et G. Peyré, Model Selection with Piecewise Regular Gauges, Tech. report, http://arxiv.org/abs/1307.2342 , 2013 • J. Fadili, V. and G. Peyré, Linear Convergence Rates for Gauge Regularization, ongoing work
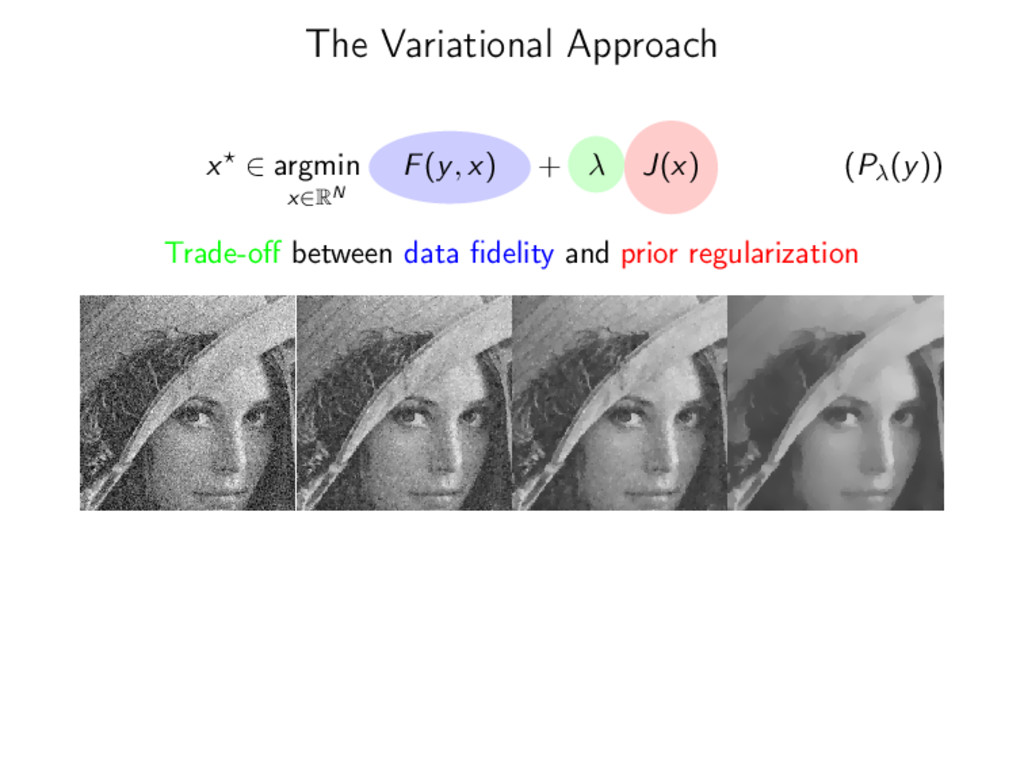
λ J(x) (Pλ(y)) Trade-off between data fidelity and prior regularization • Data fidelity: 2 loss, logistic, etc. F(y, x) = 1 2 ||y − Φx||2 2 • Parameter: By hand or automatic like SURE.
λ J(x) (Pλ(y)) Trade-off between data fidelity and prior regularization • Data fidelity: 2 loss, logistic, etc. F(y, x) = 1 2 ||y − Φx||2 2 • Parameter: By hand or automatic like SURE. • Regularization: ?
sparse representations in arbitrary redundant bases. • Tropp, J. A. (2006). Just relax: Convex programming methods for identifying sparse signals in noise. • Grasmair, M. and al. (2008). Sparse regularization with q penalty term. • Bach, F. R. (2008). Consistency of the group lasso and multiple kernel learning & Consistency of trace norm minimization. • V. and al. (2011). Robust sparse analysis regularization. • Grasmair, M. and al. (2011). Necessary and sufficient conditions for linear convergence of 1-regularization. • Grasmair, M. (2011). Linear convergence rates for Tikhonov regularization with positively homogeneous functionals. (and more !)
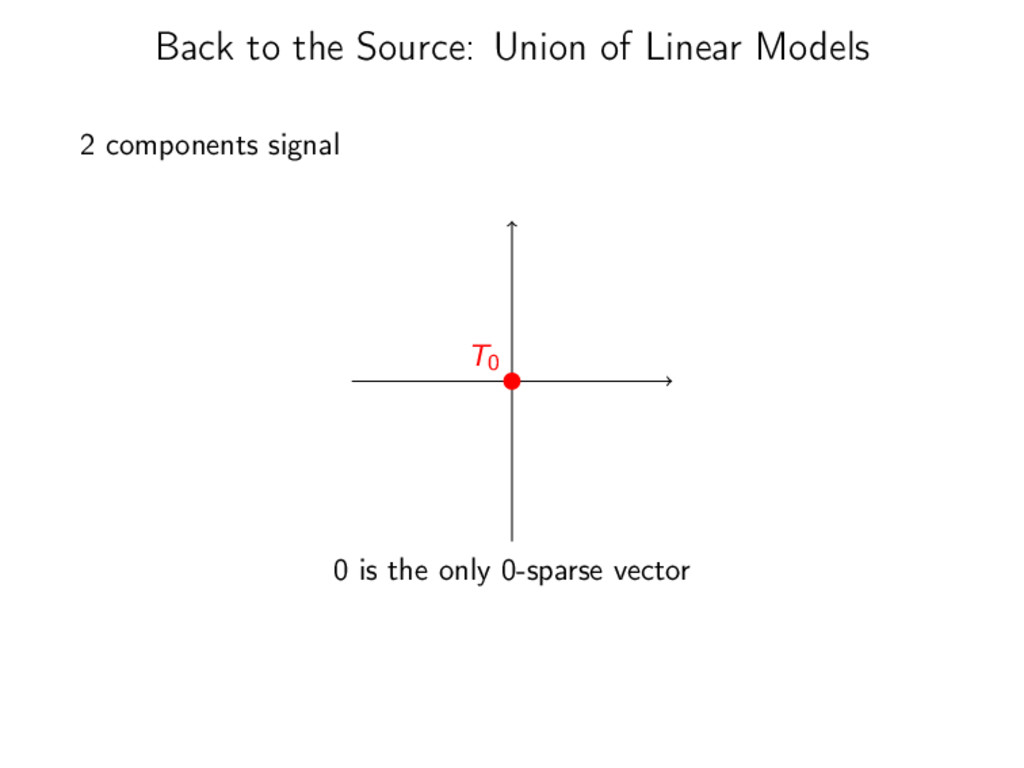
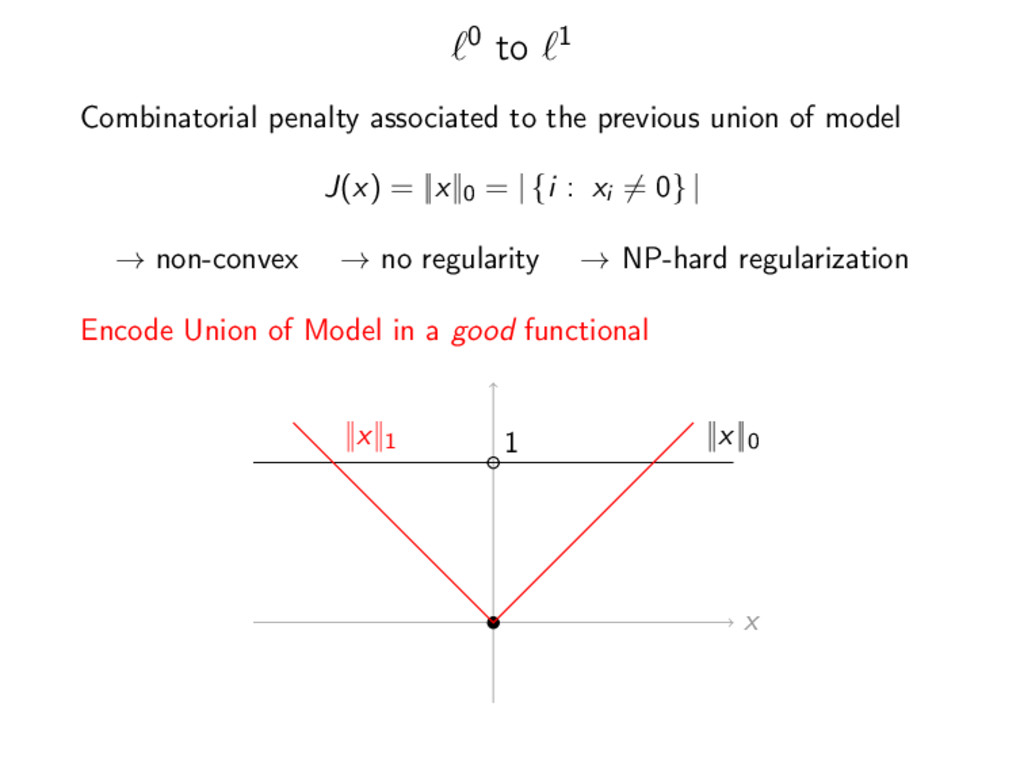
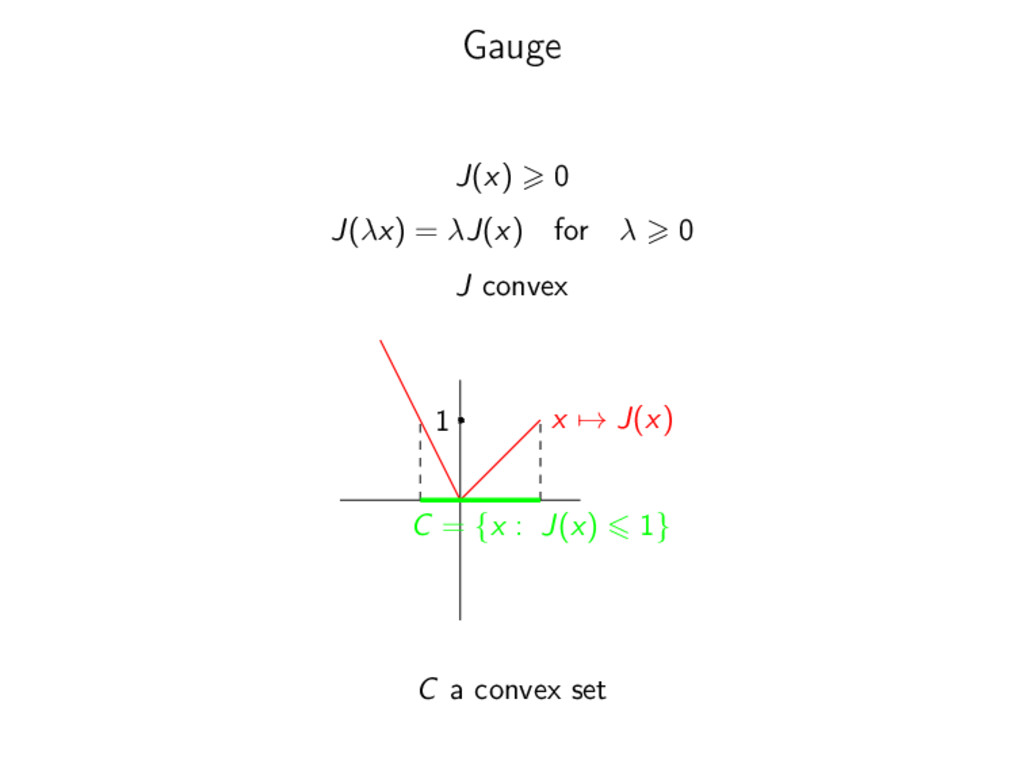
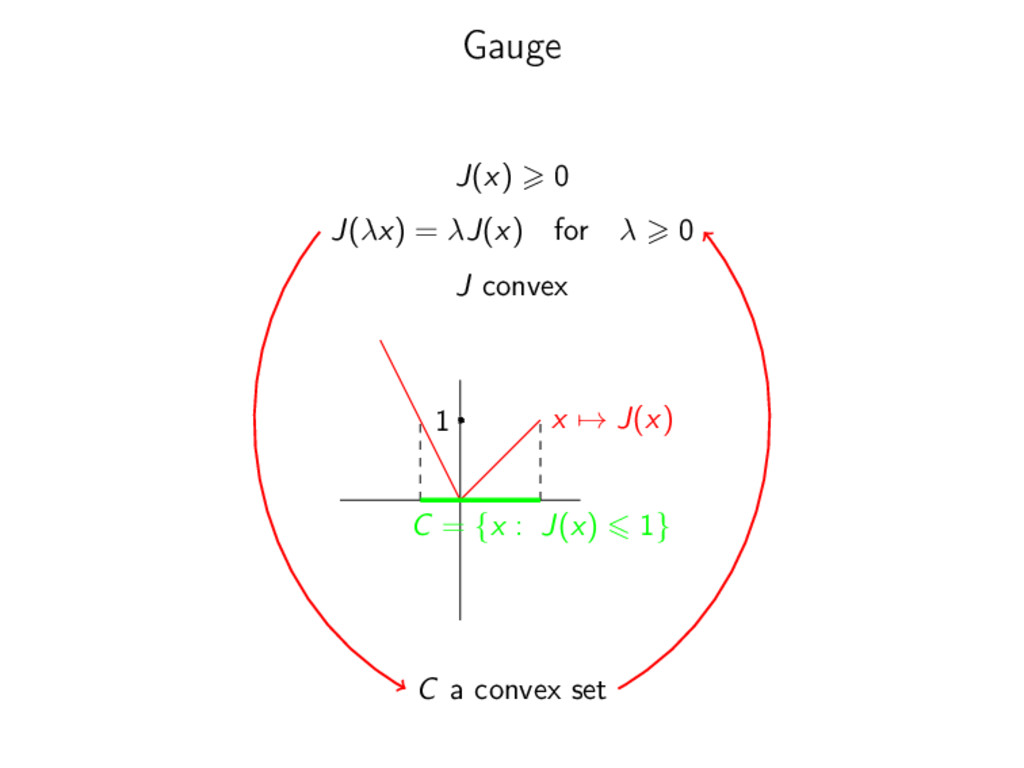
of model J(x) = ||x||0 = | {i : xi = 0} | → non-convex → no regularity → NP-hard regularization Encode Union of Model in a good functional x ||x||0 1 ||x||1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}