う • なんでもできると思われがちなやつ 犬猫の画像分類 株価の予測 機械翻訳
画像の生成 自動運転 よくわかってない人の AIのイメージ
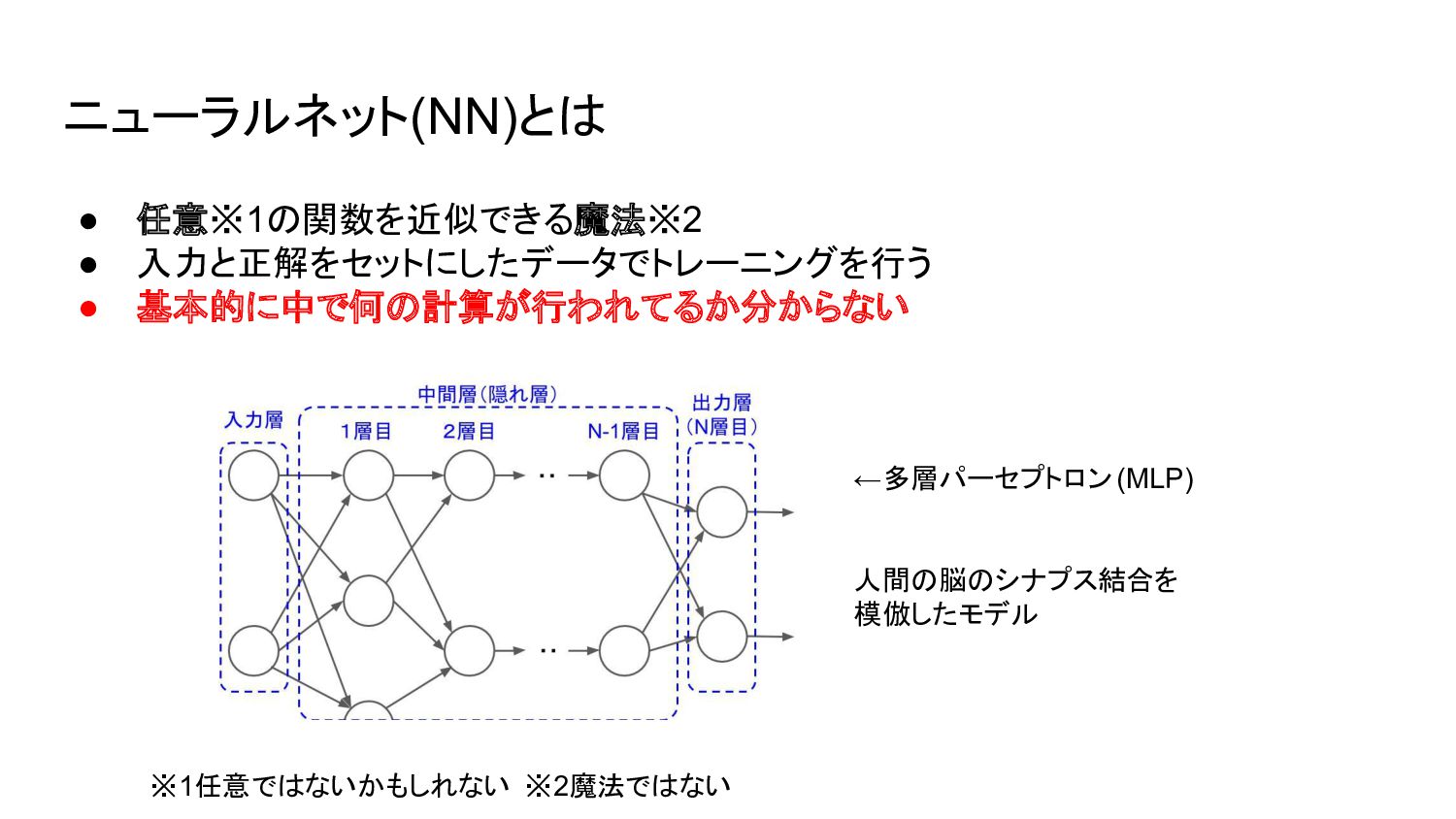
ニューラルネット(NN)とは • 任意※1の関数を近似できる魔法※2 • 入力と正解をセットにしたデータでトレーニングを行う • 基本的に中で何の計算が行われてるか分からない ※1任意ではないかもしれない ※2魔法ではない ←多層パーセプトロン(MLP)
人間の脳のシナプス結合を 模倣したモデル
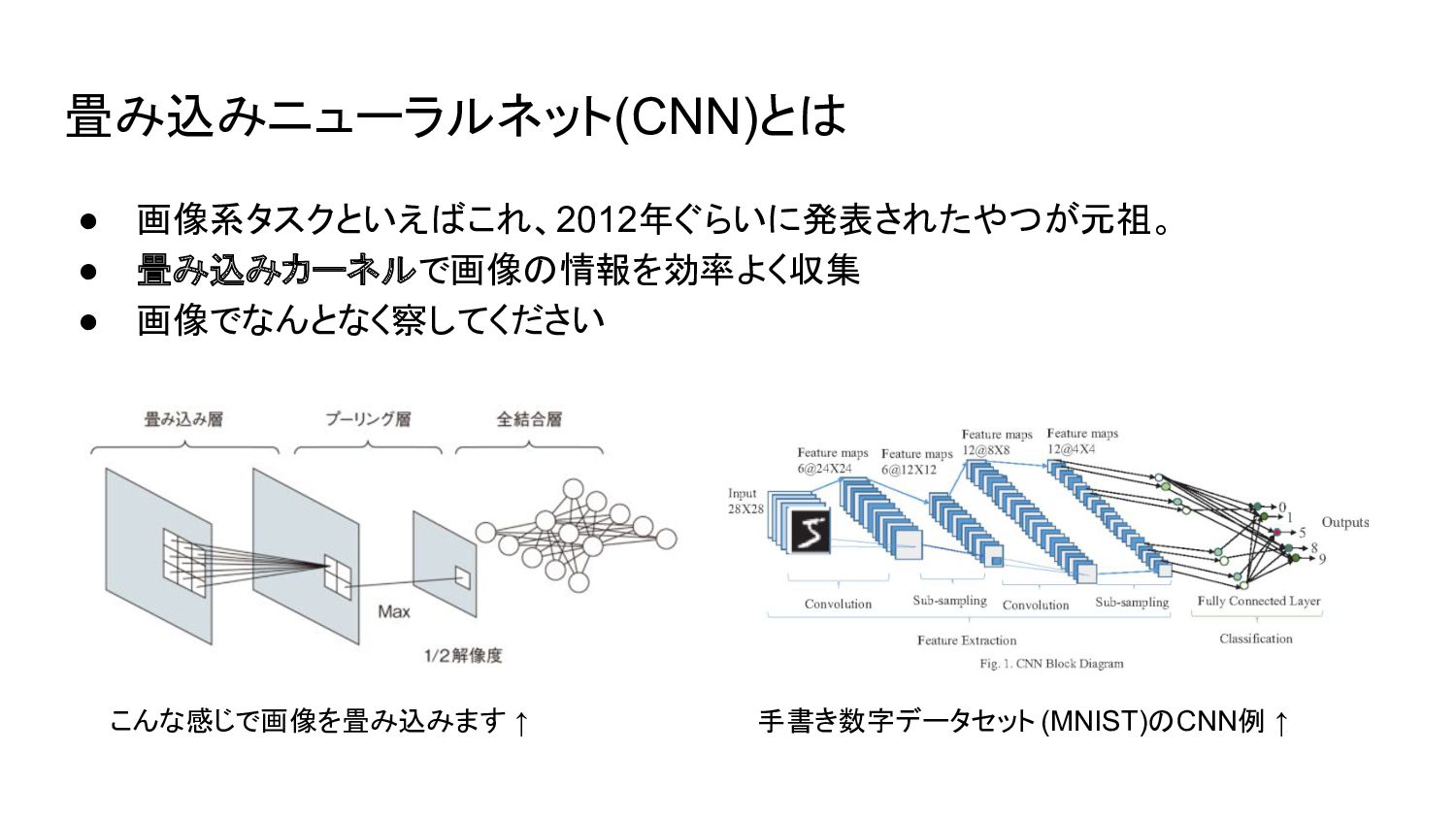
畳み込みニューラルネット(CNN)とは • 画像系タスクといえばこれ、2012年ぐらいに発表されたやつが元祖。 • 畳み込みカーネルで画像の情報を効率よく収集 • 画像でなんとなく察してください 手書き数字データセット (MNIST)のCNN例 ↑
こんな感じで画像を畳み込みます ↑
CNNの応用タスク 画像分類 画像生成 物体認識 距離画像生成
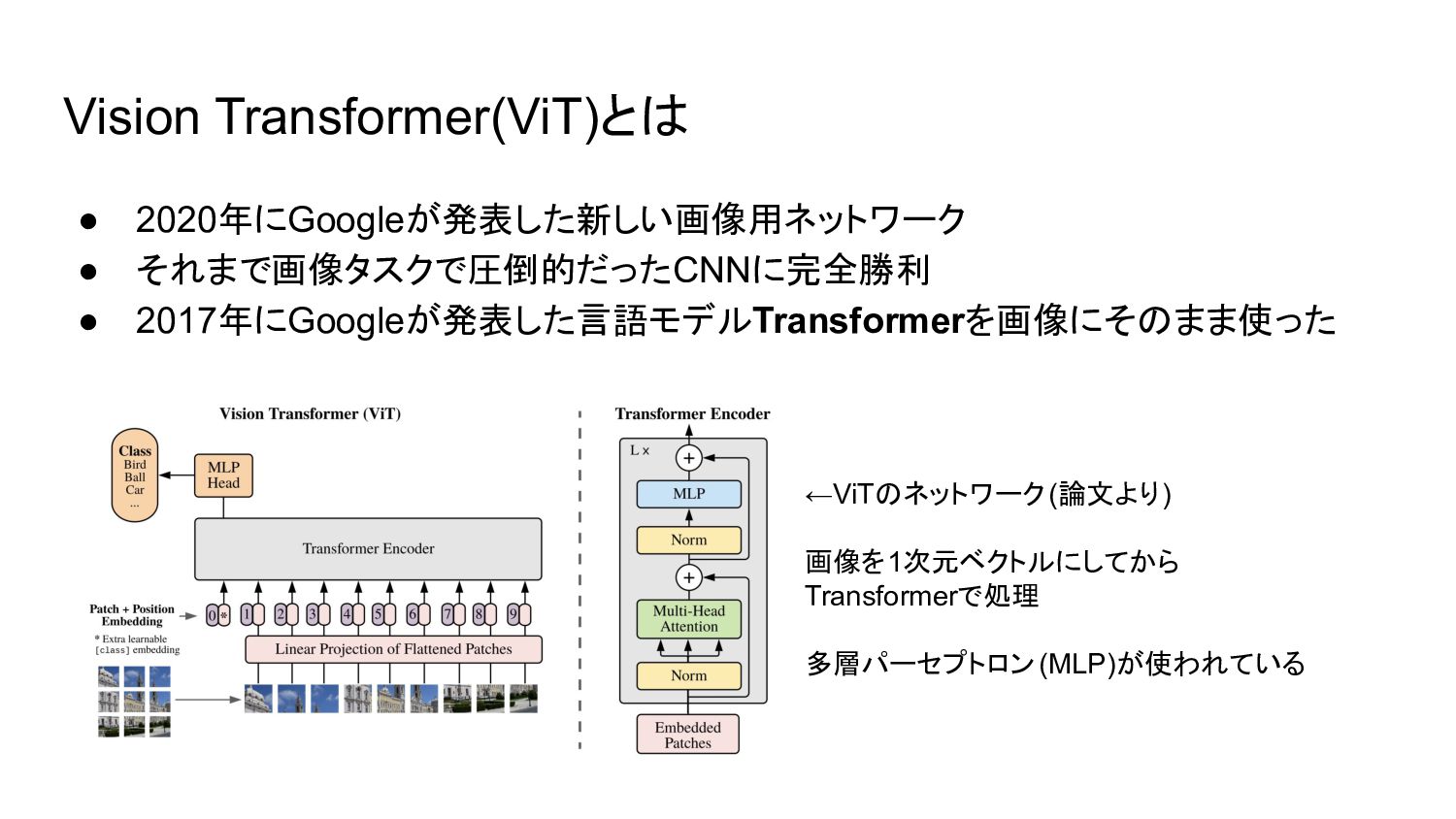
Vision Transformer(ViT)とは • 2020年にGoogleが発表した新しい画像用ネットワーク • それまで画像タスクで圧倒的だったCNNに完全勝利 • 2017年にGoogleが発表した言語モデルTransformerを画像にそのまま使った ←ViTのネットワーク(論文より) 画像を1次元ベクトルにしてから
Transformerで処理 多層パーセプトロン(MLP)が使われている
Attentionとは • 最初はCNNで導入されたモジュール • ニューラルネットがどこに注目するのかを決める Attentionの例 Attentionが犬以外の背景 をあまり重要視しない ように学習されている
Scaled Dot-Product Attentionの解説 Query, Key, Valueを用意して計算 1. Query, Keyの行列積を計算 2.
SoftMaxを使ってAttentionMapを生成 3. ValueにMaskを適用して完成 • ViTで使われているのはMulti-Head Attention • Scaled Dot-Product Attentionを複数使う • より多くのパターンを作ることで情報量UP
Vision Transformerのアーキテクチャ1 入力 画像をパッチに分割して1次元ベクトル化 (xy座標情報は捨てる) パッチごとにPosition Embeddingも追加 ViTでは16*16単位で画像をパッチ化 パッチ化した画像を平坦化して入力!
Vision Transformerのアーキテクチャ2 1. Norm: データの正規化を行うNormalization 2. MHA: 情報の注目を決めるAttention 3. MLP:
情報の処理を行う多層パーセプトロン (横道に逸れている矢印はSkip-Connection) Norm->MHA->Norm->MLPのブロックをLレイヤー繰り返す ここでMHAの入力QKVは全て同じ入力(?!)
CNN vs ViT Q. なぜViTがCNNに圧勝したのか A. タスクがちょうど良かったから ViT : Attentionで全体(Global)の特徴量をまとめる
CNN: 畳み込みで局所(Local)の特徴量を捉える • 比較が画像分類タスクだったためViTが圧勝した • 画像分類は画像の中に何が映っているか何となく分かればいい ViTとResNet(CNN)の 内部表現の類似性の比較 ViTの方が安定した表現を 獲得している (?)
CNNとViTのいいとこどり例 Depth Former (2022/3) : 深度推定タスク • ViTはCNNより良い性能が出せたがあと一歩性能が足りなかった • CNNの情報を足すことで細かいところまで考慮できるようになった
• 深度(距離)画像なのでカーペットのテクスチャが反映されているのはおかしい • CNNとViTの組み合わせでLocalとGlobalの情報を考慮できるネットワークになった 入力画像 ViTモデル1 ViTモデル2 DepthFormer 正解画像
さいごに • 現在多くの画像タスクでBackboneとしてViTが使われている • ViT自体も様々なモデルの開発競争が行われている • ViT以外にもCNNだけのモデルやMLPのモデルも研究されている • みんなもViTを実装して最新のAIモデルを作ろう! •
画像系AIの相談があれば@shun74まで
参考 1. ニューラルネット: https://ledge.ai/neural-network/ 2. CNN: https://leadinge.co.jp/rd/2021/06/07/863/ 3. ViT: https://qiita.com/omiita/items/0049ade809c4817670d7
(最強資料) 4. ViT vs CNN: https://ai-scholar.tech/articles/transformer/transformer-vs-cnn 5. DepthFormer: https://arxiv.org/abs/2203.14211
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}