SELECT agent_id, 'PLUGIN_NAME' AS tag, avg(data.plugins.PLUGIN_NAME.metrics.buffer_queue_length.value) AS avg_buffer_queue_length FROM fluent_monitoring.win:time_batch(1 minute) GROUP BY agent_id HAVING avg(data.plugins.PLUGIN_NAME.metrics.buffer_queue_length.value) > 76
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
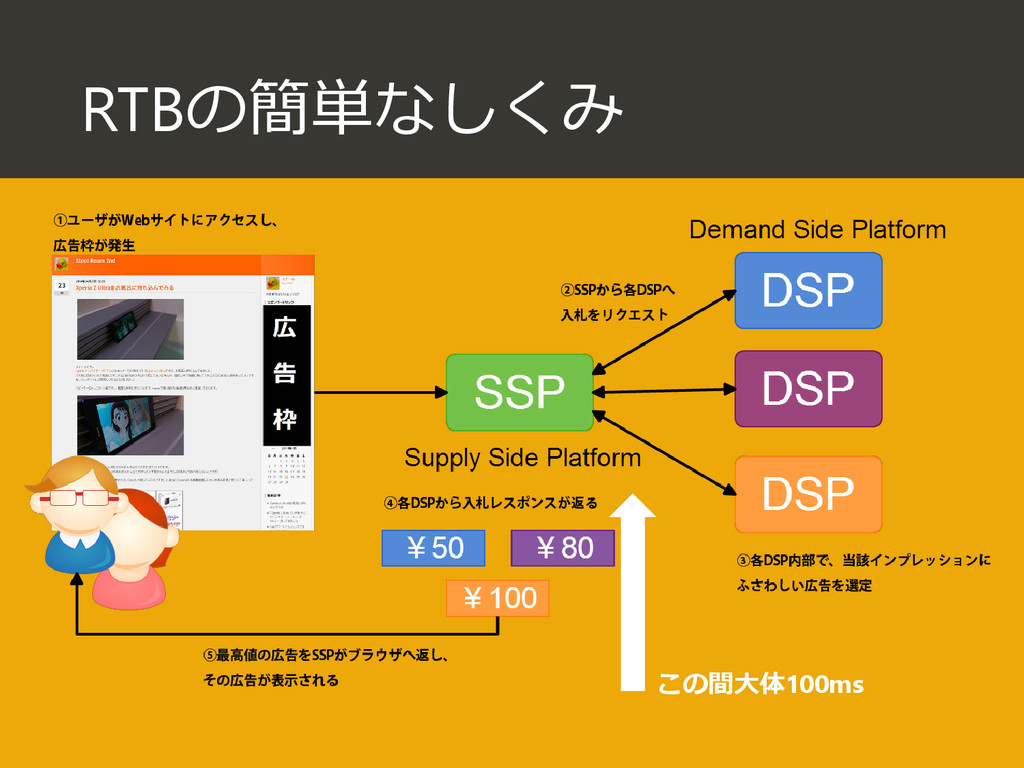{kind=link}
{kind=link}
{kind=link}
{kind=link}
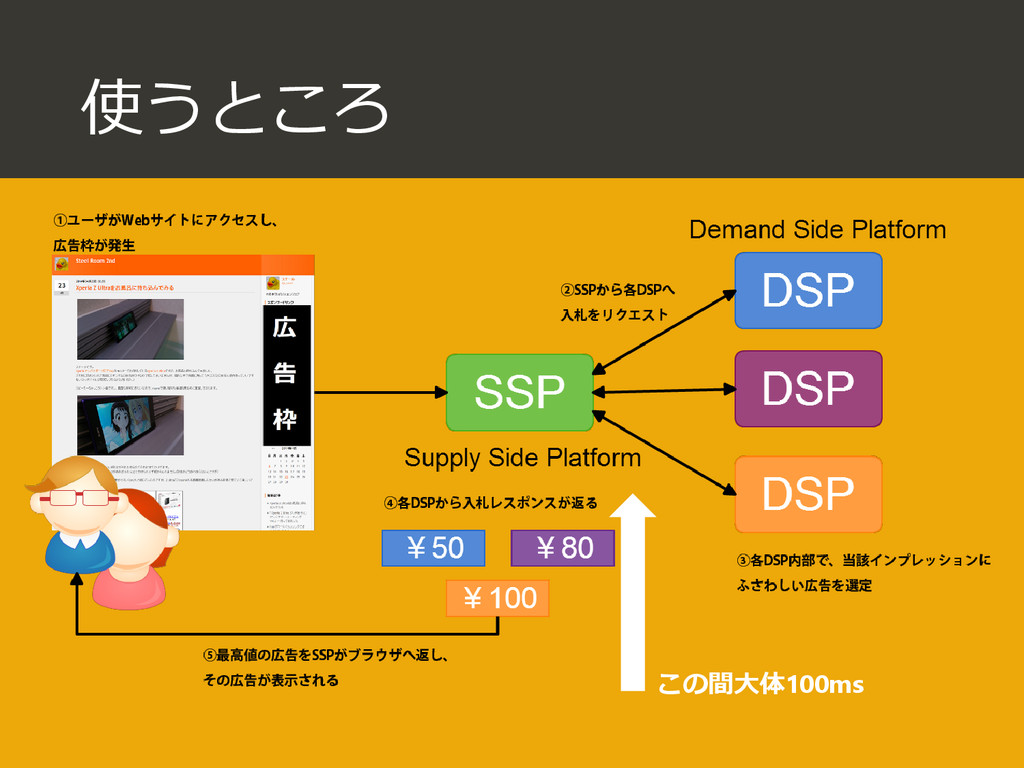{kind=link}
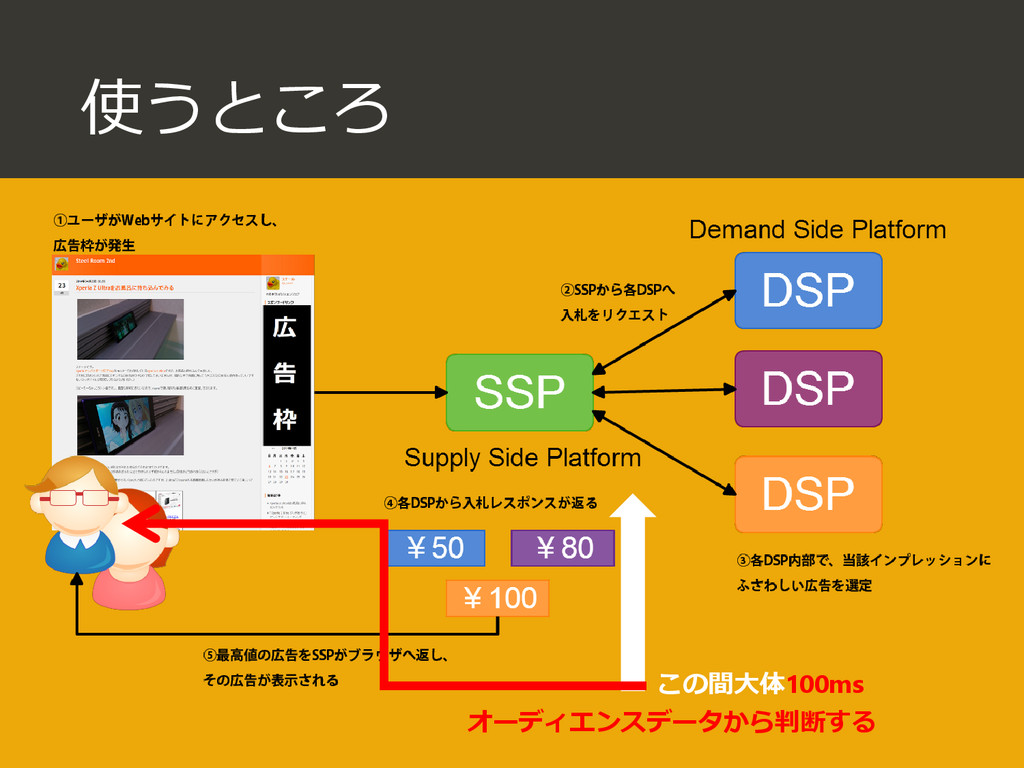{kind=link}
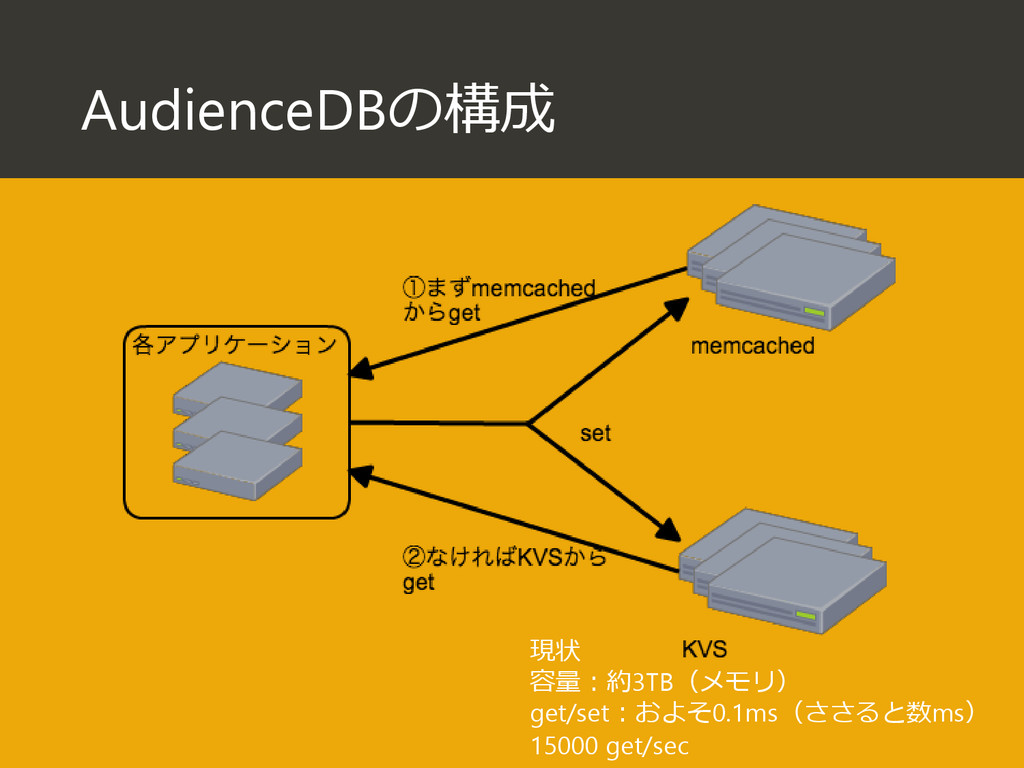{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
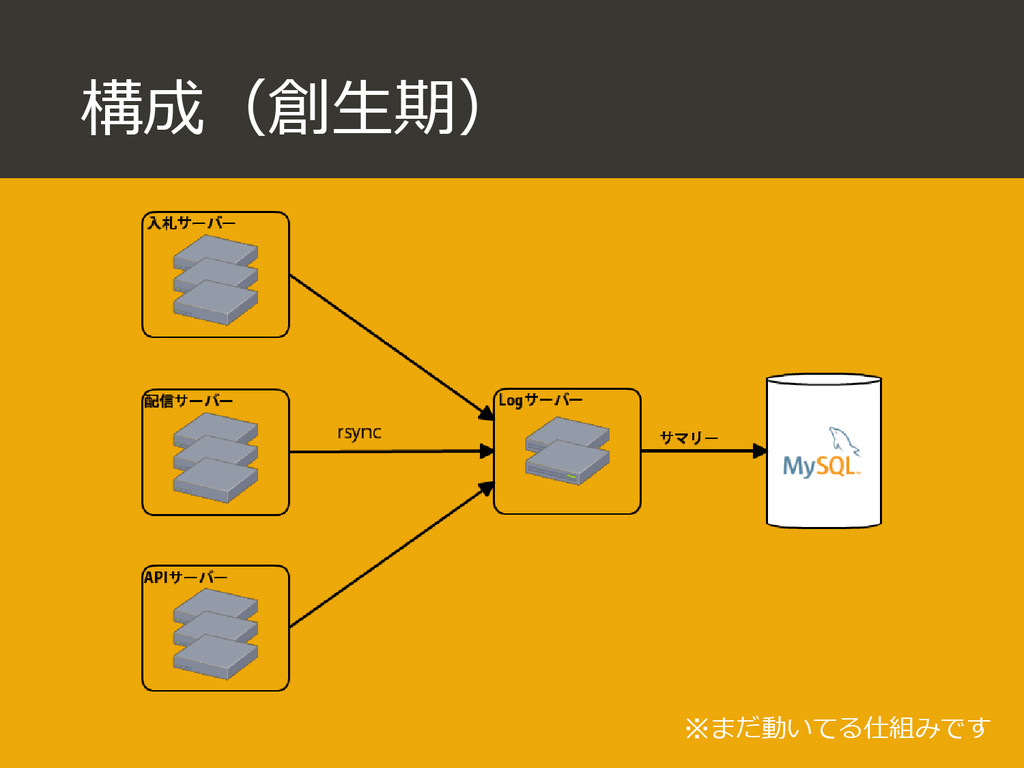{kind=link}
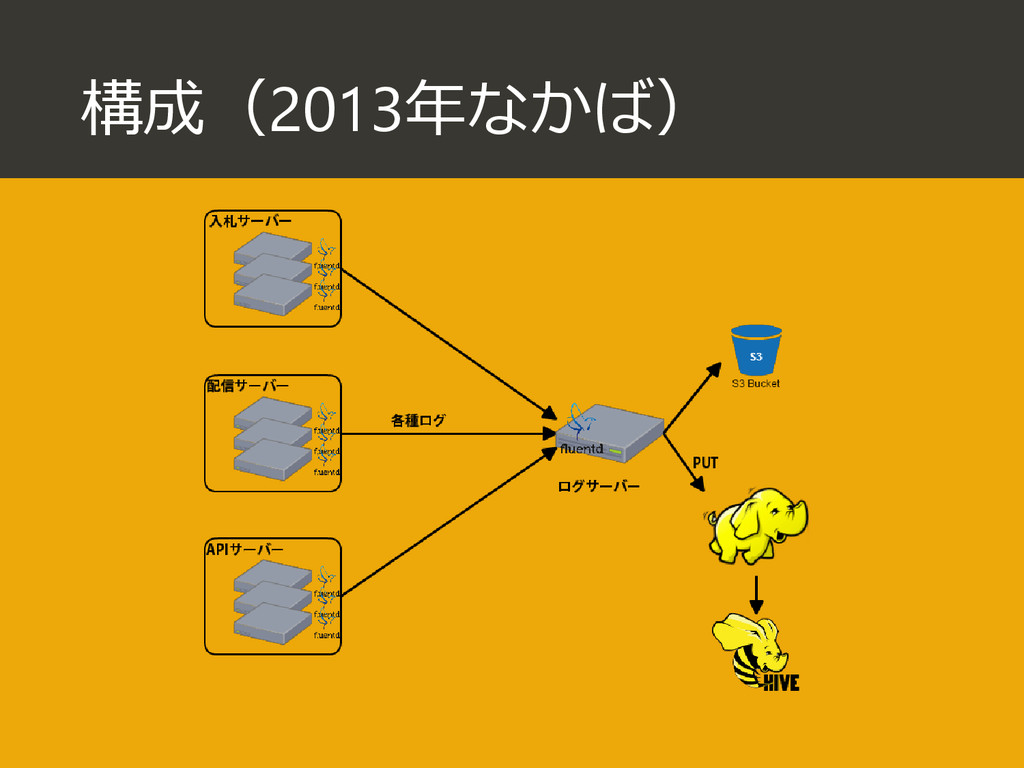{kind=link}
{kind=link}
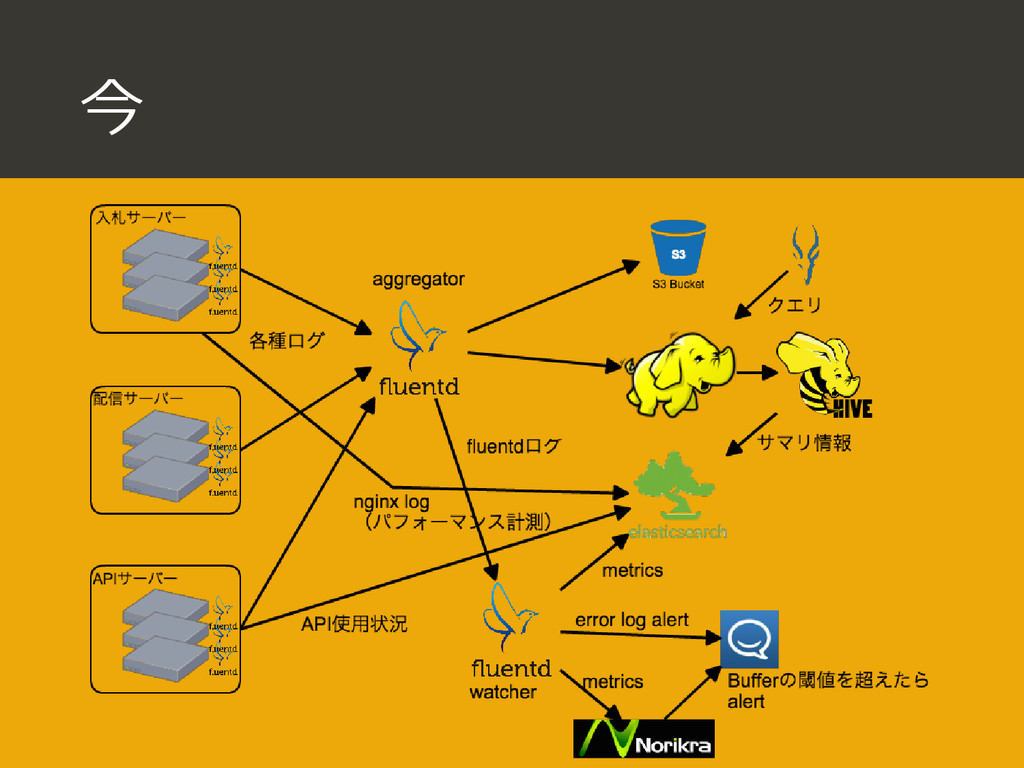{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
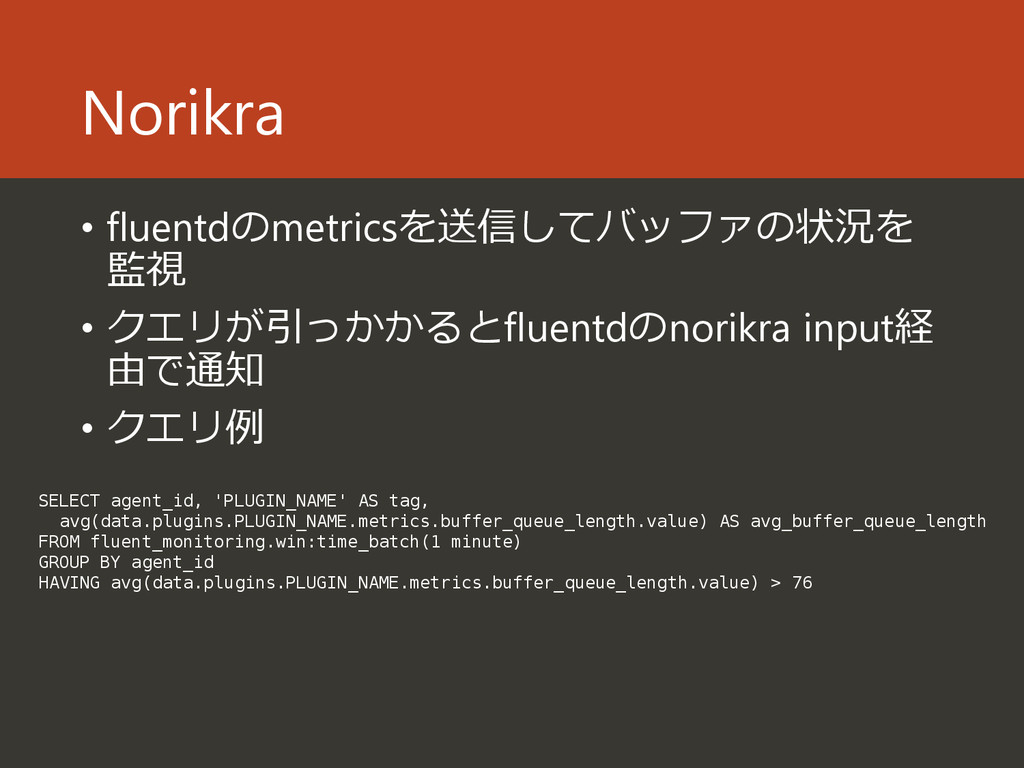{kind=link}
{kind=link}
{kind=link}
{kind=link}