Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[ML輪講] Hindsight Experience Replay
Search
Takuma Seno
April 26, 2018
Technology
840
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[ML輪講] Hindsight Experience Replay
Reading paper of Hindsight Experience Replay at Keio Machine Learning Seminor
Takuma Seno
April 26, 2018
More Decks by Takuma Seno
See All by Takuma Seno
AIは教えてもらわなければ何もできないのか
takuseno
0
1.7k
深層強化学習の動向 / survey of deep reinforcement learning
takuseno
44
48k
DQN速習会@Wantedly
takuseno
4
4.9k
Robot Architecture on Raspberry Pi
takuseno
1
310
Dependent System with Laravel
takuseno
0
800
Other Decks in Technology
See All in Technology
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
460
Jitera Company Deck
jitera
0
260
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
穢れた技術選定について
watany
19
6k
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
520
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
290
20260720_クラウド女子会×PyLadiesTokyoコラボ Amazon Bedrock ハンズオン用資料
yuuka51
1
110
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
140
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
270
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
310
Type-safe IaC for Dart
coborinai
0
180
探索・可視化・自動化を一本化 Amazon Quickでデータ活用スピードを上げる方法
koheiyoshikawa
0
160
Featured
See All Featured
Building Applications with DynamoDB
mza
96
7.1k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
620
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
660
YesSQL, Process and Tooling at Scale
rocio
174
15k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
The Pragmatic Product Professional
lauravandoore
37
7.4k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
270
Skip the Path - Find Your Career Trail
mkilby
1
170
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Transcript
Hindsight Experience Replay Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas
Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, Wojciech Zaremba, NIPS 2017 妹尾卓磨 今井研究室 慶應義塾大学 Keio Machine Learning Seminor 1
自己紹介 妹尾卓磨 今井研究室所属 修士1年 アルバイト Wantedly G社 研究 深層強化学習 内発的動機
2
ロボットにおける強化学習の課題 報酬関数の設計が困難 • 手設計の限界 • ドメイン知識の要求 • 最適な挙動が未知なケース 3
理想的な報酬設定 エピソードの最後に タスクを完了できたかどうかで0, 1を与える 4
実際の問題 探索空間が広すぎて報酬を得ることができない ⇨報酬が得られないと学習ができない 何しても報酬もらえないん ですけど(怒) 5
既存のアプローチ (1) 探索の効率化 例:カウントベースによる探索 Unifying Count-Based Exploration and Intrinsic Motivation
[Bellmare+ 16] 6
既存のアプローチ (2) 報酬関数の作り込み(reward shaping) タスクがうまく行くように促す 例:ゴールに近いほど小さい負の報酬を与える 7
既存のアプローチの課題 探索の効率化 探索空間が広すぎる場合は現実的ではない 報酬関数の作り込み ドメイン知識が要求される 得られた方策が最適ではない場合がある 8
提案手法 失敗エピソードもタスクの目的とは異なるサブゴールとして経験を 保存して学習する深層強化学習手法 Hindsight Experience Replay (HER) を提案 報酬がスパースな環境でなかなかタスクが達成できなくても 別のゴールを設定して学習を進ませることが可能
9
コンセプト: ホッケーの例 人がホッケーをプレイしている時の学習 10
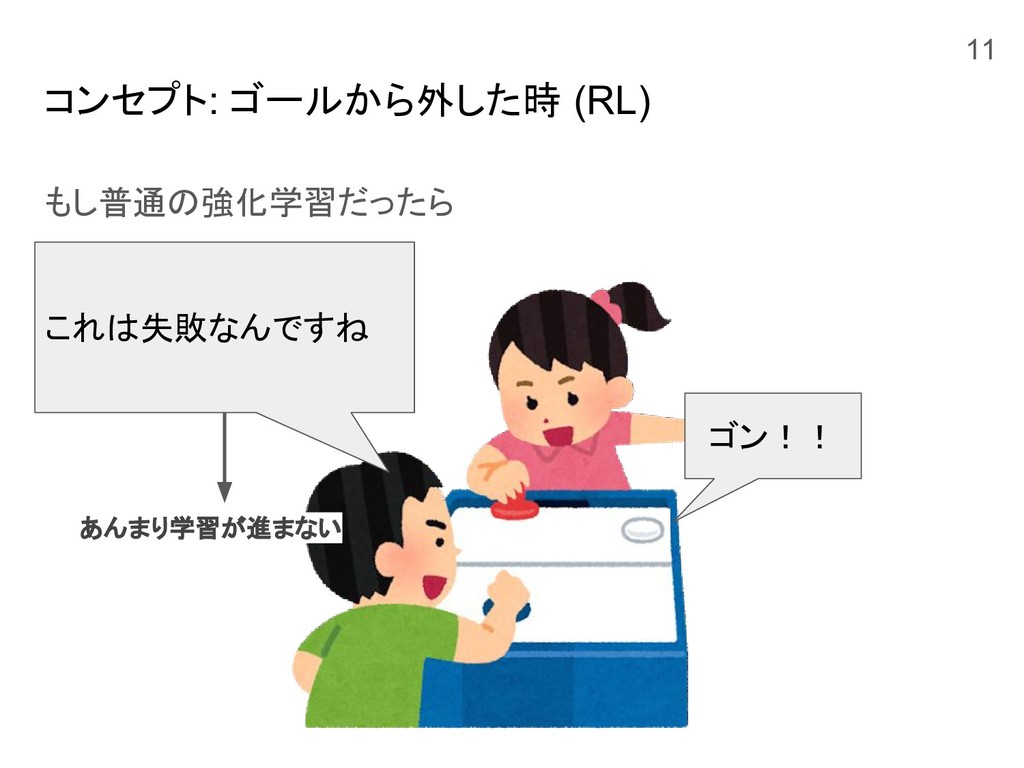
コンセプト: ゴールから外した時 (RL) もし普通の強化学習だったら ゴン!! これは失敗なんですね あんまり学習が進まない 11
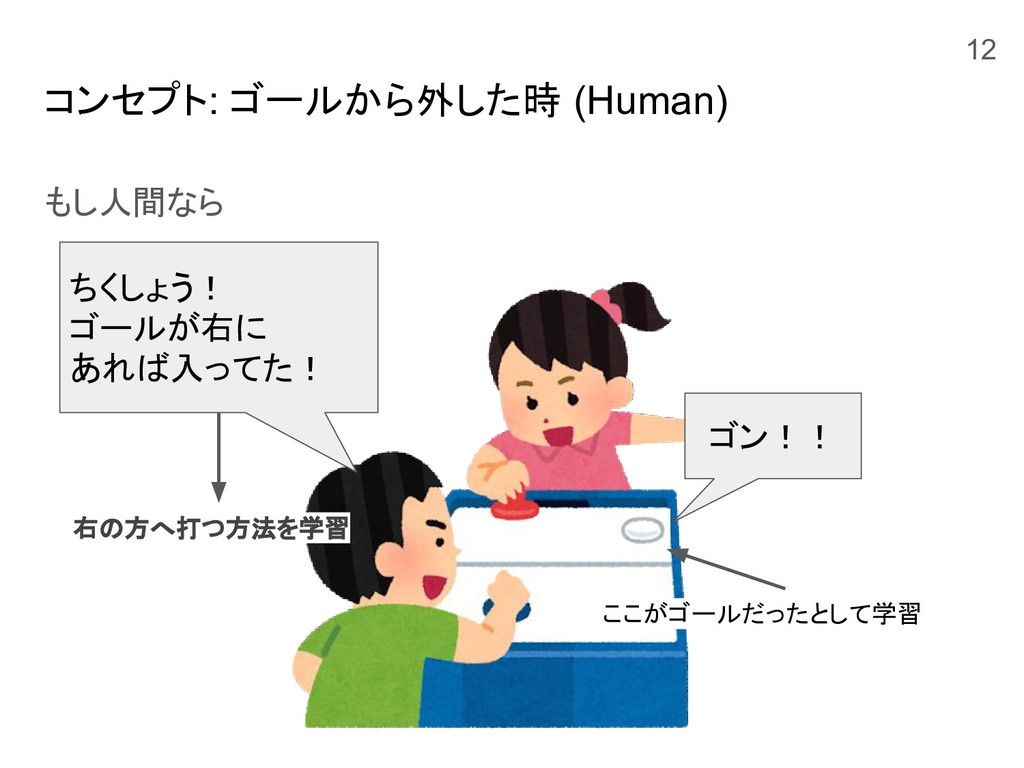
コンセプト: ゴールから外した時 (Human) もし人間なら ゴン!! ちくしょう! ゴールが右に あれば入ってた! 右の方へ打つ方法を学習 ここがゴールだったとして学習
12
Hindsight Experience Replay 13
エピソードを経験 (1) エピソードを経験 14
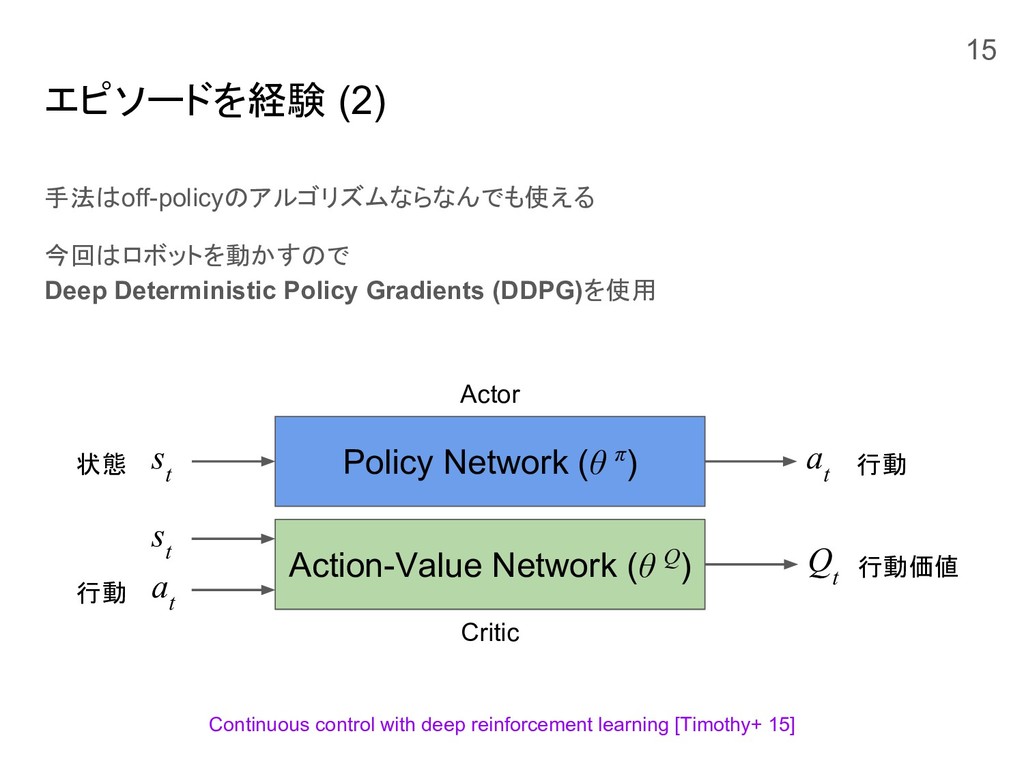
エピソードを経験 (2) 手法はoff-policyのアルゴリズムならなんでも使える 今回はロボットを動かすので Deep Deterministic Policy Gradients (DDPG)を使用 Continuous
control with deep reinforcement learning [Timothy+ 15] Policy Network (θ π) Action-Value Network (θ Q) s t s t a t Q t 状態 行動 行動価値 a t 行動 Actor Critic 15
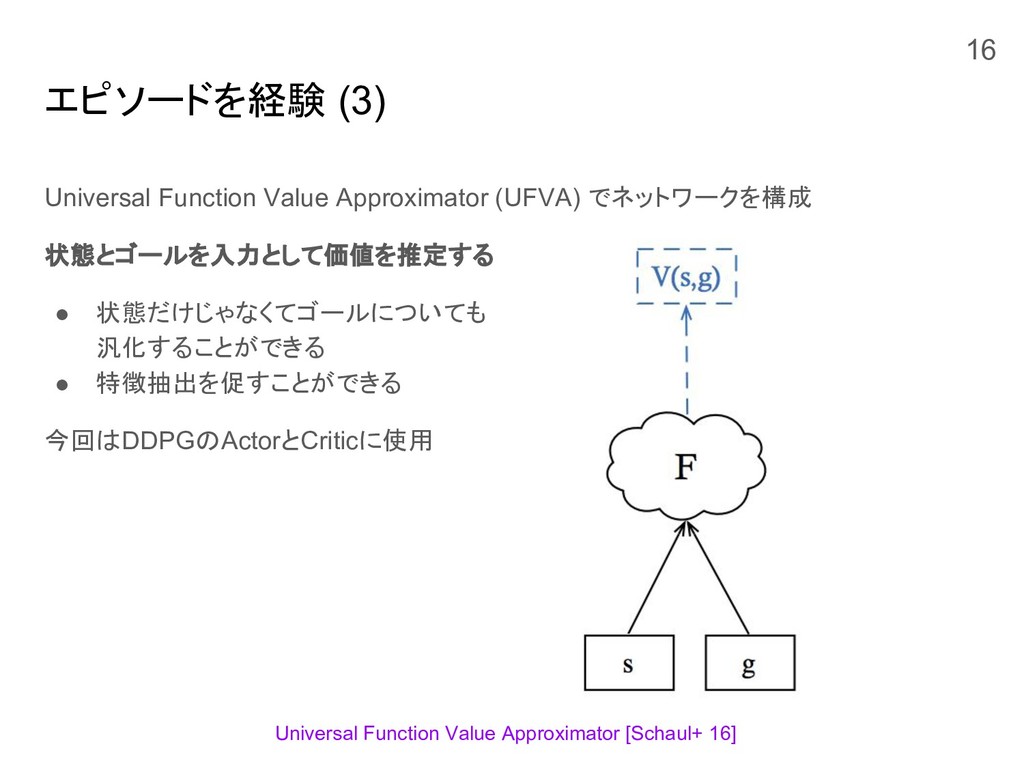
エピソードを経験 (3) Universal Function Value Approximator (UFVA) でネットワークを構成 状態とゴールを入力として価値を推定する •
状態だけじゃなくてゴールについても 汎化することができる • 特徴抽出を促すことができる 今回はDDPGのActorとCriticに使用 Universal Function Value Approximator [Schaul+ 16] 16
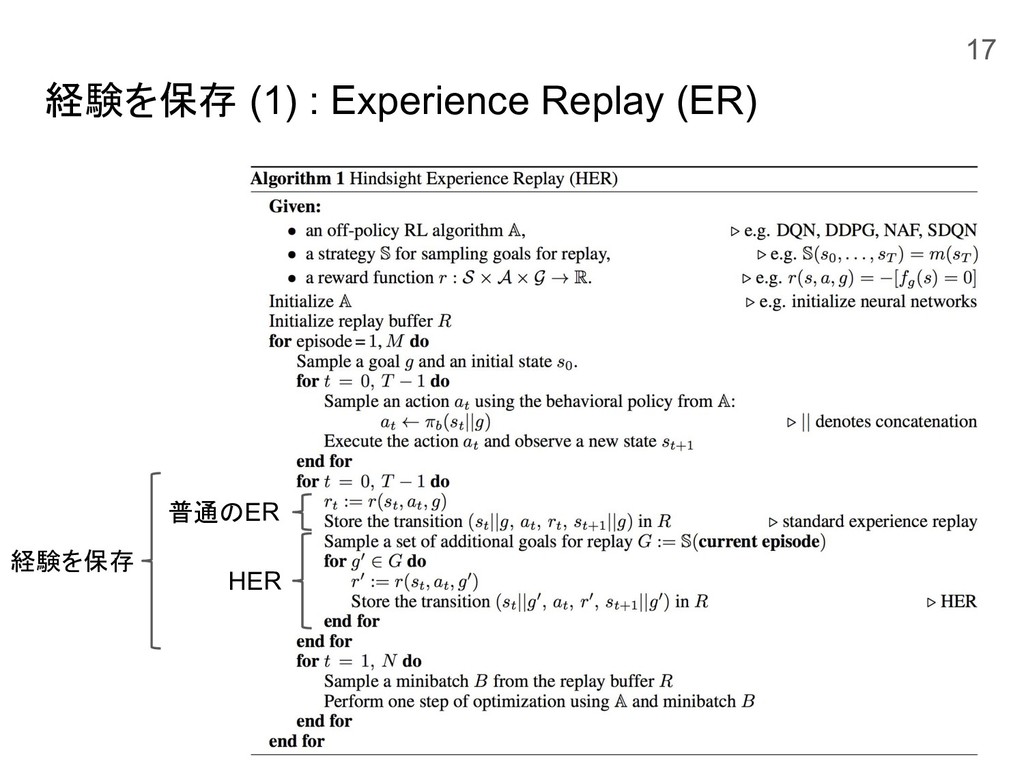
経験を保存 (1) : Experience Replay (ER) 経験を保存 普通のER HER 17
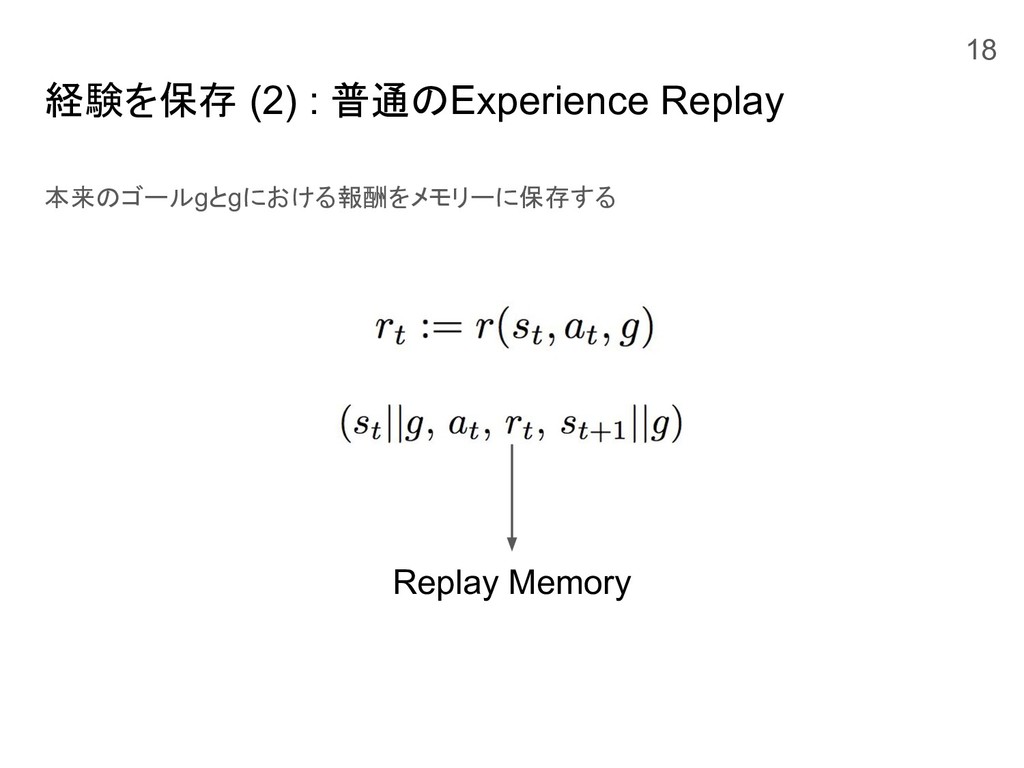
経験を保存 (2) : 普通のExperience Replay 本来のゴールgとgにおける報酬をメモリーに保存する Replay Memory 18
経験を保存 (3) : Hindsight Experience Replay ゴールを選択する方法Gにしたがってg’を決定して経験を保存する Gの例: エピソードの最終状態s T
をg’とする (final) Replay Memory 19
経験をサンプリングして学習 サンプリングした経験 から学習 20
実験 MuJoCoエンジンを使ったロボットシミュレータでタスクを学習 7自由度のロボットを用いて3タスクで性能を評価 Pusing Sliding Pick-and-place 21
実験詳細 観測 グリップの絶対位置,物体と対象物の相対位置,指の間隔 Criticには追加でグリップと指の速度と物体の相対速度と相対角速度 ゴール 動かしたい目的の場所(物体の位置はエピソードごとにランダム) 報酬 物体を閾値以下まで動かせれば1,そうでなければ0 22
実験の様子 23
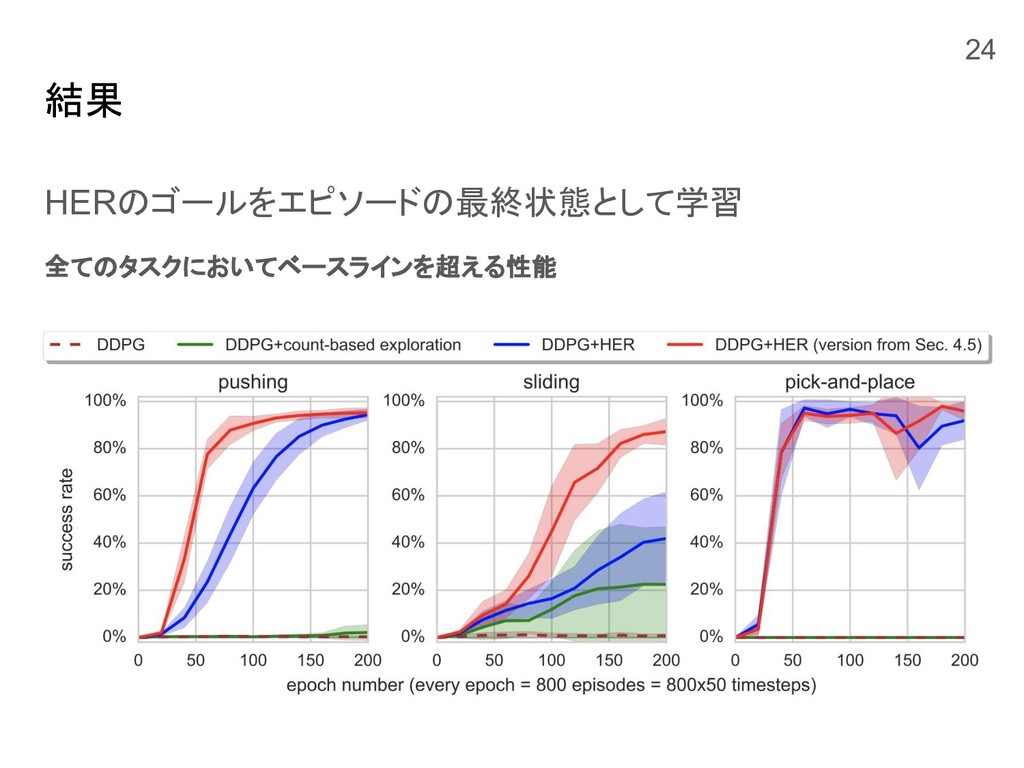
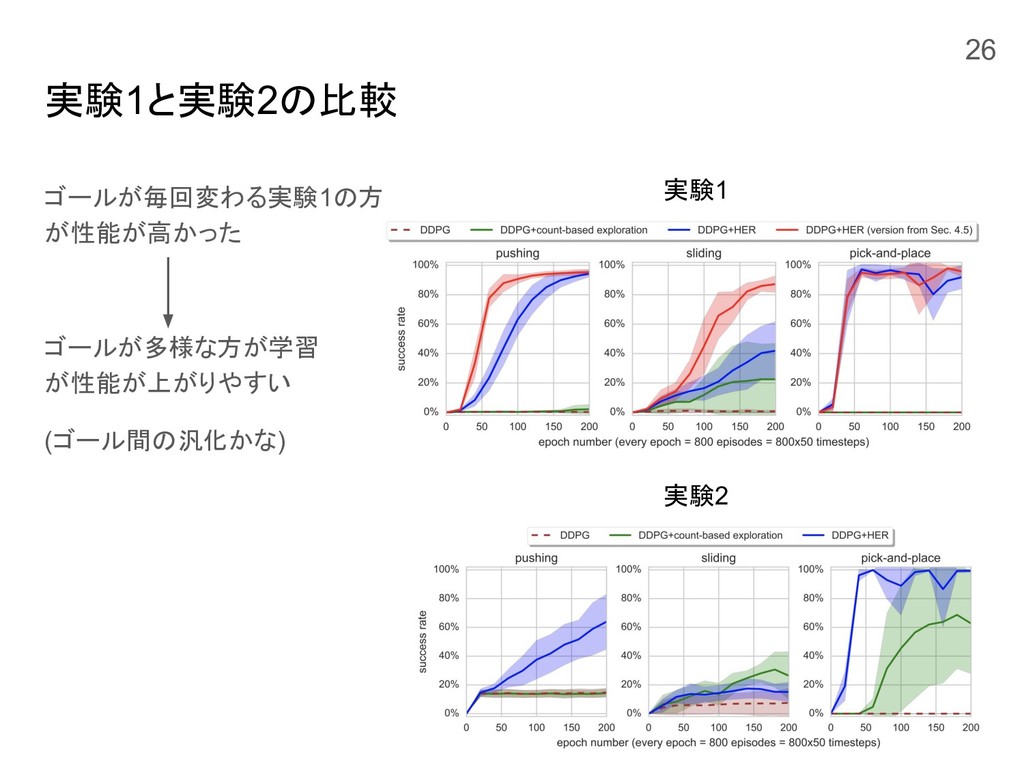
結果 HERのゴールをエピソードの最終状態として学習 全てのタスクにおいてベースラインを超える性能 24
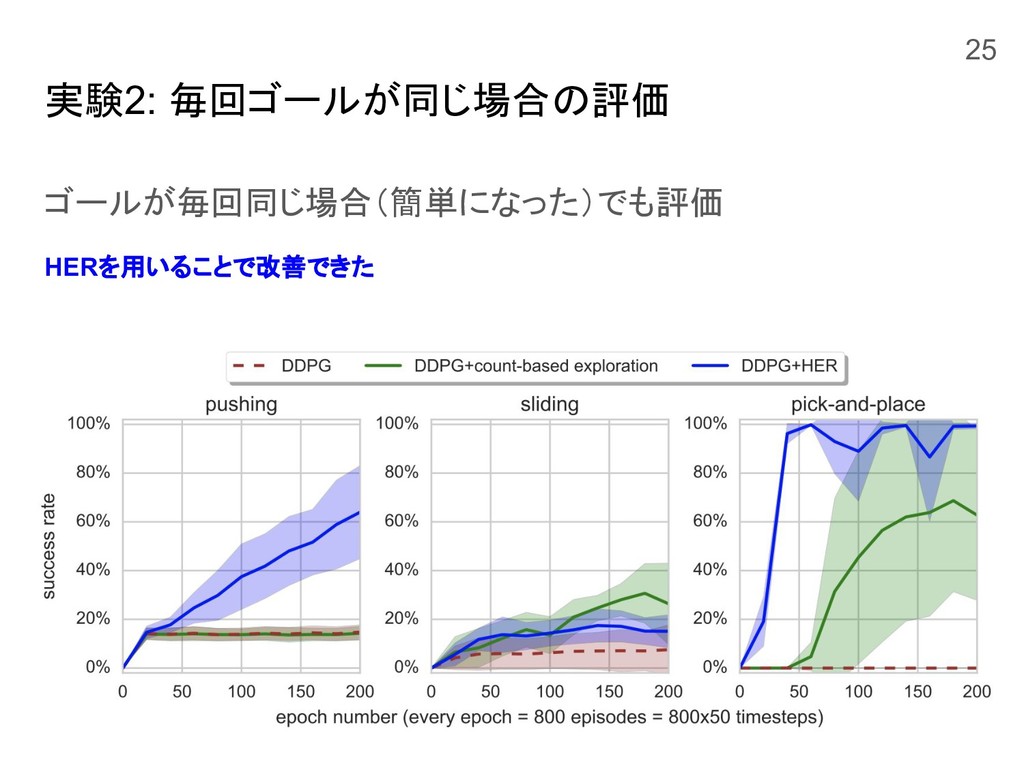
実験2: 毎回ゴールが同じ場合の評価 ゴールが毎回同じ場合(簡単になった)でも評価 HERを用いることで改善できた 25
実験1と実験2の比較 ゴールが毎回変わる実験1の方 が性能が高かった ゴールが多様な方が学習 が性能が上がりやすい (ゴール間の汎化かな) 実験1 実験2 26
実験3: reward shaping での学習 reward shapingを行って学習ができるかどうか評価 動かした時に物体に近づくほど大きな報酬が発生するように設定 次のステップでの位置 定数 HERを用いても学習ができなくなった
27
reward shapingして学習ができなくなった理由 報酬関数によって最適化されるものと目指してるものが違う 直感的に設計した報酬がタスクの最適化と合致しているとは限らない 報酬関数が探索を抑制してしまう ちょっとでも物体を動かすと負の報酬を受け取ってしまい,物体を動かさないのが最適 方策となってしまっている 28
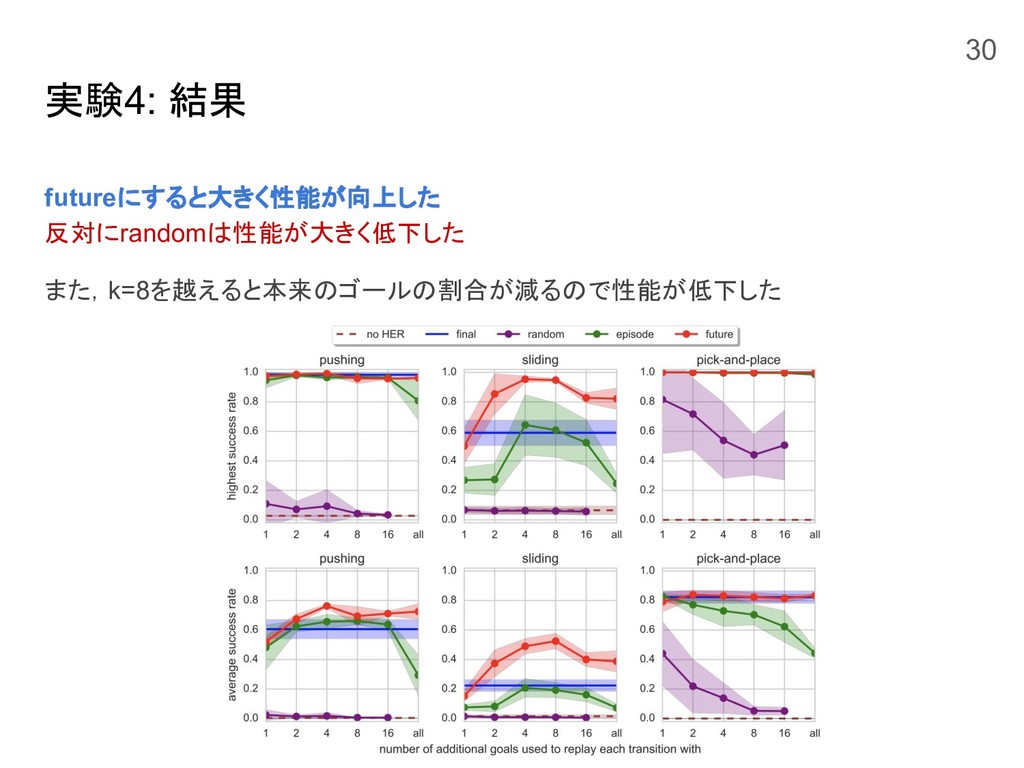
実験4: Gの戦略を色々変えてみる 新たに3つのGの戦略を加えて評価 future ランダムに同一エピソードで今後訪れるk個の状態をゴールにする episode ランダムに同一エピソードで訪れるk個の状態をゴールにする random ランダムに学習中に訪れたk個の状態をゴールにする 29
実験4: 結果 futureにすると大きく性能が向上した 反対にrandomは性能が大きく低下した また,k=8を越えると本来のゴールの割合が減るので性能が低下した 30
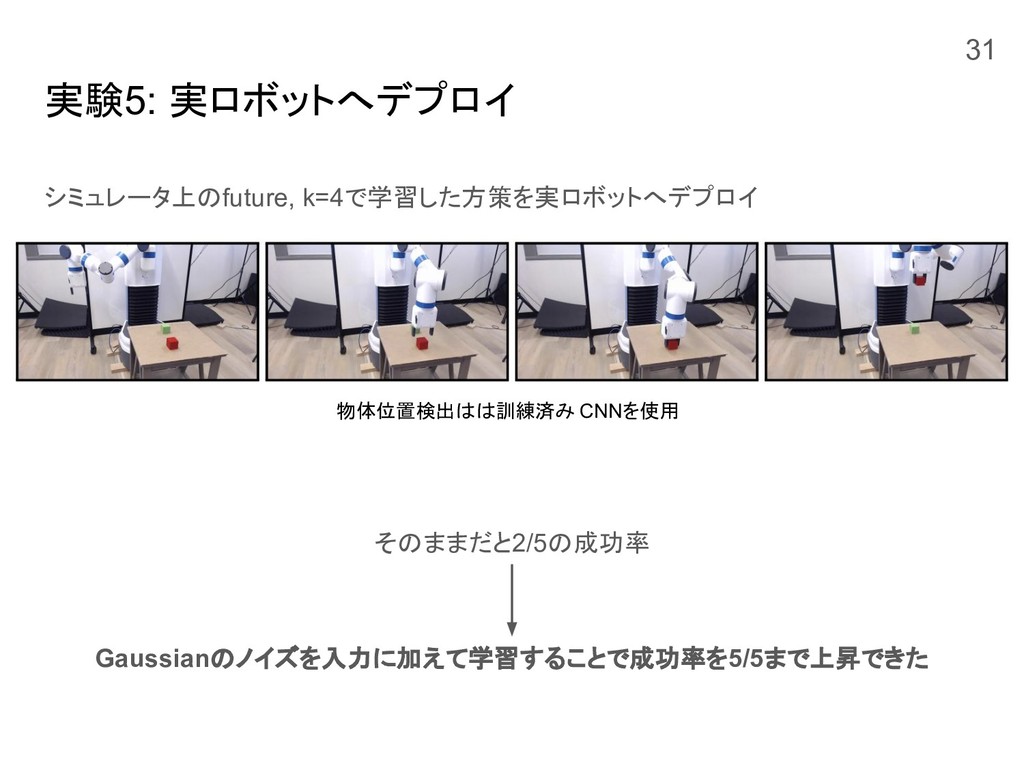
実験5: 実ロボットへデプロイ シミュレータ上のfuture, k=4で学習した方策を実ロボットへデプロイ そのままだと2/5の成功率 Gaussianのノイズを入力に加えて学習することで成功率を5/5まで上昇できた 物体位置検出はは訓練済み CNNを使用 31
HERを用いた後続の研究 OpenAIはこれ以降ロボットの学習に強化学習を用いる研究を盛んにしている • Sim-to-Real Transfer of Robotic Control with Dynamics Randomization
[Xue+ 17] シミュレーションの環境にノイズを加えることで汎化性能を向上させて実環境に耐える方 策を学習する • Overcoming Exploration in Reinforcement Learning with Demonstrations [Ashvin+ 17] 人のデモンストレーションを使用して学習するかどうかをCriticの評価で決定することで デモンストレーション以上の方策を学習する • Asymmetric Actor Critic for Image-Based Robot Learning [Lerrel+ 17] Actorの入力は限られているが,Criticには全情報を与えることで効率的に実環境でも使 用できる方策を学習する 32
総評 • 失敗エピソードでもゴールを自分で設定することで学習を促す ことができた • 最近UVFAを使った論文が増えてきているので,UVFAに時代 が追いついてきた ◦ マルチタスク ◦
ゴールの汎化による未知タスクへのアプローチ • 人間による報酬ハンドエンジニアリングを超えてくるあたりがま さに深層強化学習の真骨頂という感じ 33
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}