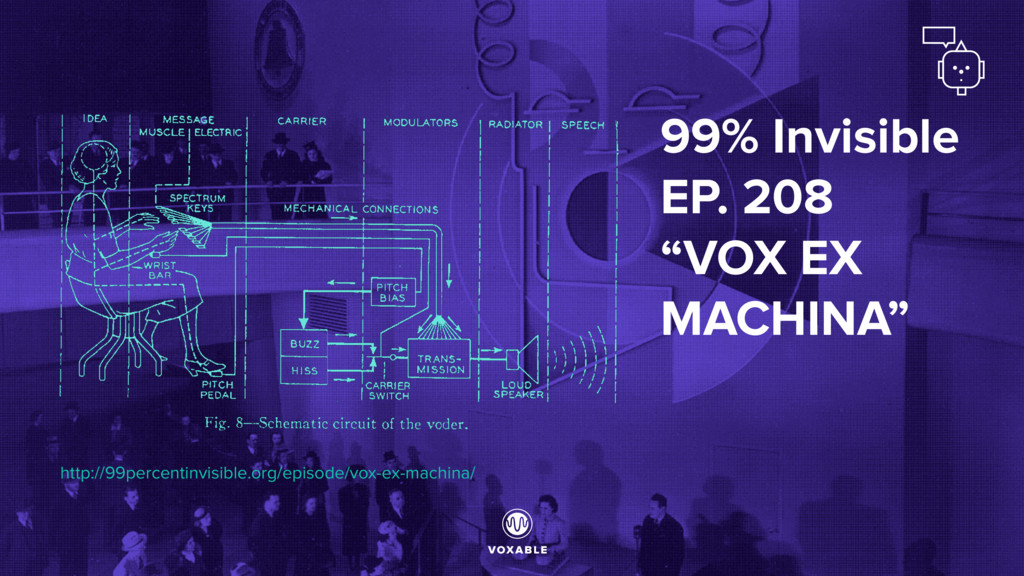
century • Inventor of the term “transistor” • “There are strong reasons for believing that spoken English is… not recognizable phoneme by phoneme or word by word.” 1969: John Robinson Pierce https://en.wikipedia.org/wiki/Speech_recognition#History
Friday after 4pm.” Sure thing! Would you like to fly first class, business class, or coach? First class Classy! And would you like a meal on this flight? Perfect! Here are a list of flights that match your criteria. Yes, of course. find flights first class first class, yes to meal departure city: Austin
xmlns="http://www.w3.org/2001/10/synthesis" xml:lang="en-US"> <s><prosody pitch="x-high">I'm a mouse.</prosody></s> <s><prosody pitch="x-low">I'm a house.</prosody></s> <p> <s>That is <emphasis>huge</emphasis> news!</s> <s>That is a <emphasis level="strong">hefty</emphasis> fine!</s> </p> </speak>
with the schedule, but where are the restrooms? Hello there! Welcome to the conference. You can say: “show me a map”, “schedule”, or “contact organizers.” Great! Here’s the schedule…
item) is it possible to return something is it possible to return an item can I return something can I return an item how do I return something how do I return an item Expando
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
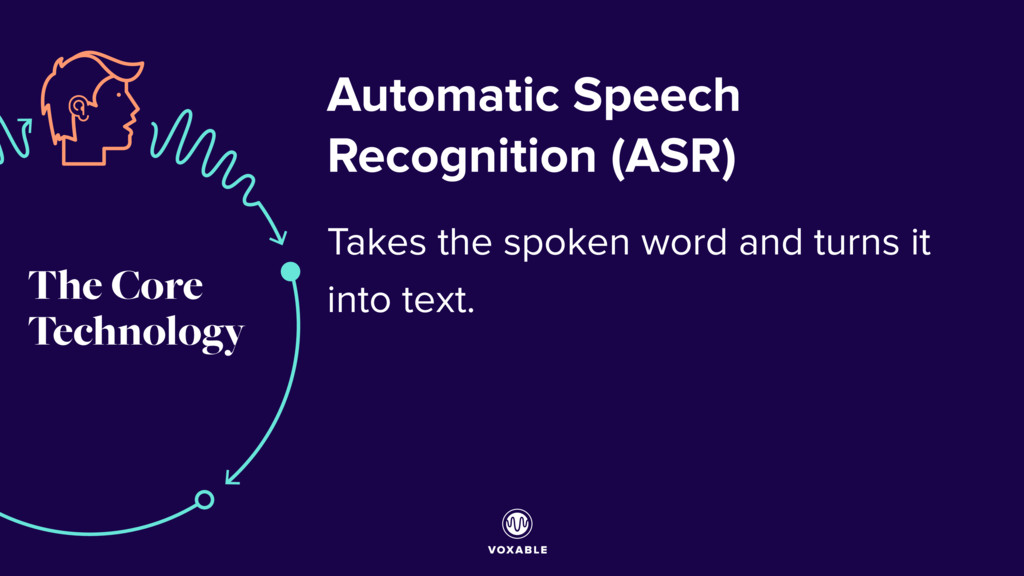{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
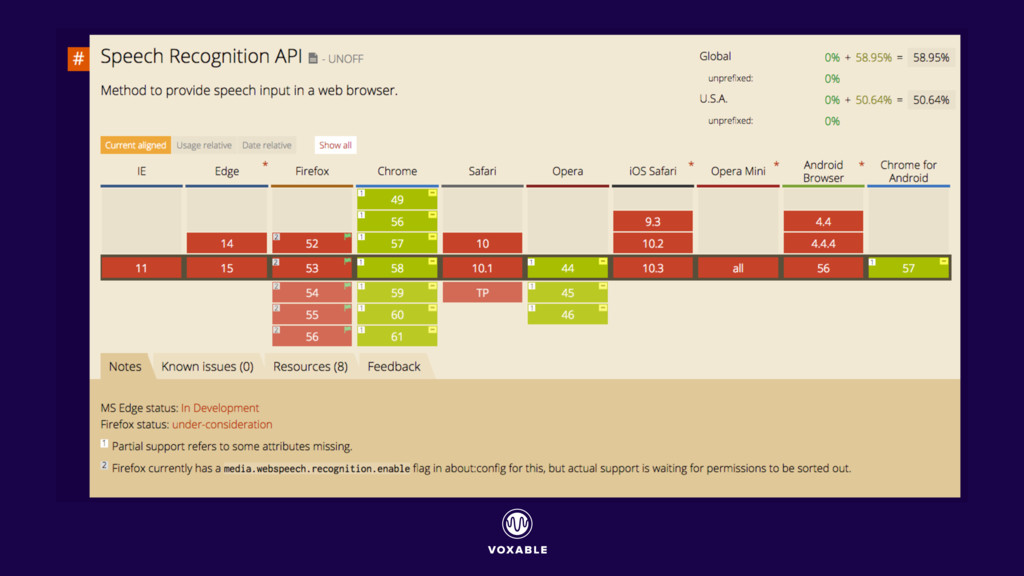{kind=link}
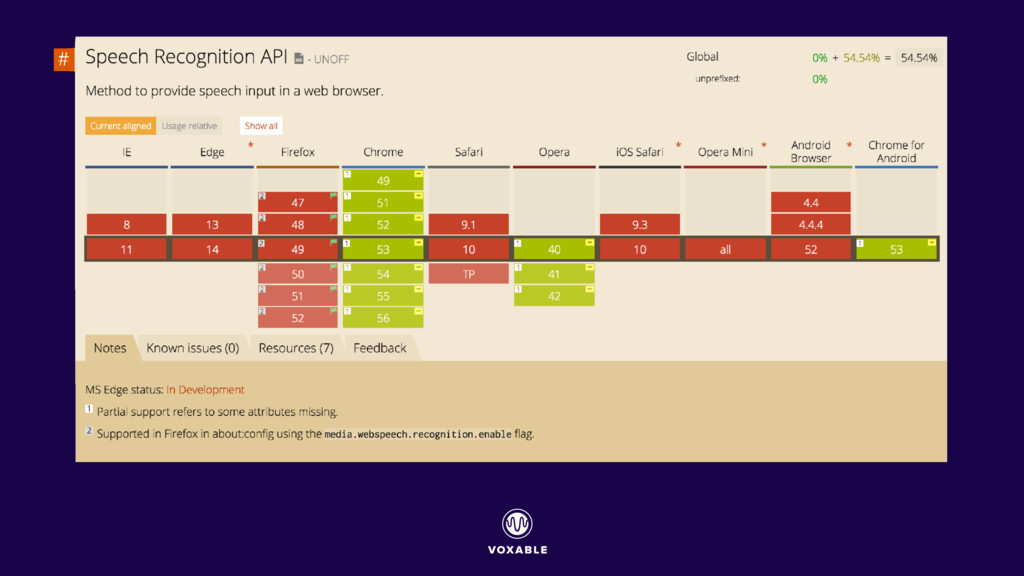{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}