• .java doesn’t have a corresponding .class file, or • .java is newer than the .class file - based on timestamps This can be further tweaked with include/exclude attributes
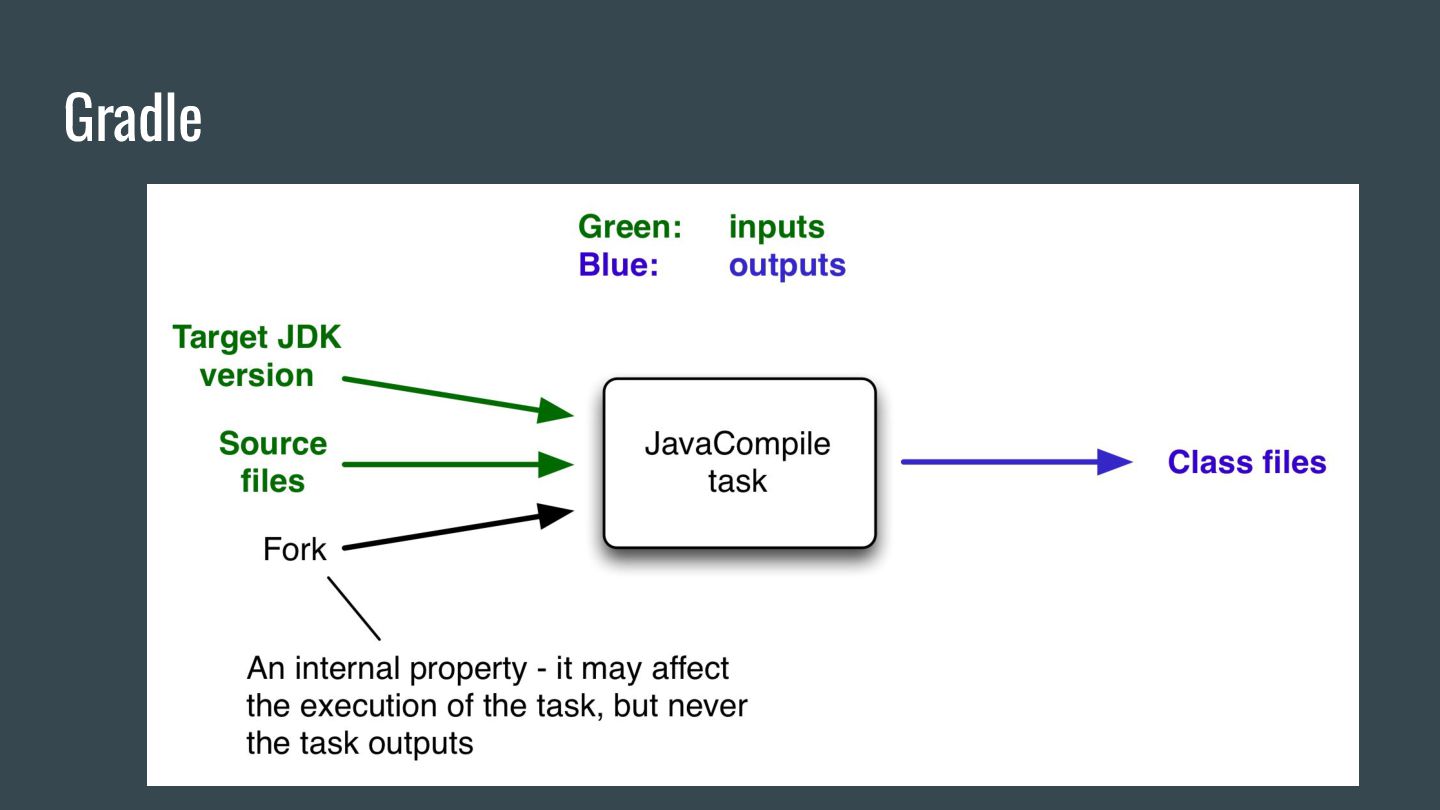
creates a fingerprint The fingerprint has the hash of the input files along with some metadata. Once the task runs, Gradle calculates the fingerprint of the output.
creates a fingerprint The fingerprint has the hash of the input files along with some metadata. Once the task runs, Gradle calculates the fingerprint of the output. When the task is run again, Gradle makes new fingerprints and compares with old fingerprints.
creates a fingerprint The fingerprint has the hash of the input files along with some metadata. Once the task runs, Gradle calculates the fingerprint of the output. When the task is run again, Gradle makes new fingerprints and compares with old fingerprints. If fingerprints don’t match, the task is re-run
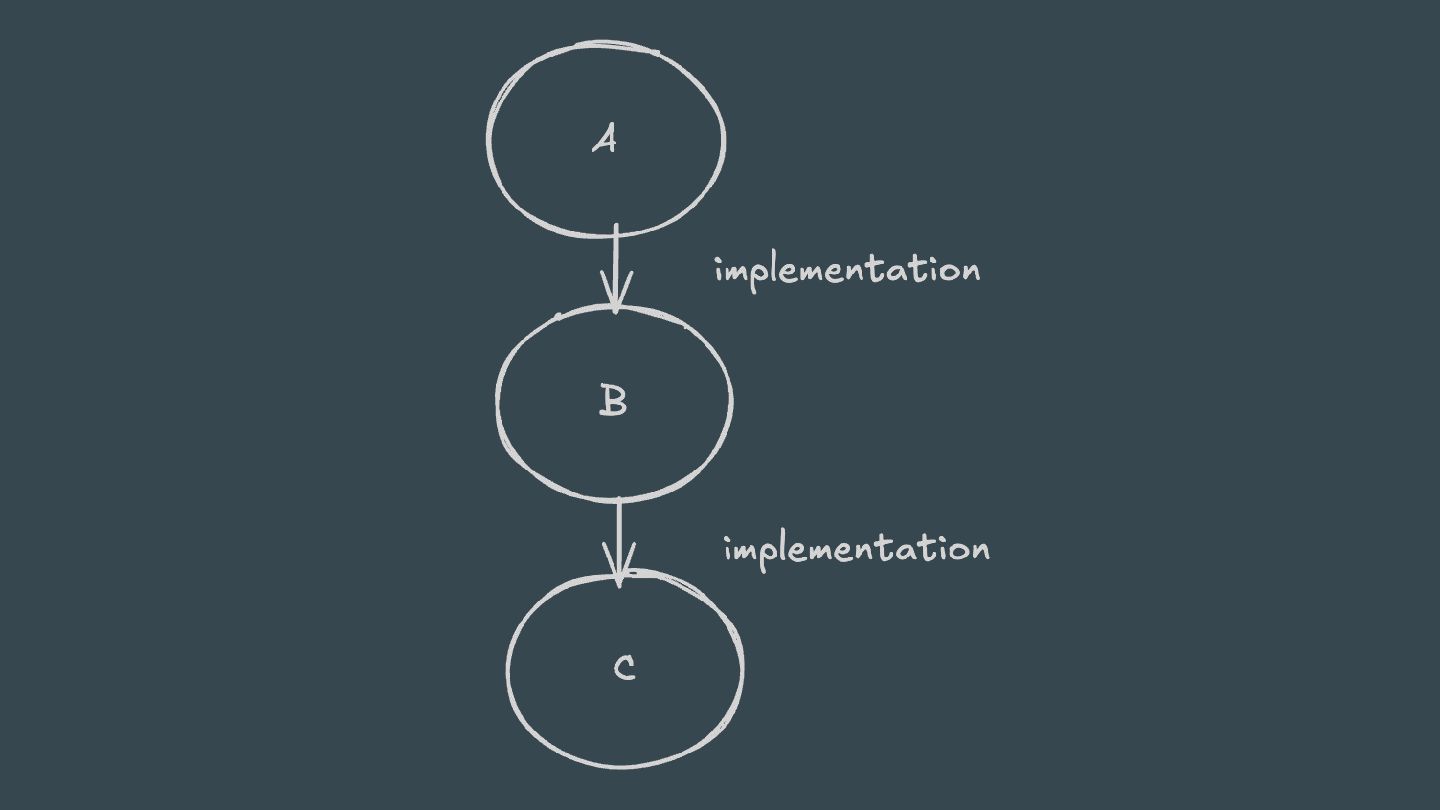
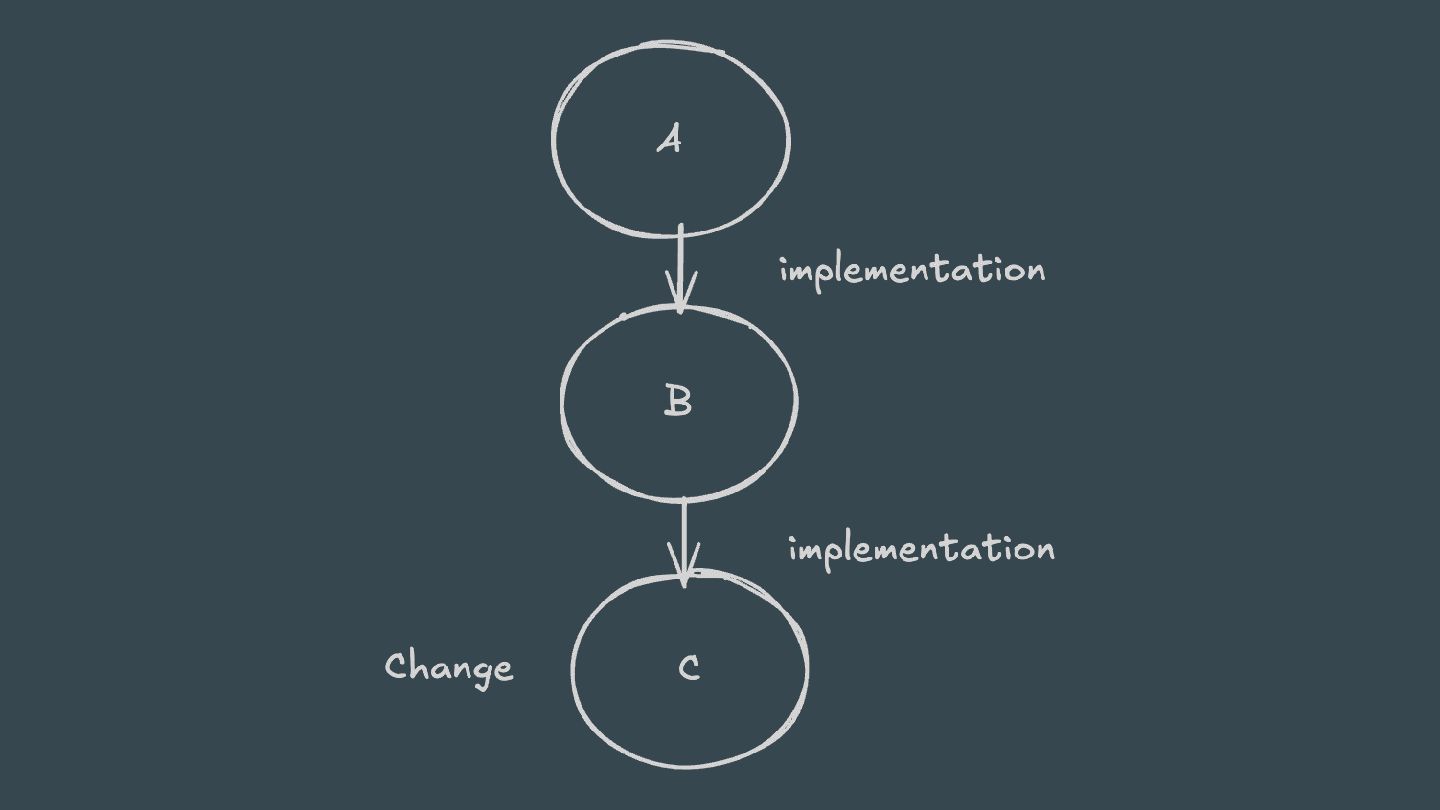
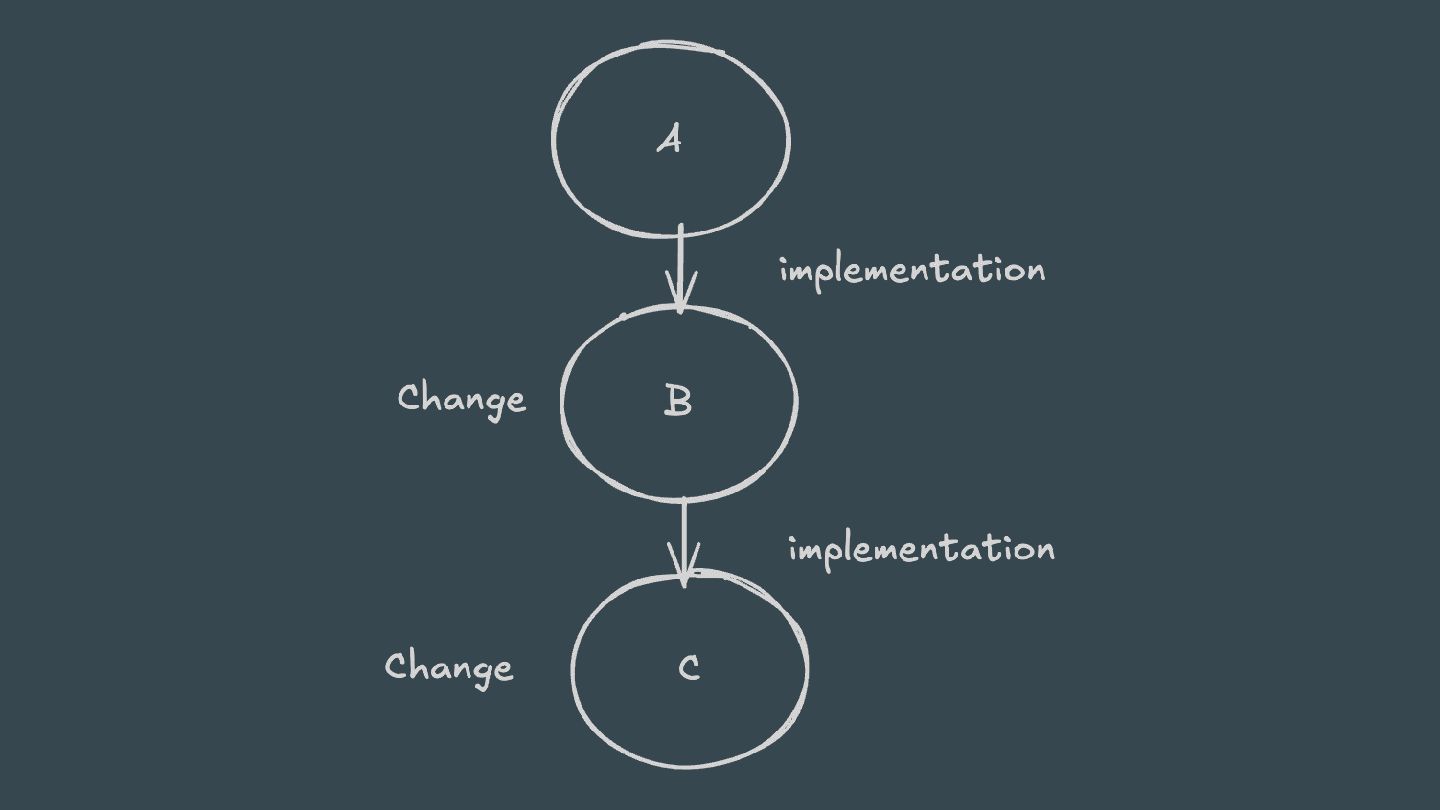
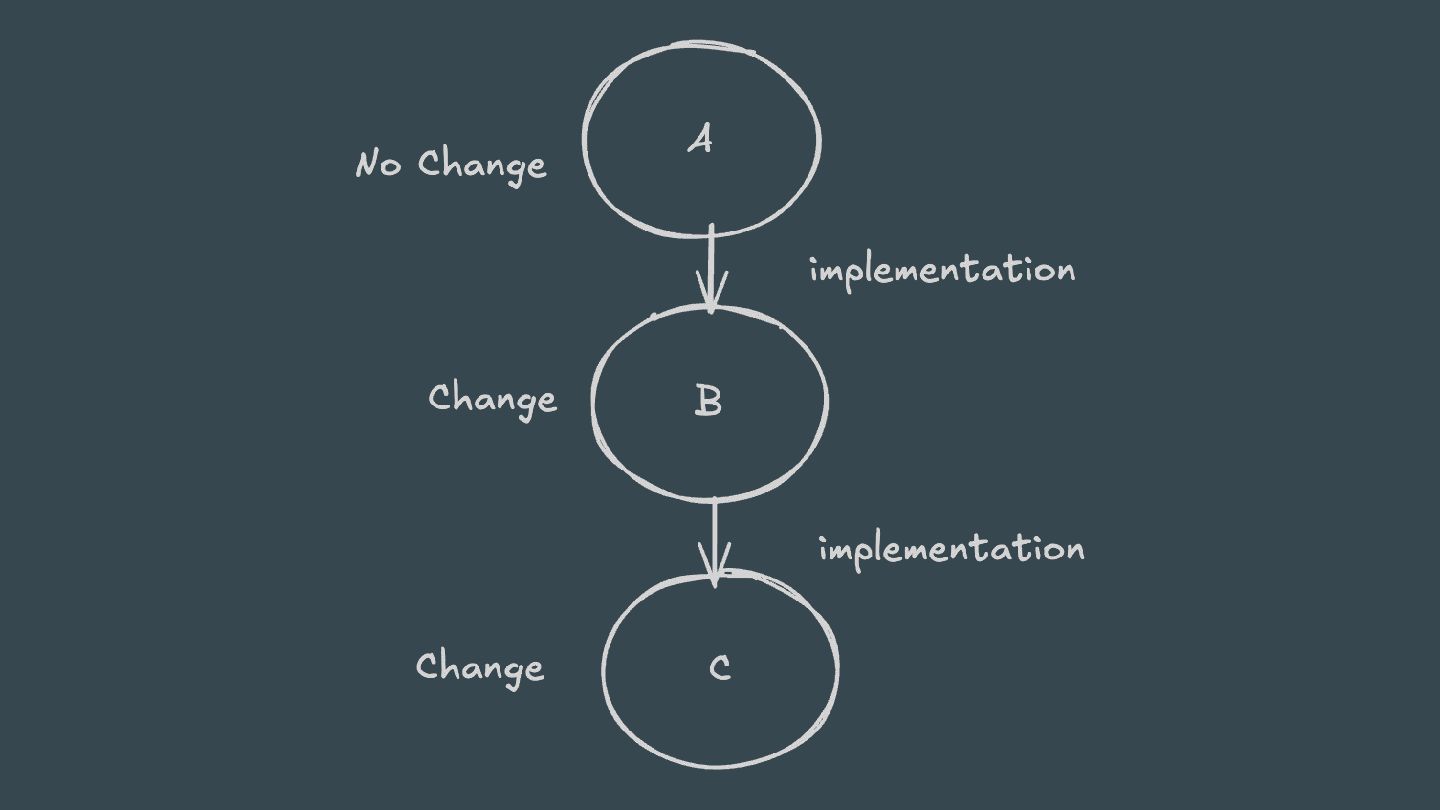
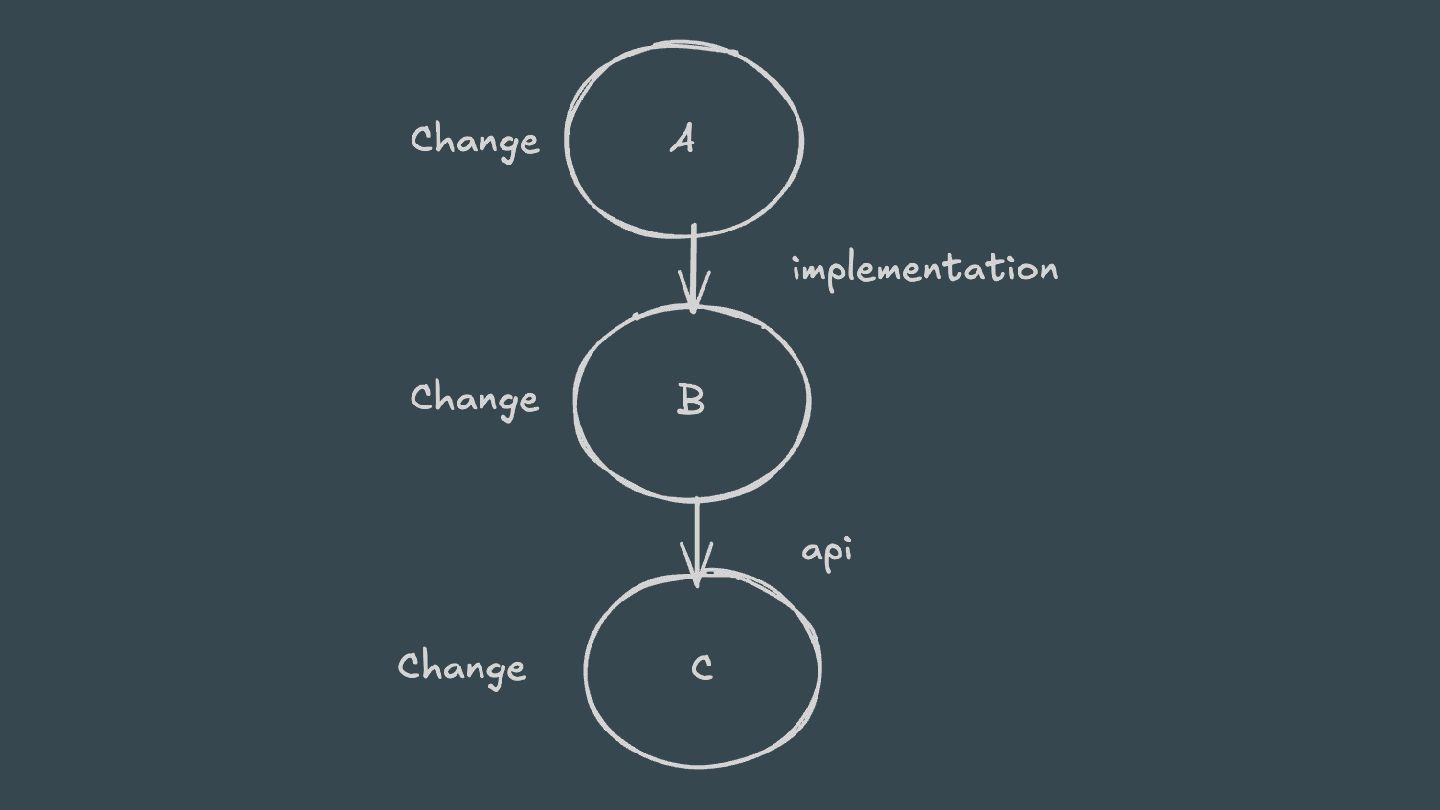
ABI-compatible way (only its private API has changed), then Java compilation tasks will be up-to-date. This means that if project A depends on project B and a class in B is changed in an ABI-compatible way (typically, changing only the body of a method), then Gradle won’t recompile A.
will focus on Kotlin/JVM implementation Kotlin relies on classpath snapshots to determine whether compilation is necessary. Classpath snapshots also rely on the ABI surface.
members. When changes are detected, only classes affected by the changes are recompiled. Coarse snapshots: only contains the ABI hash. When the ABI changes, the compiler recompiles all classes that depend on the changed class. This is useful for libraries and external dependencies. The compiler also keep coarse snapshots of .jar files.
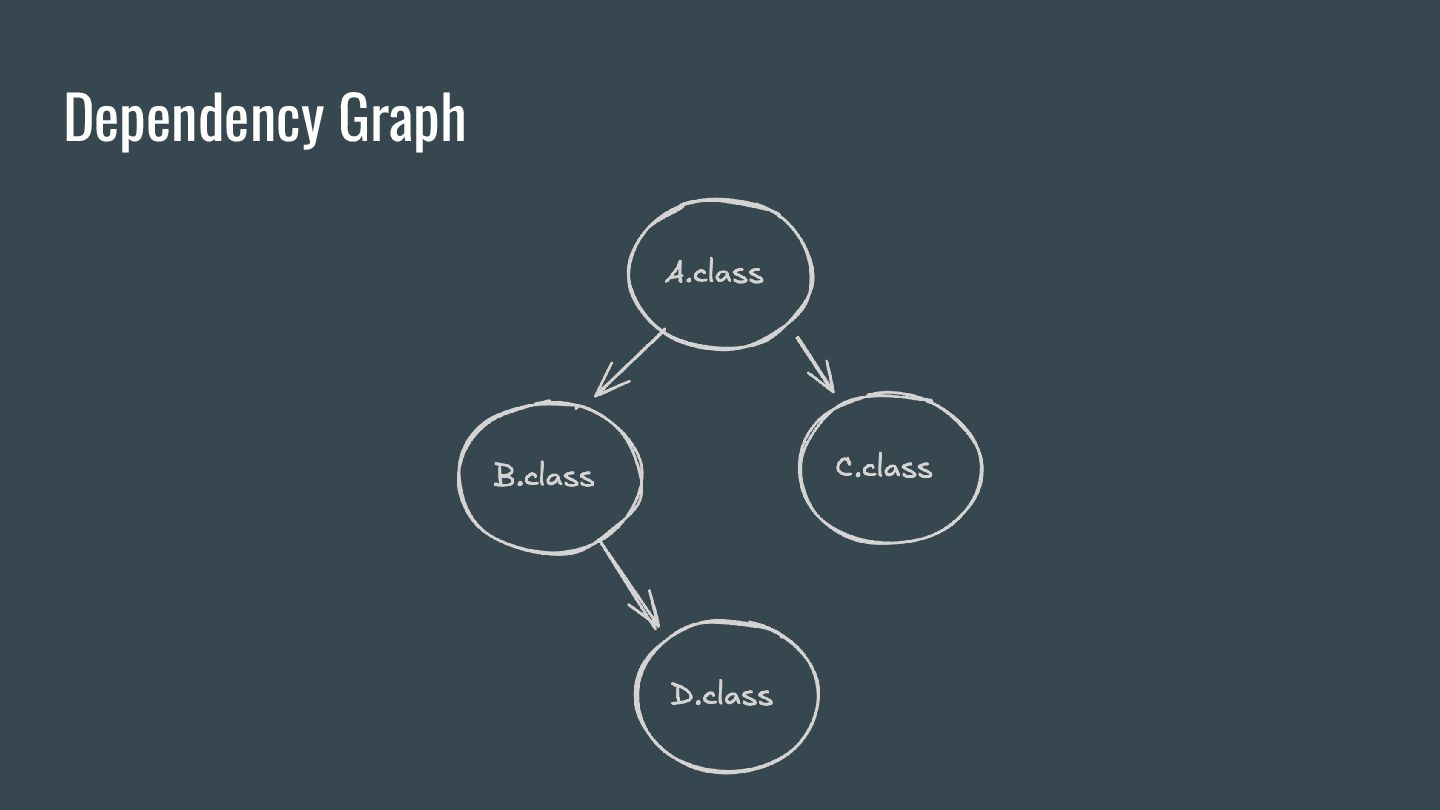
each class annotated with `@Entity` All actions must be based on information reachable via the Abstract Syntax Tree(AST) If it’s based on anything outside the AST, it should be aggregating
each class annotated with `@Entity` All actions must be based on information reachable via the Abstract Syntax Tree(AST) If it’s based on anything outside the AST, it should be aggregating Every generated file must be mapped to 1 originating file
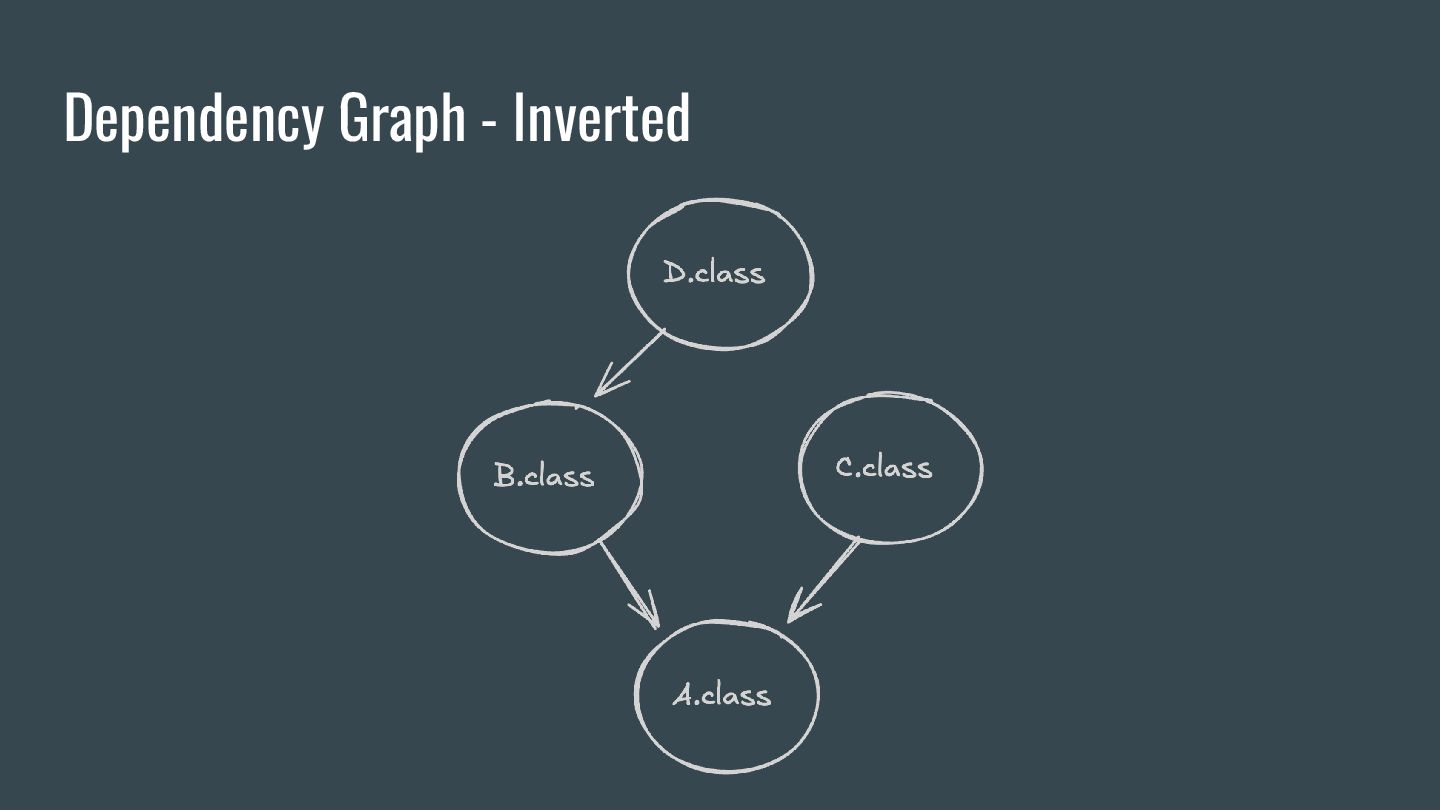
of input sources and generated output. Each output needs to be mapped to a corresponding set of KSNode By default, KSP tracks the classpath in addition to Java and Kotlin sources.
of input sources and generated output. Each output needs to be mapped to a corresponding set of KSNode By default, KSP tracks the classpath in addition to Java and Kotlin sources. To disable classpath tracking,you can use `ksp.incremental.intermodule=false`
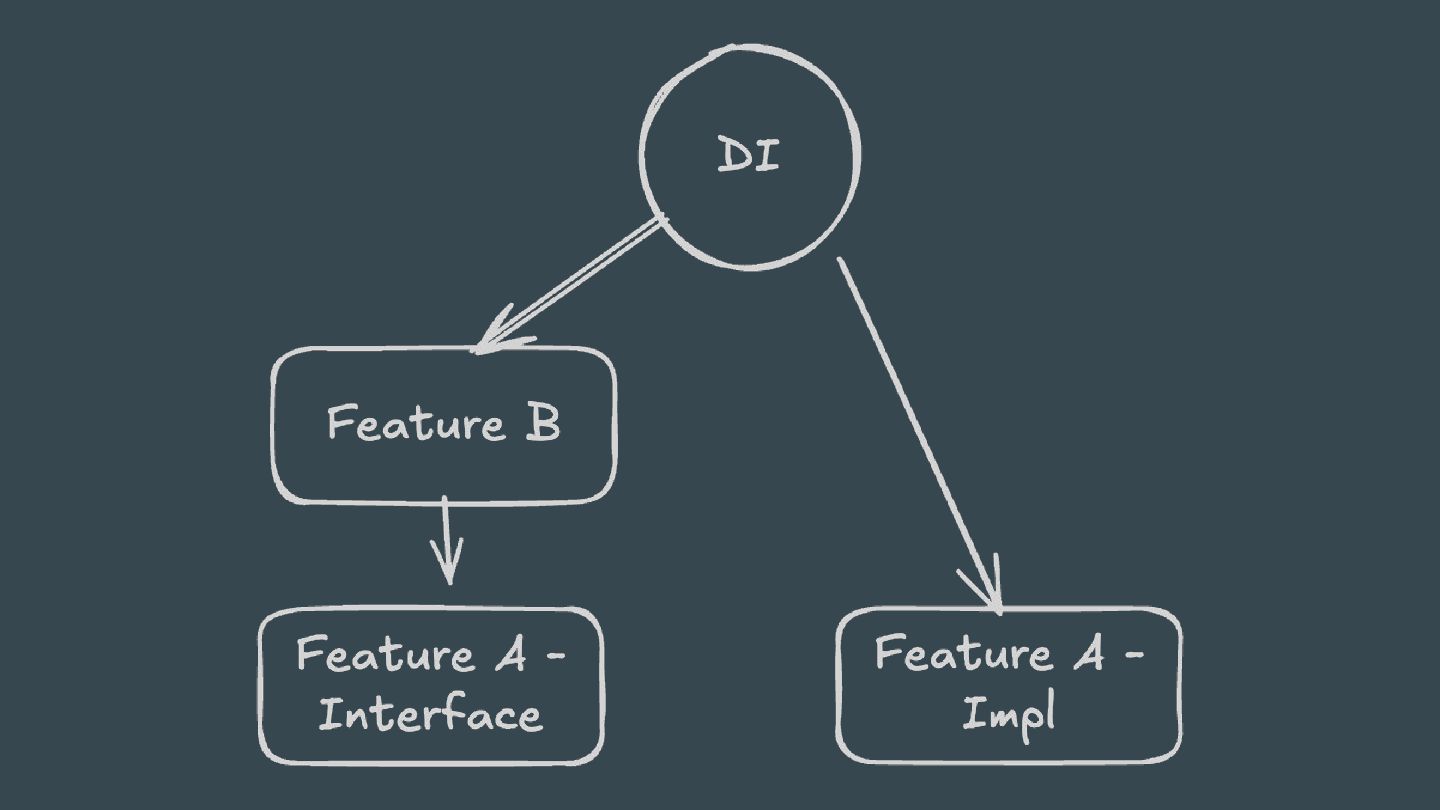
annotation processing: • Aggregating • Isolating Unlike Gradle annotation processing, KSP marks each output as either isolating or aggregating and not the entire processor.
annotation processing: • Aggregating • Isolating Unlike Gradle annotation processing, KSP marks each output as either isolating or aggregating and not the entire processor. Unlike Java, an Isolating output can define multiple source files.
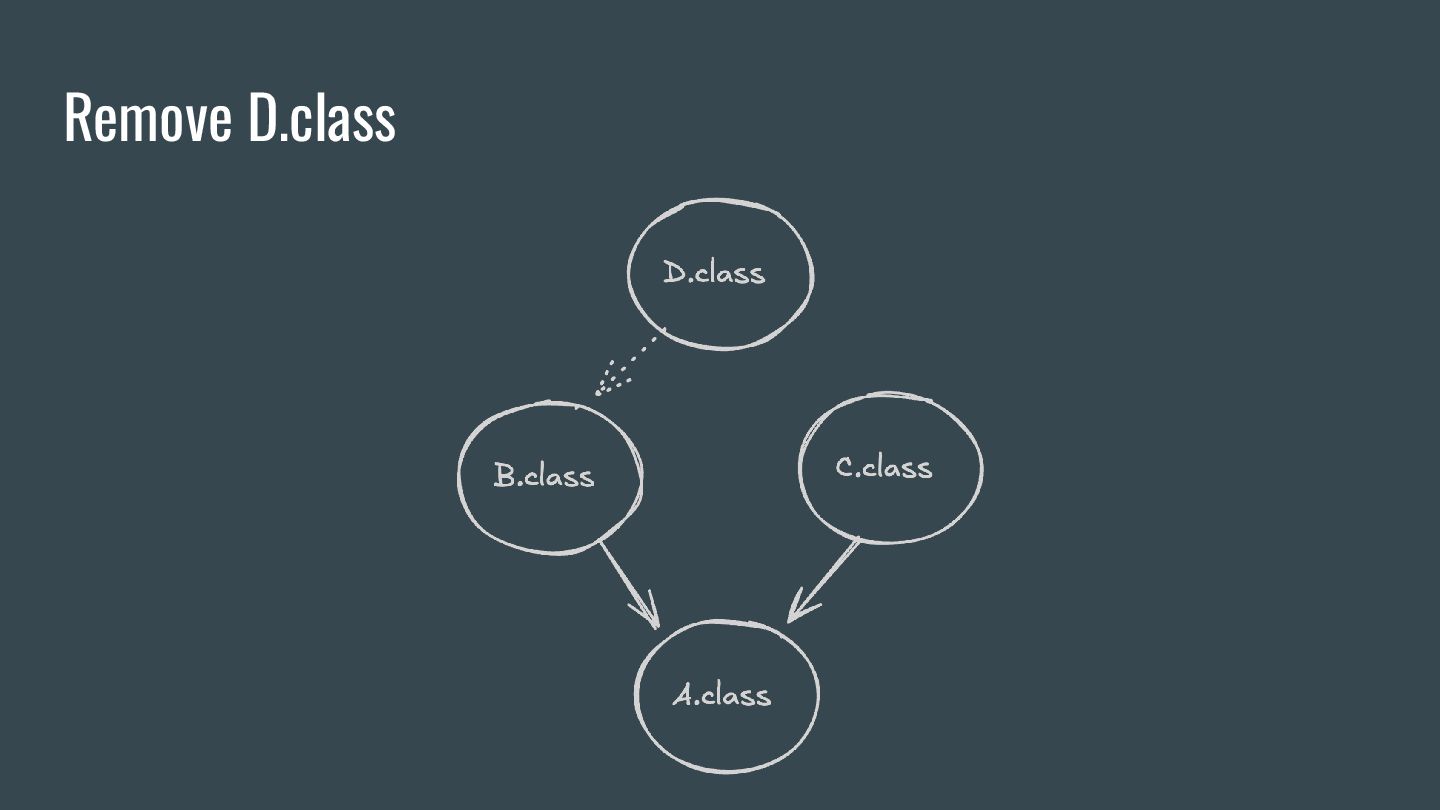
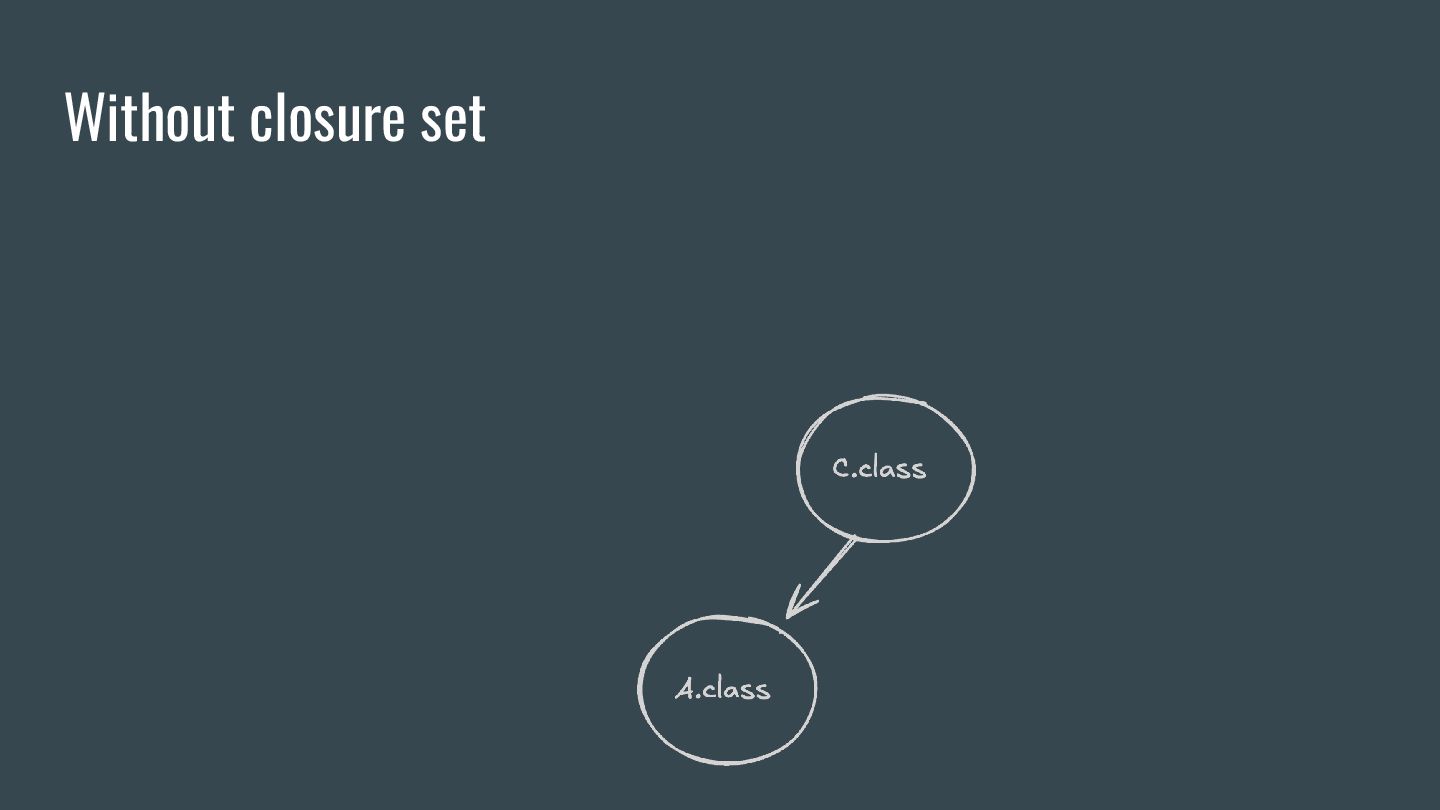
will be reprocessed. 2. If an input file is changed and it’s associated with an output, then all other input files associated with that output will also be reprocessed 3. All input files associated with at least one aggregating output will be reprocessed
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}