Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
運転動画を検索可能にする〜Cosmos-Embed1とDatabricks Vector Se...
Search
開発室Graph
April 28, 2026
Programming
1.2k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
運転動画を検索可能にする〜Cosmos-Embed1とDatabricks Vector Searchで〜/cosmos-embed1-databricks-vector-search
Search Engineering Tech Talk 2026 Spring で発表
開発室Graph
April 28, 2026
More Decks by 開発室Graph
See All by 開発室Graph
AWSで実現した大規模日本語VLM学習用データセット "MOMIJI" 構築パイプライン/buiding-momiji
studio_graph
2
1.5k
技術を楽しもう/enjoy_engineering
studio_graph
1
590
めちゃくちゃ悩んでクックパッドに新卒入社して1年経った/newgrads_event2020
studio_graph
7
5.7k
クックパッドでの機械学習開発フロー/ml-ops-in-cookpad
studio_graph
9
15k
DWHを活用した機械学習プロジェクト/ml-with-dwh
studio_graph
6
5.3k
無理をしない機械学習プロジェクト2/step_or_not2
studio_graph
9
11k
知識グラフのリンク予測におけるGANを用いたネガティブサンプルの生成
studio_graph
4
4.2k
機械学習を使ったレシピ調理手順の識別
studio_graph
2
2.2k
Other Decks in Programming
See All in Programming
Laravelで学ぶ Webアプリケーションチューニング入門/web_application_tuning_101
hanhan1978
4
1.4k
AIが無かった頃の素敵な出会いの話
codmoninc
1
280
2年かけて Deno に DOMMatrix を実装した話 / How I implemented DOMMatrix in Deno over two years
petamoriken
0
180
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
1.1k
作るコストが小さくなった時代 幸せに働くために改めて考えたいこと 〜エンジニアとして価値を出し続けるために注視している二分野〜
yuppeeng
0
140
改善しないと、タスクが回らない。 “てんこ盛りポジション” を引き継いだ情シスの、入社3ヶ月の業務改善録
krm963
0
230
React本体のコードリーディング
high_g_engineer
0
110
php-fpmのプロセスが枯渇した日-調査・対処・そして本当にやるべきだったこと-
shibuchaaaan
0
170
ソフトウェア設計に溶けるインフラ ― AWS CDK のインフラ認識論
konokenj
3
710
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
160
信頼性について考えてみる(SRE NEXT 2026 miniLT)
hayama17
0
230
変わらないものが、変わるものを決める — 意図駆動開発 × イベントソーシング × イミュータブル | What Doesn't Change Decides What Can — IDD × Event Sourcing × Immutability
tomohisa
0
730
Featured
See All Featured
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
540
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.8k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
470
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Believing is Seeing
oripsolob
1
170
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1.1k
Navigating Team Friction
lara
192
16k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
930
Designing Powerful Visuals for Engaging Learning
tmiket
1
470
Practical Orchestrator
shlominoach
191
11k
Transcript
運転動画を検索可能にする @stu3dio_graph Turing株式会社 シニアソフトウェアエンジニア 〜 Cosmos-Embed1 と Databricks Vector Search
による設計と実装 〜 1
もくじ • ⾃⼰紹介, チューリングについて • 「ほしいシーンが⾒つからない」問題への対策 • Cosmos-Embed1 とは? •
アーキテクチャと設計ポイント ◦ フレーム画像抽出 ◦ ⽇次Embedding計算 ◦ Databricks DLT と Vector Search ◦ テキスト検索⽤Lambda ◦ 社内ツールへの統合 • まとめ 2
チューリングについて E2E⾃動運転(フィジカルAI)を内製開発する⽇本のスタートアップ Turing平和島ラボ前景 ⼭本⼀成 2021年8⽉ 東京都⼤⽥区平和島 約100名(アルバイト含む) 240億円 会社概要 代表取締役:
創業: 本社: 従業員数: 累計調達額: E2Eモデルでの運転の様⼦ 3
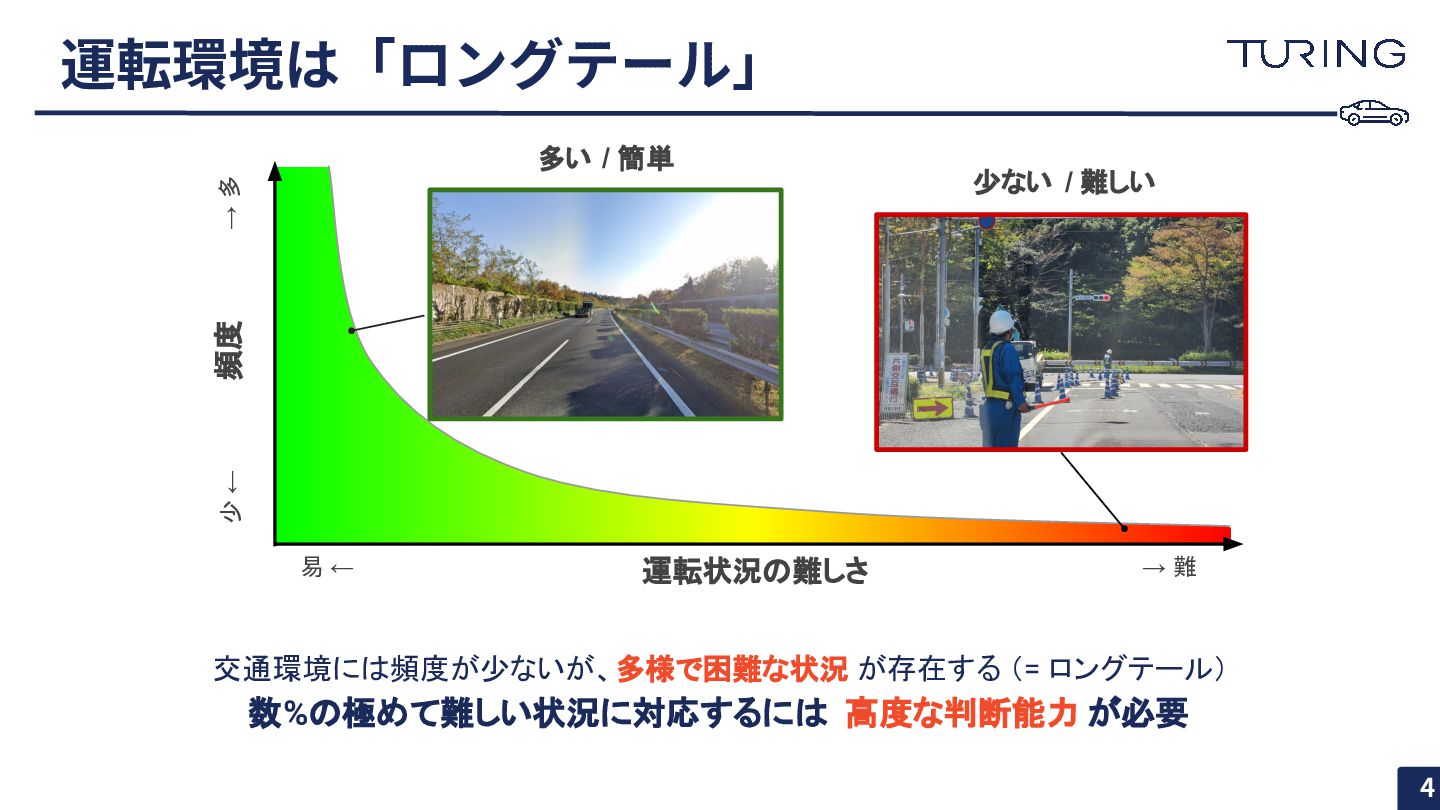
運転環境は「ロングテール」 運転状況の難しさ 頻度 少 ← → 難 易 ← →
多 多い / 簡単 少ない / 難しい 交通環境には頻度が少ないが、多様で困難な状況 が存在する (= ロングテール) 数%の極めて難しい状況に対応するには 高度な判断能力 が必要 4
ほしいシーン*が⾒つからない問題 • 数万時間規模の運転動画が蓄積 • 既存の検索⼿段は⽇次/⾞両ID/地図など • 映像の中⾝ベースで探す⼿段がなかった ◦ 交差点での歩⾏者横断 ◦
道路⼯事を避けて⾞線変更 ◦ ⻩⾊信号で進⼊ ◦ 歩⾏者が⾶び出してきた • データが増えれば増えるほど深刻化 5 シーン*: ⾛⾏動画を20秒ごとに分割した単位。
3チームからの同時多発的な要望 6 シナリオテスト拡充 クエリからシーンを ⾃動取得してシナリオ更新したい シナリオ作成チーム 学習データ品質管理 路駐避け‧⻩⾊信号などを ⼤量データから探したい アノテーションチーム
モデル挙動分析 モデルが苦⼿なシーンを 系統的に集めたい 強化学習チーム 共通項: 映像の中⾝をキーにシーンを探したい
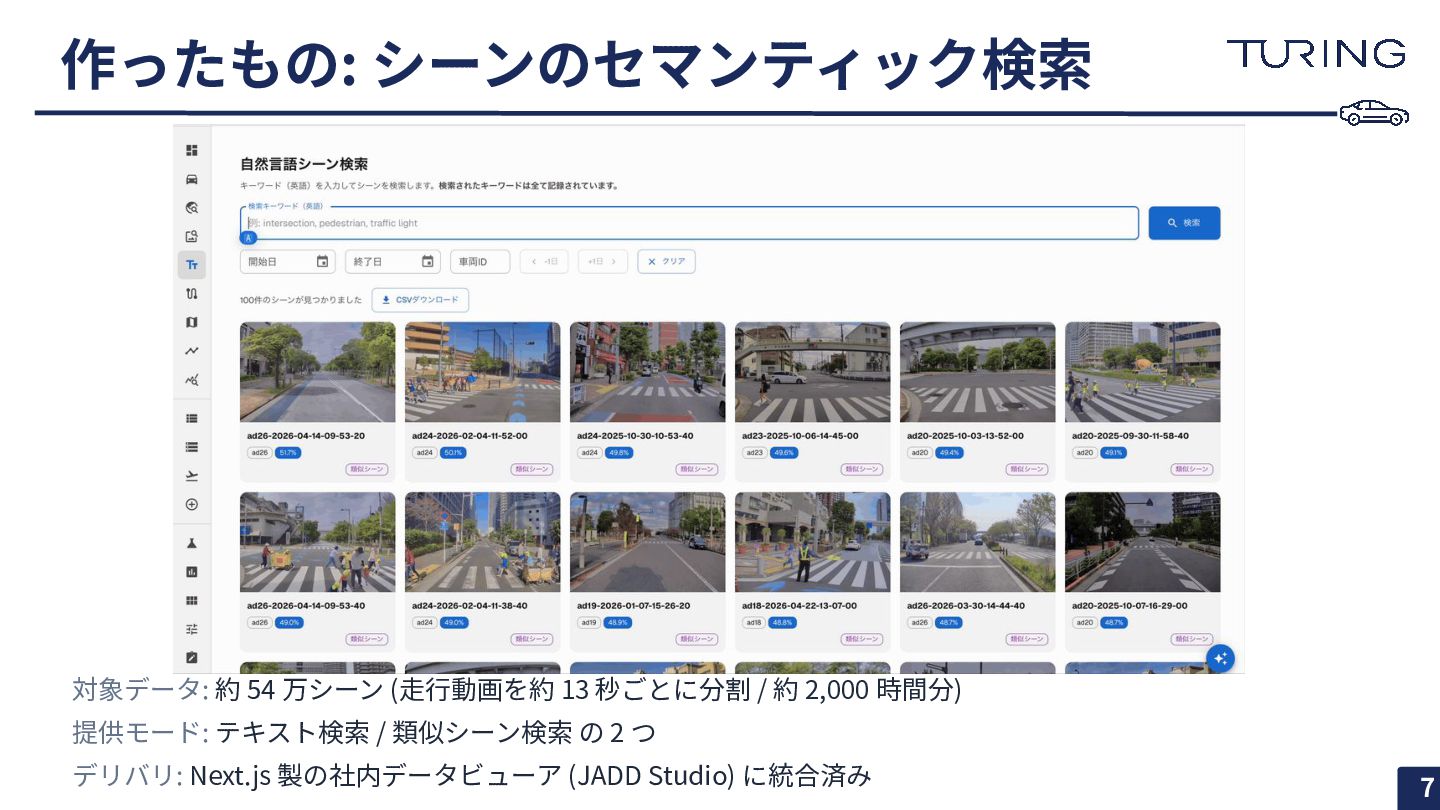
作ったもの: シーンのセマンティック検索 7 対象データ: 約 54 万シーン (⾛⾏動画を約 13 秒ごとに分割
/ 約 2,000 時間分) 提供モード: テキスト検索 / 類似シーン検索 の 2 つ デリバリ: Next.js 製の社内データビューア (JADD Studio) に統合済み
なぜ今作れるようになったか? • ベクトル検索⾃体は何年も前からある技術 • 過去はインデックス構築〜UIまでの運⽤が重い ◦ ⼀部エンジニアだけが触る状態で定着せず • 2つの要素技術の登場で,UIレベルへ落とし込めた 8
① Cosmos-Embed1 • ドメイン特化モデルで検索精度が⾶躍 • ⾃動運転データセットで顕著な性能向上 ② Databricks Vector Search の成熟 • Delta Table 統合でインデックス運⽤が激減 • 既存メタデータをそのまま使える
Cosmos-Embed1 とは? • NVIDIA が 2025 年に公開 • 10 億パラメータの
video-text joint embedding モデル • 映像とテキストを 同⼀ベクトル空間 に射影 • 学習データ: 約 800 万動画 ◦ OpenDV (⾃動運転) / AgiBot / BridgeV2 など 物理世界データセットを含む • 物理世界 (⾃動運転‧ロボット) のデータに特化 • NVIDIA Cosmos プラットフォームの⼀部として商⽤利⽤可 9
なぜ Cosmos-Embed1 を選んだか? 10 モデル OpenDV T2V-R@1 (⾃動運転データセット) Kinetics-400 F1
(汎⽤動画認識) Cosmos-Embed1-448p 34.66% 88.21% InternVideo2-1B 7.40% 62.80% • AV データセット (OpenDV) で 約 4.7 倍 の精度 • CLIP は画像単体の embedding → 時系列の動きを捉えられない ため不適 • ⾛⾏シーンは「⾞線変更」「右折」「歩⾏者の横断」など 動き が 意味を持つ ◦ フレーム列を直接⼊⼒できる Cosmos-Embed1 を採⽤ ※ 8 フレーム等間隔サンプリング、DSL rerank 適⽤時の値 (Cosmos-Embed1-448p Model Card より)
⼤きいモデルなら勝てるのか? • Qwen3-VL-Embedding-8B も検証 ◦ Cosmos-Embed1 の 約 8 倍
のパラメータ • ⾛⾏動画で「intersection (交差点)」すら正しく識別できない • 推論時間‧メモリは⼤幅増 • 汎⽤モデルとしては優秀でも、⾛⾏シーンに特化した embedding が出ない • 汎⽤モデルのスケールアップが必ずしもドメインタスクの向上に は繋がらない 11
Databricks Notebook でのPoC • 1 ⾛⾏ (約 1 時間) 分のシーンから試した
• 「waiting pedestrians」で検索 → きちんと該当シーンが取れる • 既存 Delta Table のメタデータ (⾞両 ID / ⽇時) をそのまま活⽤ • embedding を parquet に変換 → Vector Search Index 作成まで Notebook 上の 数⼗⾏で完結 ◦ 社内展開もかなり楽 • インフラ構築ゼロ で本格検索まで到達 12
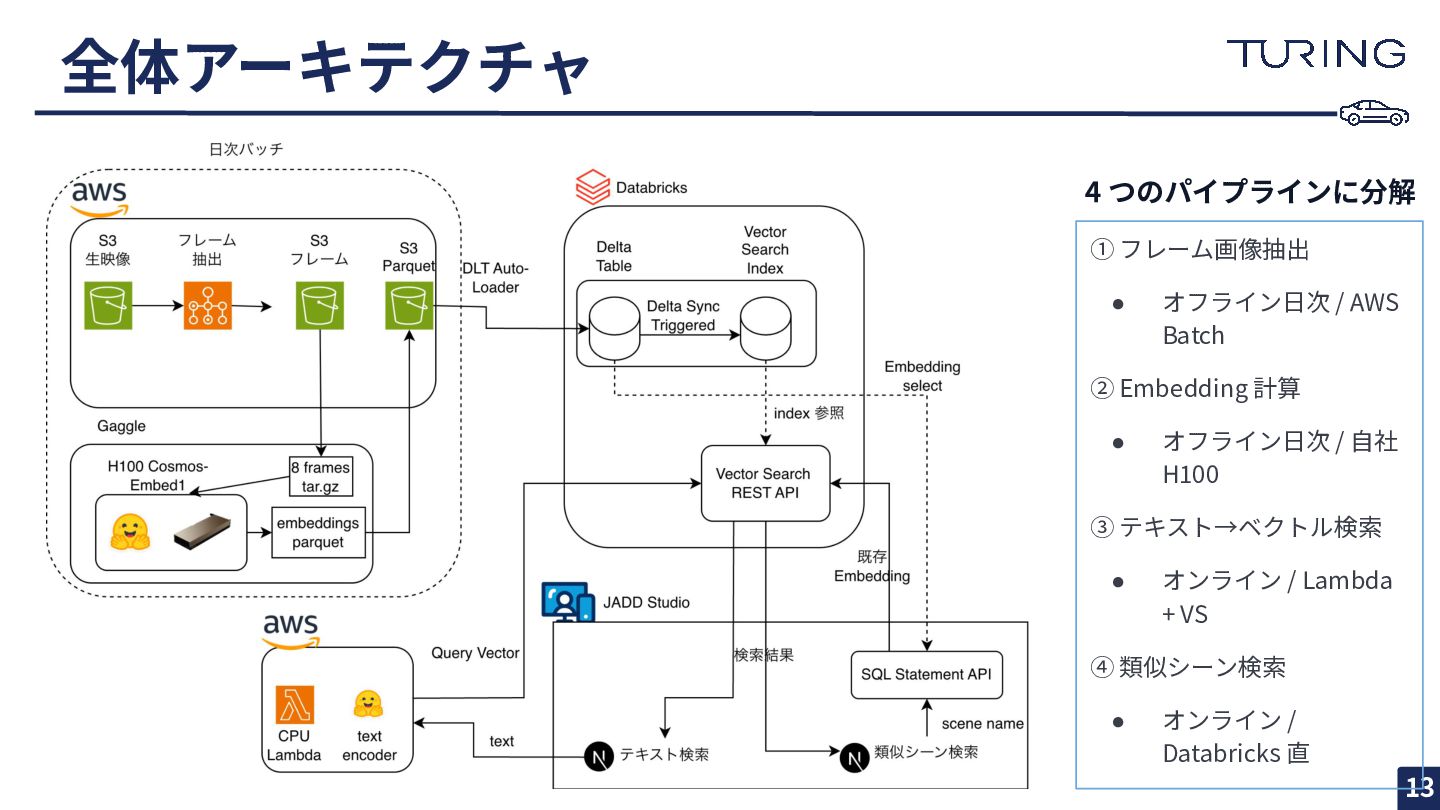
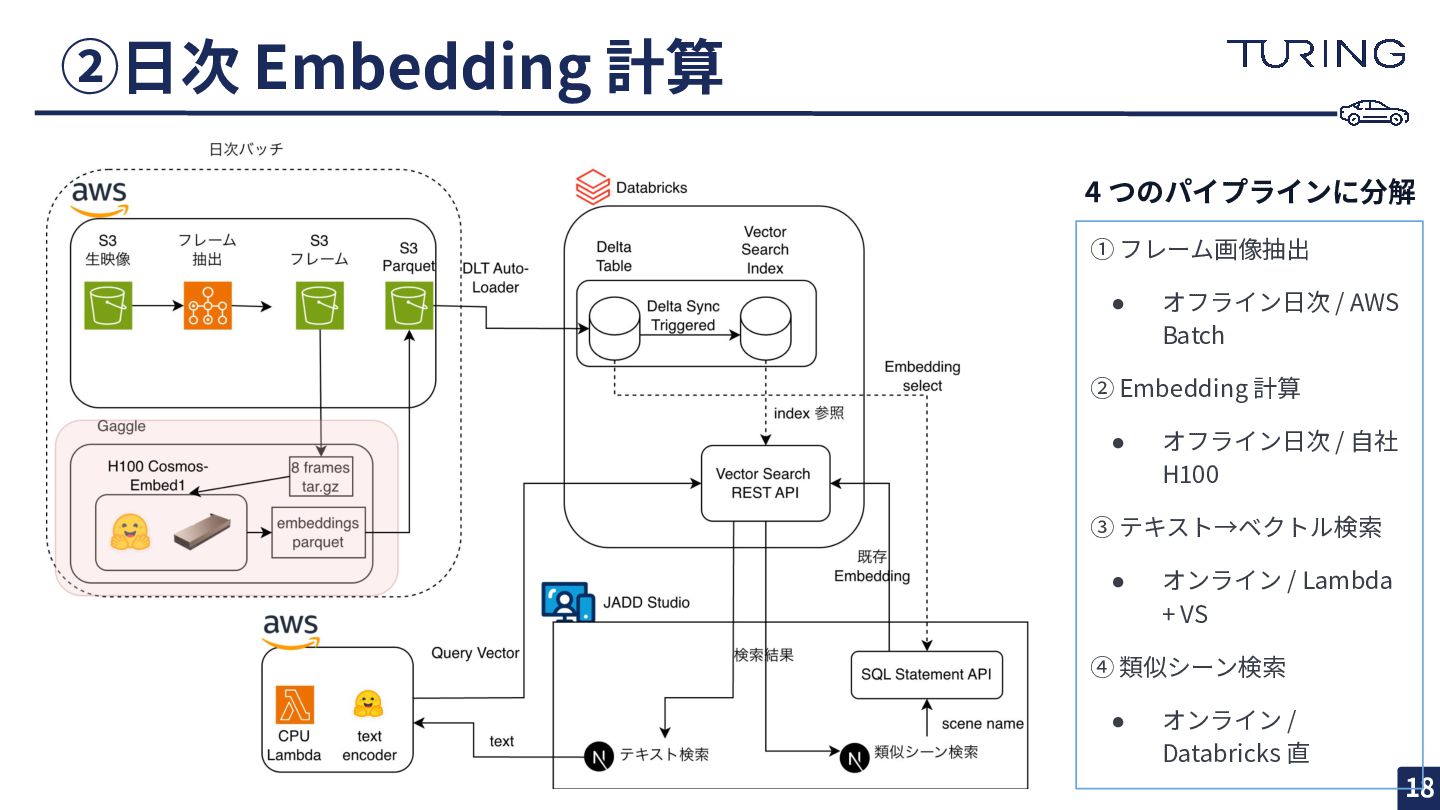
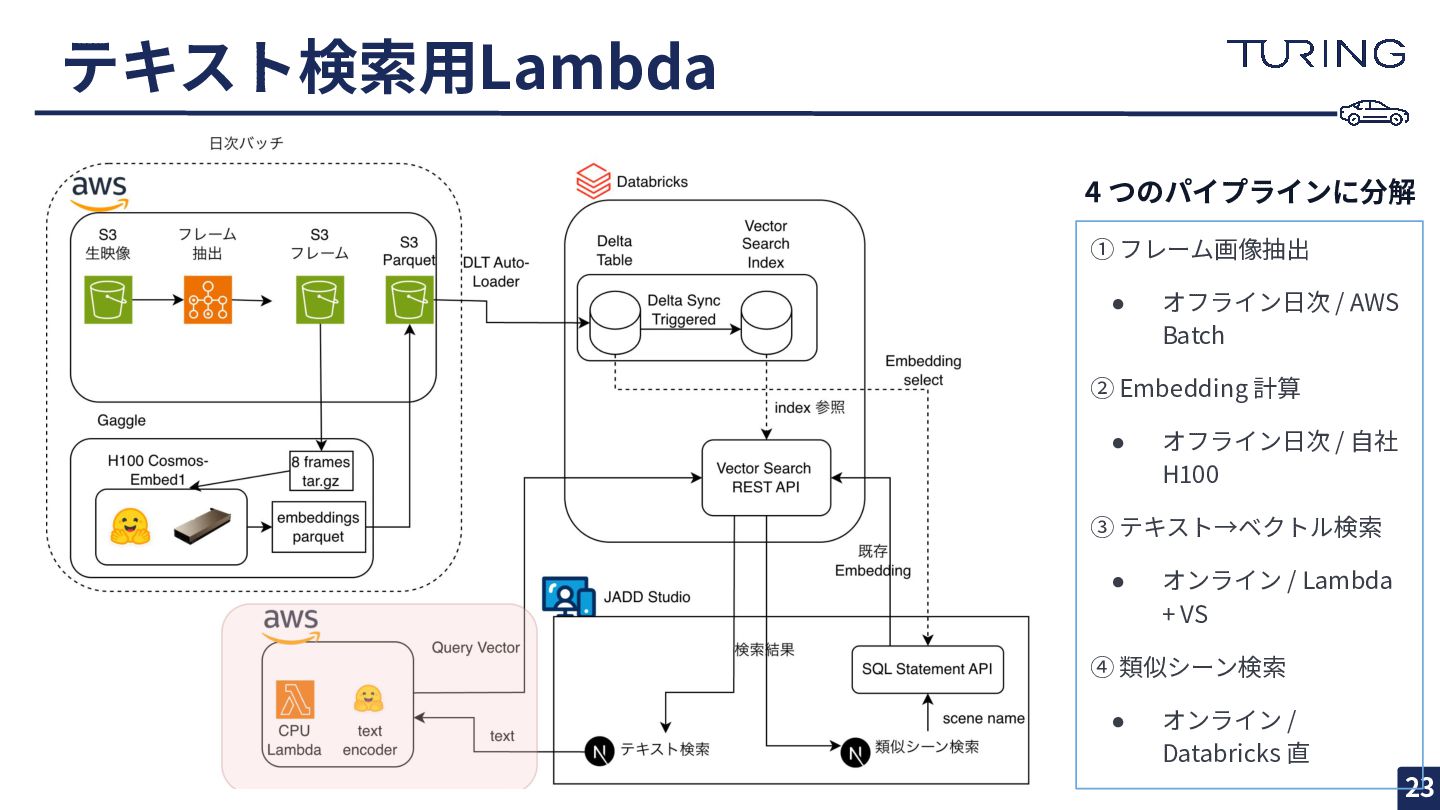
全体アーキテクチャ 13 ① フレーム画像抽出 • オフライン⽇次 / AWS Batch ②
Embedding 計算 • オフライン⽇次 / ⾃社 H100 ③ テキスト→ベクトル検索 • オンライン / Lambda + VS ④ 類似シーン検索 • オンライン / Databricks 直 4 つのパイプラインに分解
設計ポイント: 計算コストの⾮対称性 14 🎥 Video Embedding • GPU 必須‧重い •
リアルタイムで毎回計算は⾮現実的 • 事前計算してインデックスへ • GPU コストはバッチ分のみ 📝 Text Embedding • CPU で数百 ms • text-encoder のみ使えば軽量 • リアルタイムで都度計算 • 検索体験はリアルタイム維持 • Video Embedding と Text Embedding の計算コストは⼤きく違う ◦ 同じ扱いをしないのが肝 • 「モデル推論が必要か」で経路を分岐 ◦ テキスト検索: Lambda経由 ◦ 類似シーン検索: Databricks直接 (embeddingはすでにDelta Table)
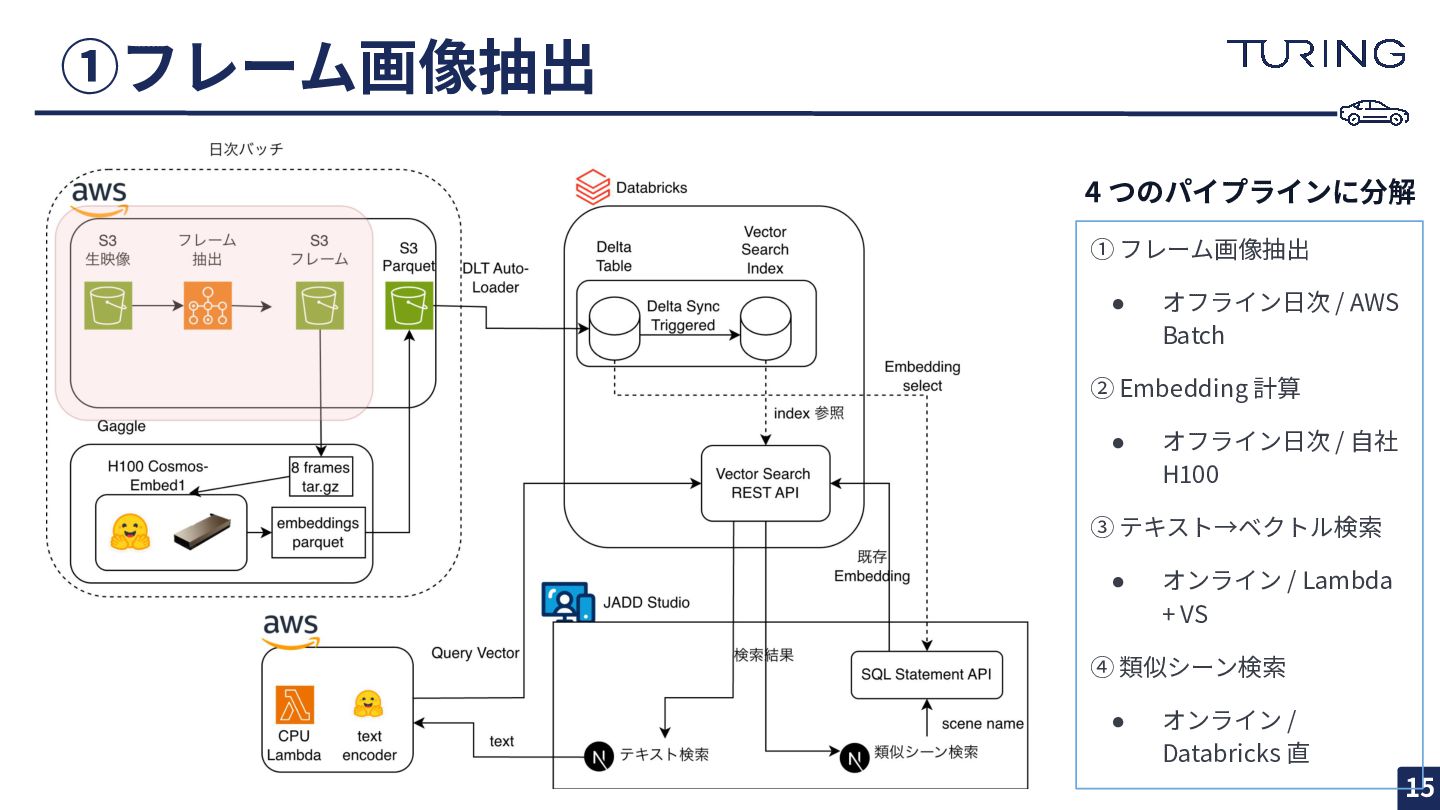
①フレーム画像抽出 15 ① フレーム画像抽出 • オフライン⽇次 / AWS Batch ②
Embedding 計算 • オフライン⽇次 / ⾃社 H100 ③ テキスト→ベクトル検索 • オンライン / Lambda + VS ④ 類似シーン検索 • オンライン / Databricks 直 4 つのパイプラインに分解
デコードが思ったより遅い 16 • 当初は「映像 → embedding」を 1 パイプラインで構想 • 実際に計測してみると
動画デコードの⽅が GPU 推論より重い 局 ⾯があった • GPU を確保してデコードに使うのは贅沢 ボトルネック分離 Fargate CPU でデコード H100 で推論専念 再利⽤性 フレームを切り出しておけば モデル差し替え時にやり直し不要
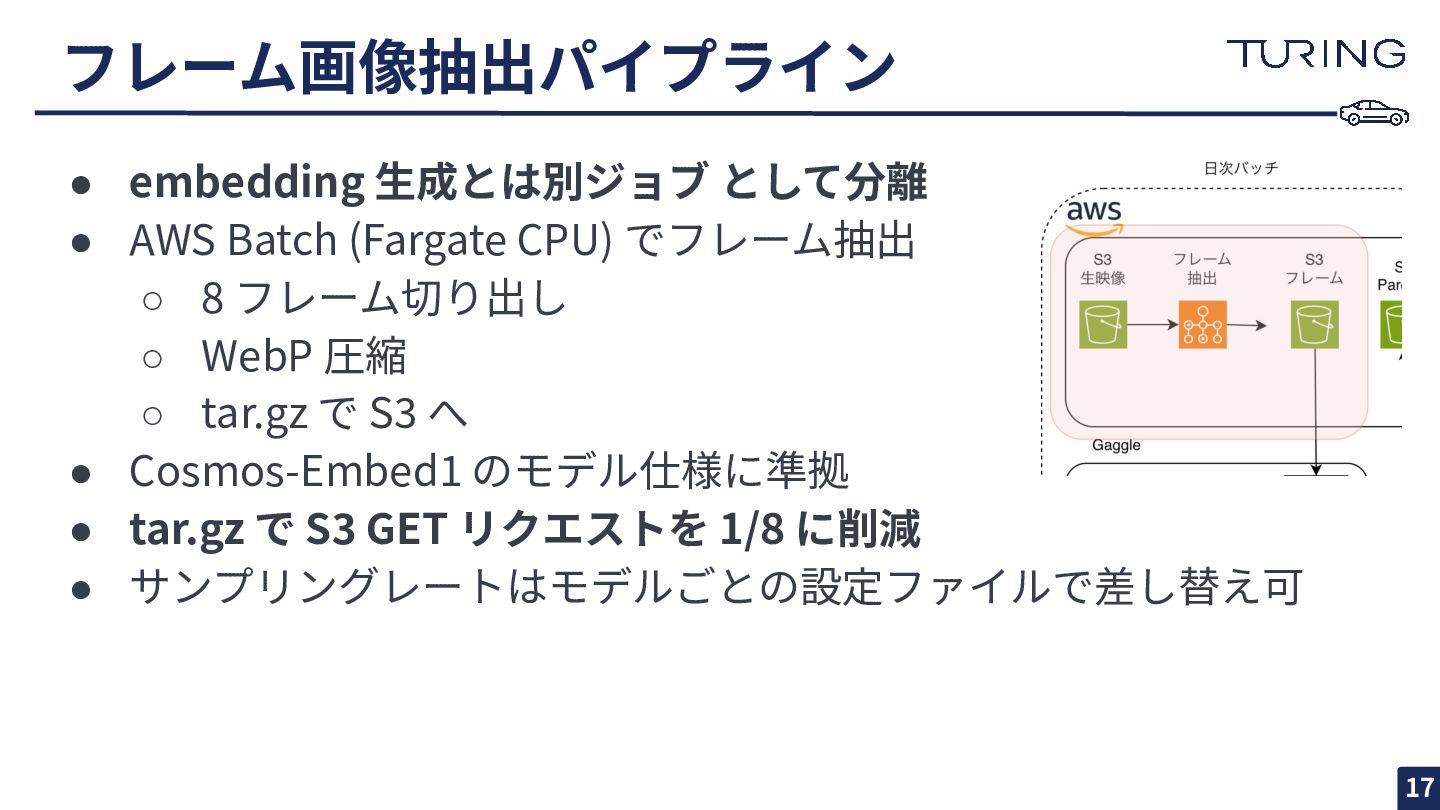
フレーム画像抽出パイプライン 17 • embedding ⽣成とは別ジョブ として分離 • AWS Batch (Fargate
CPU) でフレーム抽出 ◦ 8 フレーム切り出し ◦ WebP 圧縮 ◦ tar.gz で S3 へ • Cosmos-Embed1 のモデル仕様に準拠 • tar.gz で S3 GET リクエストを 1/8 に削減 • サンプリングレートはモデルごとの設定ファイルで差し替え可
②⽇次 Embedding 計算 18 ① フレーム画像抽出 • オフライン⽇次 / AWS
Batch ② Embedding 計算 • オフライン⽇次 / ⾃社 H100 ③ テキスト→ベクトル検索 • オンライン / Lambda + VS ④ 類似シーン検索 • オンライン / Databricks 直 4 つのパイプラインに分解
⽇次 Embedding 計算: オンプレ H100 + Slurm 19 • Gaggle
(社内 GPU クラスタ) で平均 10 シーン/秒 • AWS P5 オンデマンドより オンプレが圧倒的に安い • 毎⽇ 2:00 に Slurm ジョブ起動 → 学習と競合せず • 未処理シーン検出 ◦ S3 上の tar.gz と Parquet の集合差分 だけ • GPUを使い切るために ◦ ボトルネックはS3からのtar.gzダウンロード ▪ Producer-Consumer で次3バッチを先読み ◦ ディスクを経由せず直接メモリに展開 ▪ I/O 待ちを最⼩化する
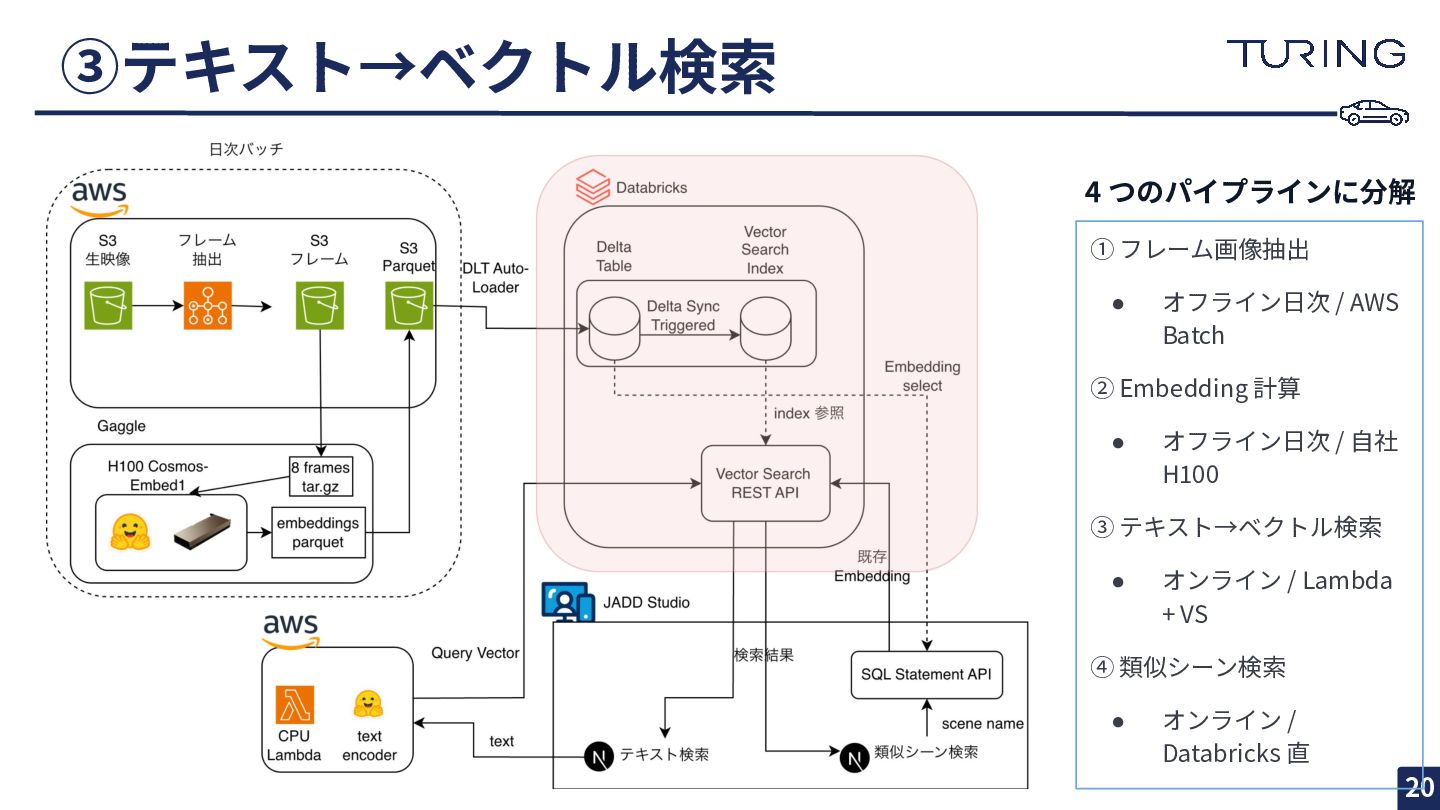
③テキスト→ベクトル検索 20 ① フレーム画像抽出 • オフライン⽇次 / AWS Batch ②
Embedding 計算 • オフライン⽇次 / ⾃社 H100 ③ テキスト→ベクトル検索 • オンライン / Lambda + VS ④ 類似シーン検索 • オンライン / Databricks 直 4 つのパイプラインに分解
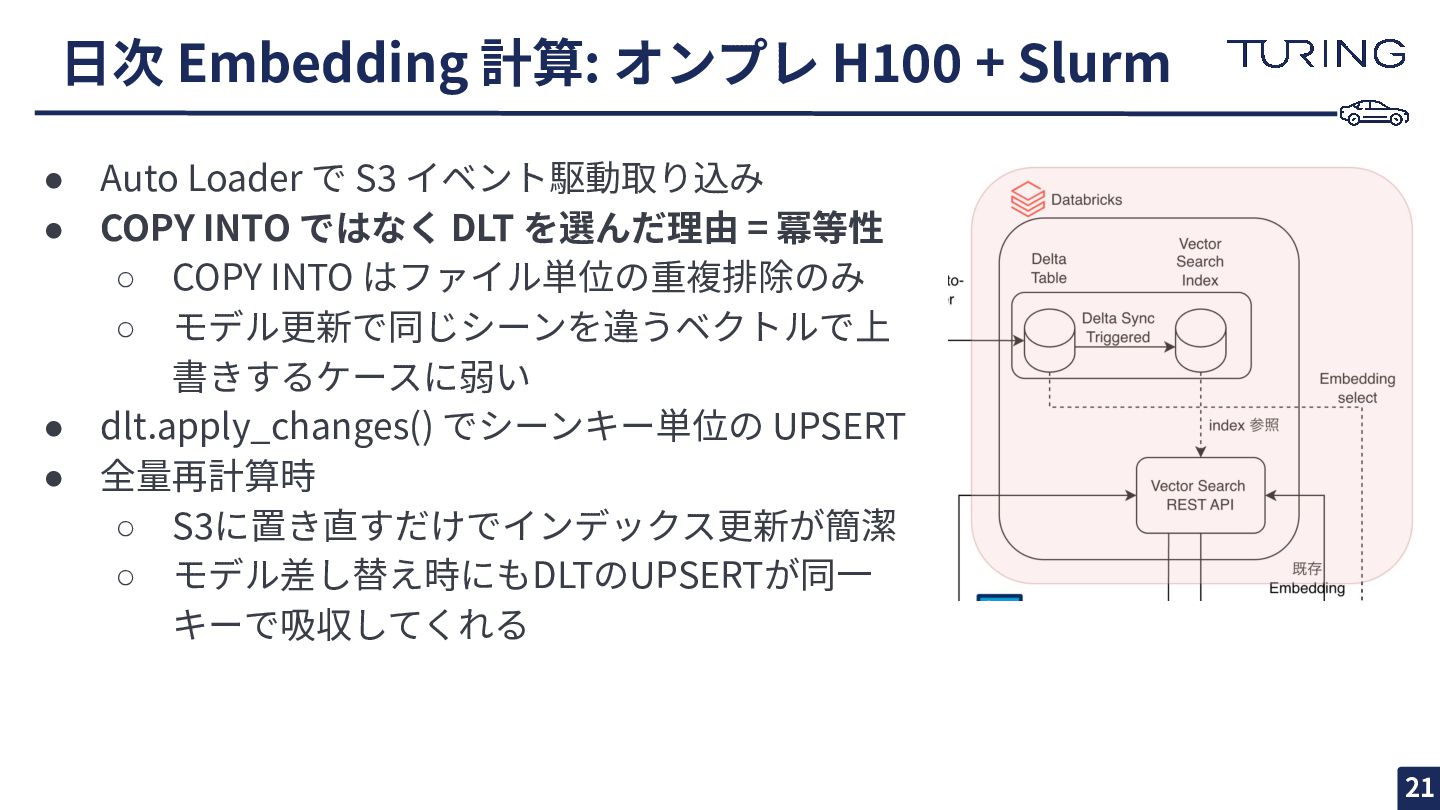
⽇次 Embedding 計算: オンプレ H100 + Slurm 21 • Auto
Loader で S3 イベント駆動取り込み • COPY INTO ではなく DLT を選んだ理由 = 冪等性 ◦ COPY INTO はファイル単位の重複排除のみ ◦ モデル更新で同じシーンを違うベクトルで上 書きするケースに弱い • dlt.apply_changes() でシーンキー単位の UPSERT • 全量再計算時 ◦ S3に置き直すだけでインデックス更新が簡潔 ◦ モデル差し替え時にもDLTのUPSERTが同⼀ キーで吸収してくれる
Vector Search Index の同期モード選択 22 CONTINUOUS ✗ 不採⽤ • 常時同期
(プロセスが常に⾛る) • コスト⾼ • ⽇次バッチには過剰スペック DELTA_SYNC + TRIGGERED ✓ 採⽤ • DLT 完了後に 1 回 sync で⼗分 • Databricks API 経由で sync をトリ ガー • 追加の運⽤負荷ほぼゼロ • embedding を Delta Table に取り込み後,Vector Search Endpoint と Index を作る必要あり ◦ 索引更新頻度と利⽤頻度に合わせて選ぶ
テキスト検索⽤Lambda 23 ① フレーム画像抽出 • オフライン⽇次 / AWS Batch ②
Embedding 計算 • オフライン⽇次 / ⾃社 H100 ③ テキスト→ベクトル検索 • オンライン / Lambda + VS ④ 類似シーン検索 • オンライン / Databricks 直 4 つのパイプラインに分解
テキスト検索⽤ Lambda 24 • text-encoder のみ → CPU で数百 ms
• 利⽤頻度: 1 ⽇ 数⼗〜数百リクエスト • SageMaker Endpoint は常時課⾦で過剰 • Lambda はリクエスト課⾦ → コスト最適 • zip 上限 250MB を超えるためコンテナ Lambda (最⼤ 10GB) を採⽤ Dockerfile (要点) RUN python -c "AutoModel.from_pretrained('nvidia/Cosmos-Embed1-448p', ...)" ENV TRANSFORMERS_OFFLINE=1 # 実行時のネットワーク完全遮断 ENV HF_HUB_OFFLINE=1
コスト最適化: warm start の⾼速化 25 • Lambda は⼀定時間以内ならランタイムが 使い回される ◦
モデルロード‧Secrets Manager 呼び出しを @lru_cache でメモ化 ◦ OAuth トークンは TTL 付きキャッシュ • Provisioned Concurrency を平⽇営業時間のみ ON ◦ 24h 確保はコスト⾼ → 利⽤時間帯だけ常時起動 ◦ EventBridge Scheduler の Universal Target で Lambda SDK API を直接呼出 • warm start は1秒以内,cold start でも数秒
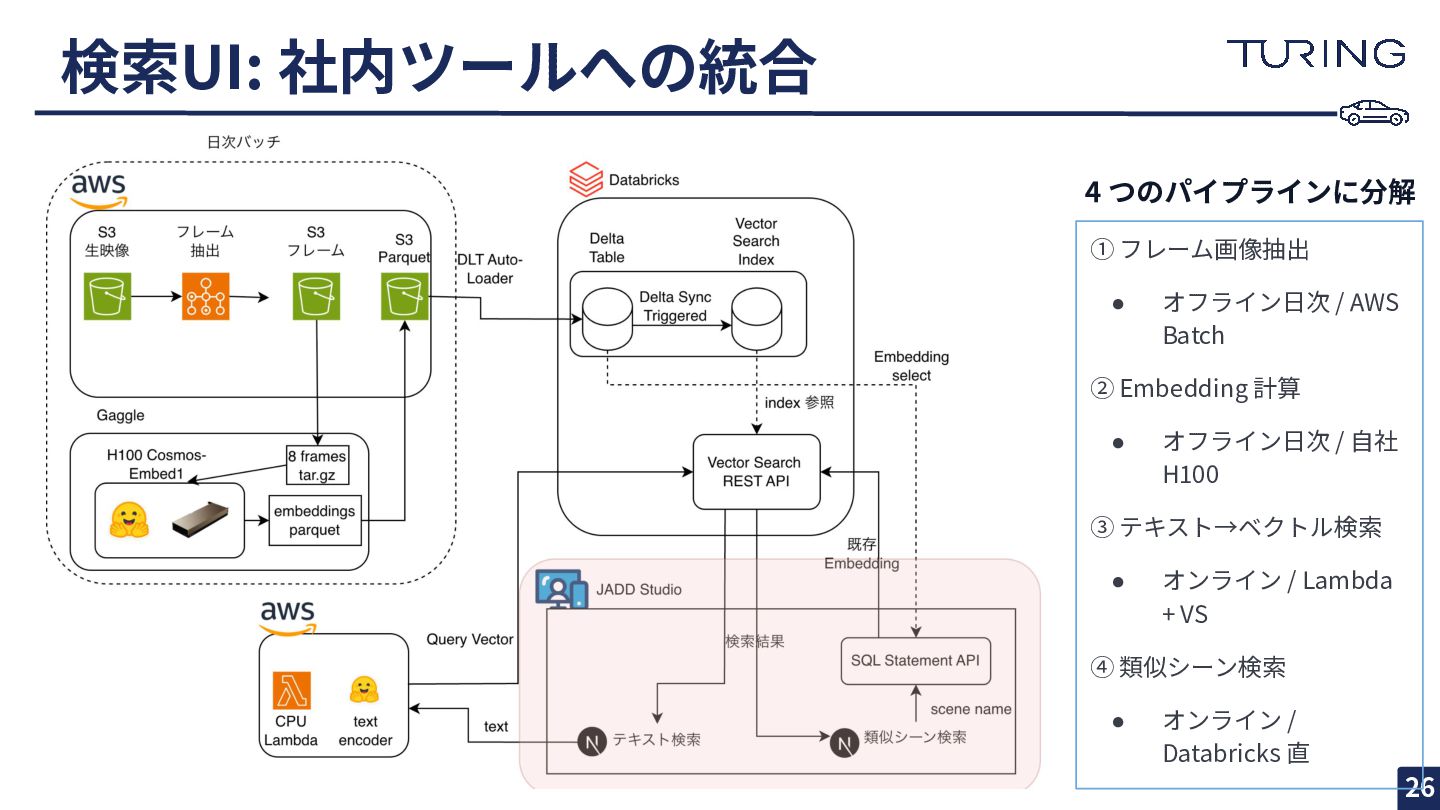
検索UI: 社内ツールへの統合 26 ① フレーム画像抽出 • オフライン⽇次 / AWS Batch
② Embedding 計算 • オフライン⽇次 / ⾃社 H100 ③ テキスト→ベクトル検索 • オンライン / Lambda + VS ④ 類似シーン検索 • オンライン / Databricks 直 4 つのパイプラインに分解
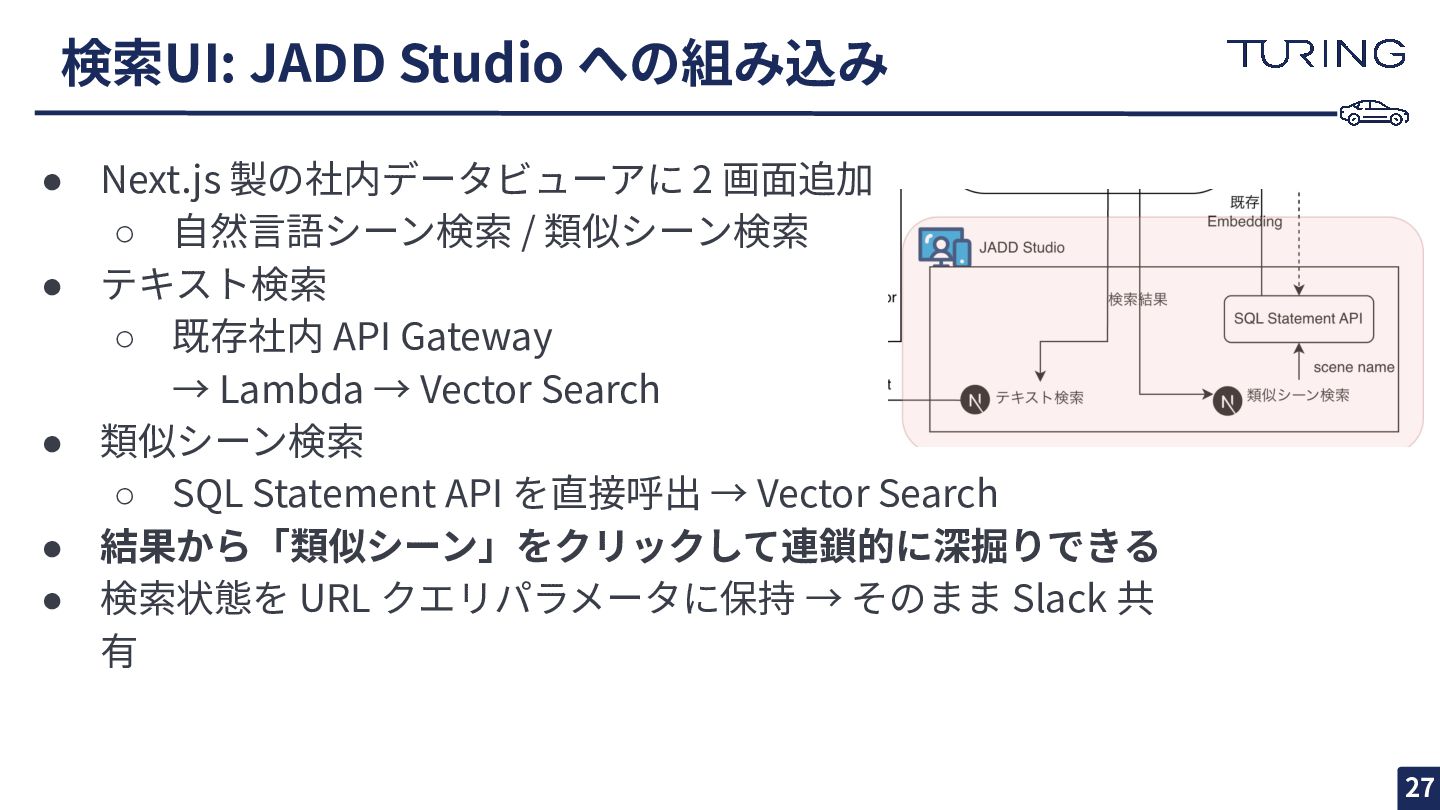
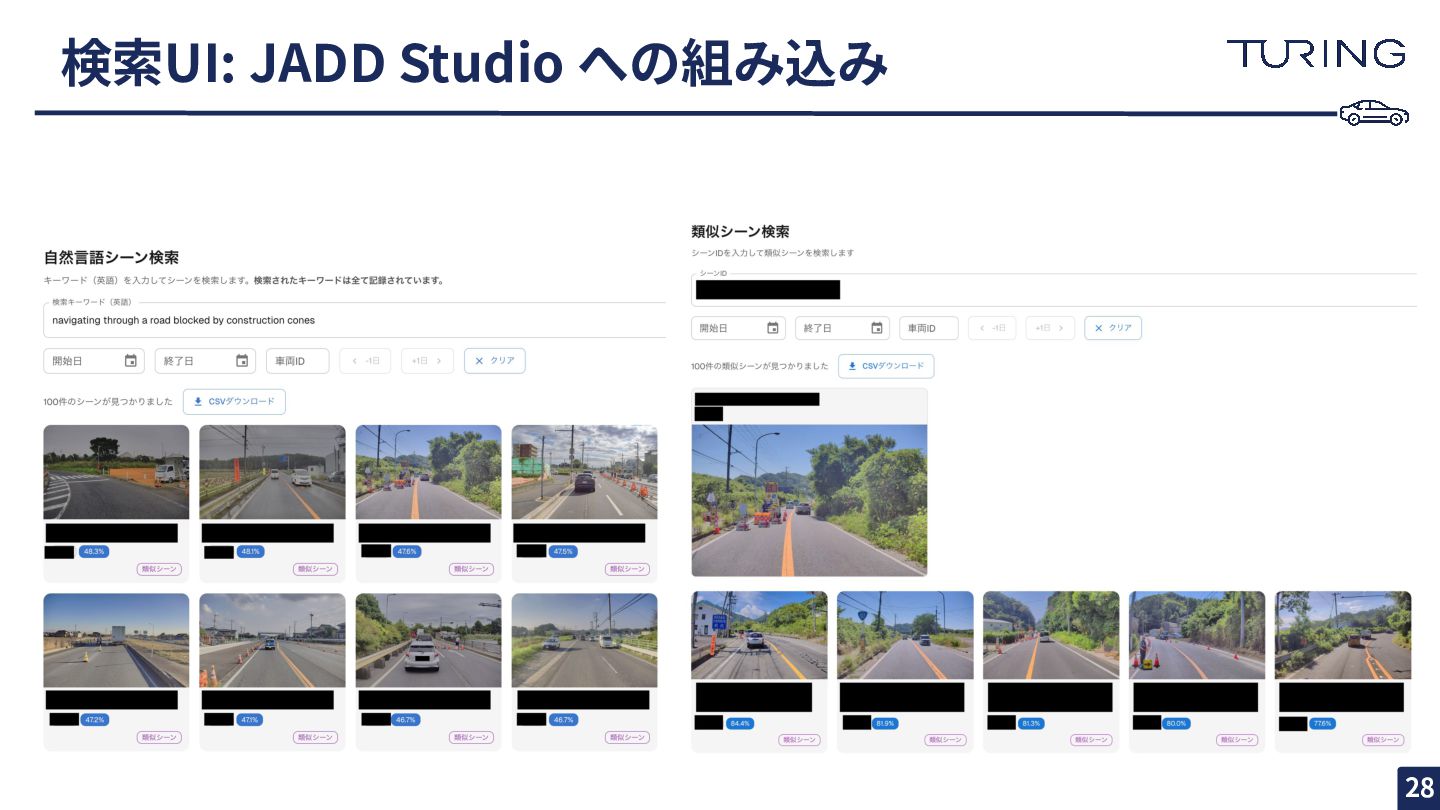
検索UI: JADD Studio への組み込み 27 • Next.js 製の社内データビューアに 2 画⾯追加
◦ ⾃然⾔語シーン検索 / 類似シーン検索 • テキスト検索 ◦ 既存社内 API Gateway → Lambda → Vector Search • 類似シーン検索 ◦ SQL Statement API を直接呼出 → Vector Search • 結果から「類似シーン」をクリックして連鎖的に深掘りできる • 検索状態を URL クエリパラメータに保持 → そのまま Slack 共 有
検索UI: JADD Studio への組み込み 28
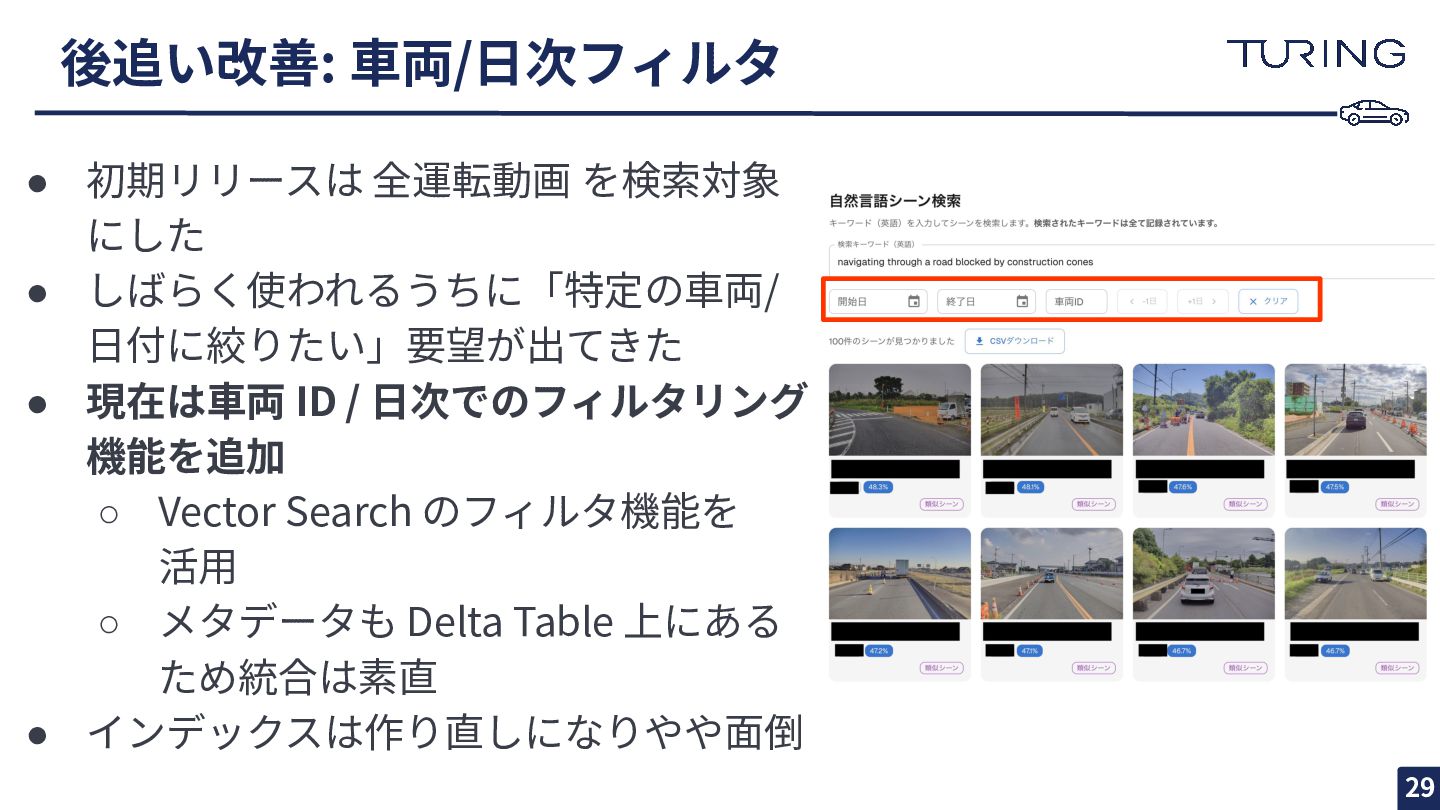
後追い改善: ⾞両/⽇次フィルタ 29 • 初期リリースは 全運転動画 を検索対象 にした • しばらく使われるうちに「特定の⾞両/
⽇付に絞りたい」要望が出てきた • 現在は⾞両 ID / ⽇次でのフィルタリング 機能を追加 ◦ Vector Search のフィルタ機能を 活⽤ ◦ メタデータも Delta Table 上にある ため統合は素直 • インデックスは作り直しになりやや⾯倒
どれくらいのコストがかかっている? 30 Compute (バッチ) オフライン⽇次 • オンプレ H100 (Gaggle) •
深夜帯のみ実⾏ • 学習との競合なし ほぼ社内設備の 減価償却分のみ Vector Search Endpoint 常時起動 • DELTA_SYNC + TRIGGERED • 1回/⽇ sync • endpoint ⾃体は常駐 ⽉ 数⼗ドル Text 検索 Lambda リクエスト課⾦ • コンテナ Lambda (10GB) • PC: 営業時間のみ • warm start ≪1s 利⽤頻度に応じた 変動費のみ
まとめ 31 • Cosmos-Embed1 と Databricks Vector Search ◦ 最低限の実装とインフラコストで運転動画に対する
セマンティックな検索システムを構築 • Video(事前計算)× Text(リアルタイム)の⾮対称設計で効率化 • 社内データビューアと統合し、⾮エンジニアにも利⽤拡⼤ • ⾃動運転開発を⽀える実⽤ツールとしてすでに活⽤中 • 今後の展望 ◦ 複数カメラへの拡張,検索精度の定量評価,類似シーン除外に よるデータ多様性向上 ◦ 可視化(クラスタリング / t-SNE),データ収集の⾼度化 (検索を超えた活⽤)
32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}