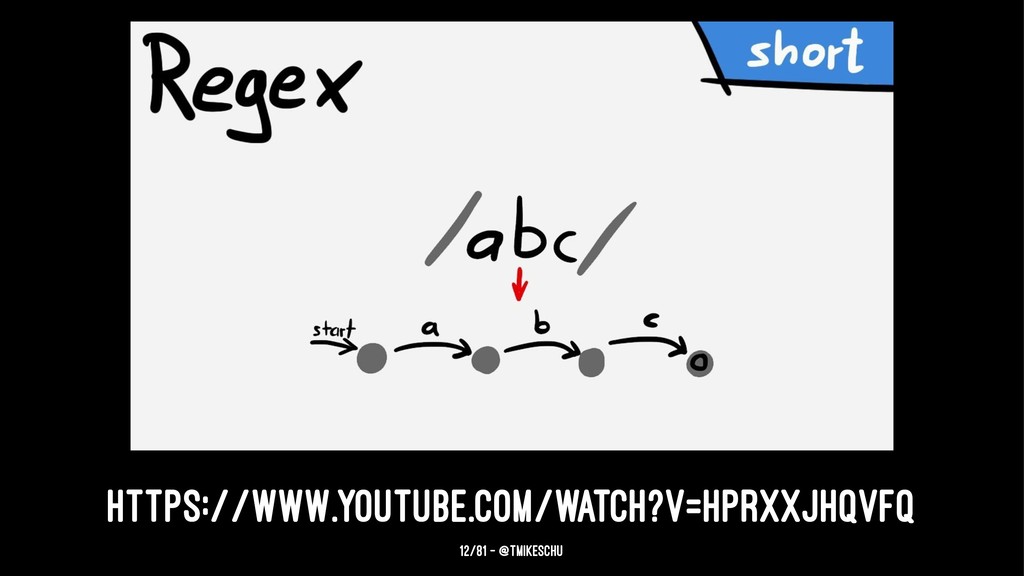
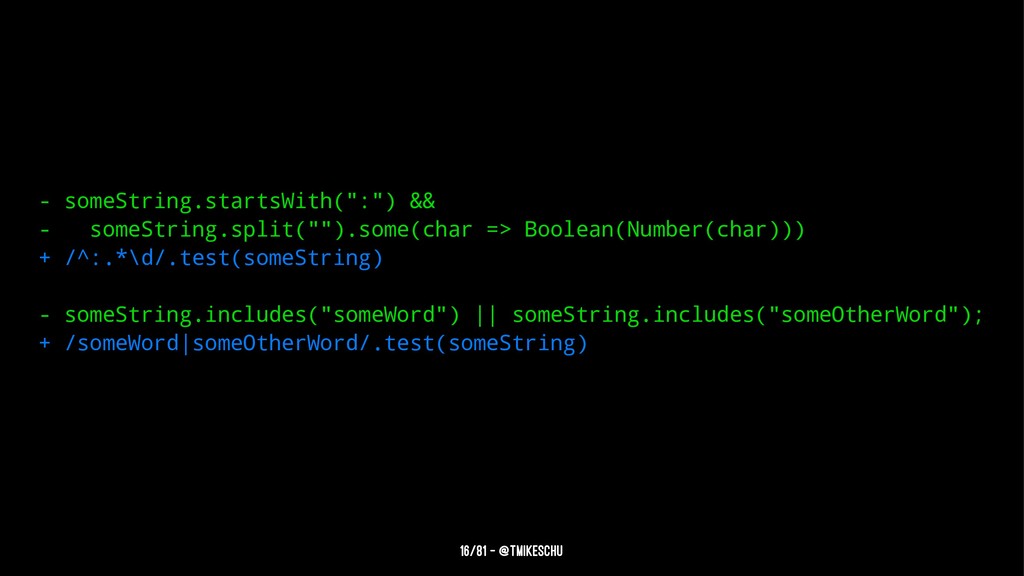
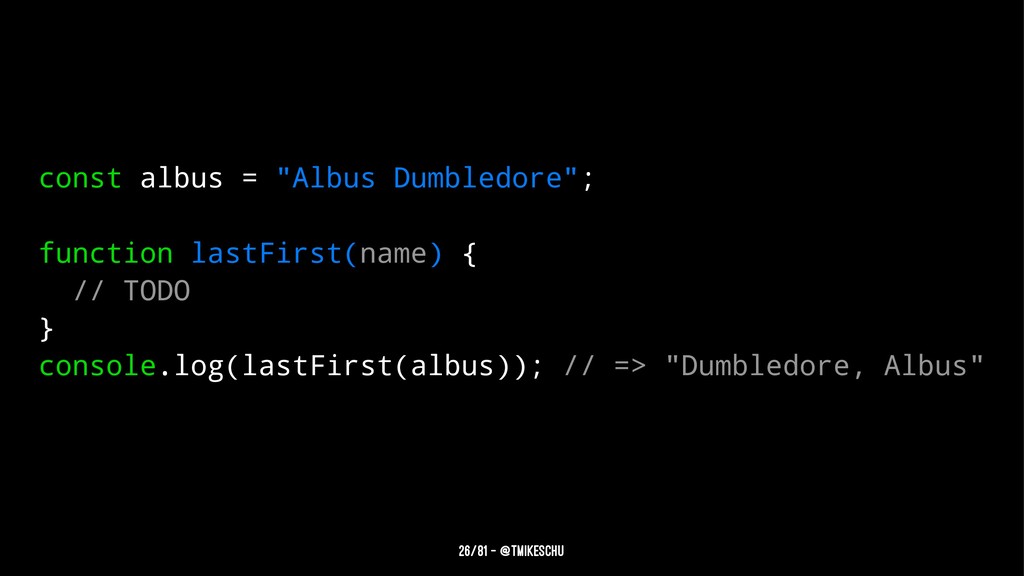
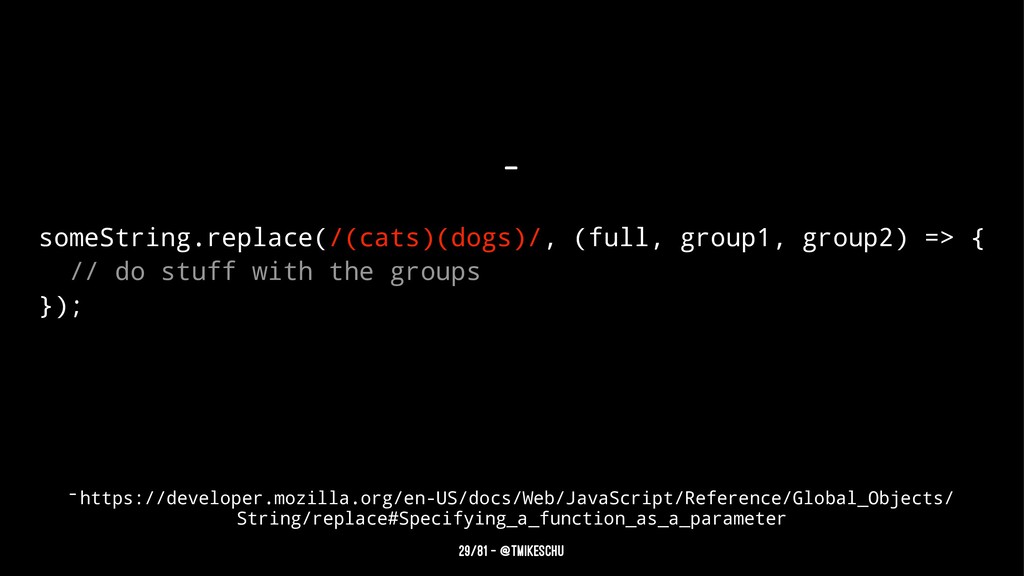
We’ve all been there. You want to to parse a string with a bit o’ regex. You have to account for things like dashes and three-digit-numbers and words-that-start-with-capital-letters. So you cobble together some sketchy stack overflow results, toss em between those infamous forward slashes, and cross your fingers. Maybe 10% of the time you get what you want, the other 90% leaves you with an empty string or nil. Either way, your heart feels fragile, and you just need a hug.
This, my friends, is regexion. Like rejection, it hurts. Don't feel bad though, it happens to everyone. We love expressive syntax, so it’s hard to not see regex as inscrutable black magic. This talk provides context for why regex is worth the effort and dives into the advanced technique of capture groups. You will walk away with the tools and mindset to face regexion with courage and optimism.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![function lastFirst(rawName) { const [name, suffix] = rawName.split(", "); const](https://files.speakerdeck.com/presentations/3615e75f01684b969058c99cc8b9f17a/slide_109.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![APPROACH 1: SPLIT function lastFirst(rawName) { const [name, suffix] =](https://files.speakerdeck.com/presentations/3615e75f01684b969058c99cc8b9f17a/slide_119.jpg){kind=link}
{kind=link}
![function lastFirst(rawName) { const [name, suffix] = rawName.split(", "); const](https://files.speakerdeck.com/presentations/3615e75f01684b969058c99cc8b9f17a/slide_121.jpg){kind=link}
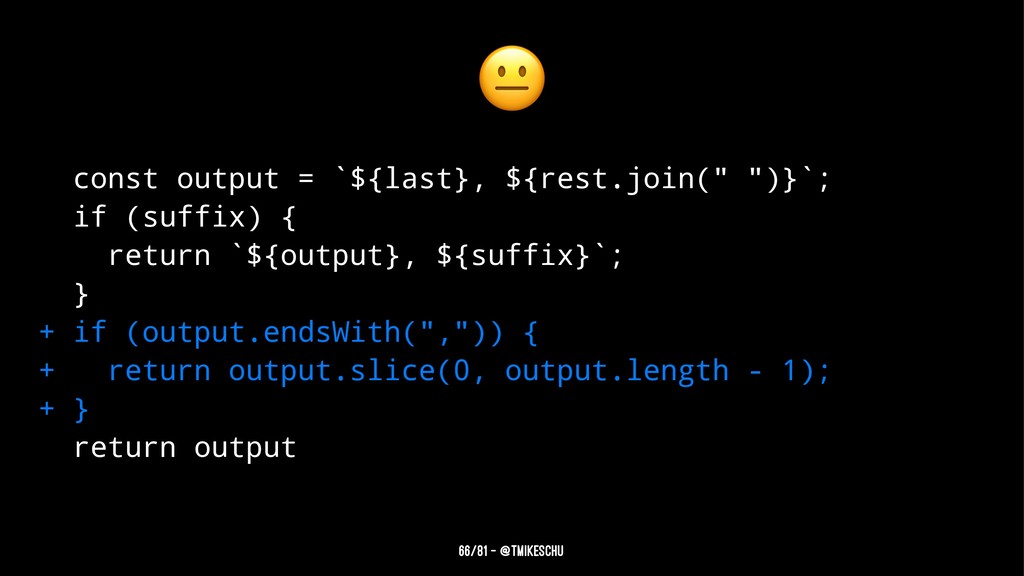{kind=link}
![function lastFirst(rawName) { const [name, suffix] = rawName.split(", "); const](https://files.speakerdeck.com/presentations/3615e75f01684b969058c99cc8b9f17a/slide_123.jpg){kind=link}
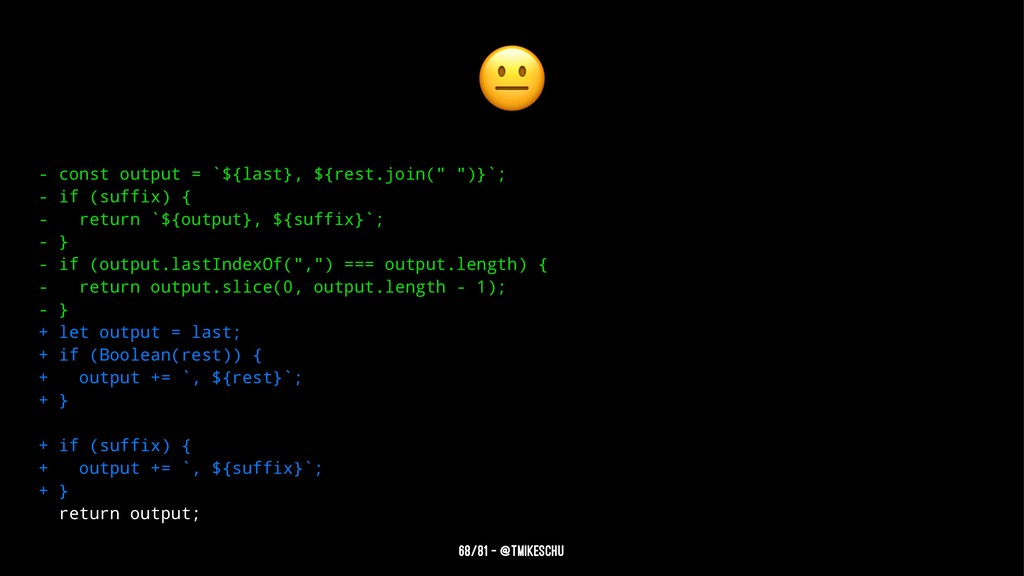{kind=link}
{kind=link}
{kind=link}
{kind=link}
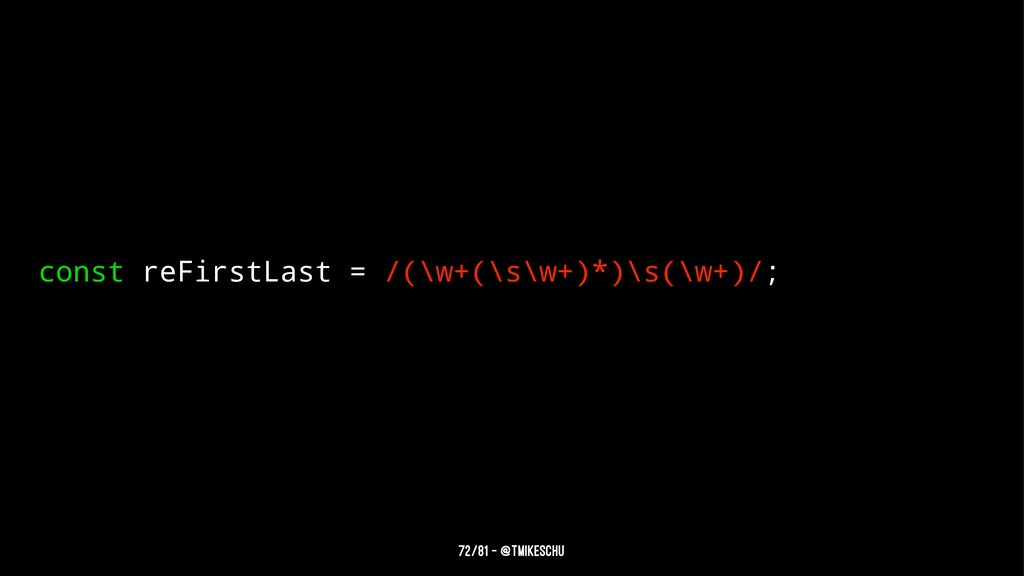{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}