Parametric estimators of the conditional mean 11.3 Nonparametric estimators of the conditional mean 11.4 Smoothing 11.5 The bias-variance trade-off Fine Point & Technical Point ◦ Fisher consistency. ◦ Model dimensionality and the relation between frequentist and Bayesian intervals. ◦ A taxonomy of commonly used models.
Difference-in-Differences, https://diff.healthpolicydatascience.org/ (Last access: 2020/07/24) The quantity we care about. (興味のある対象) The algorithm that takes data as input and produces a value of the estimand. (Estimandを求めるために用いられるアルゴリズム・関数) The estimator’s output, given data input. (Estimatorの出力・実現値)
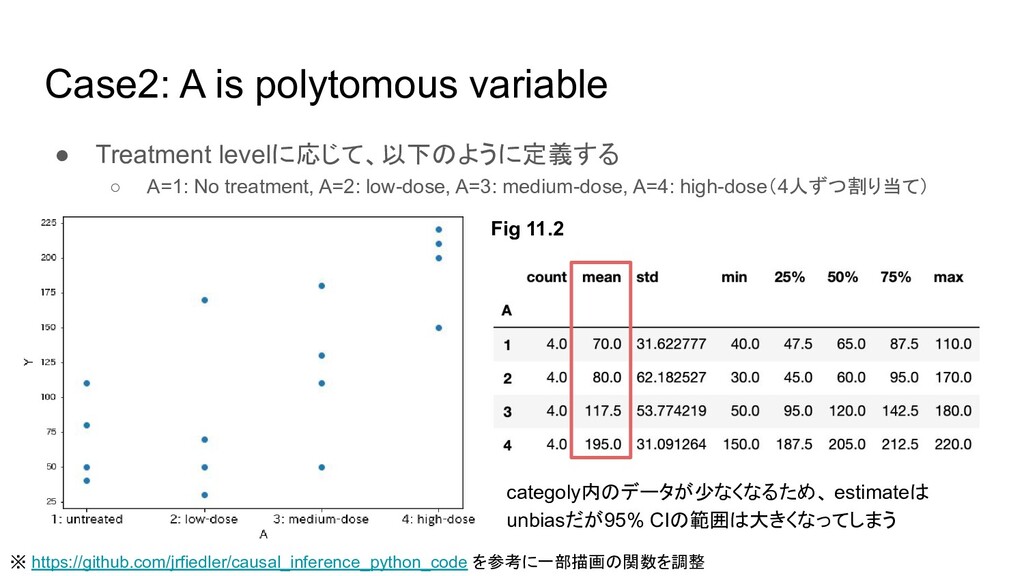
valueを取る(ので、正確には discreteだが実数の場合でも同様の議論になる) ※ https://github.com/jrfiedler/causal_inference_python_code を参考に一部描画の関数を調整 Fig 11.3 Aのパターンがさらに増えるため、データが 取得できないものが存在する( e.g. A = 90) ⇒ sample averageが計算できなくなる (continuousだった場合はほぼ全ての Aで問題に) “The data cannot speak about themselves”
Parametric estimators of the conditional mean 11.3 Nonparametric estimators of the conditional mean 11.4 Smoothing 11.5 The bias-variance trade-off Fine Point & Technical Point ◦ Fisher consistency. ◦ Model dimensionality and the relation between frequentist and Bayesian intervals. ◦ A taxonomy of commonly used models.
◦ A が多くのカテゴリであったり連続である場合、 sample averageが計算できなくなる ⇒ e.g. が評価できなくなる • 問題に対処するための考え方 ◦ A=90 におけるYの平均は、A=80における平均とA=100における平均の間にならないか? ◦ (さらに突っ込んで)YはAに対して線形に応答していたりしないか? ▪ この仮定が成り立つと、 A=90での効果は他のデータからの内挿で評価できて嬉しい Conditional mean function の形がパラメータ と の線形結合で表せると仮定 (制限)する Linear Mean Model
is not free lunch…. ◦ A prioriなモデルの制約が正しい時にしか評価は正しくならない ◦ “No model misspecification” かどうかに依存 ◦ このような理想的な状態が成立することはほとんどなく、 ある程度のmisspecificationは織り込まないといけないだろう • Parametricではない方法で修正することはできないか? ⇒ Nonparametric Estimator(次節)
Parametric estimators of the conditional mean 11.3 Nonparametric estimators of the conditional mean 11.4 Smoothing 11.5 The bias-variance trade-off Fine Point & Technical Point ◦ Fisher consistency. ◦ Model dimensionality and the relation between frequentist and Bayesian intervals. ◦ A taxonomy of commonly used models.
Parametric estimators of the conditional mean 11.3 Nonparametric estimators of the conditional mean 11.4 Smoothing 11.5 The bias-variance trade-off Fine Point & Technical Point • Fisher consistency. • Model dimensionality and the relation between frequentist and Bayesian intervals. • A taxonomy of commonly used models.
Parametric estimators of the conditional mean 11.3 Nonparametric estimators of the conditional mean 11.4 Smoothing 11.5 The bias-variance trade-off Fine Point & Technical Point ◦ Fisher consistency. ◦ Model dimensionality and the relation between frequentist and Bayesian intervals. ◦ A taxonomy of commonly used models.
specifiedであると仮定する ◦ 現実的な仮定ではないが、モデルの妥当性以外の話題に集中するため ◦ 次節以降では、本節で導入したモデルを用いてどのように因果推論が行われるか考えていく “We are now ready to describe the use of models for causal inference.”
Parametric estimators of the conditional mean 11.3 Nonparametric estimators of the conditional mean 11.4 Smoothing 11.5 The bias-variance trade-off Fine Point & Technical Point ◦ Fisher consistency. ◦ Model dimensionality and the relation between frequentist and Bayesian intervals. ◦ A taxonomy of commonly used models.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Case3: A is (continuous) variable • Aは薬の摂取量 [mg/day] ◦ 0-100のinteger](https://files.speakerdeck.com/presentations/6bd262c86ab141b59d8476687bc521c9/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}