Since Apache Lucene moved to Java 5 in November 2009 several new features and concepts were introduced. From maintaining Version-by-Version backwards compatibility to fully enabled Unicode 4.0 support and the recently merged "Flexible-Indexing" branch, future Versions are ushering a new ear of Open Source fulltext search. During spring 2010 Lucene and Solr developments have merged leading to an even closer development and more flexible modularization.
{kind=link}
![Who we are Uwe Schindler ([email protected]) Apache Lucene/Solr PMC](https://files.speakerdeck.com/presentations/41412ce02ab80130898a12313d035c57/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
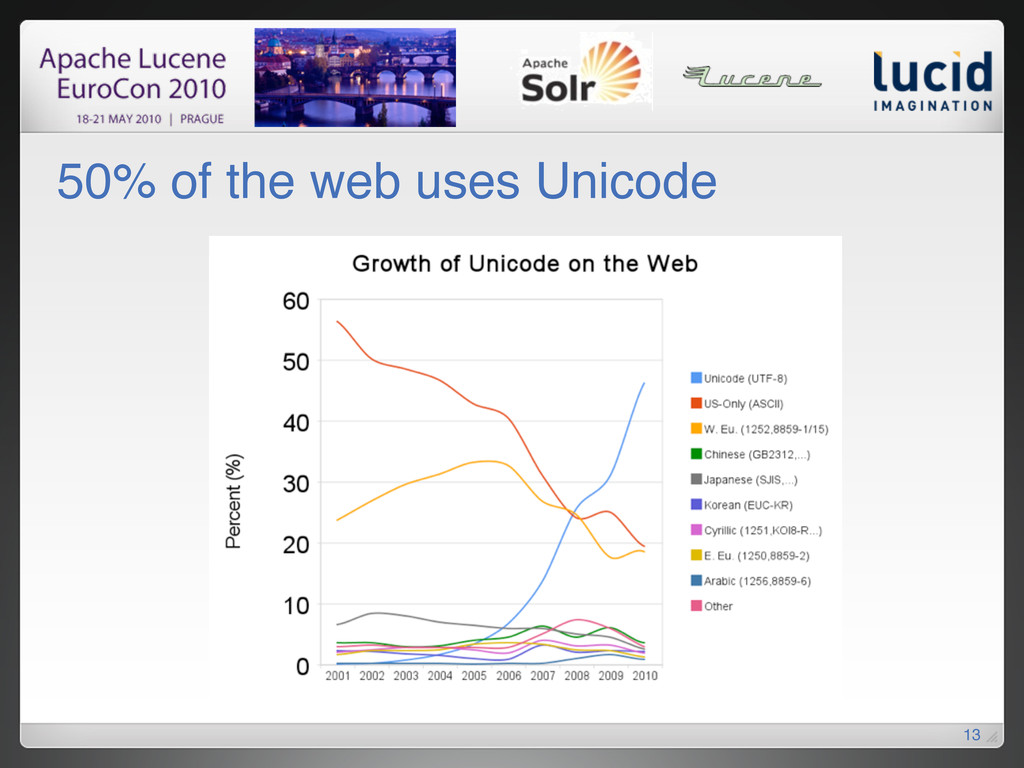{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
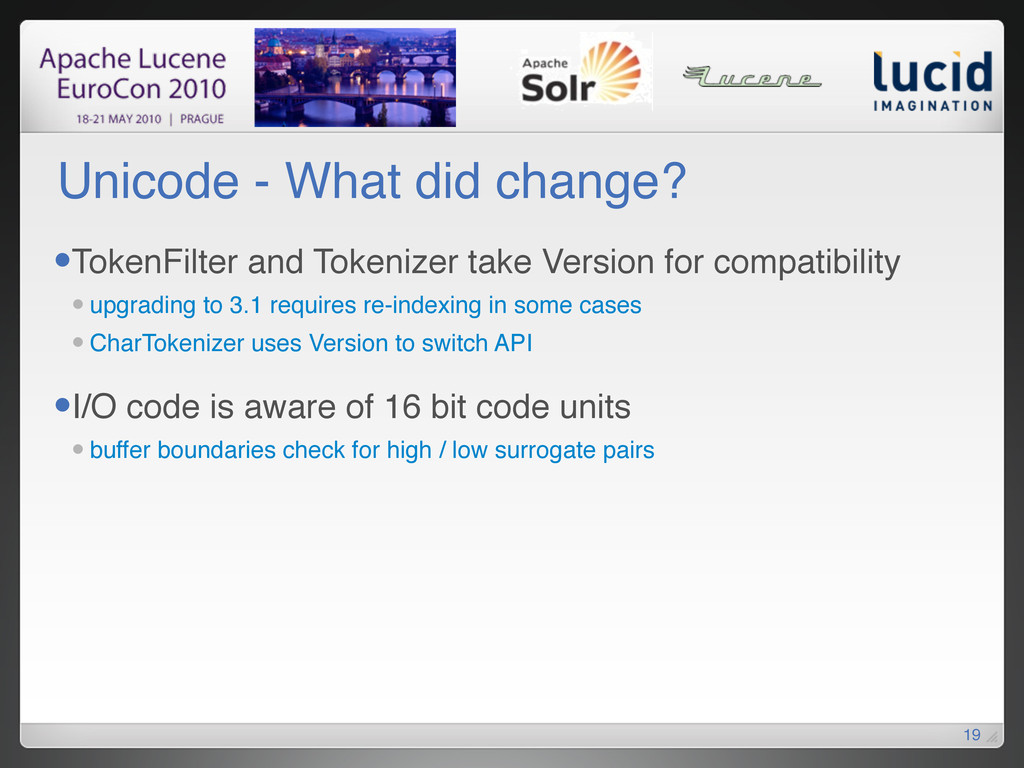{kind=link}
{kind=link}
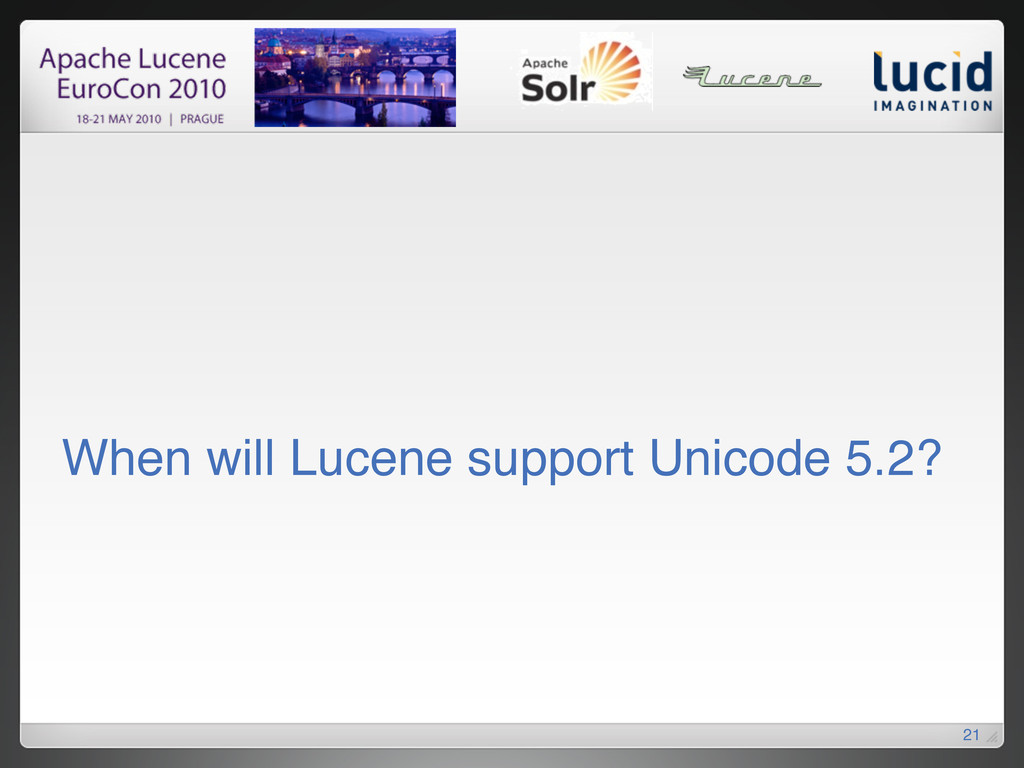{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
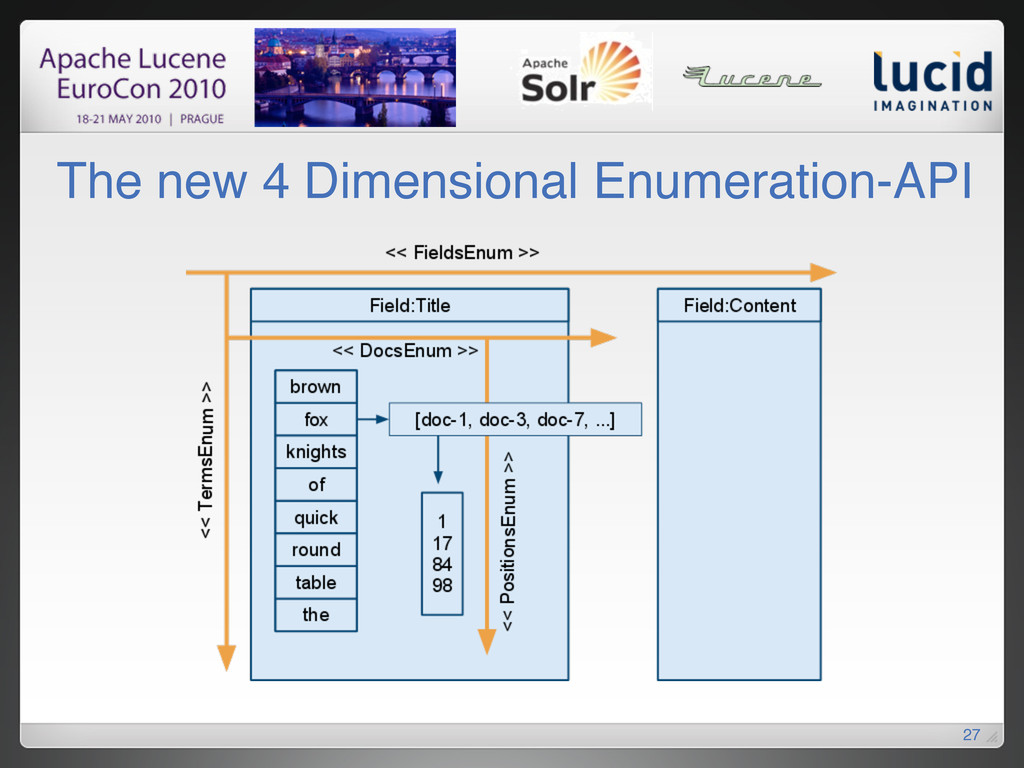{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}