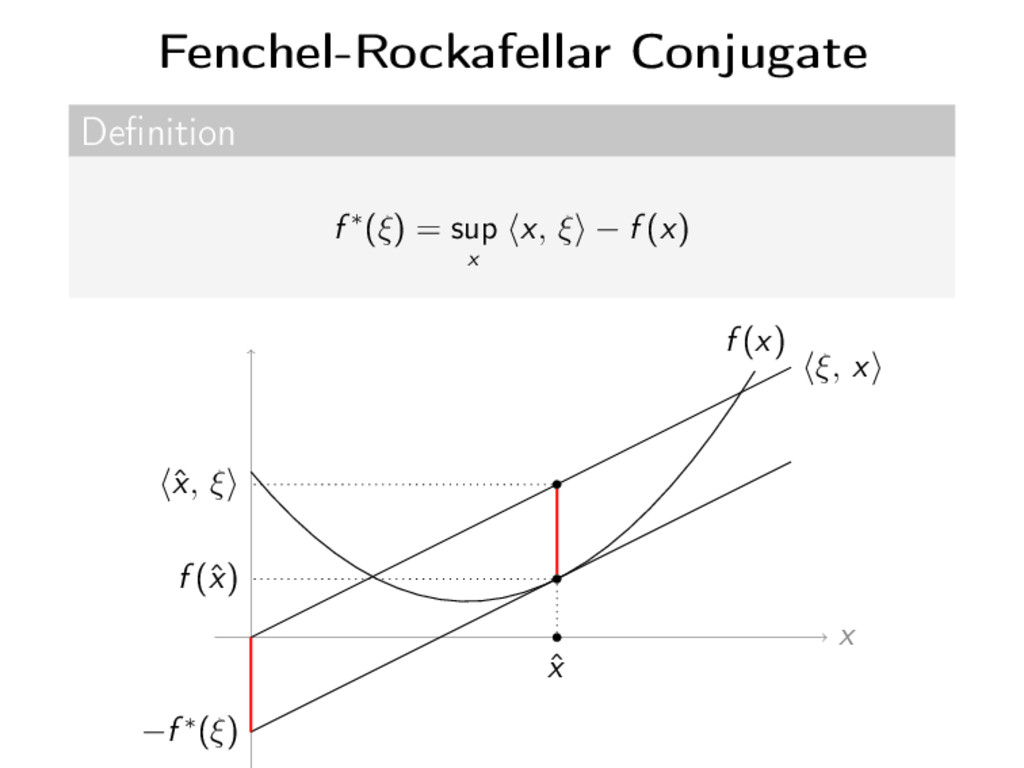
tutorial: M = RN (finite dimension, euclidian setting) f nicely convex no global smoothness assumption Fundamental ideas covered Fixed point Splitting Duality
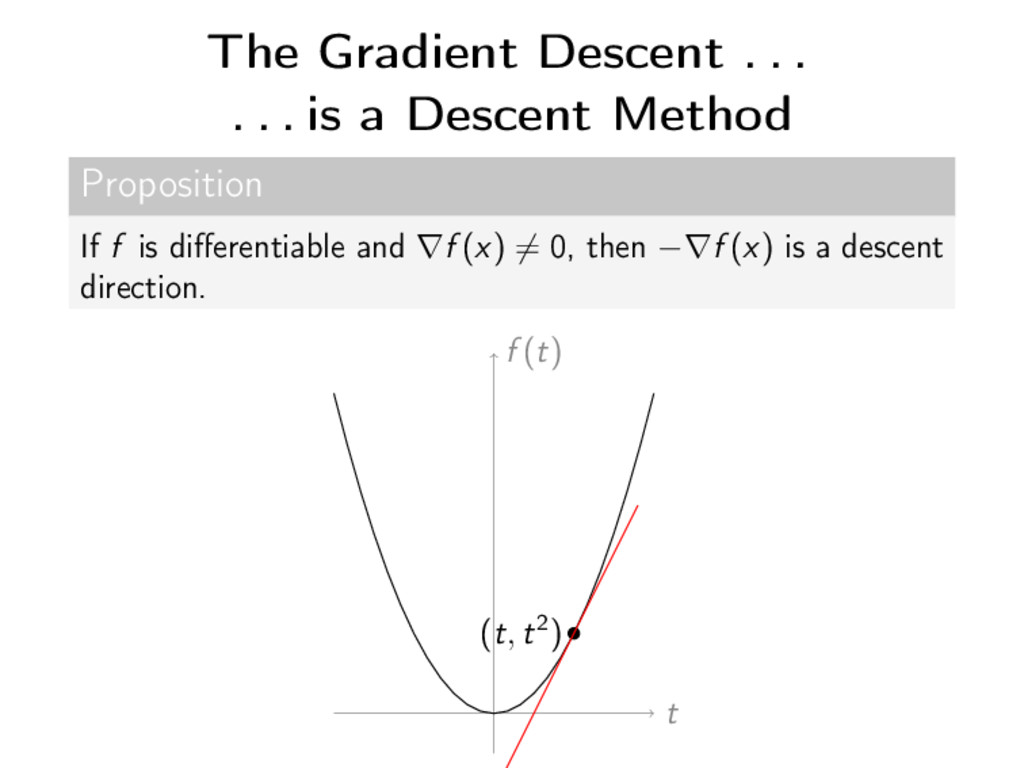
descent direction at x if there exists ρx > 0 such that ∀ρ ∈ (0, ρx ), f (x + ρd) < f (x). f (x(n)) x(n) f (x(n+1)) x(n+1) dx(n) Descent method x(n+1) = x(n)+ρx(n) dx(n)
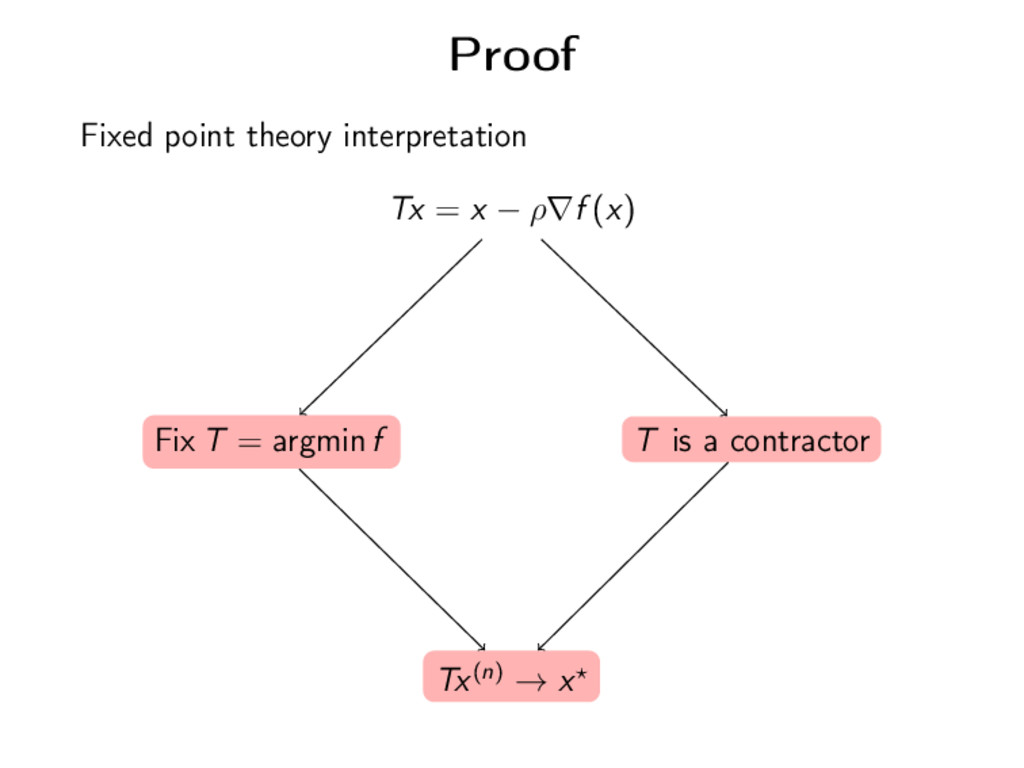
(x(n)) Proposition If 0 < ρ < 2α β , then x(n) converges to the unique minimizer x of f . Moreover, there exists 0 < γ < 1 such that ||x(n) − x || γk||x(0) − x ||
operator Nonexpansive mappings People: Brézis, Fenchel, Lions, Moreau, Rockafellar, etc. study of multivalued mappings of Banach spaces Today: application-driven approach
Convexity f (tx + (1 − t)y) tf (x) + (1 − t)f (y) Lower semi-continuous lim inf x→x0 f (x) f (x0 ) Proper f (x) > −∞ et ∃x, f (x) = +∞ HERE convex ≡ convex, l.s.c and proper. We assume also that argmin f is not empty.
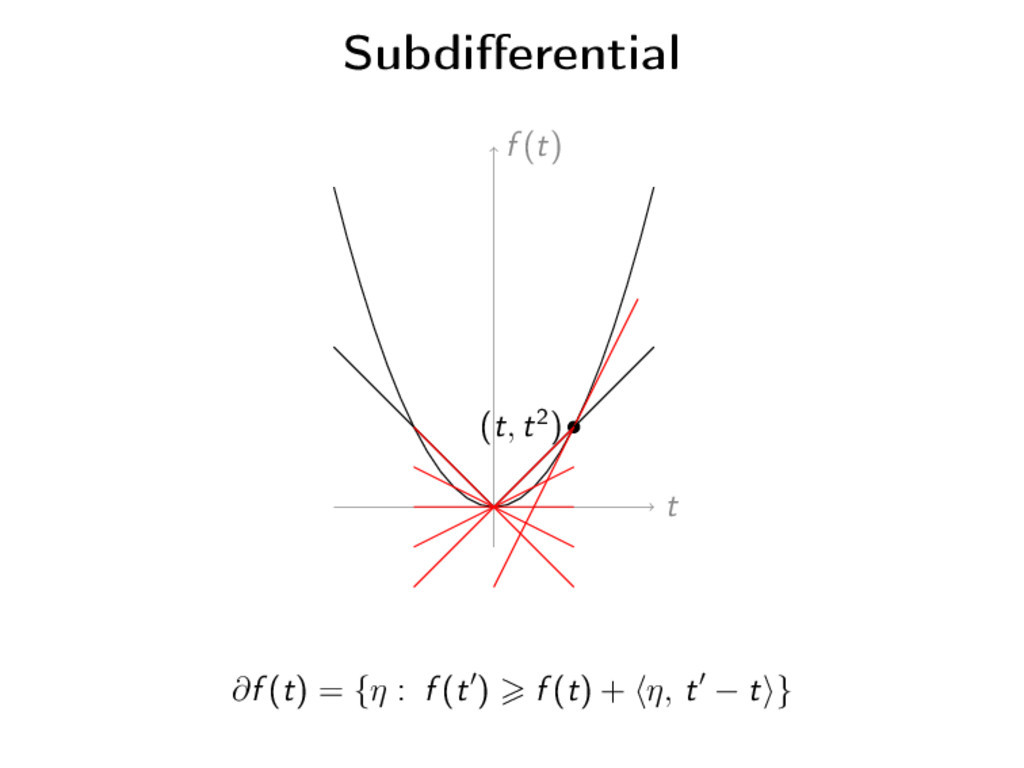
function f at x ∈ RN is the subset of RN defined by ∂f (t) = {η : f (t ) f (t) + η, t − t } Proposition If f is smooth, ∂f (x) = {∇f (x)} For ρ > 0, ∂(ρf )(x) = ρ∂f (x) ∂(f + g)(x) ⊆ ∂f (x) + ∂g(x) Equality if ri dom f ∩ ri dom g = ∅
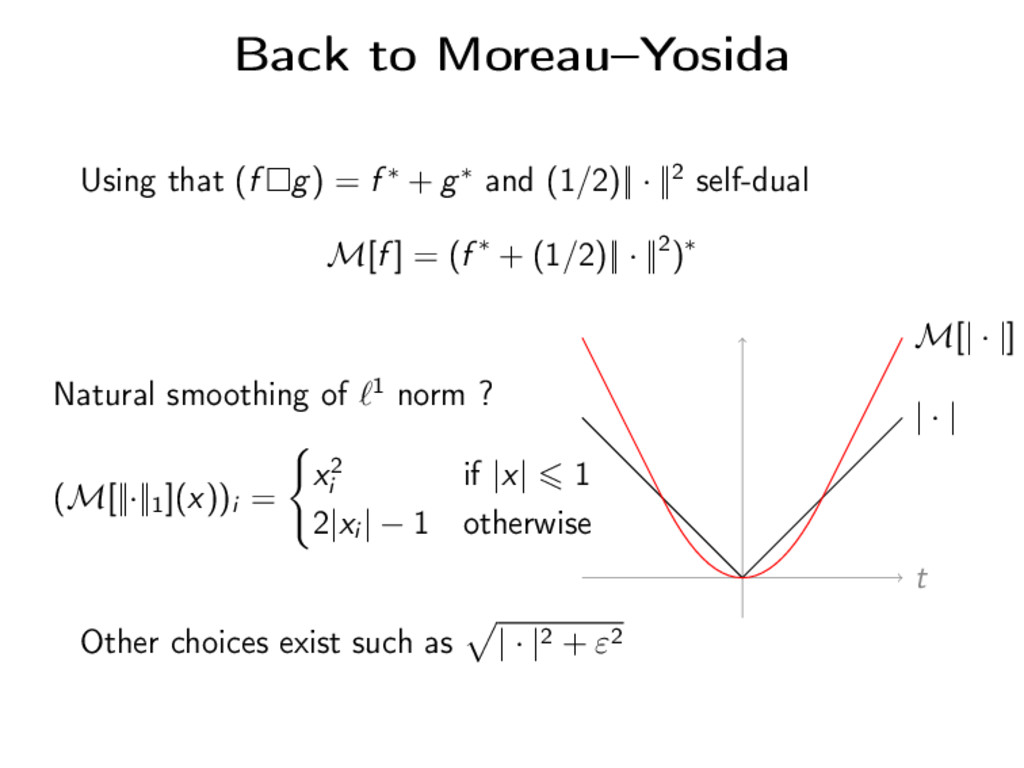
v f (x) + g(v − x) Definition The Moreau–Yosida regularization of f is defined as M[f ] = f (1/2)|| · ||2 Theorem For any convex function f (not smooth, not full-domain) dom M[f ] = Rn M[f ] is continuously differentiable argmin M[f ] = argmin f
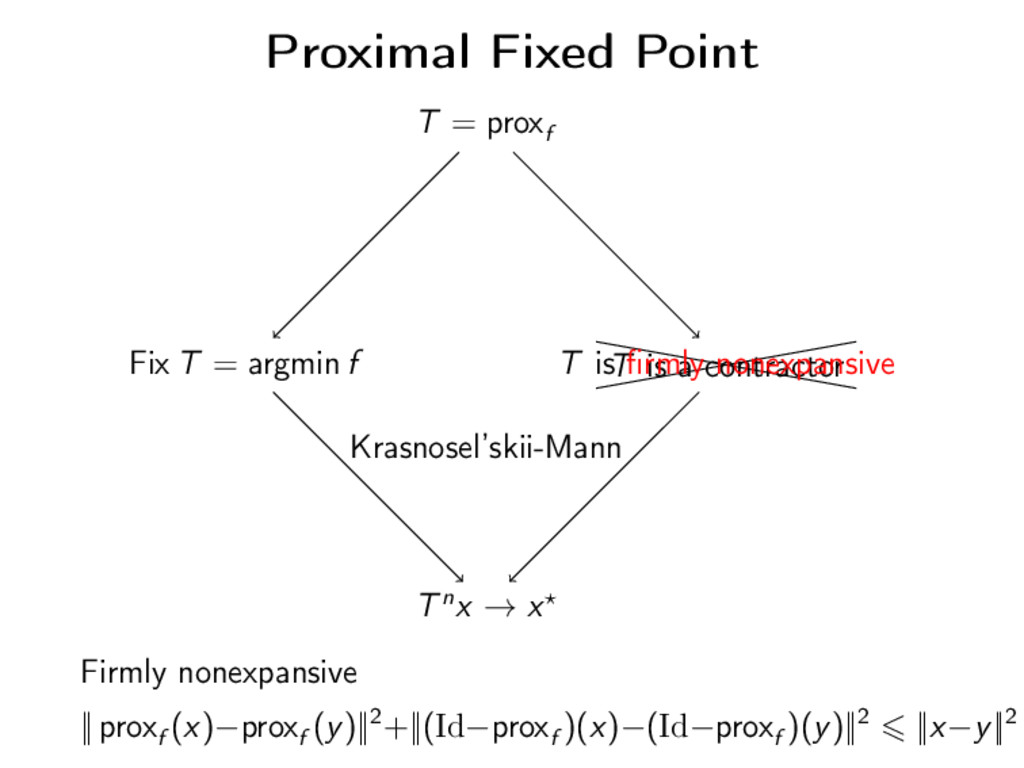
Definition The proximity operator of a convex function f is defined by proxf (v) = argmin x f (x) + 1 2 ||x − v||2 Smooth interpretation: implicit gradient step proxf (x) = x − ∇M[f ](x)
if x ∈ C +∞ otherwise. Proposition (Proximity ≡ Projection) If C is a convex set, then proxιC = ΠC proxιC (v) = argmin x proxιC (v) + 1 2 ||x − v||2 = argmin x∈C 1 2 ||x − v||2 = ΠC (v)
f T is a contractor T is firmly nonexpansive Tnx → x Krasnosel’skii-Mann Firmly nonexpansive || proxf (x)−proxf (y)||2+||(Id−proxf )(x)−(Id−proxf )(y)||2 ||x−y||2
f1 (x) + f2 (y) proxf (v, w) = (Proxf1 (v), Proxf2 (w)) Orthogonal precomposition: f (x) = g(Ax) with AA∗ = Id proxf (v) = AT proxg (Av) Affine addition: f (x) = g(x) + u, x + b proxf (v) = proxg (v − a)
w Assumption: x0 sparse, i.e. Card supp(x0 ) N Variational recovery min x 1 2 ||y − Φx||2 + λ Card supp(x) Convex relaxation min x 1 2 ||y − Φx||2 + λ||x||1 where ||x||1 = i |xi |
− Φx||2 f + λ||x||1 λg J not smooth / proxJ hard to compute But: f is smooth proxλg is easy to compute t ST(t) λ −λ Soft thresholding (proxλ||·||1 (x))i = sign(xi )(|xi |−λ)+
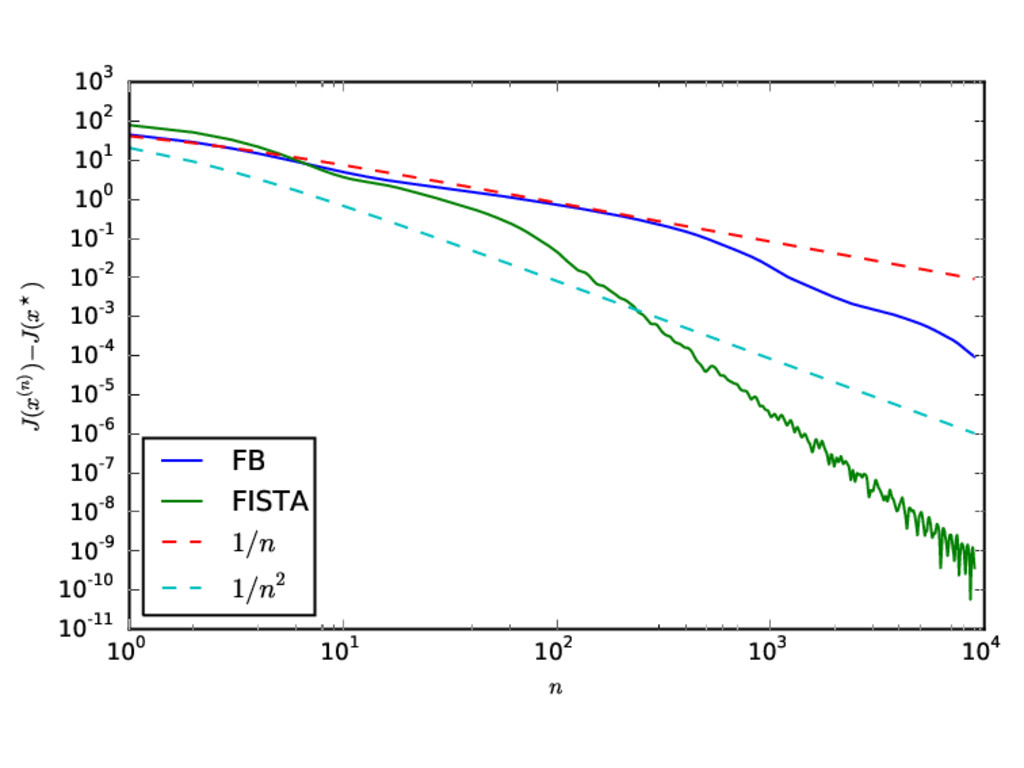
forward ) Proposition If 0 < ρ < 1 β , then x(n) converges to a minimizer x of f + g. Moreover, J(x(n)) − J(x ) = O(1/n) The convergence ||x(n) − x || may be arbitrary slow
Assumption: x0 sparse, i.e. Card supp(x0 ) N Variational recovery min y=Φx Card supp(x) Convex relaxation min y=Φx ||x||1 Constraint-less formulation min x ||x||1 + ιy=Φx (x)
∂f (x ) + ∂g(x ) 2x ∈ (x + ρ∂f (x )) + (x + ρ∂g(x )) 2x ∈ (Id + ρ∂f )(x ) + (Id + ρ∂g)(x ) Idea: take z ∈ (Id + ρ∂g)(x ) 2x ∈ (Id + ρ∂f )(x ) + z x = (Id + ρ∂f )−1(2x − z) Almost a fixed point . . . let Γρf = 2(Id + ρ∂f ) − Id 2x ∈ (Id + ρ∂f )(x ) + z 2x − z ∈ (Id + ρ∂f )(x ) Γρg (z) ∈ (Id + ρ∂f )(x ) In particular, x = (Id + ρ∂f )−1(Γρg (z)).
x = (Id + ρ∂f )−1(Γρg (z)) et Γρg (z) ∈ (Id + ρ∂f )(x ) Thus, z = 2x −Γρg (z) = 2(Id+ρ∂f )−1(Γρg (z))−Γρg (z) = Γρf (Γρg (z)) Fixed point x ∈ argmin f + g ⇔ x = proxρg (z) z = (Γρf ◦ Γρg )(z) Proposition proxρg (Fix(Γρf ◦ Γρg )) = argmin f + g
= proxρg (y(n)) z(n) = proxρf (2x(n) − y(n)) y(n+1) = y(n) + γ(z(n) − x(n)) Proposition If ρ > 0, 1 < γ < 2, then x(n) converges to a minimizer x of f + g. The rate of convergence is hard to derive
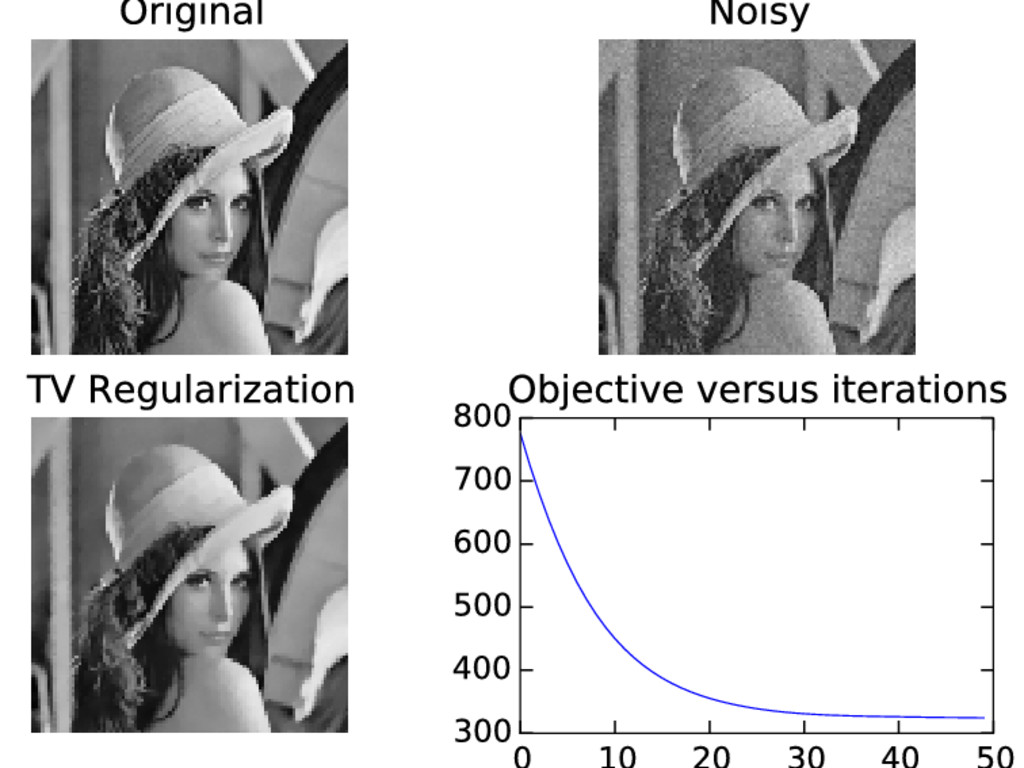
string min x 1 2 ||y − Φx||2 + λ||Dx||p D first-order finite difference Composite Problem: min x f (Kx) + g(x) where K is a linear operator proxf easy to compute ⇒ proxf ◦K easy to compute ? No (except if K is orthogonal)
proper then proxf (x) + proxf ∗ (x) = x Applications: Generalization of the orthogonal splitting of Rn ΠT (x) + ΠT⊥ (x) = x If proxf ∗ easy to compute, so does proxf .
K inside f . 1. Biconjugate theorem f (Kx) = (f ∗)∗(Kx) = sup ξ ξ, Kx − f ∗(ξ) 2. Adjoint operator f (Kx) = sup ξ K∗ξ, x − f ∗(ξ) 3. Rewrite initial problem (with qualification assumption) min x max ξ K∗ξ, x − f ∗(ξ) + g(x)
, V ∈ OM ) F(VXU) = F(X) Proposition If F is orthogonally invariant, then F(X) = F(diag(σ(X))), where σ(X) is the ordered singular values of X. Absolute symmetry (∀x ∈ RN, ∀Q signed permutation) f (Qx) = f (x) Theorem F orthogonally inv. ⇔ F = f ◦ σ with f absolutely symmetric. ex: || · ||nuc = || · ||1 ◦ σ
N. Parikh and S. Boyd, Proximal algorithms, 2013 P.L. Combettes and J.-C. Pesquet, Proximal Splitting Methods in Signal Processing, 2011 A. Beck and M. Teboulle, Gradient-Based Algorithms with Applications to Signal Recovery Problems, 2010
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}