Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
IP70_counterfactual_machine_learning
Search
SatokiMasuda
November 18, 2024
Research
84
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
IP70_counterfactual_machine_learning
第70回土木計画学研究発表会・秋大会の発表資料です。「反実仮想機械学習を用いた行動変容のための情報提供方策の最適化」
SatokiMasuda
November 18, 2024
More Decks by SatokiMasuda
See All by SatokiMasuda
IP73_LUTI_dynamic_game
stkmsd
0
34
hksts2025
stkmsd
1
60
ieee2025
stkmsd
0
58
ip71_contraflow_reconfiguration
stkmsd
0
170
kanazawa2024
stkmsd
0
69
hksts2024
stkmsd
0
72
ip68_LocationGame
stkmsd
0
55
ip67_MFDRL_evacuation
stkmsd
0
100
IP66_EvacuationLearning
stkmsd
0
68
Other Decks in Research
See All in Research
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.3k
Claude Code × autoresearch 実践
mathbullet
0
200
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
210
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
180
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
130
事後確率分布の共分散について
koide3
0
170
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4k
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
150
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
320
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
300
kintone リサーチ副部/UXリサーチャー 業務紹介
cybozuinsideout
PRO
0
100
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
430
Featured
See All Featured
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
800
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.2k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Building the Perfect Custom Keyboard
takai
2
810
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Transcript
反実仮想機械学習を⽤いた ⾏動変容のための情報提供⽅策の最適化 東京⼤学⼤学院博⼠2年 増⽥ 慧樹 ⽻藤 英⼆ 2024年11⽉16⽇ (⼟) 第70回⼟⽊計画学研究発表会・秋⼤会@岡⼭⼤学
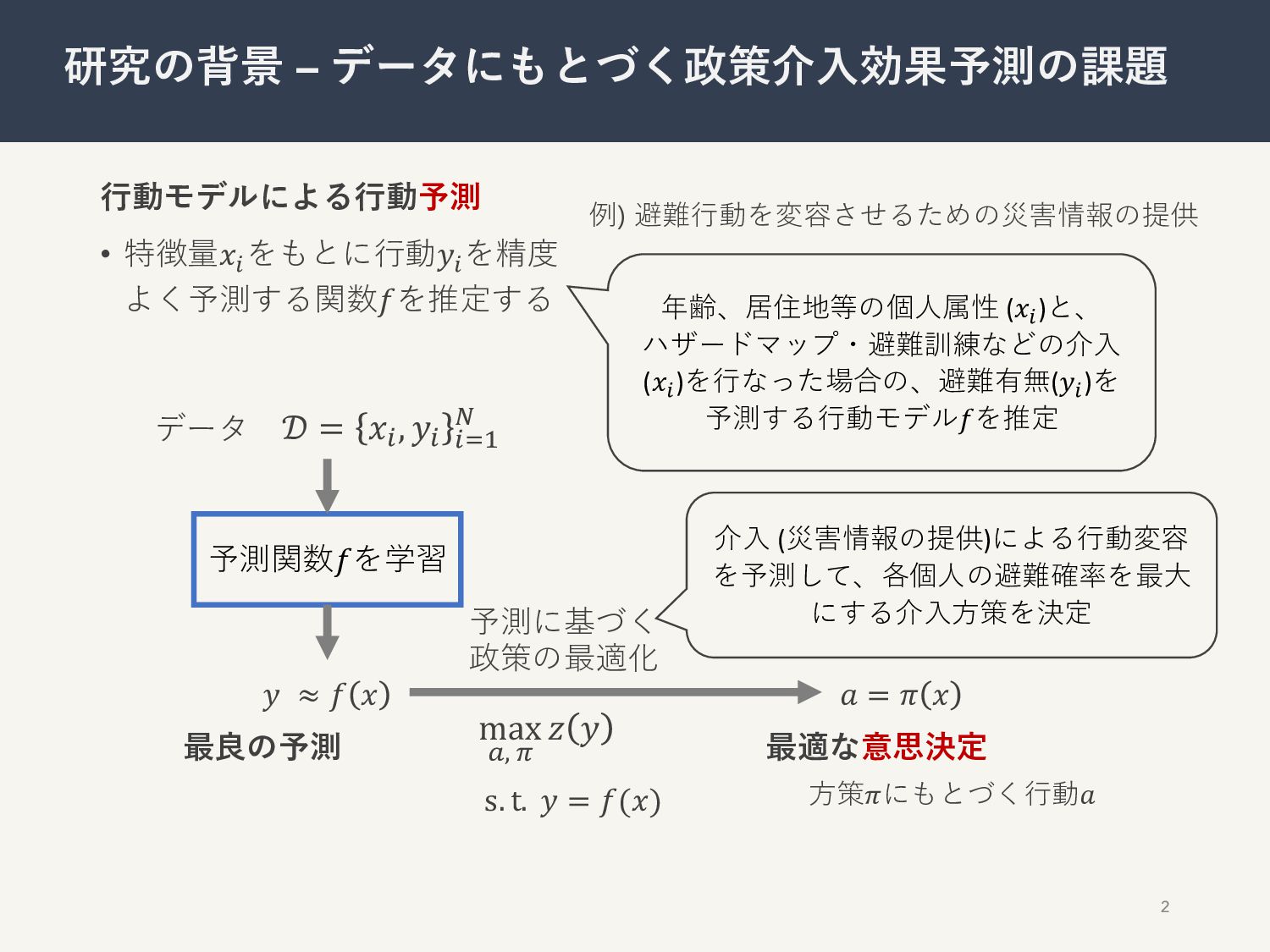
⾏動モデルによる⾏動予測 • 特徴量𝑥! をもとに⾏動𝑦! を精度 よく予測する関数𝑓を推定する 2 研究の背景 – データにもとづく政策介⼊効果予測の課題
𝒟 = 𝑥!, 𝑦! !"# $ 予測関数𝑓を学習 データ 𝑦 ≈ 𝑓 𝑥 𝑎 = 𝜋 𝑥 最適な意思決定 最良の予測 max %, ( 𝑧 𝑦 s. t. 𝑦 = 𝑓(𝑥) 年齢、居住地等の個⼈属性 (𝑥!)と、 ハザードマップ・避難訓練などの介⼊ (𝑥!)を⾏なった場合の、避難有無(𝑦!)を 予測する⾏動モデル𝑓を推定 介⼊ (災害情報の提供)による⾏動変容 を予測して、各個⼈の避難確率を最⼤ にする介⼊⽅策を決定 予測に基づく 政策の最適化 ⽅策𝜋にもとづく⾏動𝑎 例) 避難⾏動を変容させるための災害情報の提供
⾏動モデルによる⾏動予測 • 特徴量𝑥! をもとに⾏動𝑦! を精度 よく予測する関数𝑓を推定する 3 研究の背景 – データにもとづく政策介⼊効果予測の課題
⾏動履歴を⽤いた意思決定の最適設計 • 特徴量𝑥! 、介⼊𝑎! 、⾏動𝑦! の履歴が 得られたとき、期待報酬を最⼤化す る⽅策𝜋を求める 𝒟 = 𝑥!, 𝑦! !"# $ 𝒟 = 𝑥!, 𝑎!, 𝑦! !"# $ 予測関数𝑓を学習 ⽅策関数𝜋を直接学習 データ データ 𝑦 ≈ 𝑓 𝑥 𝑎 = 𝜋 𝑥 最適な意思決定 最良の予測 max ), ( 𝑧 𝑦 s. t. 𝑦 = 𝑓(𝑥) 予測に基づく 政策の最適化 反実仮想機械学習、オフ⽅策評価・学習
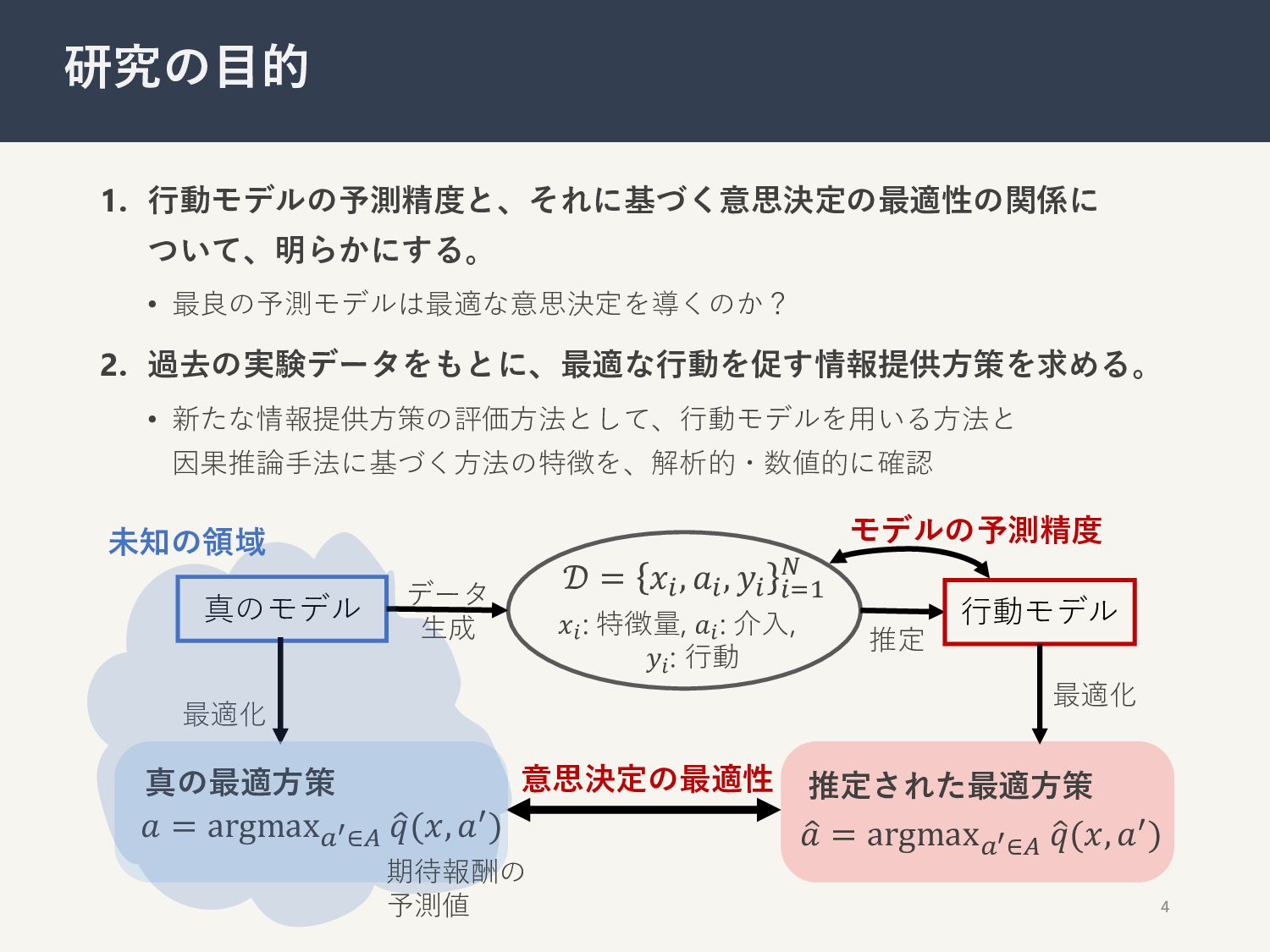
1. ⾏動モデルの予測精度と、それに基づく意思決定の最適性の関係に ついて、明らかにする。 • 最良の予測モデルは最適な意思決定を導くのか? 2. 過去の実験データをもとに、最適な⾏動を促す情報提供⽅策を求める。 • 新たな情報提供⽅策の評価⽅法として、⾏動モデルを⽤いる⽅法と 因果推論⼿法に基づく⽅法の特徴を、解析的・数値的に確認
4 研究の⽬的 真のモデル 𝑥! : 特徴量, 𝑎! : 介⼊, 𝑦! : ⾏動 𝒟 = 𝑥!, 𝑎!, 𝑦! !"# $ データ ⽣成 最適化 最適化 意思決定の最適性 真の最適⽅策 𝑎 = argmax%"∈+ . 𝑞(𝑥, 𝑎,) 推定された最適⽅策 . 𝑎 = argmax%"∈+ . 𝑞(𝑥, 𝑎,) ⾏動モデル 未知の領域 モデルの予測精度 推定 期待報酬の 予測値
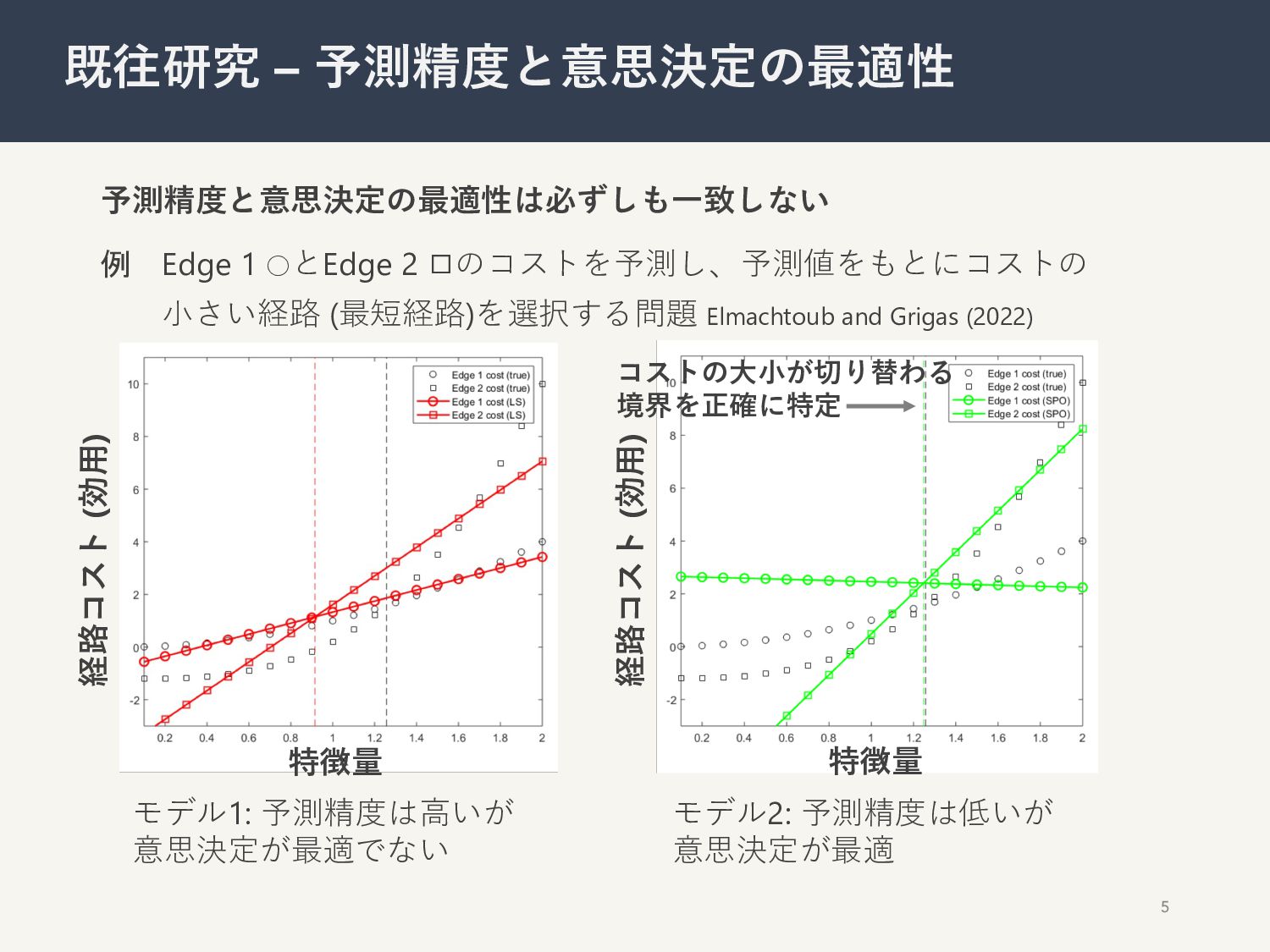
予測精度と意思決定の最適性は必ずしも⼀致しない 例 Edge 1 ◦とEdge 2 ◻のコストを予測し、予測値をもとにコストの ⼩さい経路 (最短経路)を選択する問題 Elmachtoub
and Grigas (2022) 5 既往研究 – 予測精度と意思決定の最適性 モデル1: 予測精度は⾼いが 意思決定が最適でない モデル2: 予測精度は低いが 意思決定が最適 コストの⼤⼩が切り替わる 境界を正確に特定 経路コスト (効⽤) 経路コスト (効⽤) 特徴量 特徴量
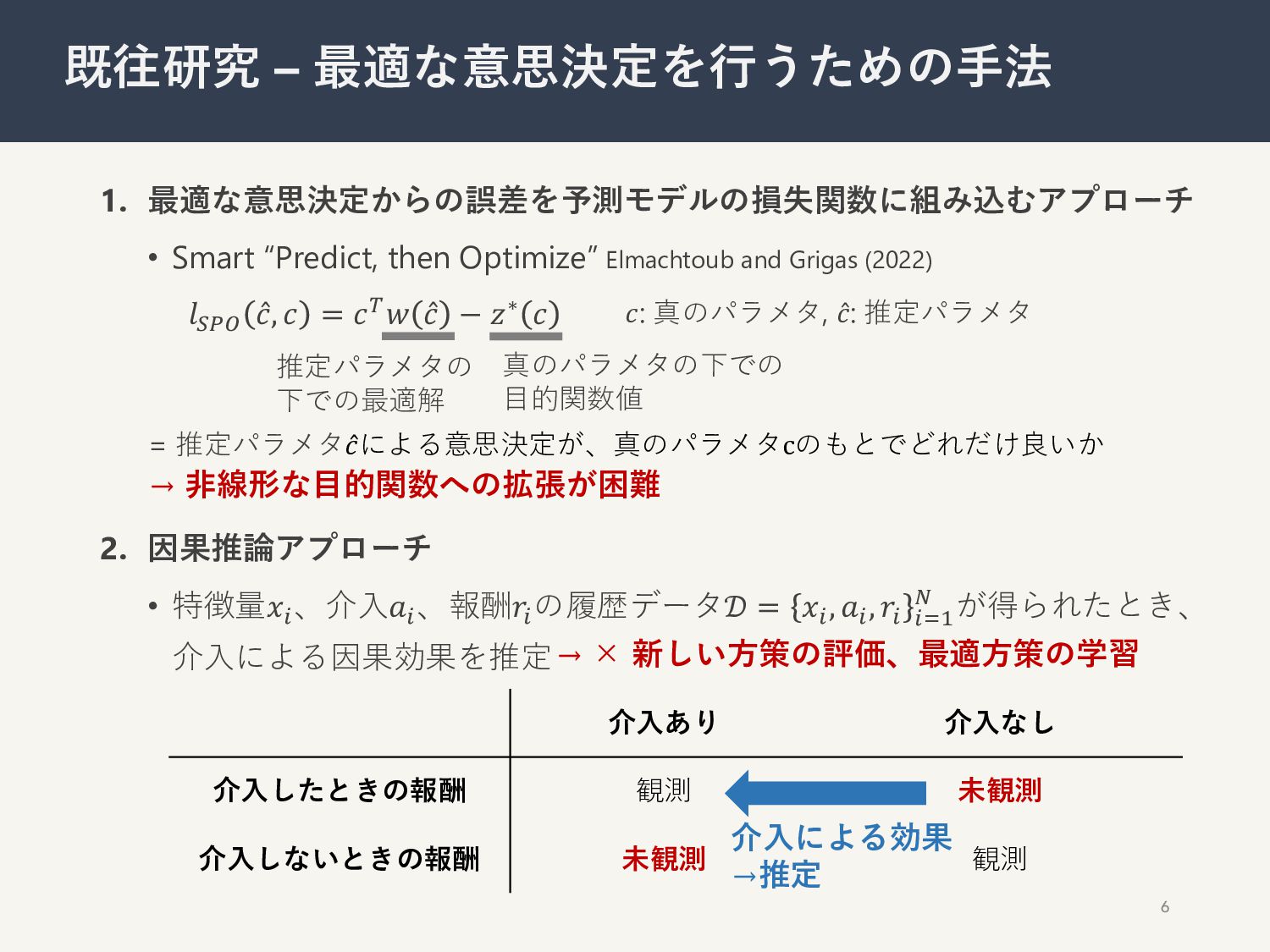
1. 最適な意思決定からの誤差を予測モデルの損失関数に組み込むアプローチ • Smart “Predict, then Optimize” Elmachtoub and Grigas
(2022) 6 既往研究 – 最適な意思決定を⾏うための⼿法 𝑙"#$ ̂ 𝑐, 𝑐 = 𝑐%𝑤 ̂ 𝑐 − 𝑧∗ 𝑐 𝑐: 真のパラメタ, ̂ 𝑐: 推定パラメタ 推定パラメタの 下での最適解 真のパラメタの下での ⽬的関数値 = 推定パラメタ ̂ 𝑐による意思決定が、真のパラメタcのもとでどれだけ良いか 介⼊あり 介⼊なし 介⼊したときの報酬 観測 未観測 介⼊しないときの報酬 未観測 観測 介⼊による効果 →推定 → ⾮線形な⽬的関数への拡張が困難 2. 因果推論アプローチ • 特徴量𝑥! 、介⼊𝑎! 、報酬𝑟! の履歴データ𝒟 = 𝑥! , 𝑎! , 𝑟! !'( ) が得られたとき、 介⼊による因果効果を推定→ × 新しい⽅策の評価、最適⽅策の学習
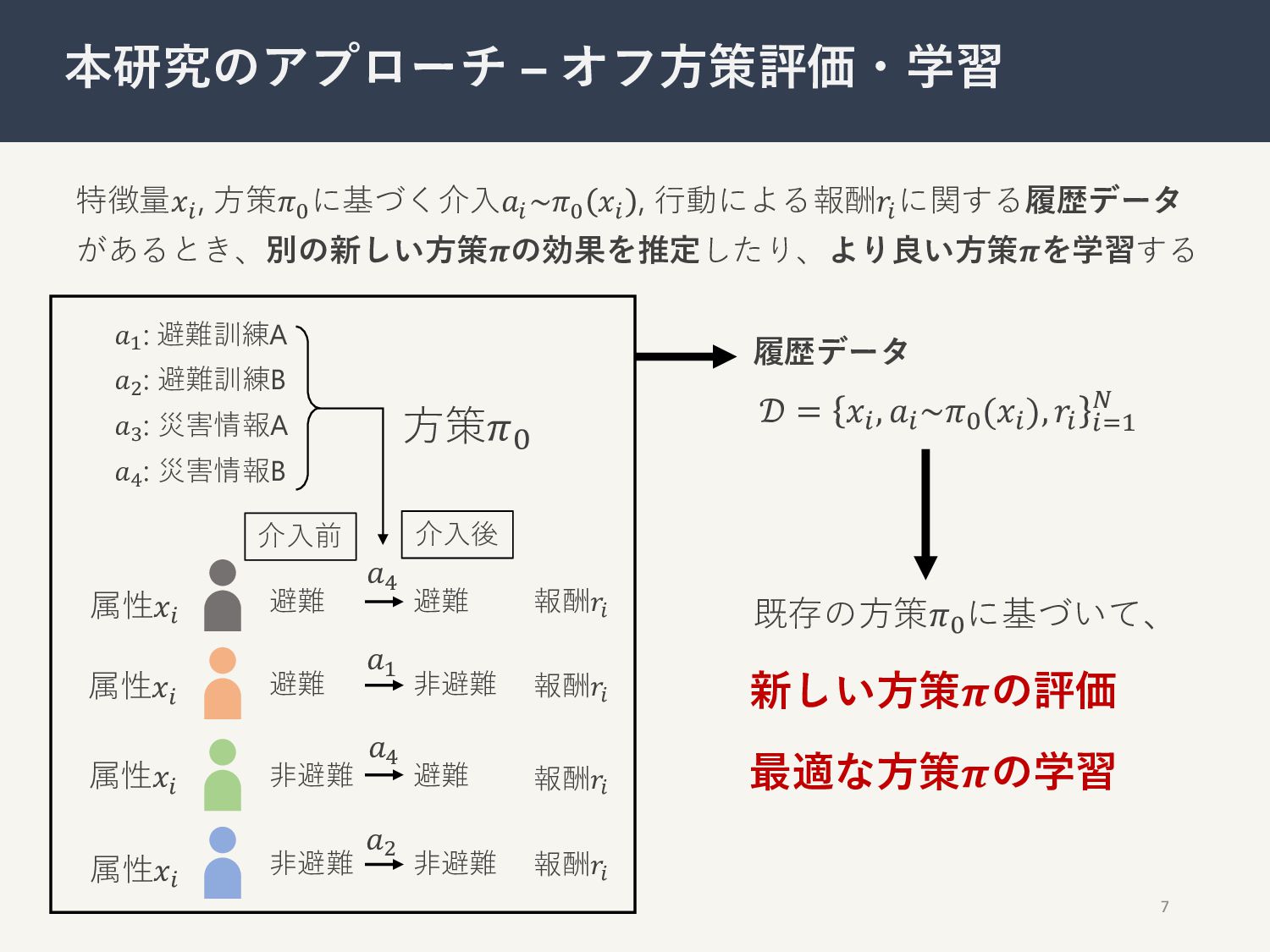
特徴量𝑥! , ⽅策𝜋* に基づく介⼊𝑎! ~𝜋* 𝑥! , ⾏動による報酬𝑟! に関する履歴データ があるとき、別の新しい⽅策𝝅の効果を推定したり、より良い⽅策𝝅を学習する
7 本研究のアプローチ – オフ⽅策評価・学習 介⼊前 介⼊後 避難 避難 𝑎+ 避難 ⾮避難 𝑎( ⾮避難 避難 𝑎+ ⾮避難 ⾮避難 𝑎, 𝑎# : 避難訓練A 𝑎$ : 災害情報A 𝑎% : 避難訓練B 𝑎& : 災害情報B 属性𝑥! 属性𝑥! 属性𝑥! 属性𝑥! ⽅策𝜋9 履歴データ 𝒟 = 𝑥!, 𝑎!~𝜋-(𝑥!), 𝑟! !"# $ 新しい⽅策𝝅の評価 最適な⽅策𝝅の学習 既存の⽅策𝜋- に基づいて、 報酬𝑟! 報酬𝑟! 報酬𝑟! 報酬𝑟!
• 新しい⽅策𝜋の性能𝑉(𝜋) 8 新⽅策𝝅の性能評価 報酬 特徴量𝑥と⾏動𝑎で条件 付けた報酬の期待値 この同時分布は未知 → データから𝑽(𝝅)を推定
→ 過去の履歴データに少量しか存在しない、または存在しない特徴量𝑥と 介⼊𝑎の組み合わせに対して、期待報酬をいかにうまく推定するかが課題 (因果推論の根本問題) 1. 予測モデルを⽤いる⽅法 (Direct Method推定量) 2. ⾏動の重み付けを⽤いる⽅法 (Inverse Propensity Score推定量) 3. 1と2を組み合わせる⽅法 (Doubly Robust推定量)
9 新⽅策𝝅の性能評価 – Direct Method推定量 • 真の性能𝑉(𝜋)に対する推定量; 𝑉(𝜋)の平均⼆乗誤差は、バイアス (𝑉(𝜋)と ;
𝑉(𝜋)の差)とバリアンス (; 𝑉(𝜋)のばらつき)に分解できる 期待報酬関数𝒒(𝒙, 𝒂)の推定モデル → 特徴量𝑥, 𝑎を⼊⼒とし、⾏動𝑦 (=報酬𝑟) を予測する⾏動モデル = 期待報酬の経験平均 ①推定モデルと真の 期待報酬関数のズレ ③予測値のバラつき ②データ数 誤差に影響する要因: ⾏動モデルの予測精度が悪い場合や、予測値のばらつきが⼤きい場合は、 新⽅策𝝅の性能を正しく評価できない
• 履歴データに少ないが新⽅策でよく選択される⾏動→ 重み⼤ • 履歴データに多いが、新⽅策であまり選択されない⾏動→ 重み⼩ • バイアスとバリアンス • Bias
= 0 → 𝑉(𝜋)に対する不偏推定量 • Variance 10 新⽅策𝝅の性能評価 – Inverse Propensity Score推定量 既存⽅策𝝅𝟎 と新⽅策𝝅についての 介⼊𝒂𝒊 の選択確率の⽐ ※ 共通サポートの仮定のもとで成⽴ 全ての𝑥, 𝑎について、𝜋 𝑎 𝑥 > 0 ⇒ 𝜋# 𝑎 𝑥 > 0 既存⽅策と新⽅策の⾏動選択確率の差が⼤きい場合 (𝒘⼤)、 バリアンスが拡⼤してしまうおそれ
11 新⽅策𝝅の性能評価 – Doubly Robust推定量 • バイアスとバリアンス • Bias =
0 → 𝑉(𝜋)に対する不偏推定量 • Variance = DM推定量とIPS推定量の組み合わせ IPS推定量の不偏性を継承しながら、バリアンスを低く抑えることが可能 DM推定量 IPS推定量と同様 に、 報酬を𝑤で重みづけ IPS推定量との違い −4 𝑞(𝑥, 𝑎)だけバリアンス低減
最良の予測モデルは最適な意思決定を導くのか? 12 数値実験1 真のモデル Masuda & Ikegai (2024) 避難有無・時間・場所の選択を Discounted
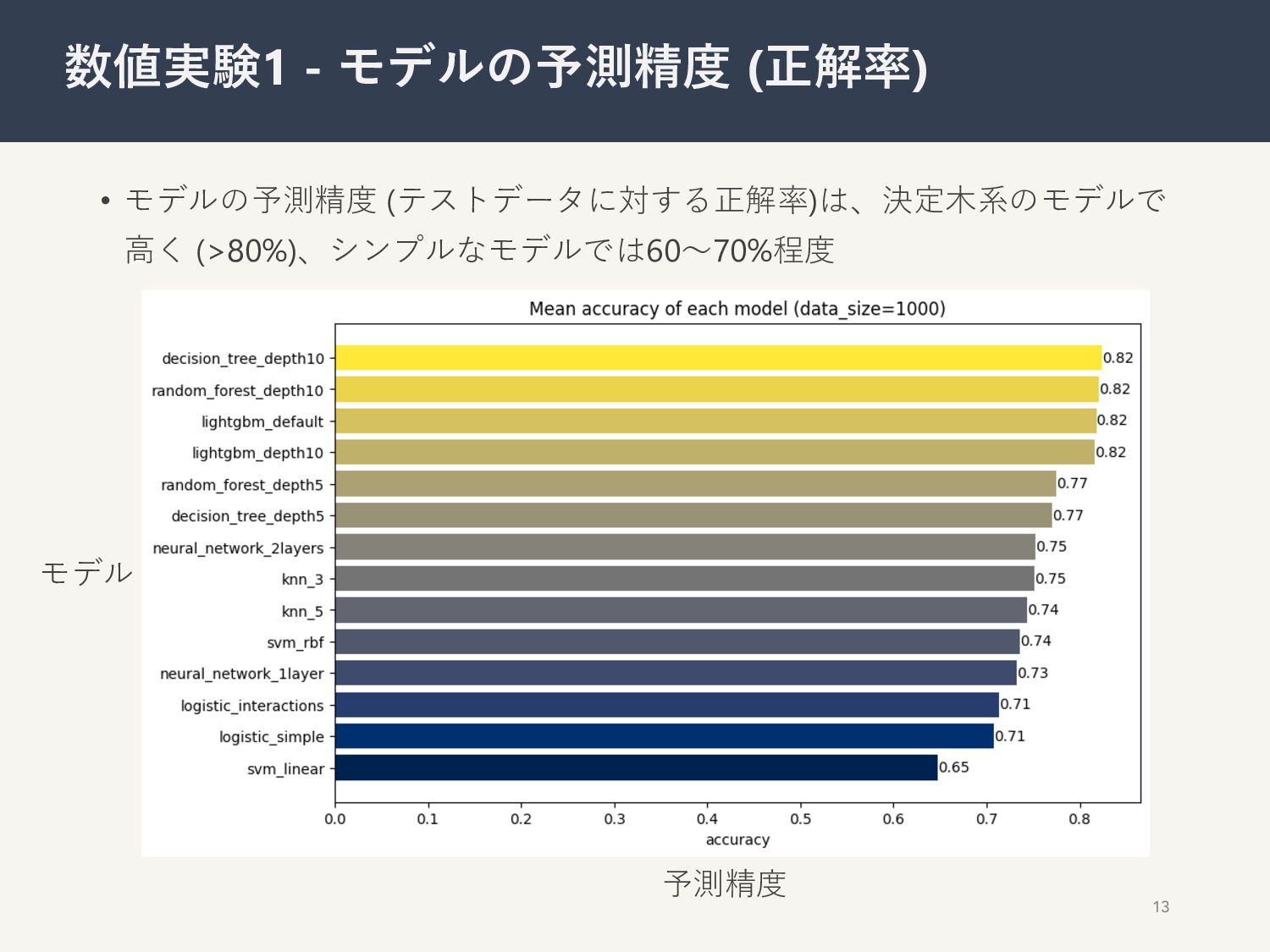
RLモデルで表現 𝑥! : ⾃宅浸⽔深、元の避難意向 𝑎! : 避難訓練、ハザードマップ 𝑦! : 避難の有無 𝒟 = 𝑥!, 𝑎!, 𝑦! !"# $ データ⽣成 学習 14種の⾏動モデル MNL(2次の交互作⽤あり/なし), ランダムフォレスト (深さ5, 10), サポートベクタマシン (線形, ガウス), k近傍法 (近傍3, 5), ニューラルネットワーク (1層、2層), LightGBM (深さ上限なし、上限10), 決定⽊ (深さ5, 10) 推定された最適⽅策 𝑎 = argmax%"∈+ . 𝑞(𝑥, 𝑎,) ⽅策学習 ⽅策学習 真の最適⽅策 𝑎 = argmax%"∈+ . 𝑞(𝑥, 𝑎,) 意思決定の最適性を確認 各個⼈への情報提供3種類 予測精度を確認 1000データ
• モデルの予測精度 (テストデータに対する正解率)は、決定⽊系のモデルで ⾼く (>80%)、シンプルなモデルでは60〜70%程度 13 数値実験1 - モデルの予測精度 (正解率)
モデル 予測精度
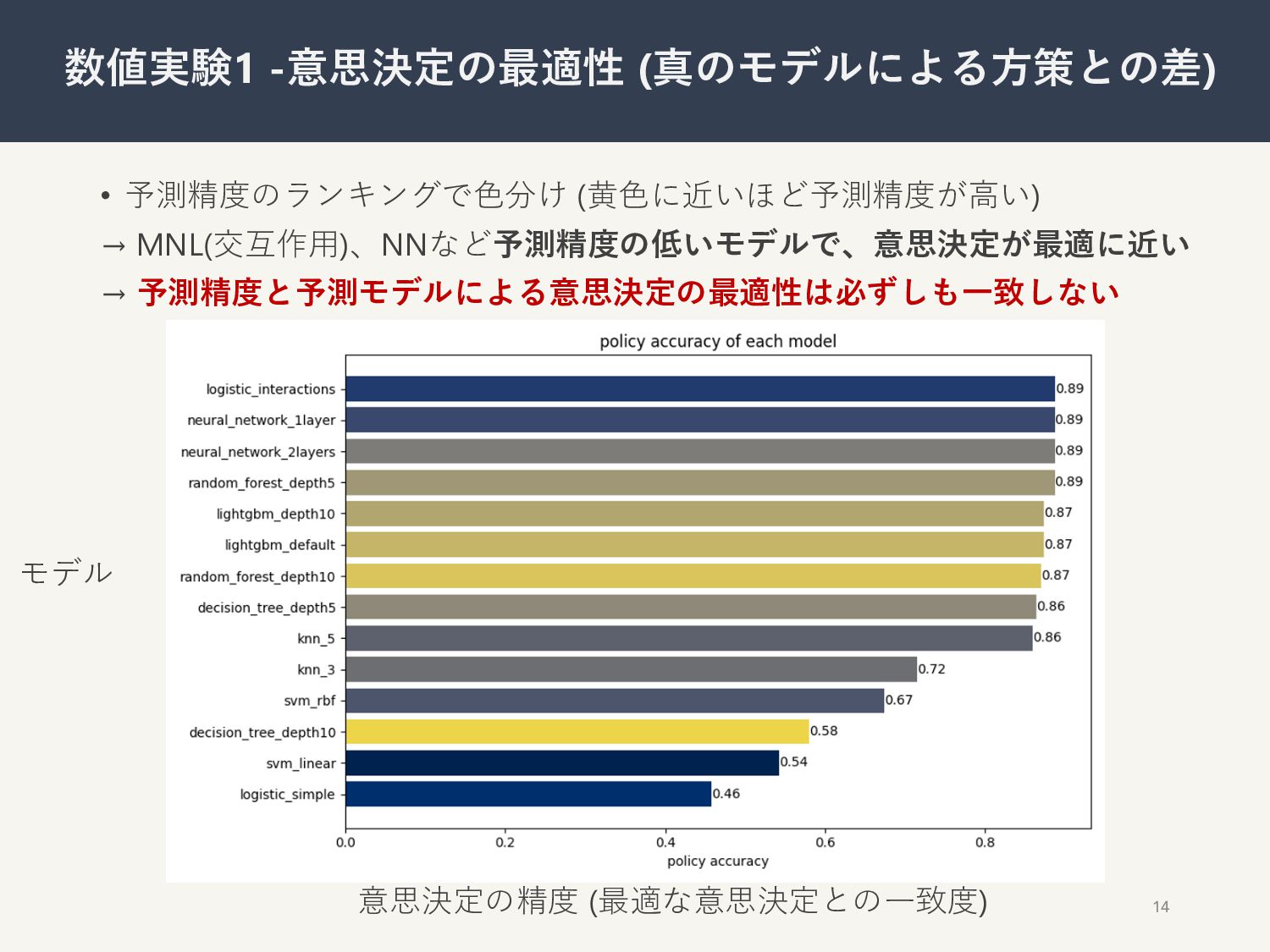
• 予測精度のランキングで⾊分け (⻩⾊に近いほど予測精度が⾼い) → MNL(交互作⽤)、NNなど予測精度の低いモデルで、意思決定が最適に近い → 予測精度と予測モデルによる意思決定の最適性は必ずしも⼀致しない 14 数値実験1 -意思決定の最適性
(真のモデルによる⽅策との差) 意思決定の精度 (最適な意思決定との⼀致度) モデル
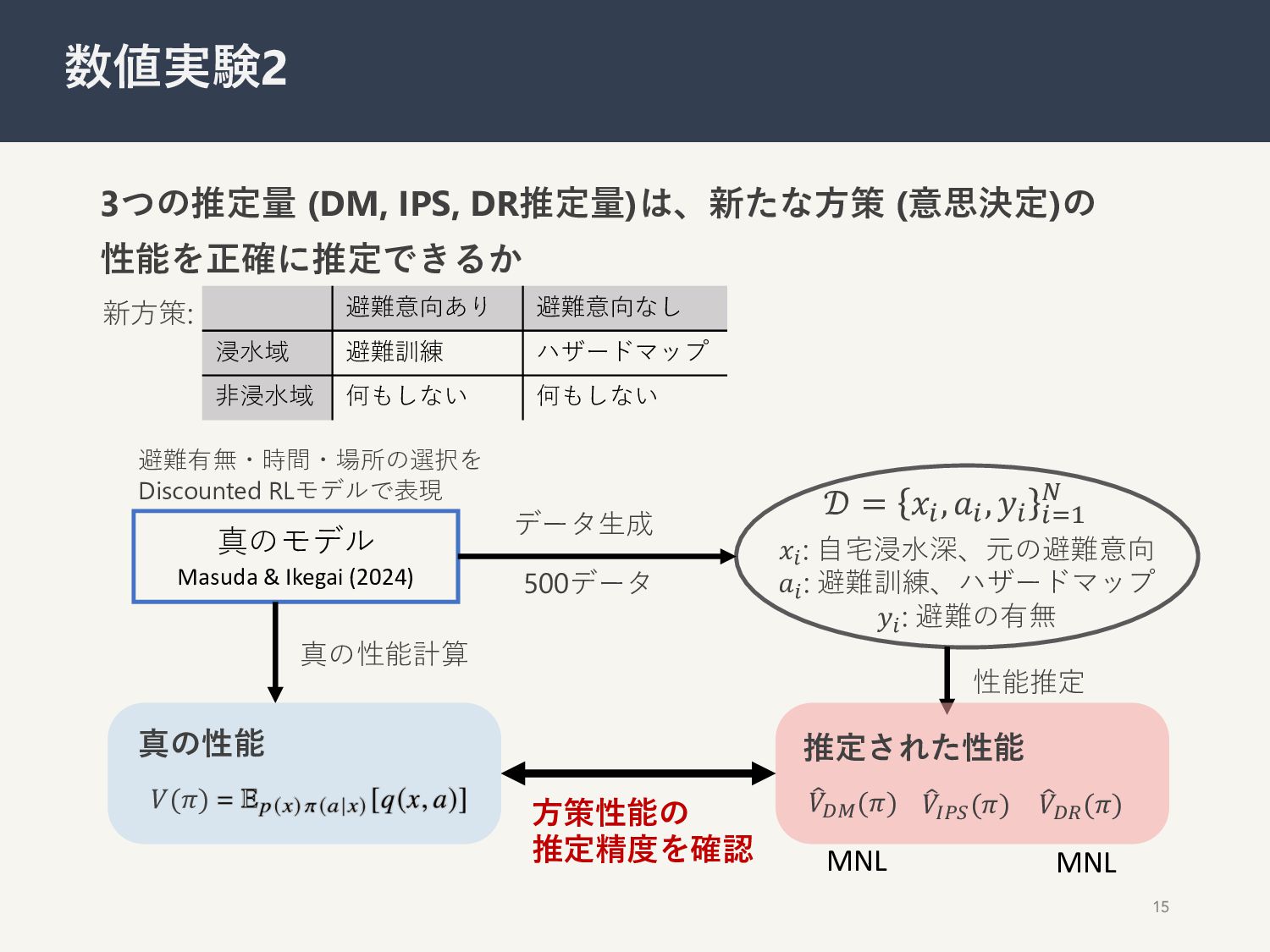
3つの推定量 (DM, IPS, DR推定量)は、新たな⽅策 (意思決定)の 性能を正確に推定できるか 15 数値実験2 真のモデル Masuda
& Ikegai (2024) 避難有無・時間・場所の選択を Discounted RLモデルで表現 𝑥! : ⾃宅浸⽔深、元の避難意向 𝑎! : 避難訓練、ハザードマップ 𝑦! : 避難の有無 𝒟 = 𝑥!, 𝑎!, 𝑦! !"# $ データ⽣成 性能推定 MNL 推定された性能 真の性能計算 ⽅策性能の 推定精度を確認 真の性能 𝑉(𝜋) 7 𝑉'((𝜋) 7 𝑉)*+ (𝜋) 7 𝑉', (𝜋) MNL 新⽅策: 避難意向あり 避難意向なし 浸⽔域 避難訓練 ハザードマップ ⾮浸⽔域 何もしない 何もしない 500データ
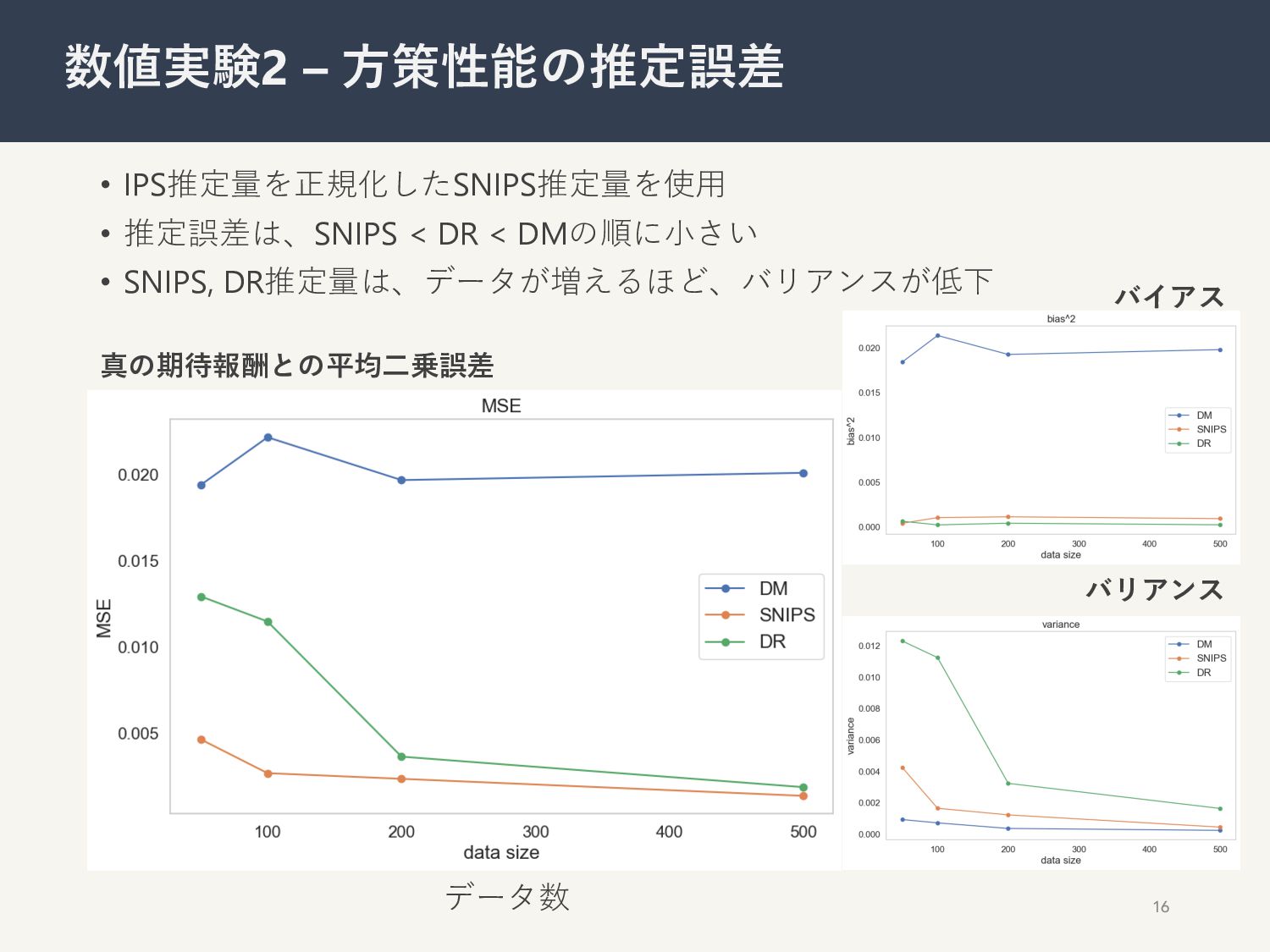
• IPS推定量を正規化したSNIPS推定量を使⽤ • 推定誤差は、SNIPS < DR < DMの順に⼩さい • SNIPS,
DR推定量は、データが増えるほど、バリアンスが低下 16 数値実験2 – ⽅策性能の推定誤差 真の期待報酬との平均⼆乗誤差 バイアス バリアンス データ数
◼ 本研究のまとめ • オフ⽅策評価・学習の⼿法を援⽤し、過去の介⼊の履歴データから、新たな ⽅策の性能を評価・学習する枠組みを整理 • 最良のモデルは、最適な意思決定と結びつかない可能性がある → 適切な推定量を⽤いて、⽅策の評価・学習を直接⾏うアプローチの可能性 ◼
今後の課題 • 予測精度と意思決定の最適性についての、さらなる分析 • 予測モデルの複雑さ?⾏動の複雑さ?予測値の分散? • ⽅策の⻑期性能の評価 → 介⼊効果の忘却や強化の評価 • ⾏動の種類や数が増加した場合の、最適⽅策の学習 → 介⼊の有無だけでなく、介⼊内容の詳細をデザインする⼿法の開発 例) 情報提供の⽂⾔、⽂書レイアウト、避難訓練の⾏程など 17 結論
真のモデルから500回サンプリング→予測モデルの学習→⽅策最適化を20回反復 →複雑な決定⽊系のモデルでモデルの予測精度が⾼い傾向 19 数値実験1 – 異なるデータセットでの検証
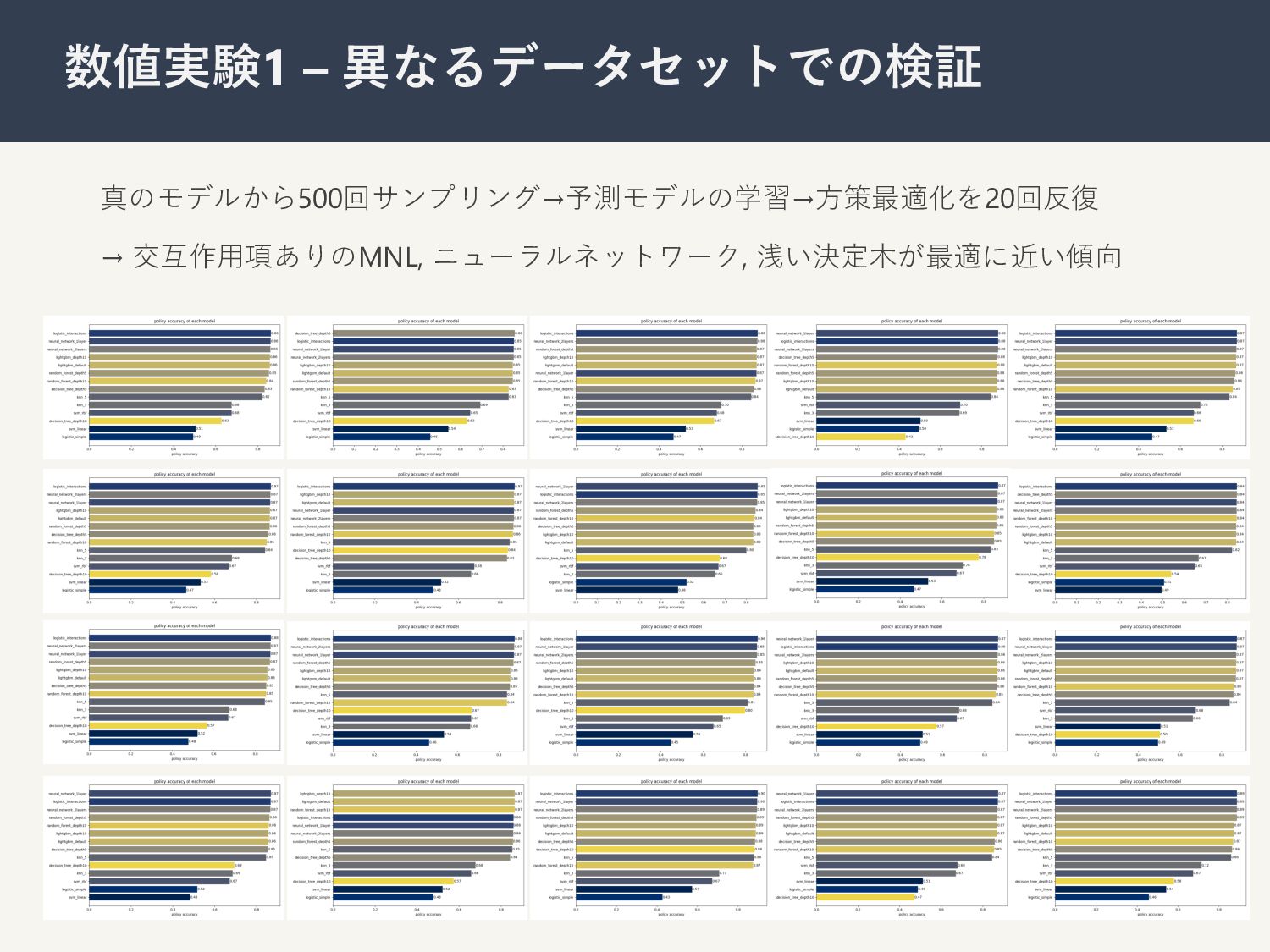
真のモデルから500回サンプリング→予測モデルの学習→⽅策最適化を20回反復 → 交互作⽤項ありのMNL, ニューラルネットワーク, 浅い決定⽊が最適に近い傾向 20 数値実験1 – 異なるデータセットでの検証
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}