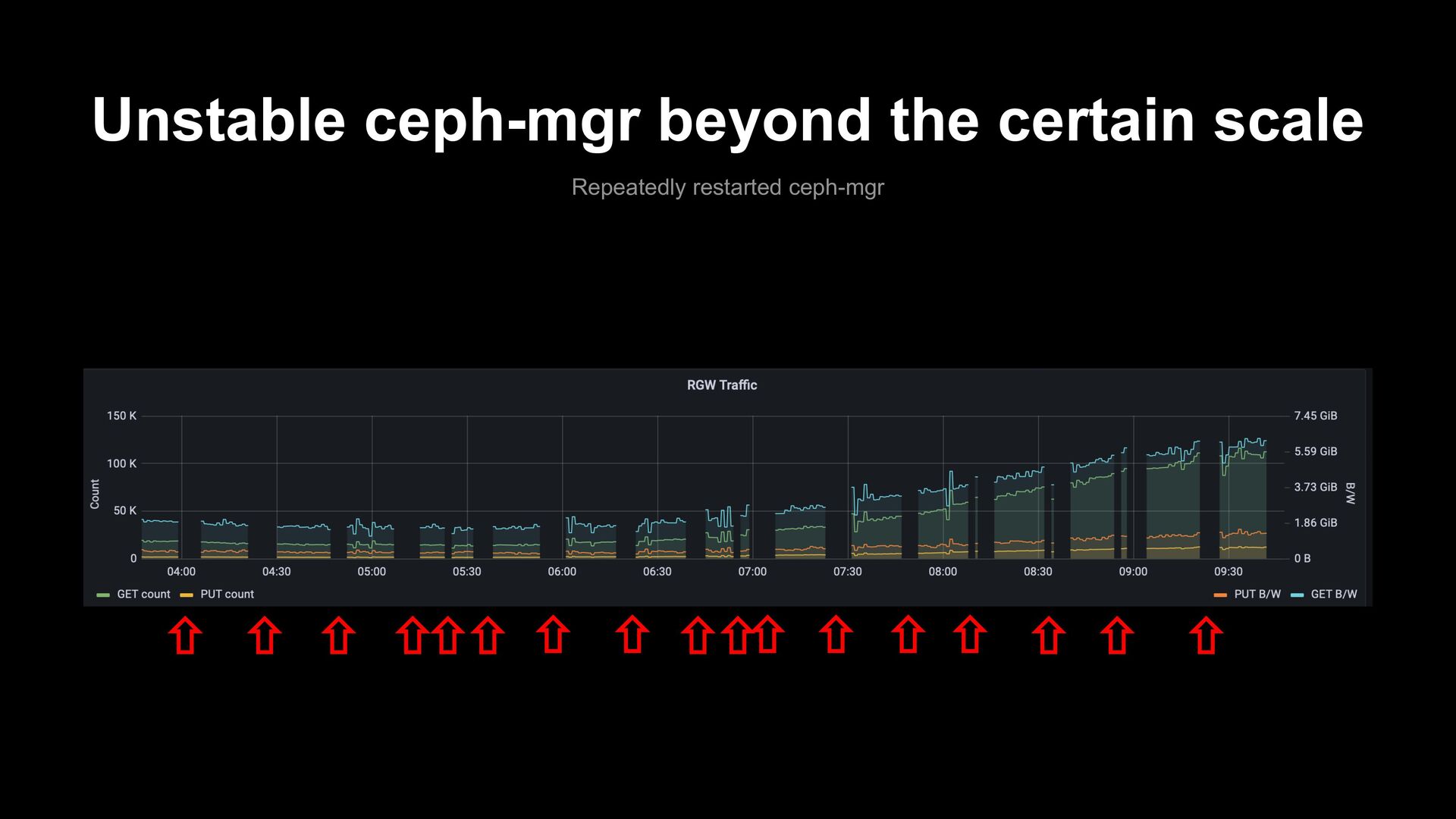
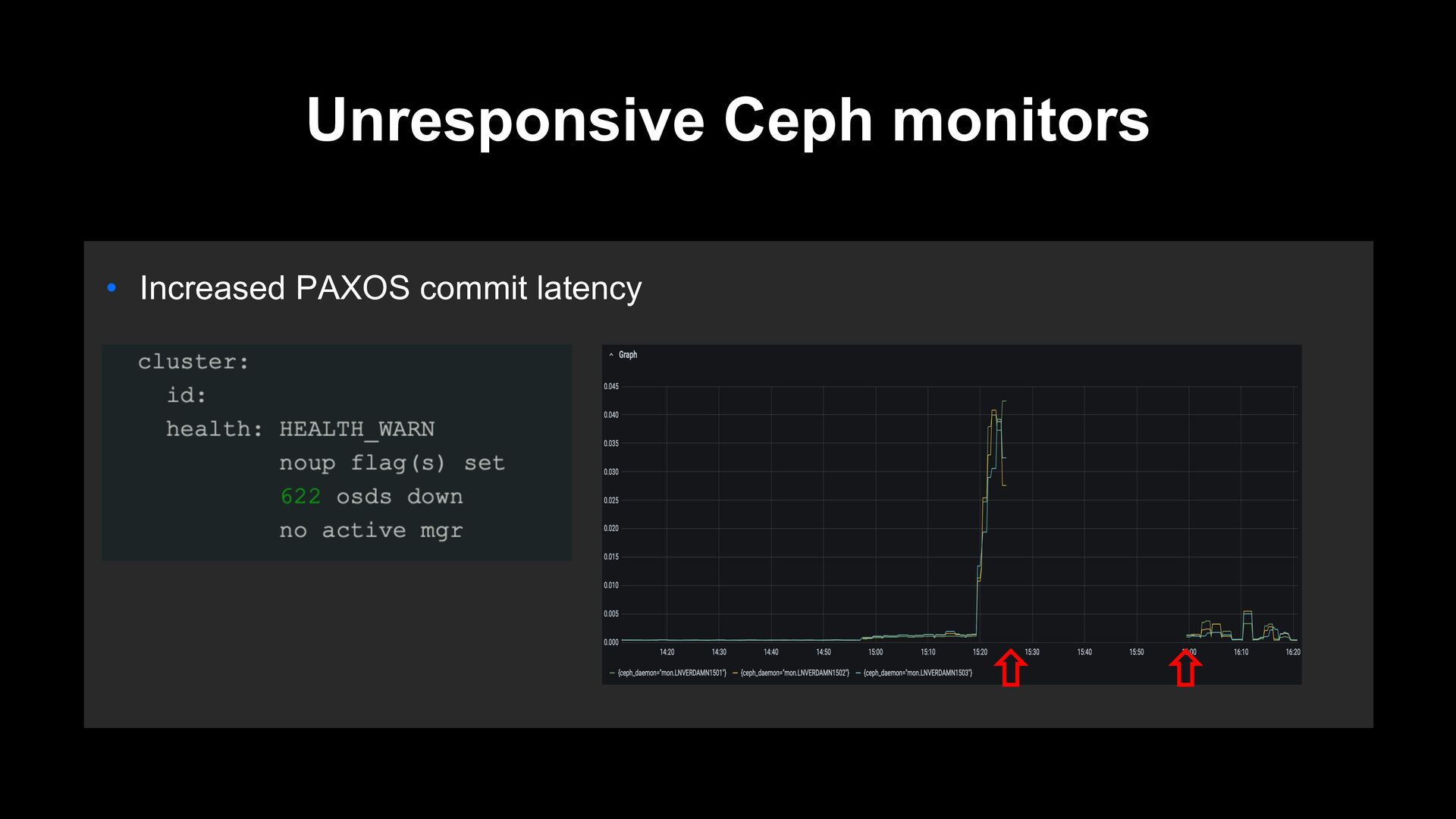
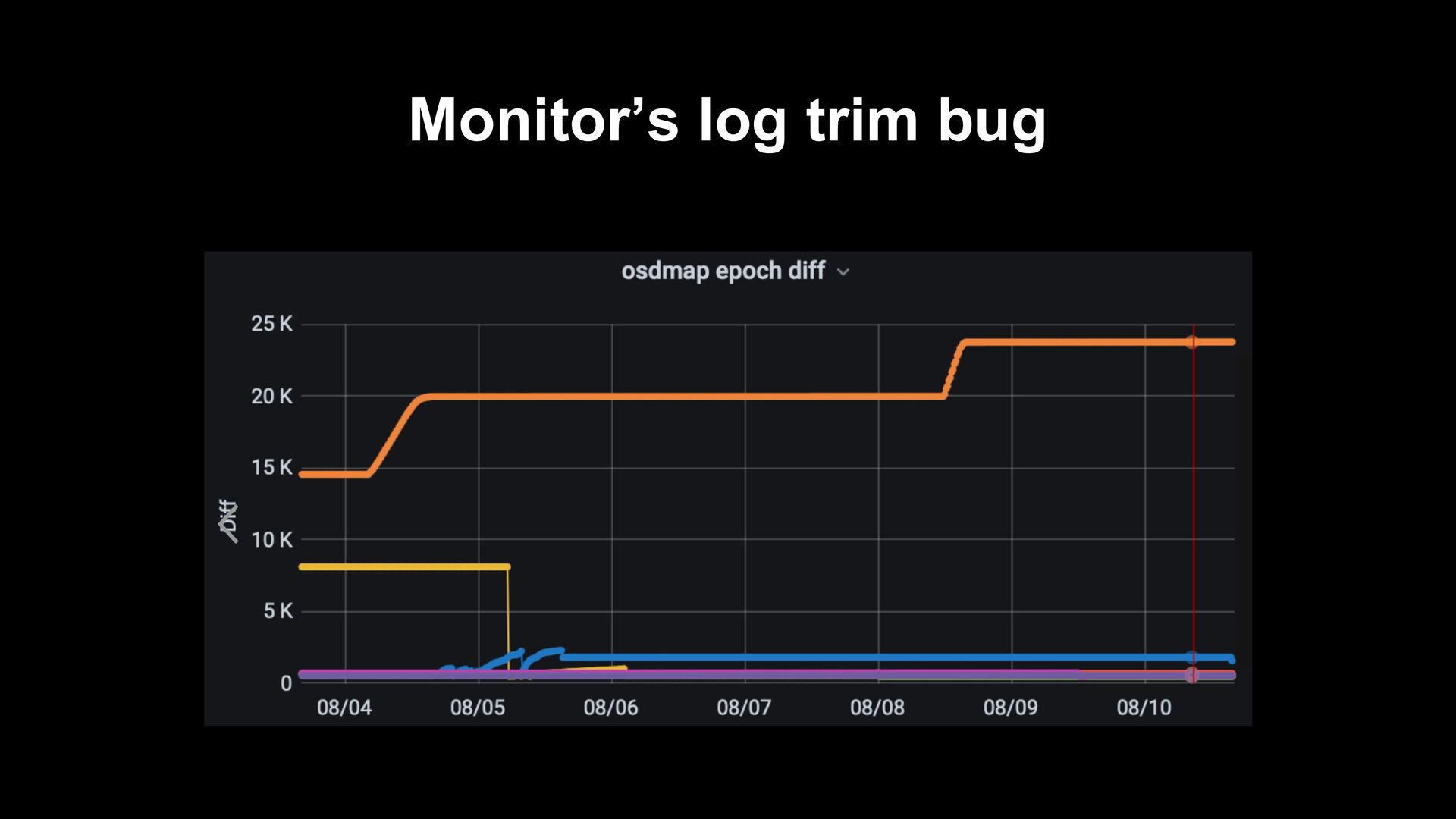
of ceph-mgr becomes severely unstable • https://ceph.io/en/news/blog/2022/scaletesting-with-pawsey/ • https://ceph.io/en/news/blog/2022/mgr-ttlcache • ceph-mgrs were killed repeatedly when adding OSDs • ceph status showed the incorrect information • Ceph monitor is not perfect! • ceph-mon was killed due to OOM due to client issues
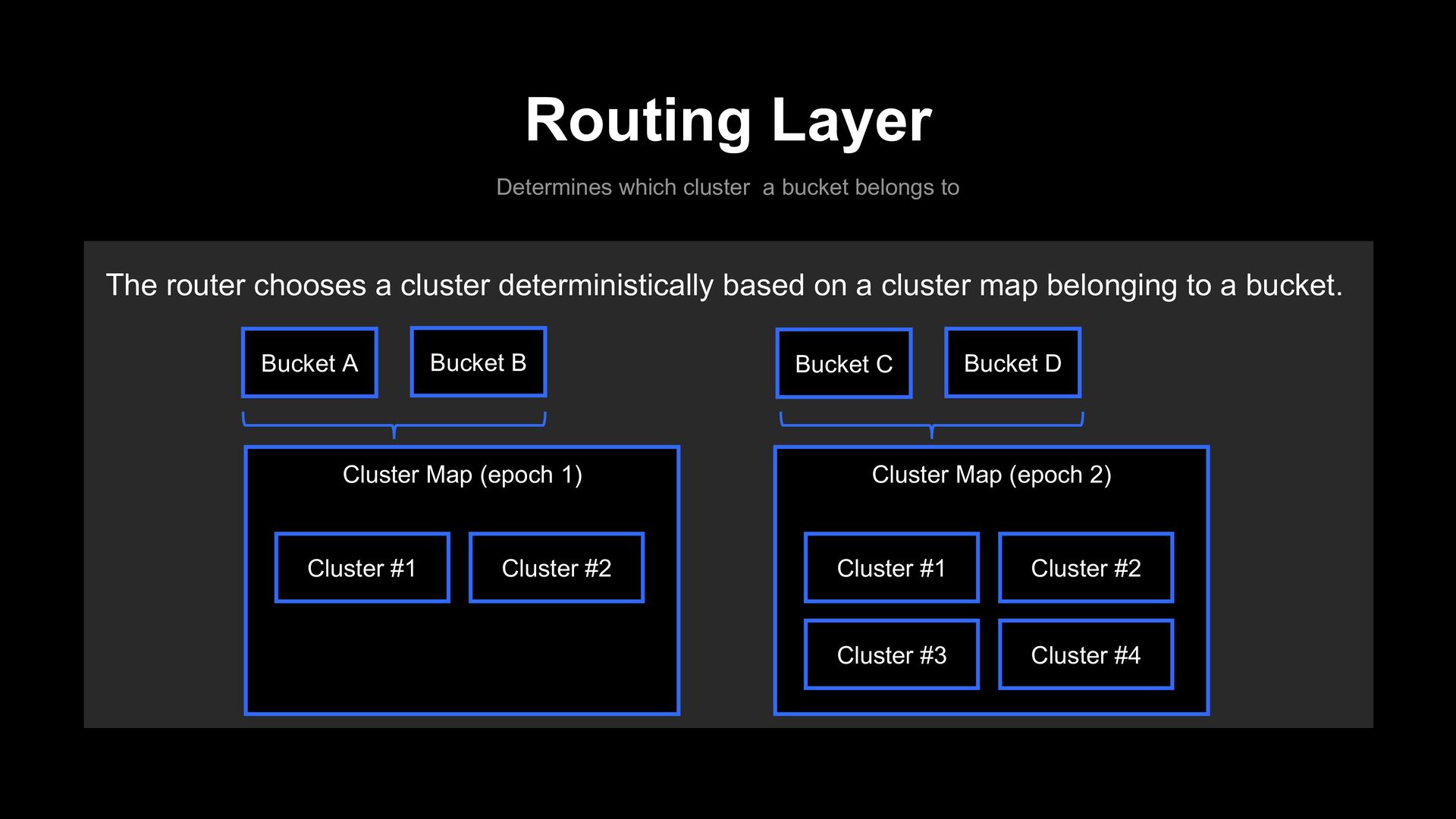
map belonging to a bucket. Routing Layer Determines which cluster a bucket belongs to Cluster Map (epoch 1) Cluster #1 Cluster #2 Cluster Map (epoch 2) Cluster #1 Cluster #2 Cluster #3 Cluster #4 Bucket A Bucket B Bucket C Bucket D
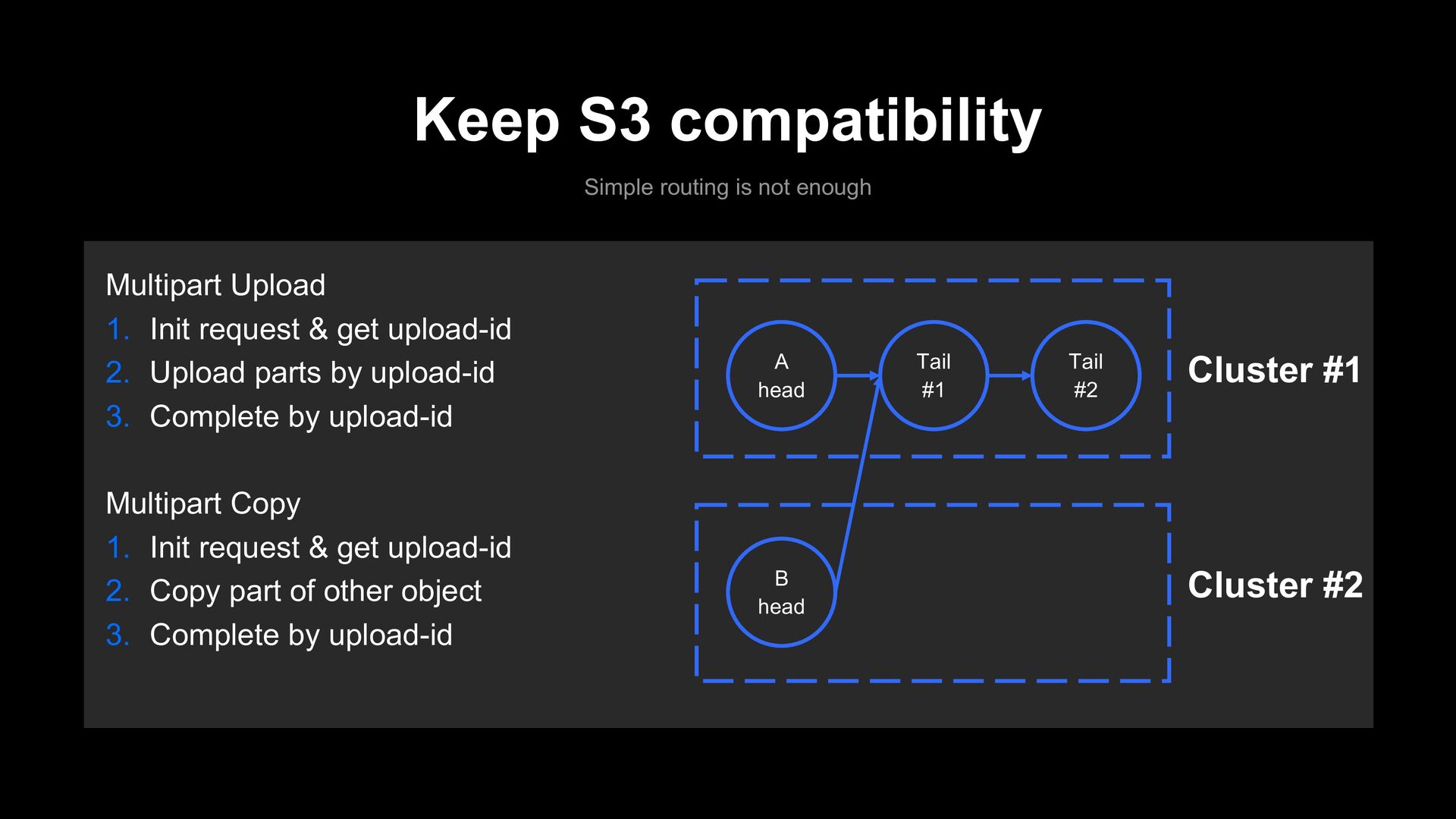
1. Init request & get upload-id 2. Upload parts by upload-id 3. Complete by upload-id Multipart Copy 1. Init request & get upload-id 2. Copy part of other object 3. Complete by upload-id A head Tail #1 Tail #2 B head
1. Init request & get upload-id 2. Upload parts by upload-id 3. Complete by upload-id Multipart Copy 1. Init request & get upload-id 2. Copy part of other object 3. Complete by upload-id A head Tail #1 Tail #2 B head Cluster #1 Cluster #2
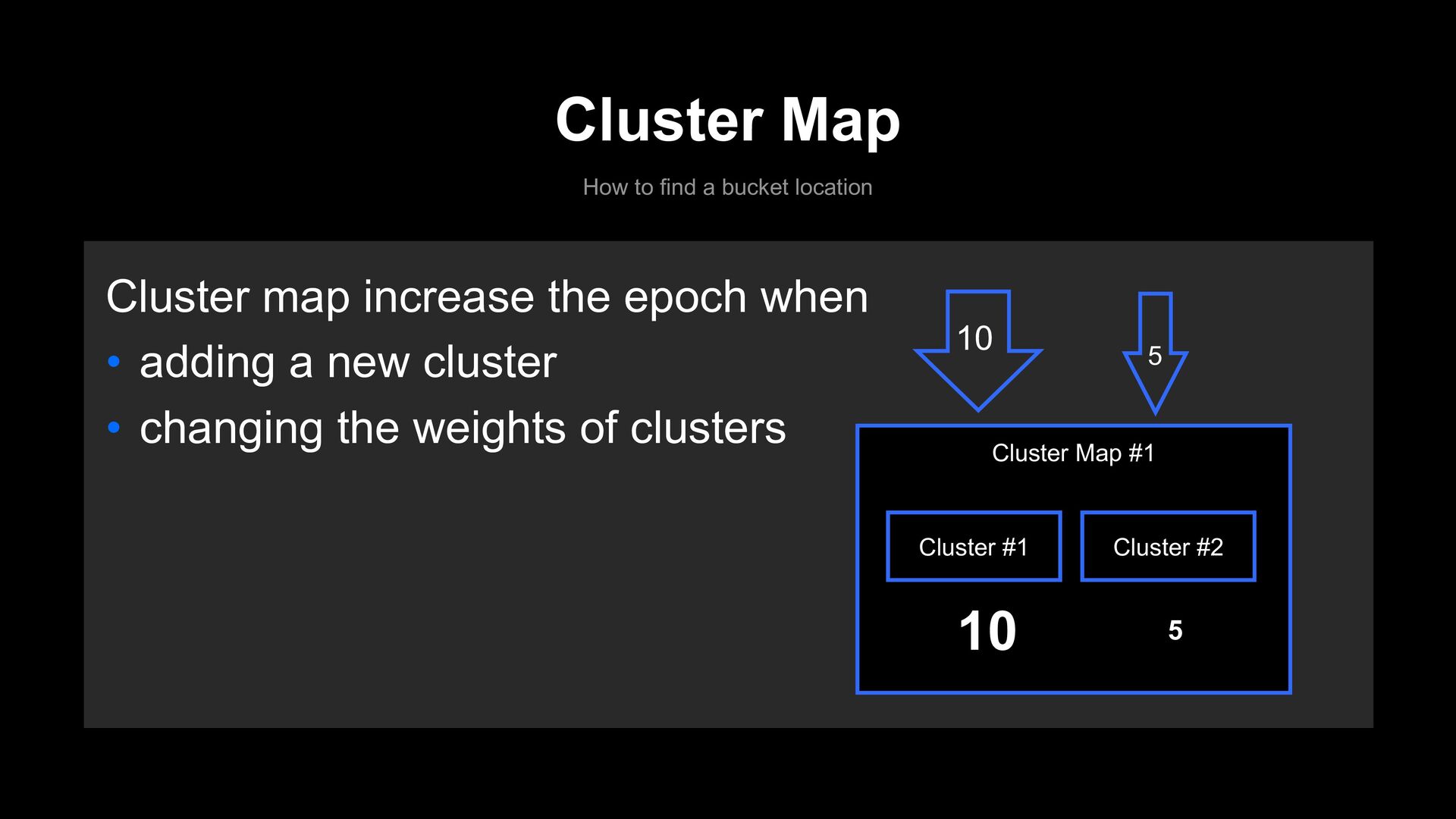
Inter-cluster reshuffling is inefficient • Inner clusters are independently scalable • We can control incoming traffic to each internal cluster • An increase in total capacity does not necessarily mean an increase in traffic.
LC.2 Bucket D Bucket E Bucket F LC.3 Bucket G Bucket H Bucket I LC.4 Bucket J Bucket K Bucket L LC Worker LC Worker LC Worker LC Worker Locked! Locked!
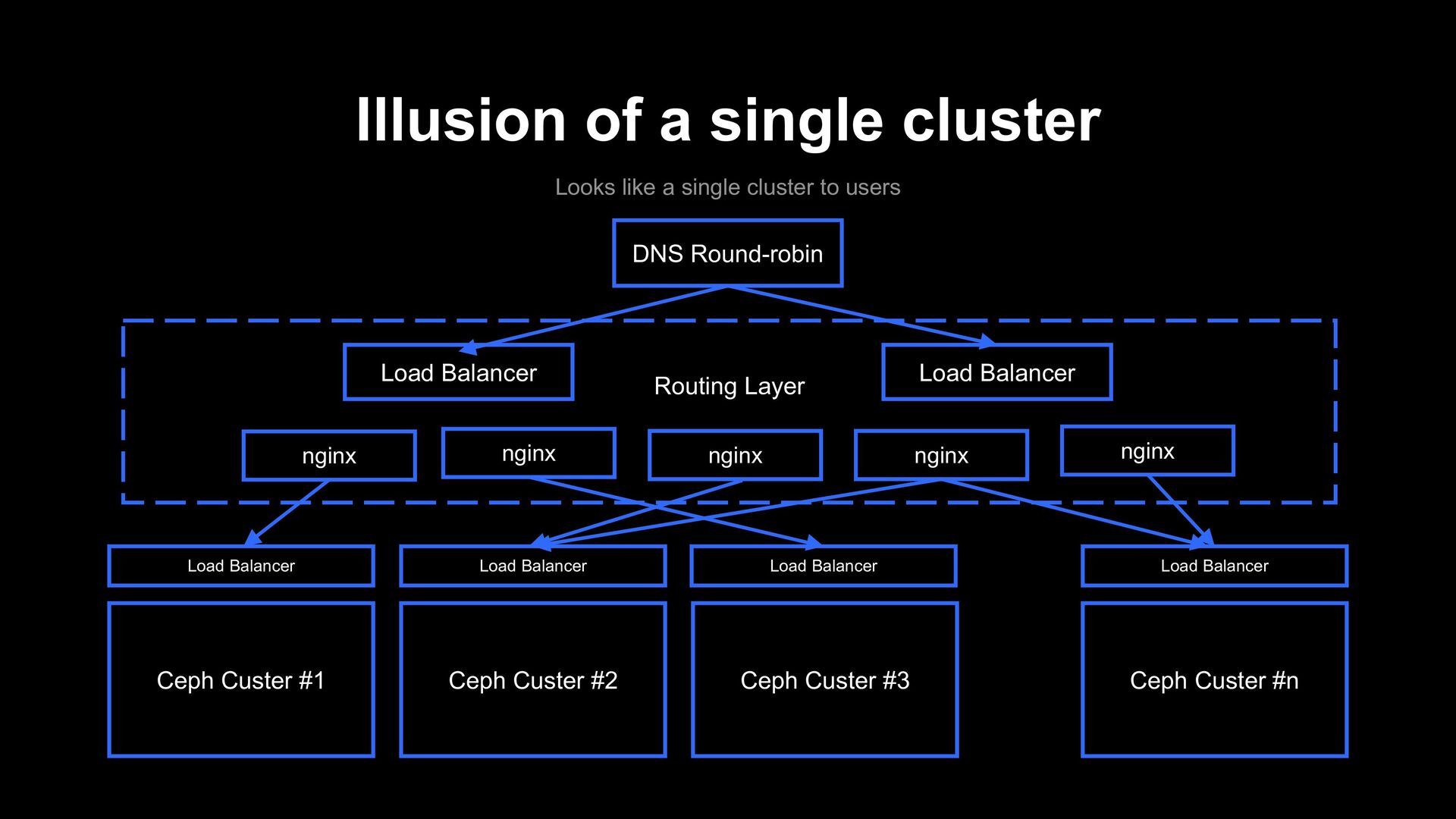
clusters to act as a single cluster • Cluster federation • S3 compatibility • High storage efficiency • We can achieve sustainable scalability Conclusions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}