(Harris, 1954), Bag of Word Vector (BoWV) (Gupta et al., 2016) model, paragraph vector models (Le and Mikolov, 2014), Topical word embeddings (TWE-1) (Liu et al.,2015b), Neural Tensor Skip-Gram Model (NTSG1to NTSG-3) (Liu et al., 2015a), tf-idf weighted average word-vector model (Singh and Mukerjee, 2015) weighted Bag of Concepts (weightBoC)(Kim et al., 2017),
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
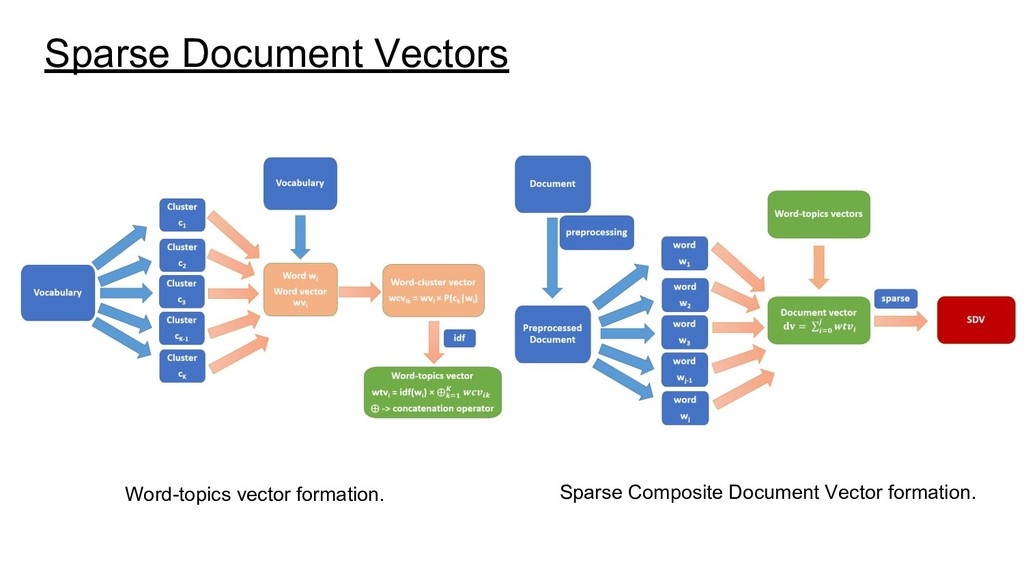{kind=link}
{kind=link}
{kind=link}
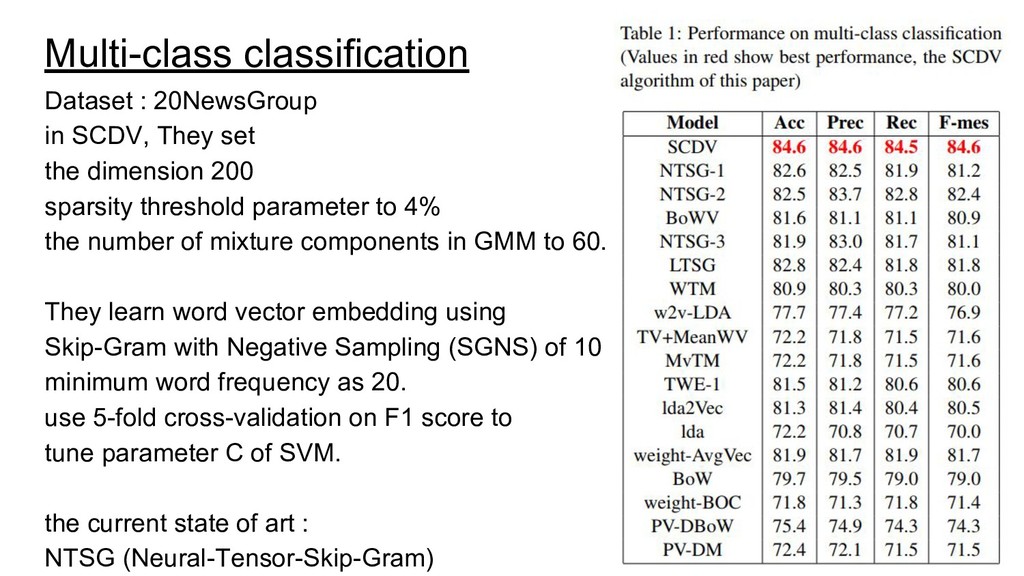{kind=link}
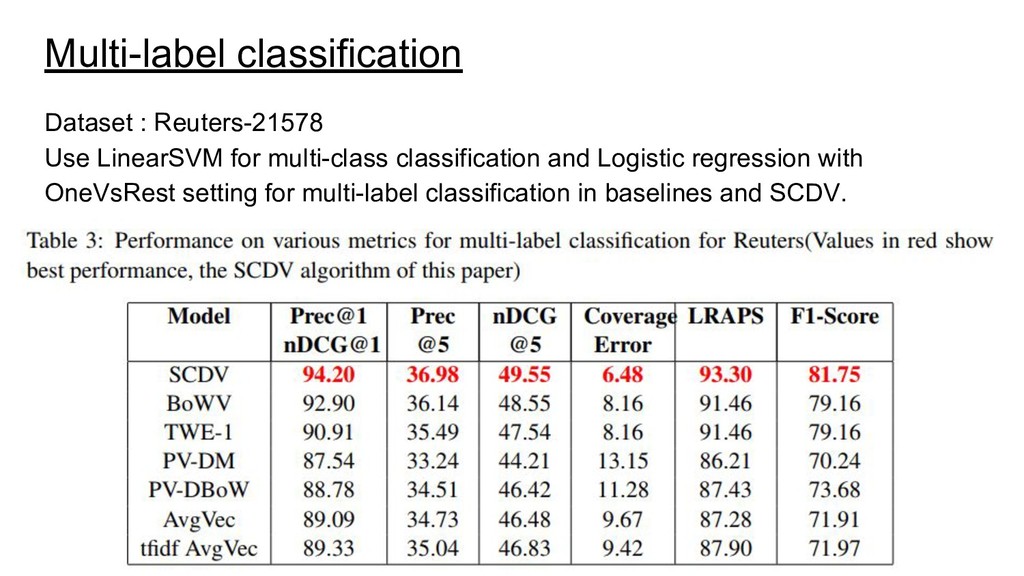{kind=link}
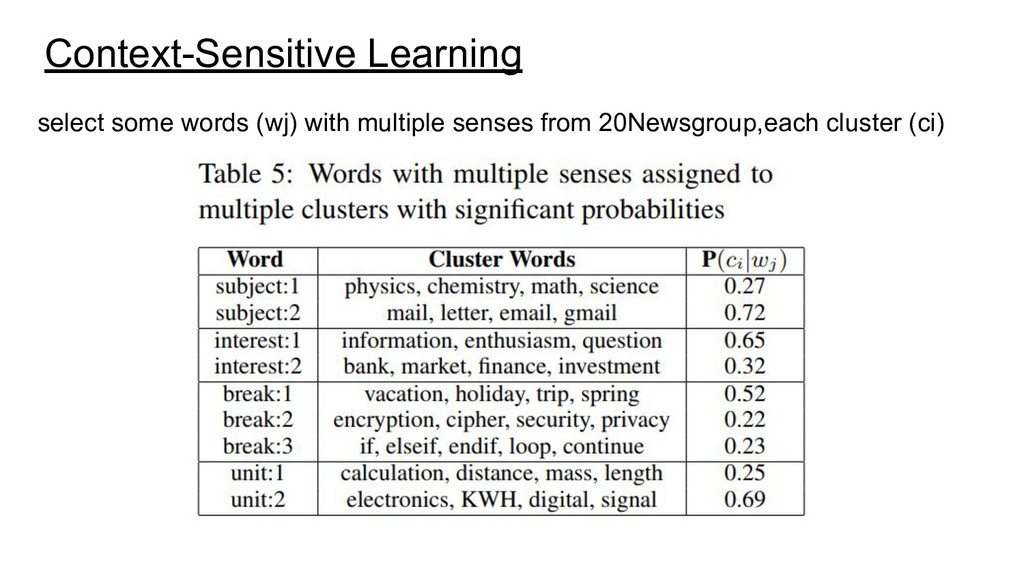{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}