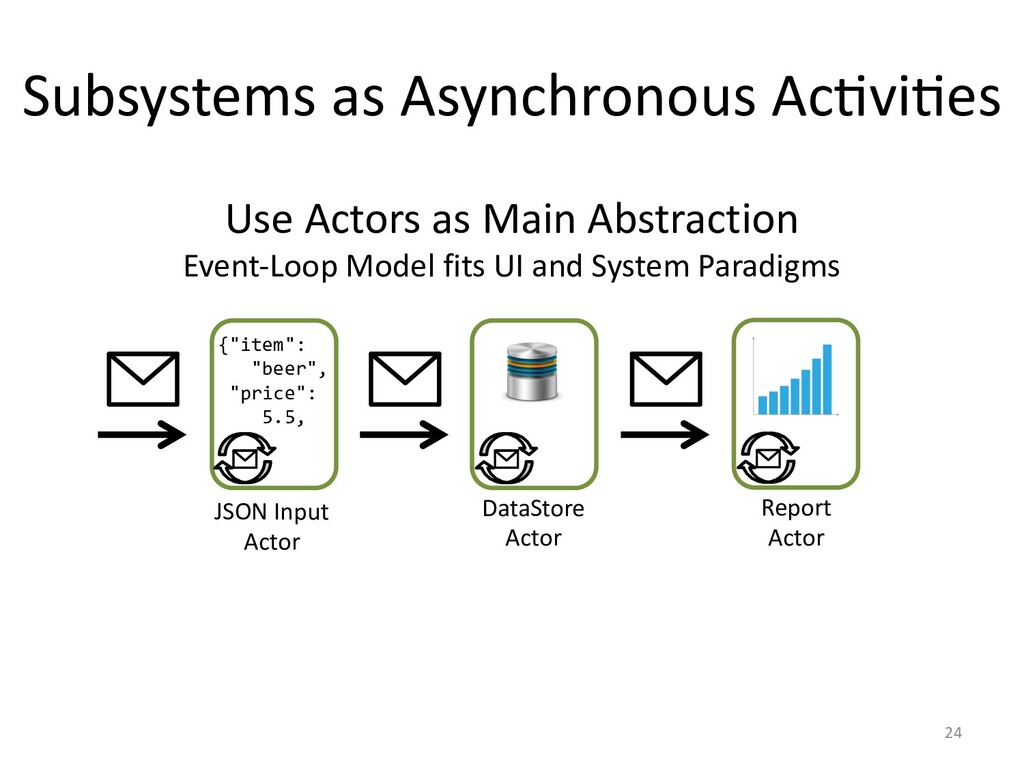
The actor model is a great tool for various use cases. Though, it's not the
only tool, and sometimes perhaps not even the best. Consequently, developers
started mixing and matching high-level concurrency models based on the problem
at hand, much like other programming abstractions. Though, this comes with
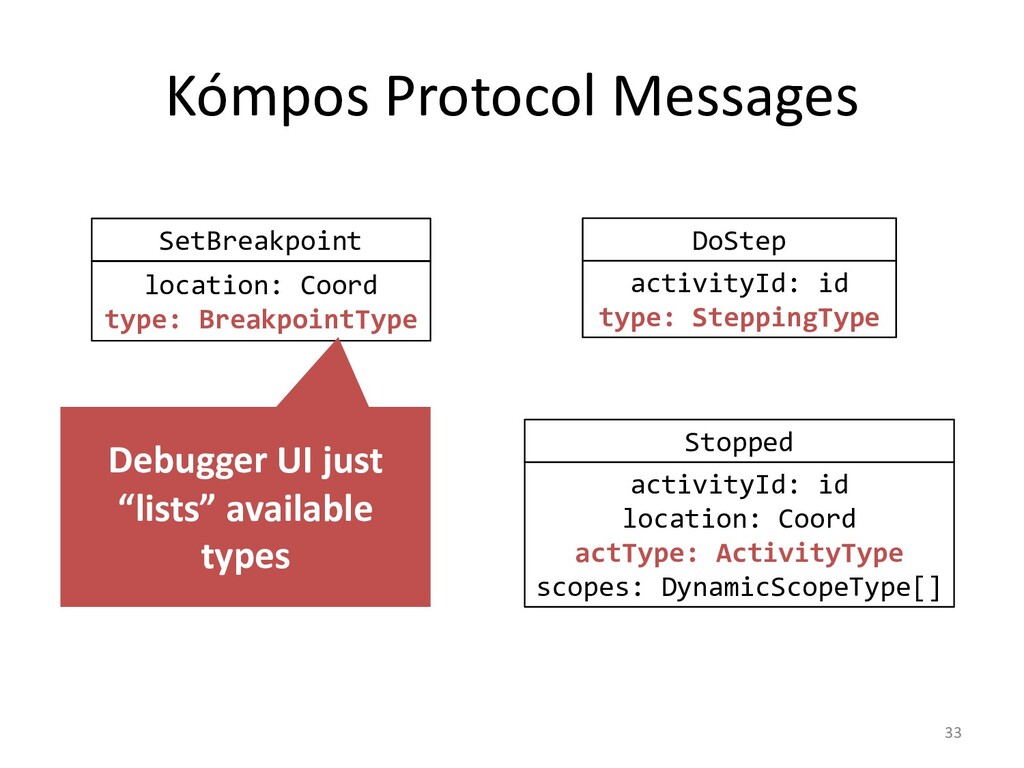
various problems. For instance, we don't usually have debugging tools that help
us to make sense of the resulting system. If we even have a debugger, it may
barely allow us to step through our programs instruction by instruction.
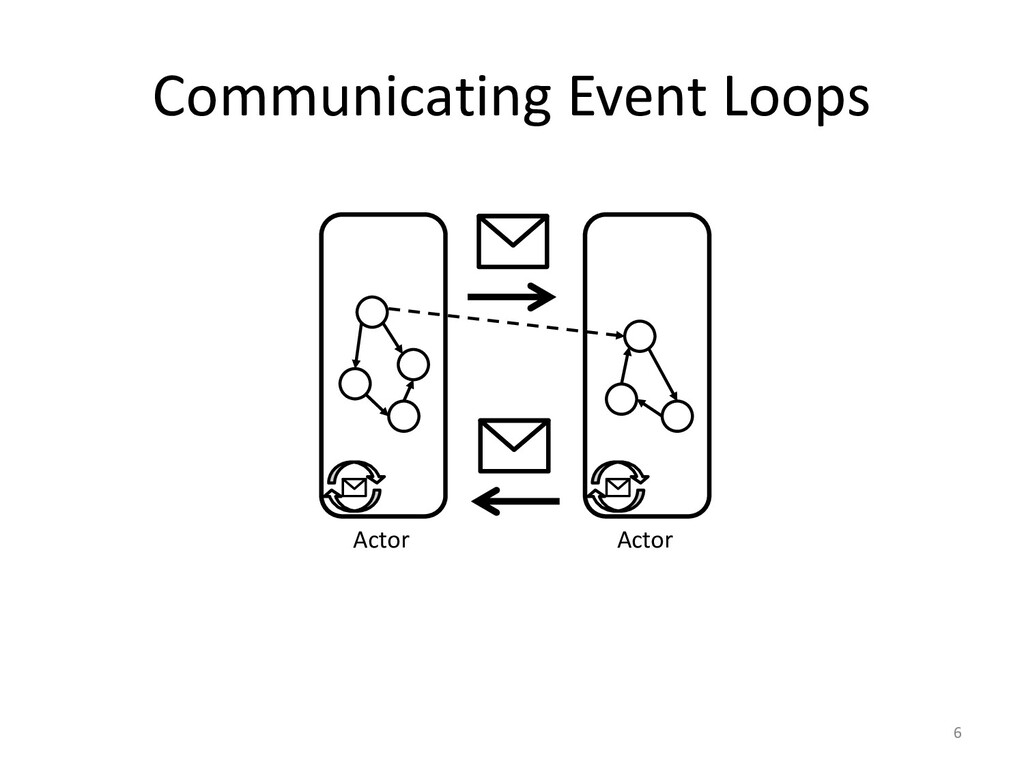
Let's imagine a better world! One were we can follow asynchronous messages,
jump to the next transaction commit, or break on the next fork/join task
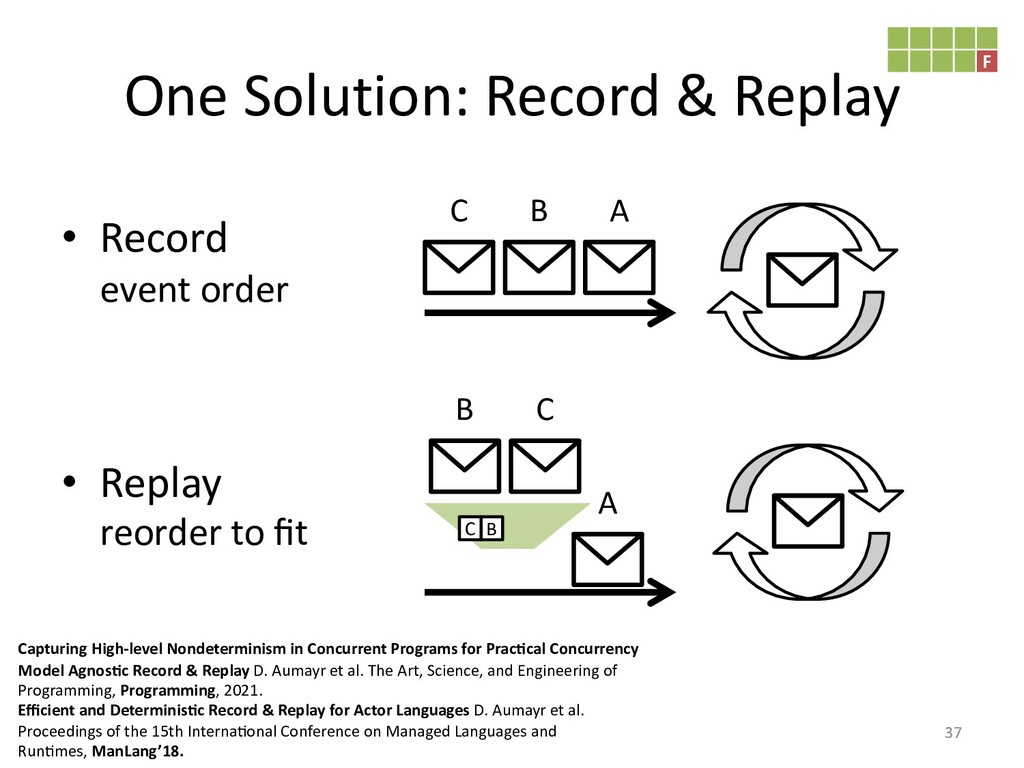
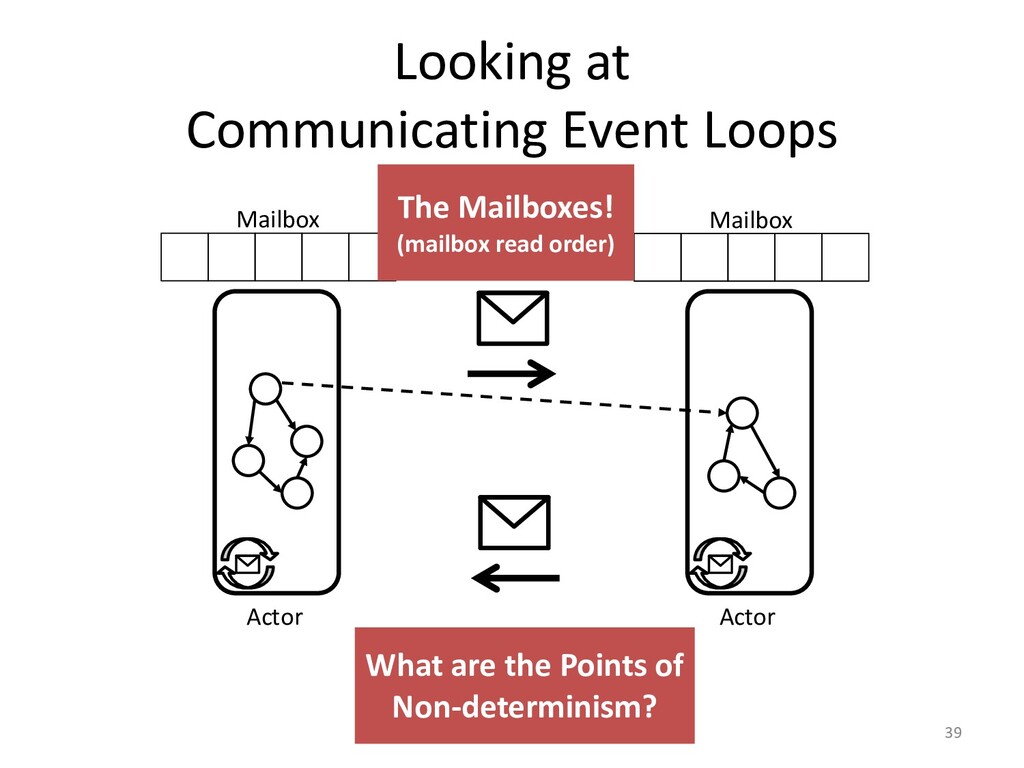
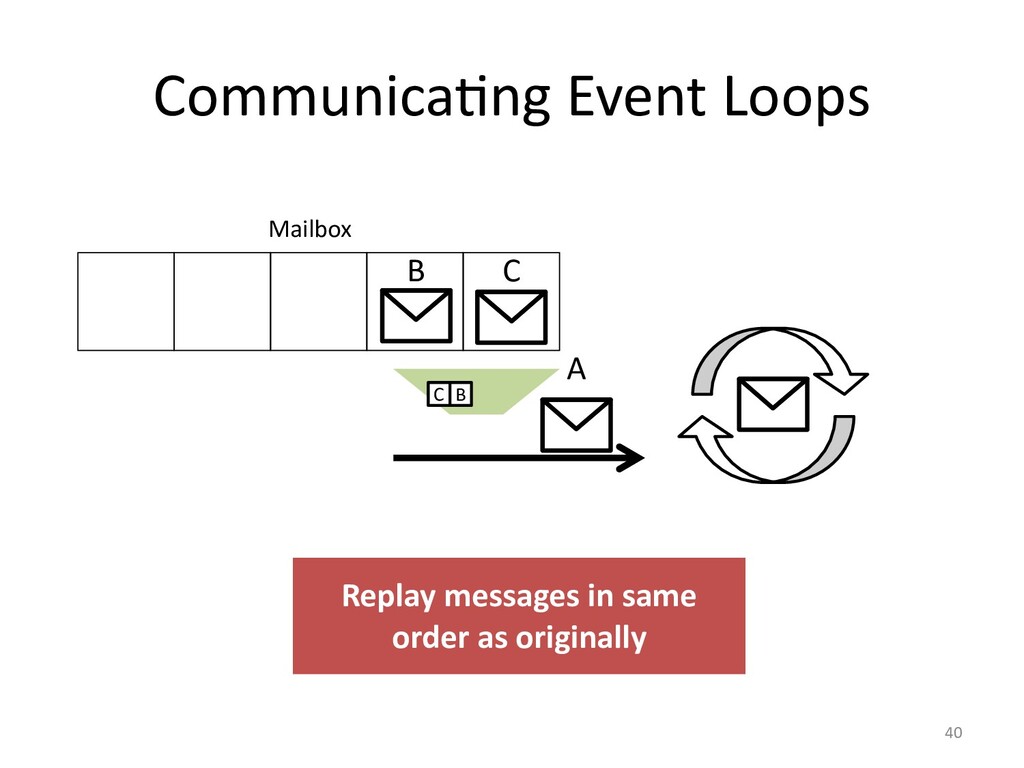
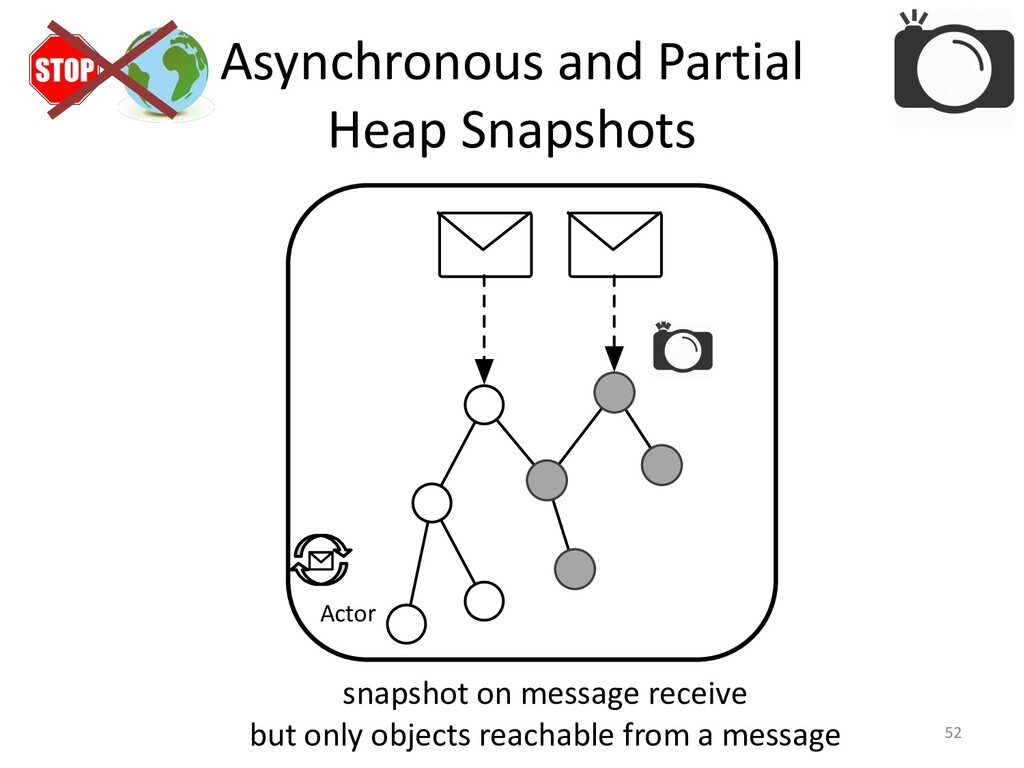
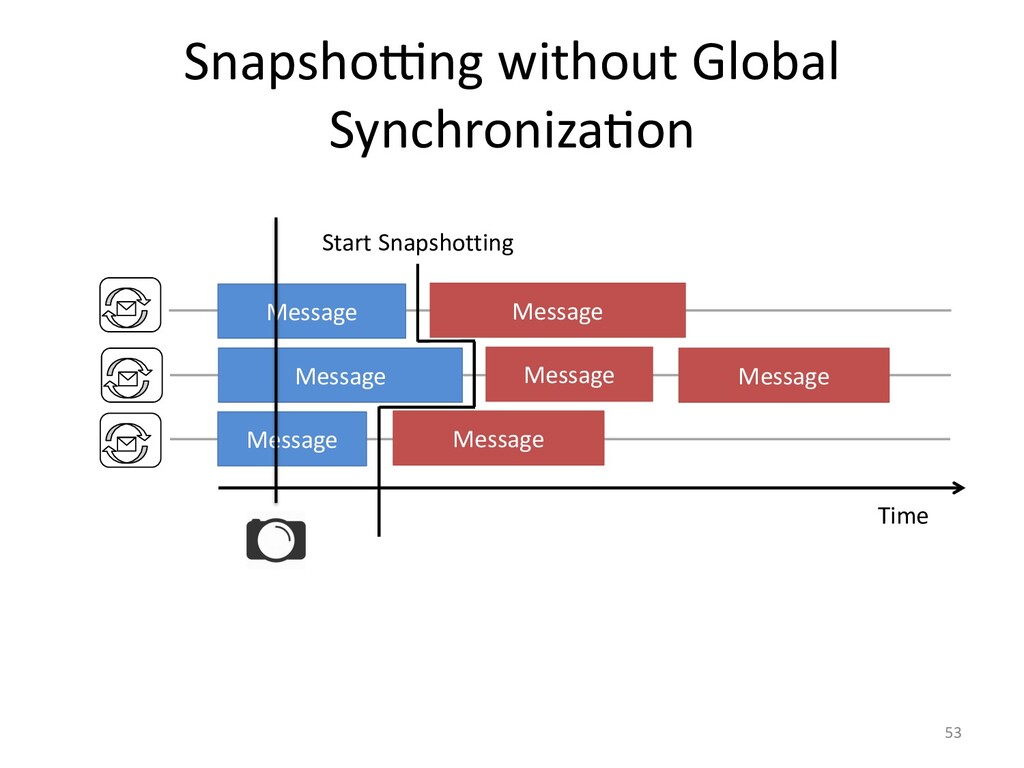
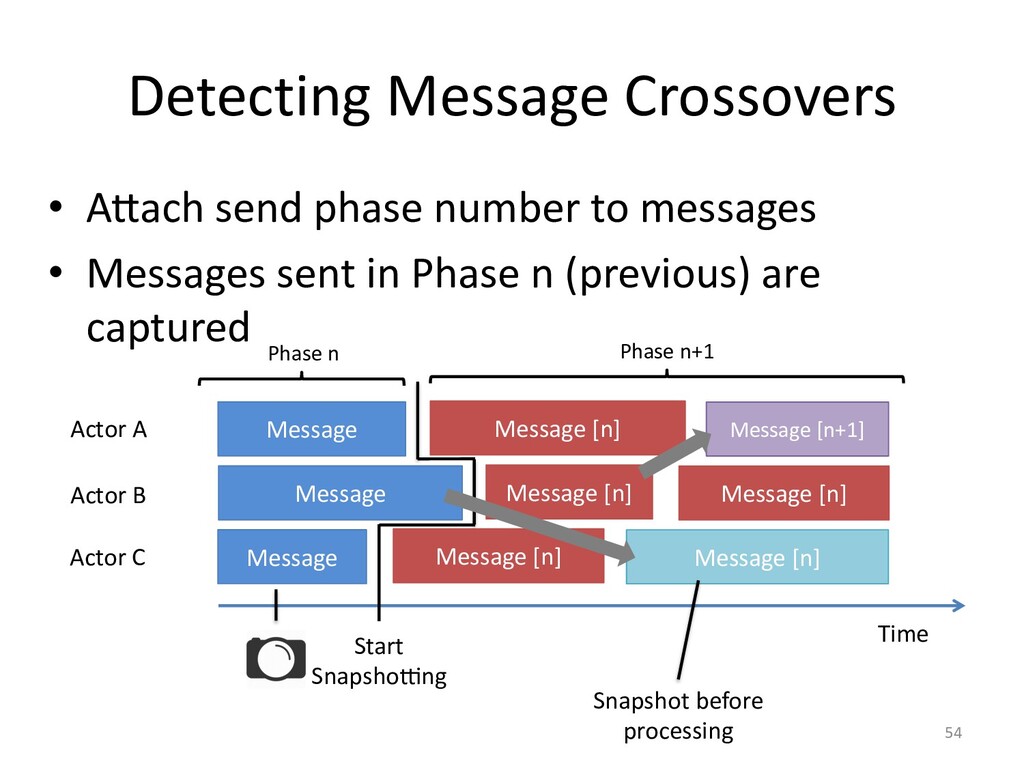
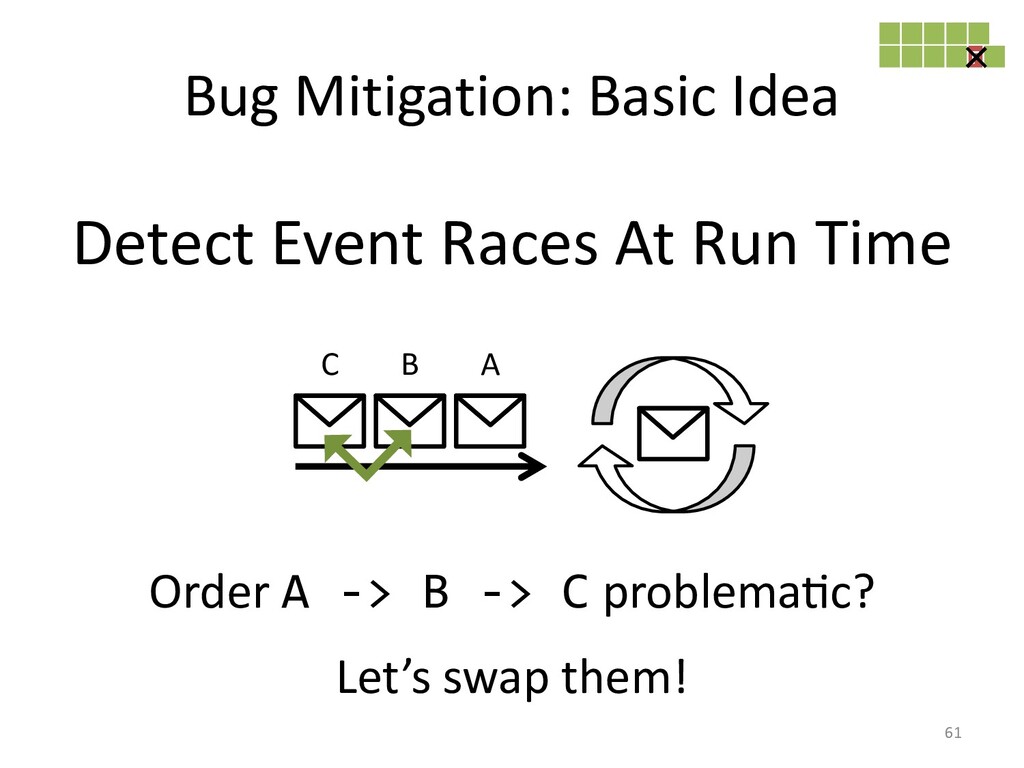
created. Though, race conditions remain notoriously difficult to reproduce. One
solutions it to record our program's execution, ideally capturing the bug. Then
we can replay it as often as need to identify the cause of our bug.
The hard bit here is making record & replay practical.
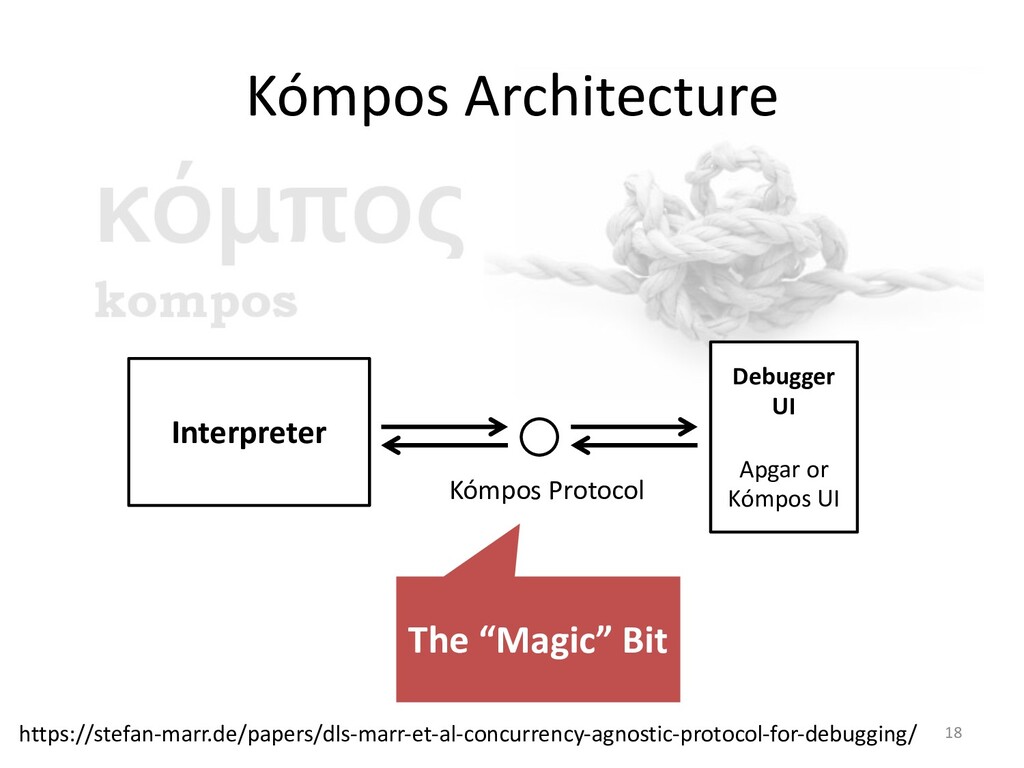
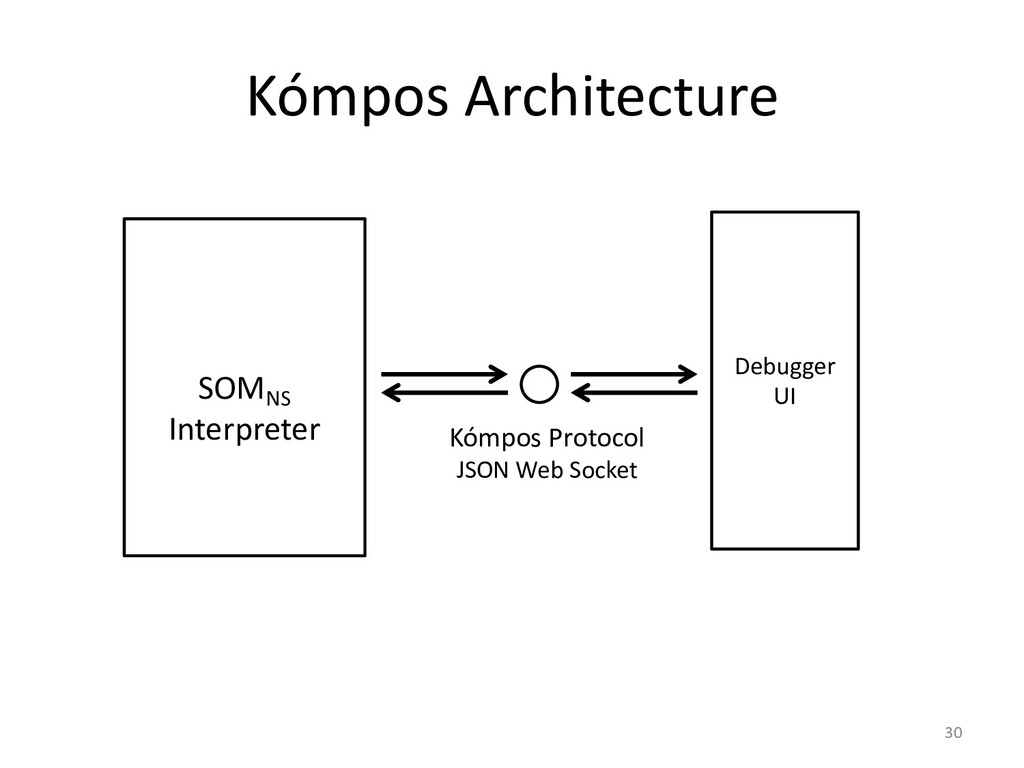
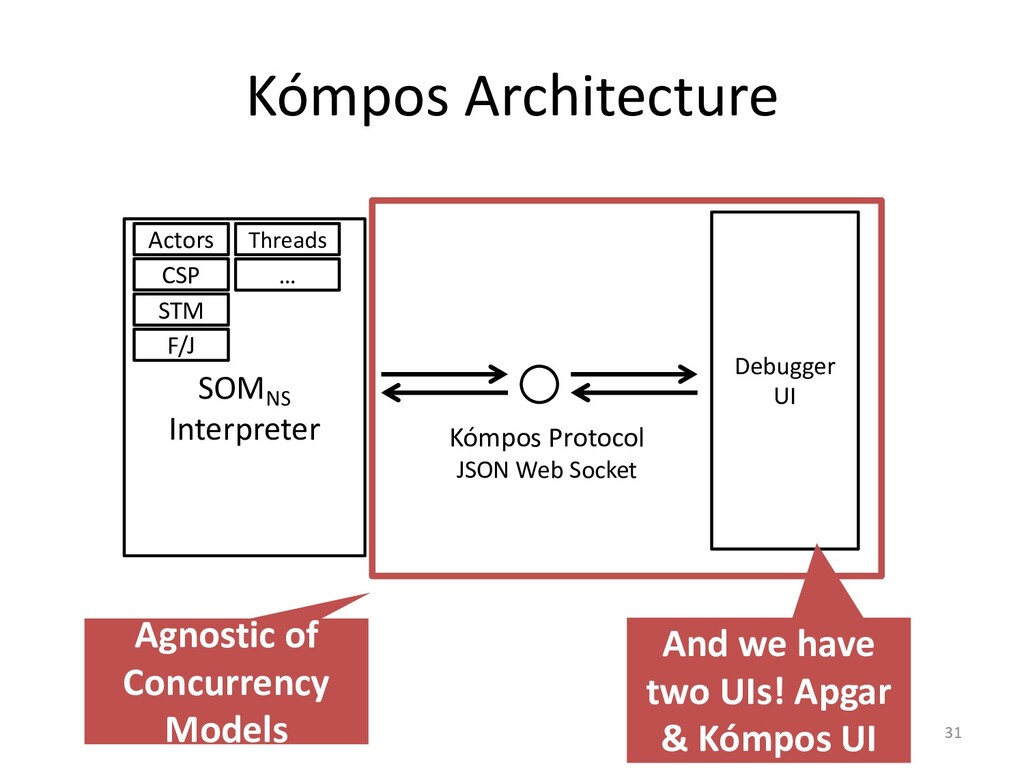
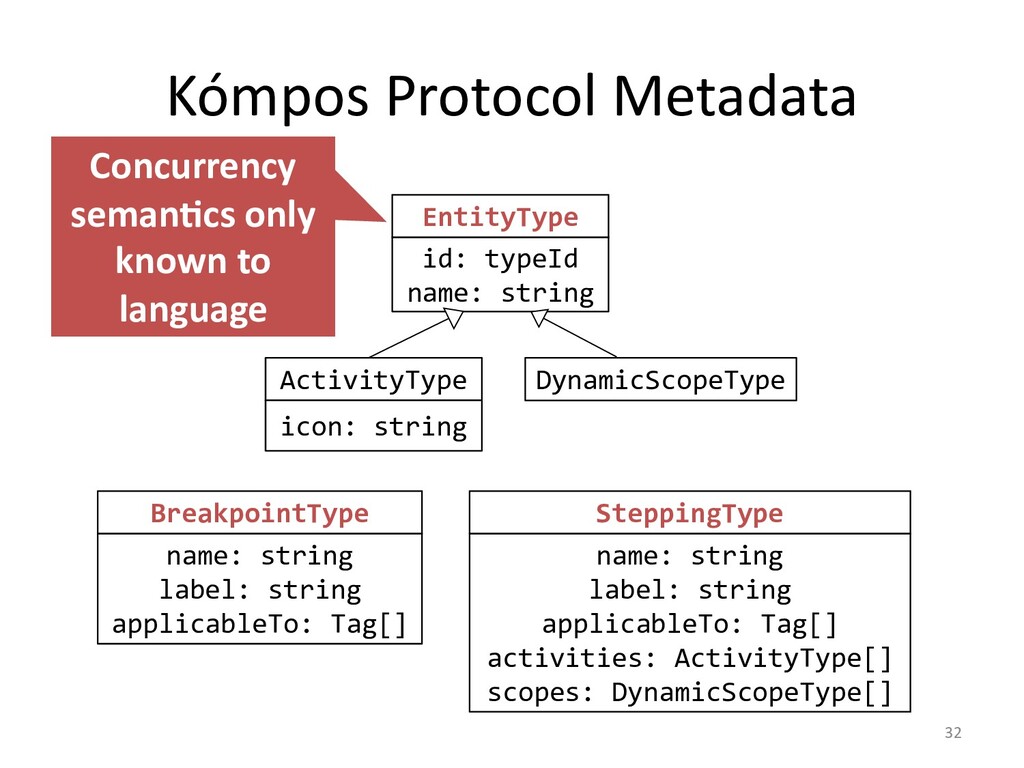
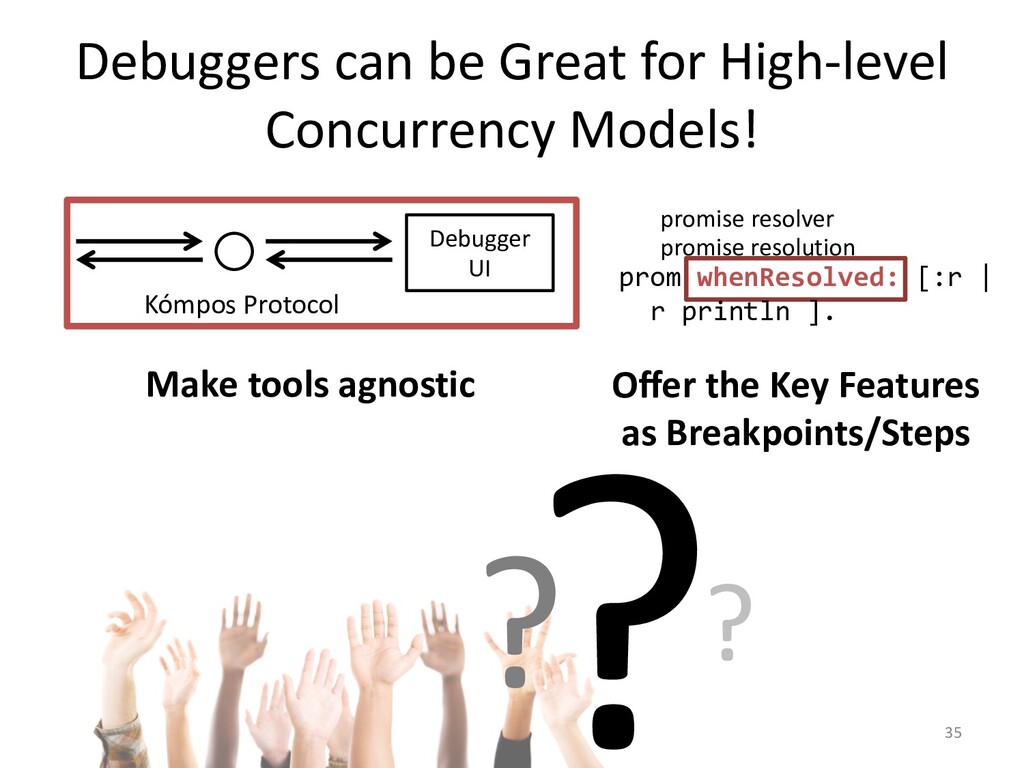
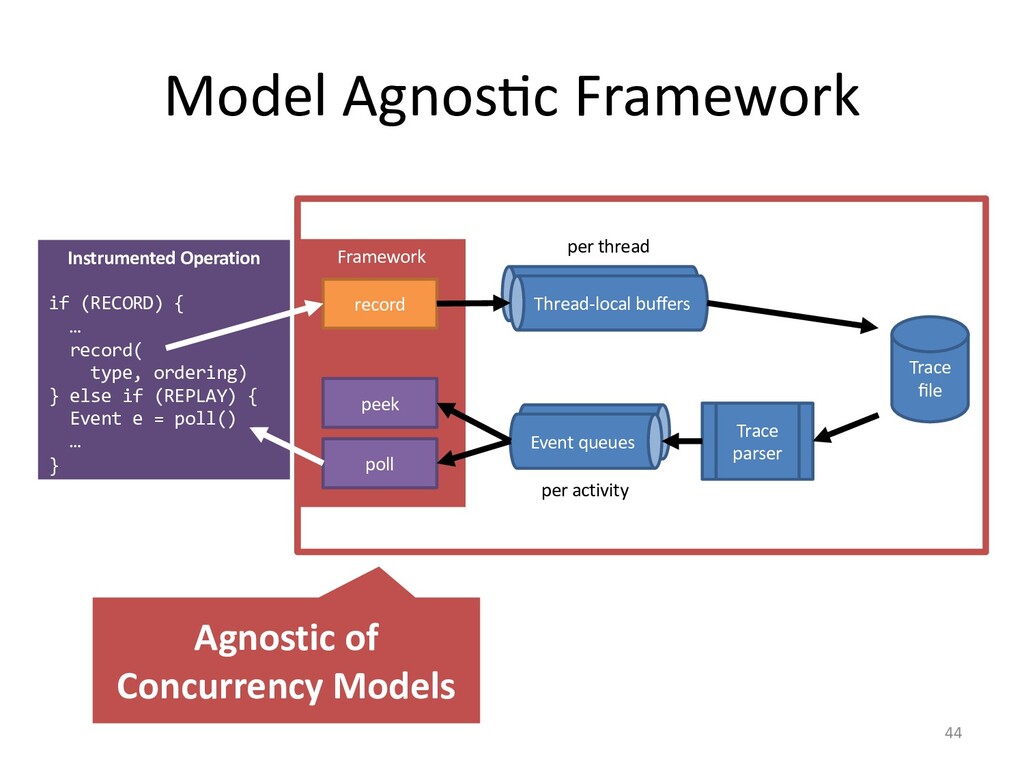
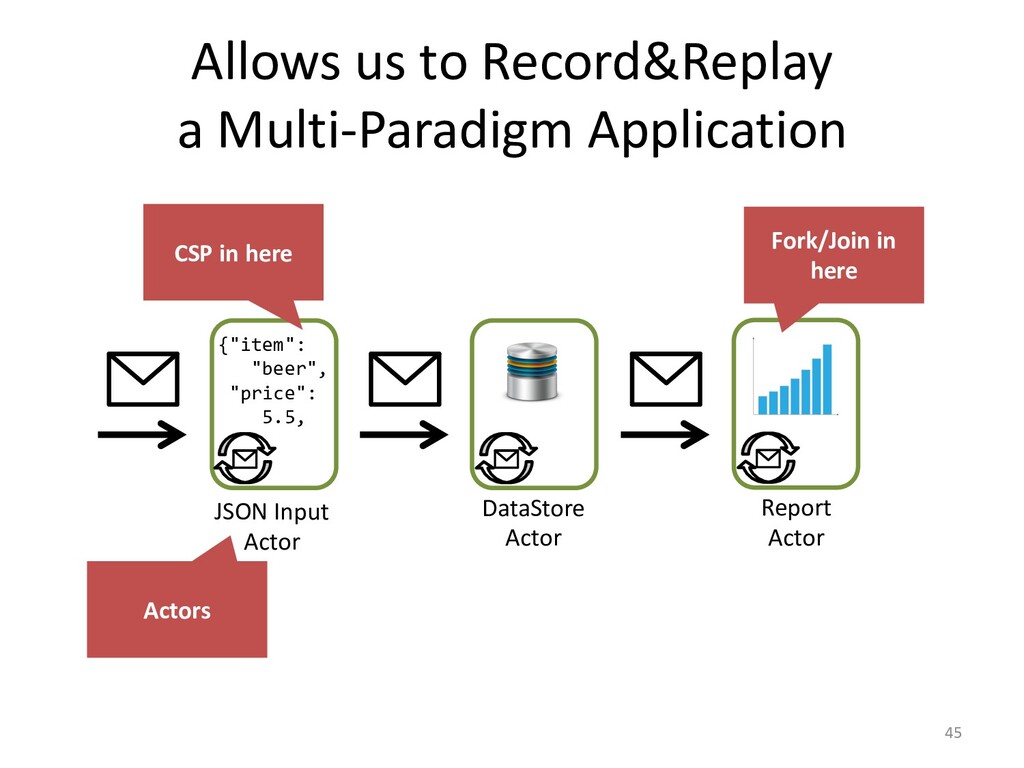
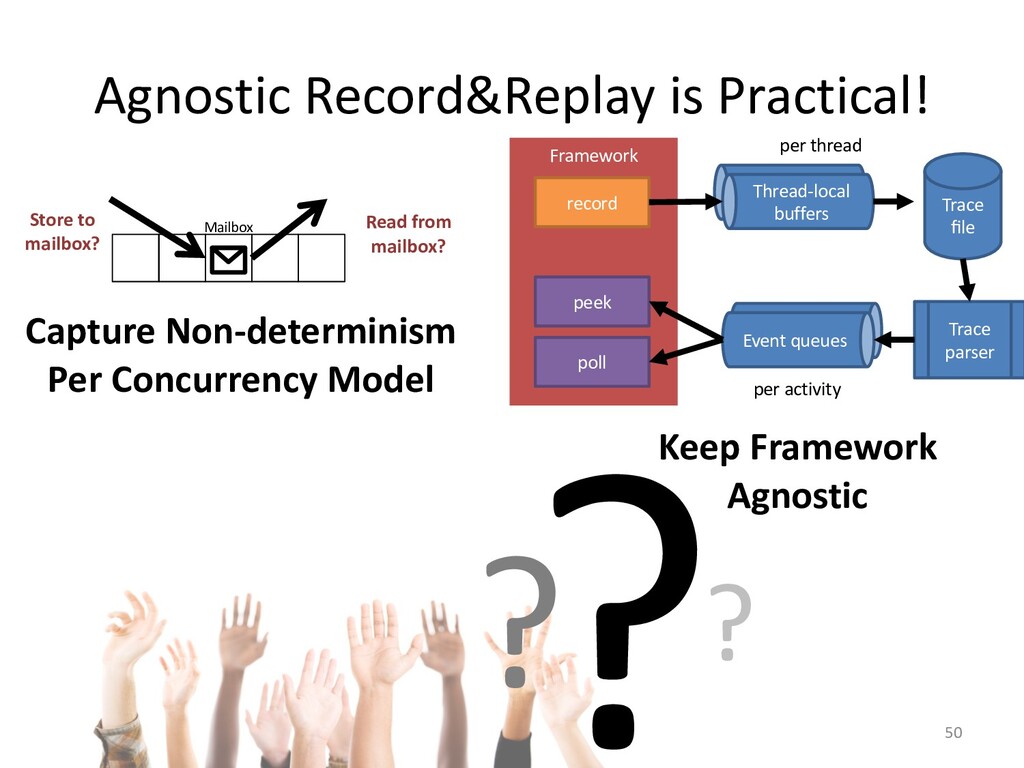
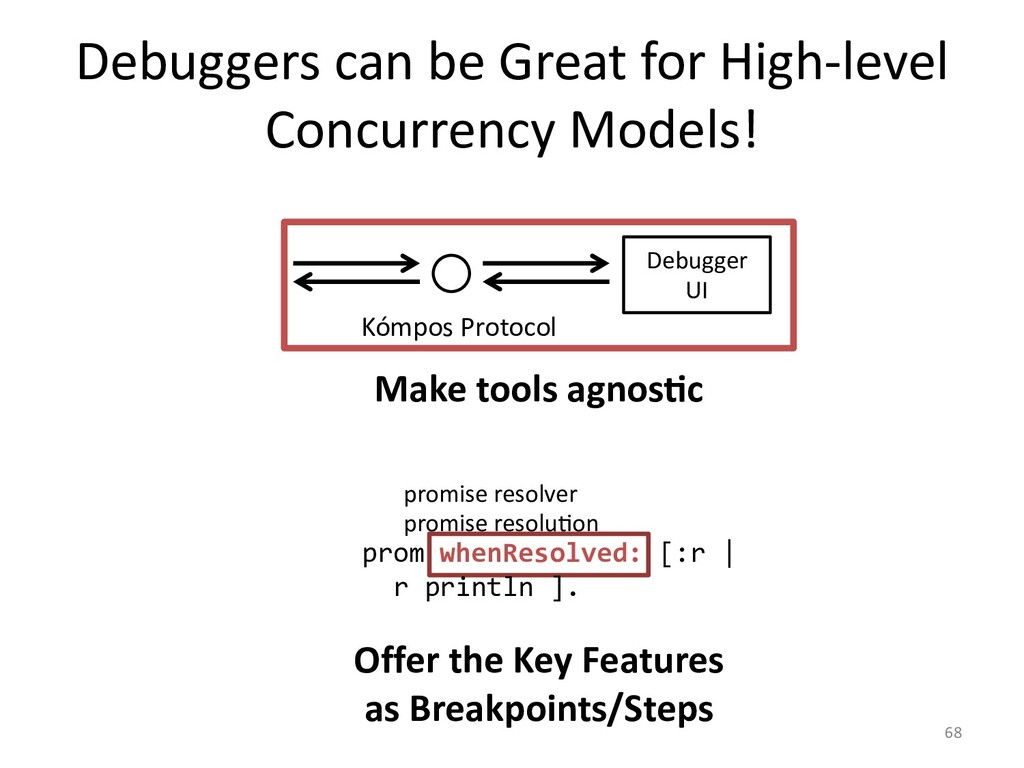
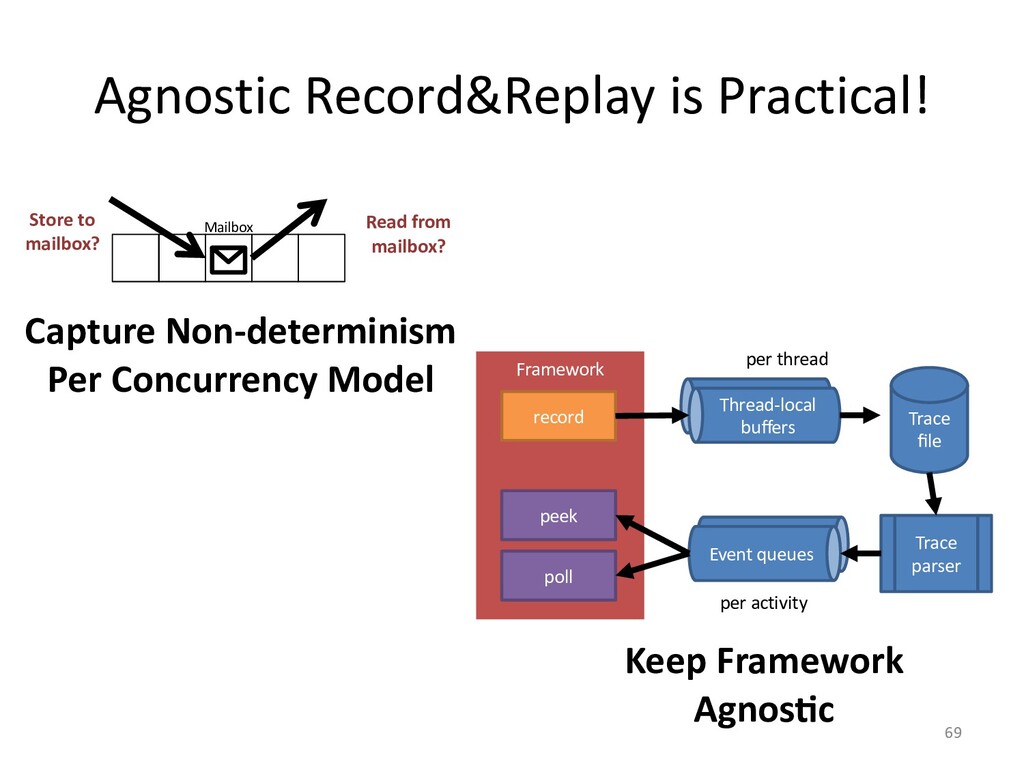
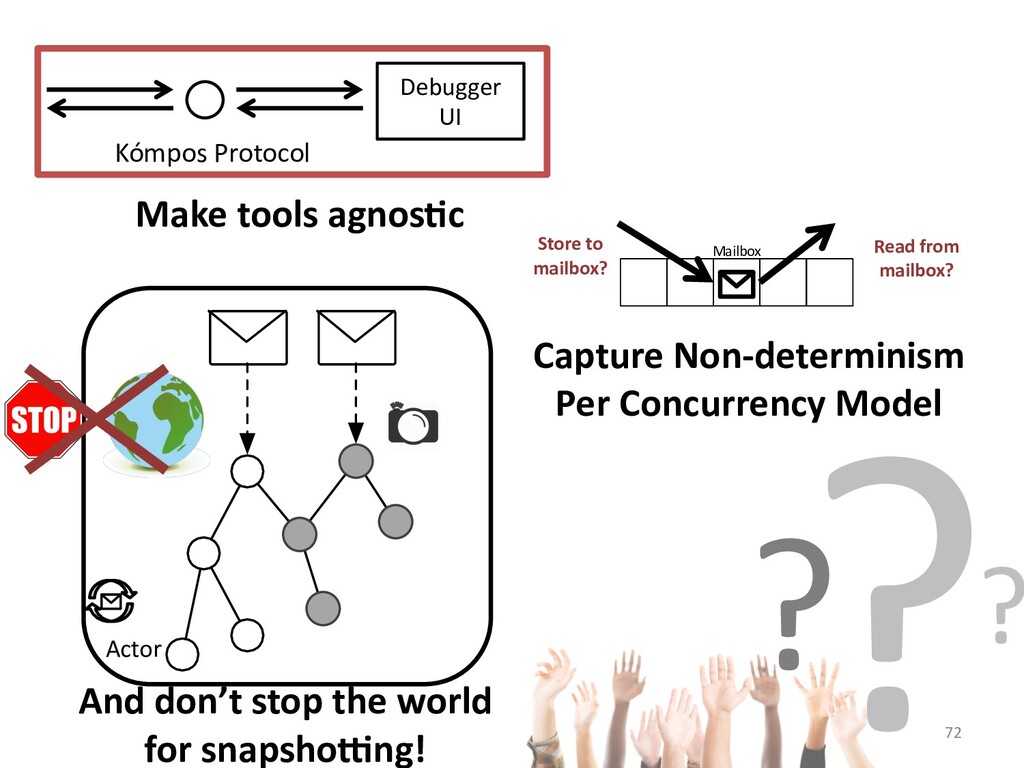
I will explain how our concurrency-model-agnostic approach allows us
to record model interactions trivially for later replay,
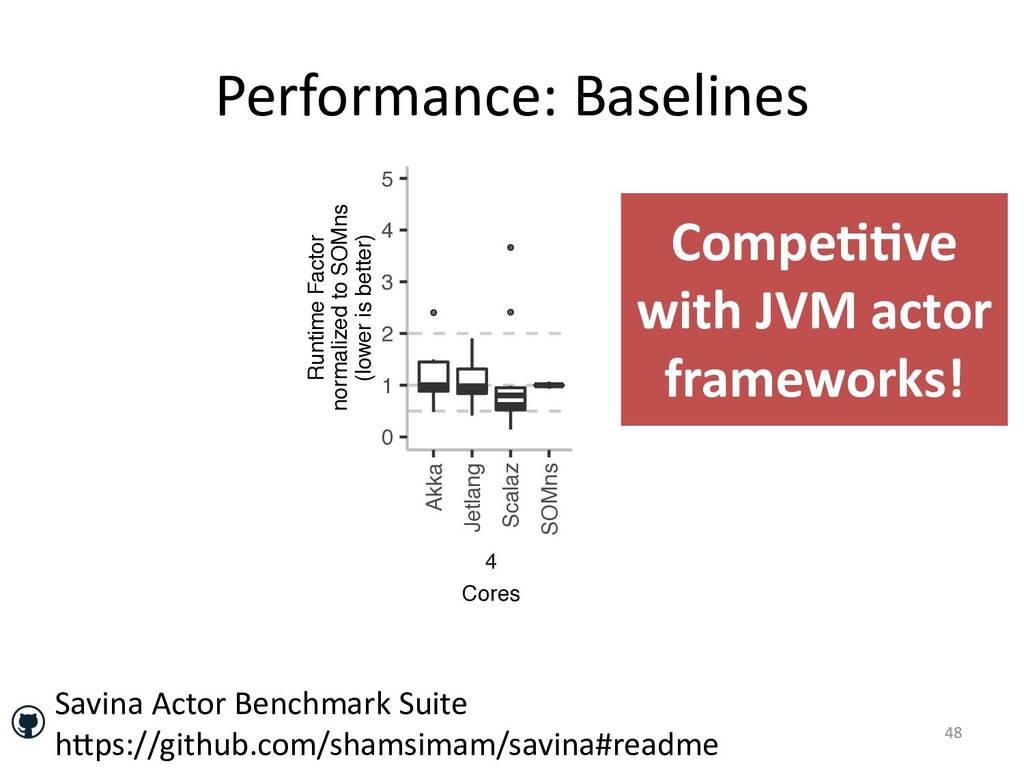
and how we minimized its run-time overhead.
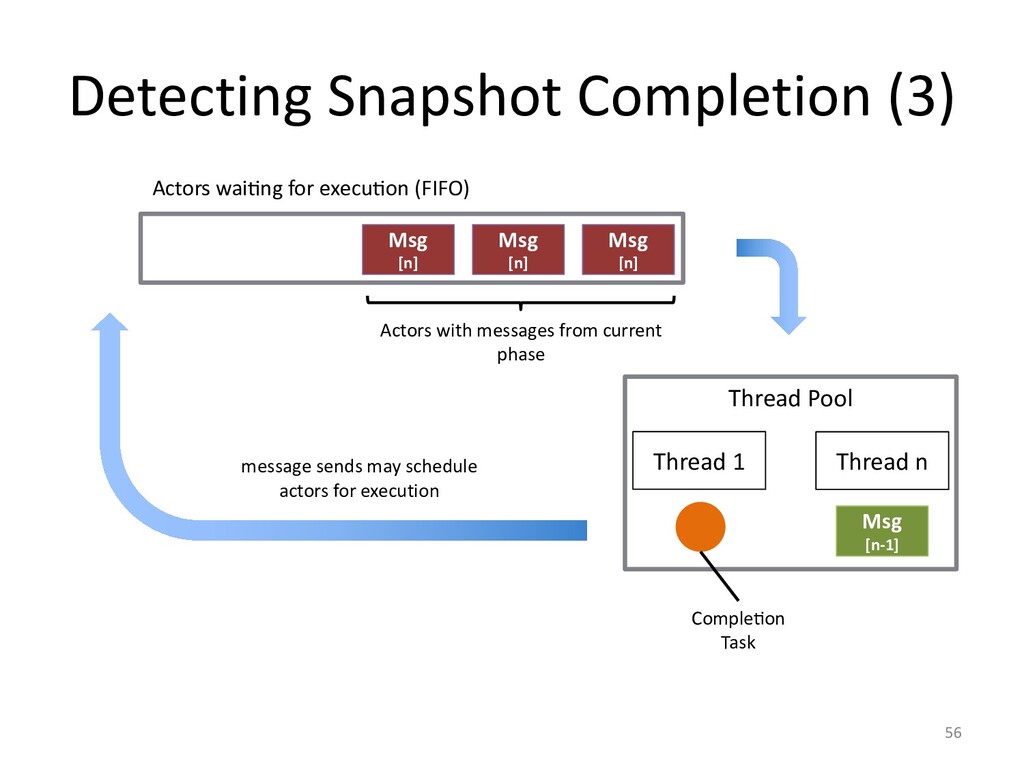
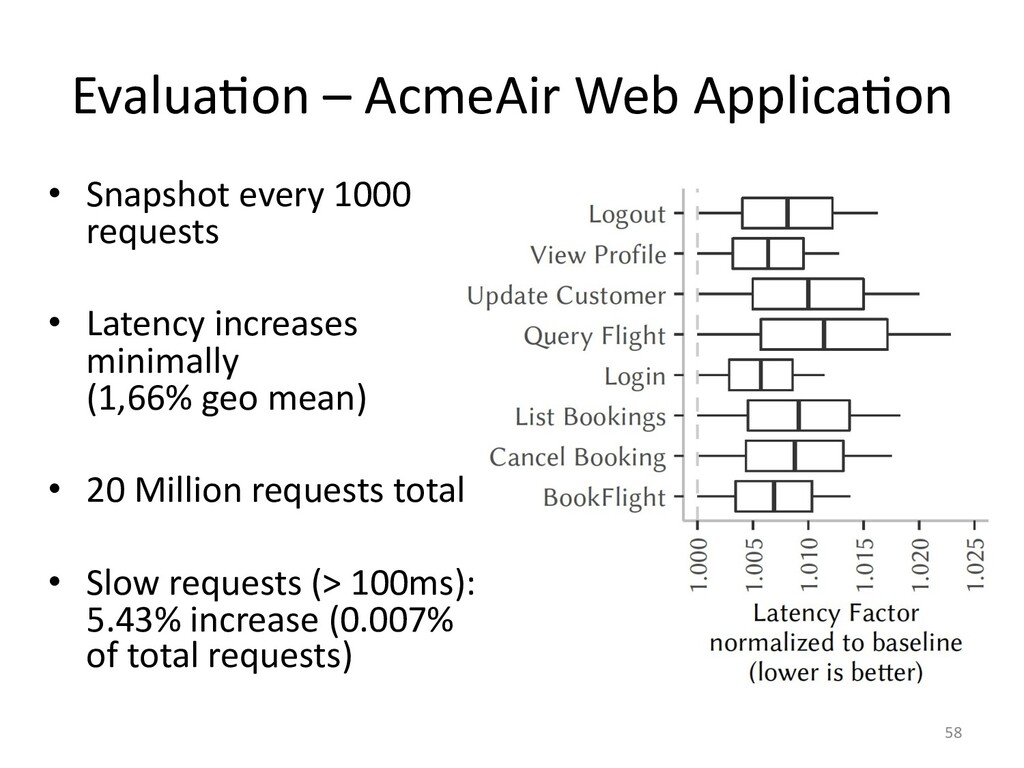
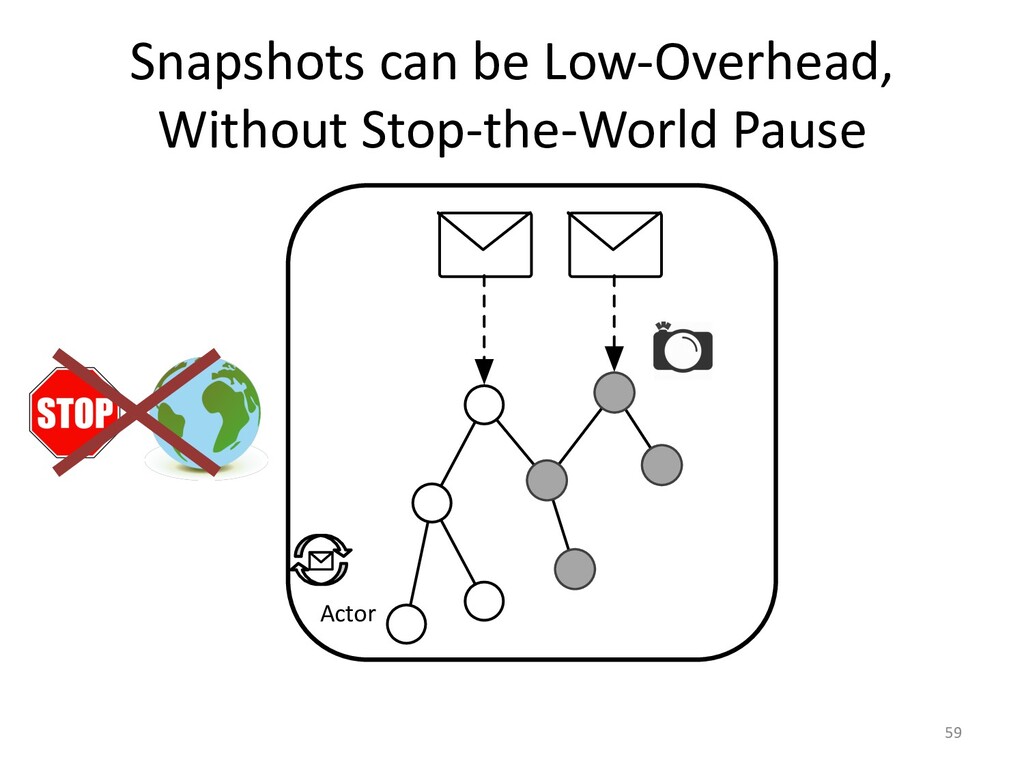
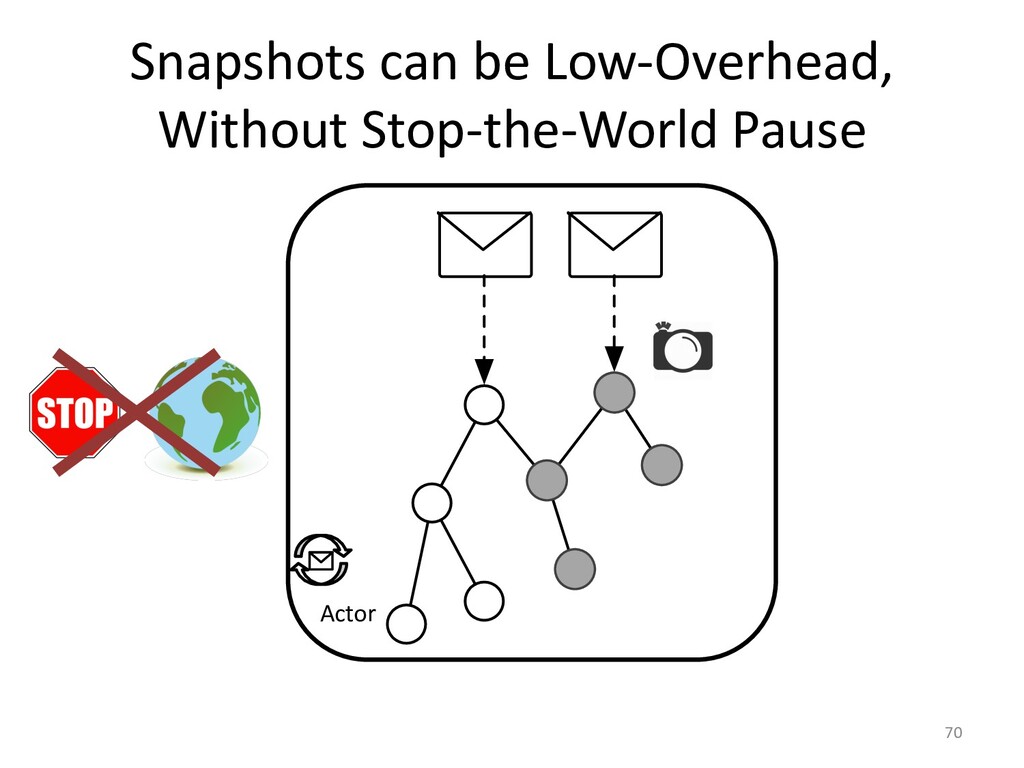
In the case of actor applications, we can even make the snapshotting fast
to be able to limit trace sizes.
Having better debugging capabilities is a real productivity boost.
Though, some bugs will always slip through the cracks.
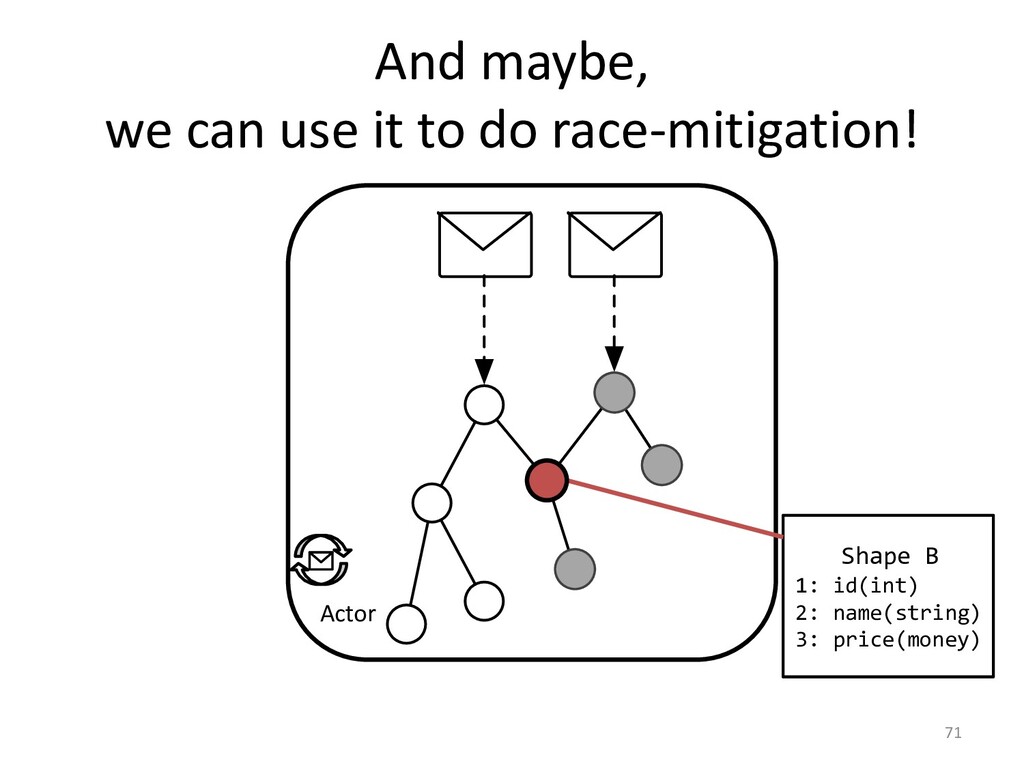
So, what if we could prevent those bugs from causing issues?
Other researchers have shown how to do it, and I'll conclude this talk
with some ideas on how we can utilize the knowledge we have in our
language implementations to make such mitigation approaches fast.
The talk is based on work done in collaboration with
Dominik Aumayr, Carmen Torres Lopez, Elisa Gonzalez Boix, and Hanspeter Mössenböck.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Detecting Snapshot Completion (2) 55 Msg [n-1] Msg [n-1] Msg](https://files.speakerdeck.com/presentations/54949b14853f48339e9be576942e4b01/slide_54.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}