Présentation effectuée le 25 Novembre 2015 au Toulouse Data Science, soirée co-organisée par Duchess France, par Aurélie Vache.
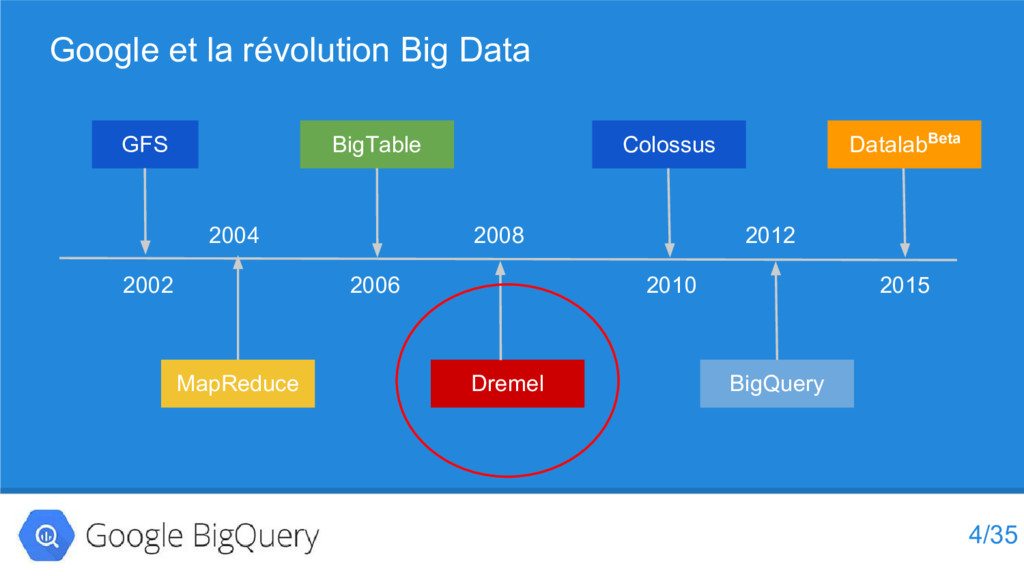
Les ingénieurs de Google avaient du mal à suivre le rythme de croissance de leurs données. Le nombre d’utilisateurs de Gmail augmentait constamment et était de l’ordre de centaines de millions; Il y avait plus de 100 milliards de recherches Google effectuées chaque mois.
Essayer de donner un sens à toutes ces données prenait un temps fou et était une expérience très frustrante pour les équipes de Google.
Ce problème de données a conduit l’élaboration en 2008 d’un outil interne appelé Dremel, qui a permis aux employés de Google d’exécuter des requêtes SQL extrêmement rapides sur un grand ensemble de données.
En 2012 lors de la Google I/O, Google à annoncé la sortie de Google BigQuery, l'implémentation externe de Dremel...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
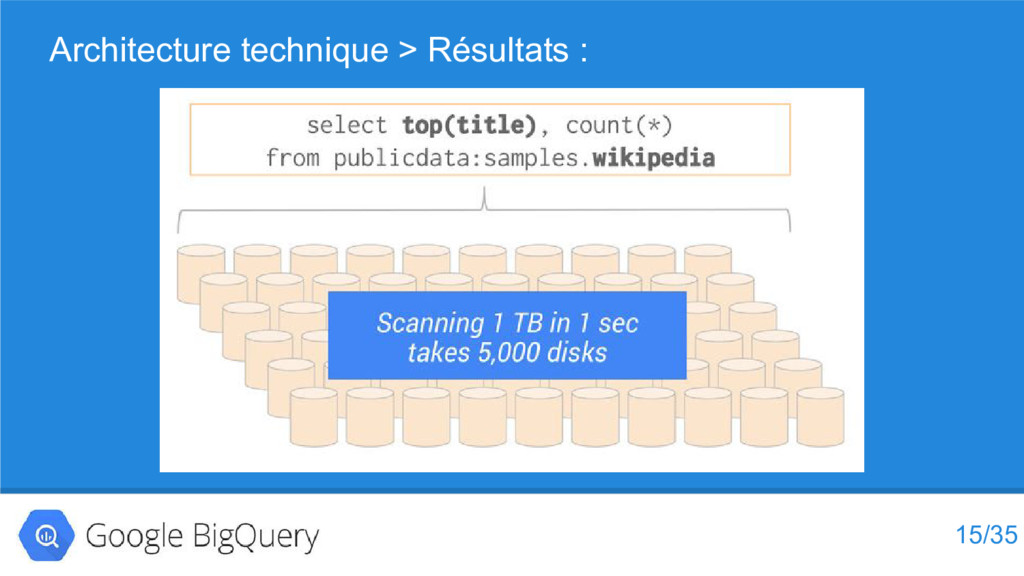{kind=link}
{kind=link}
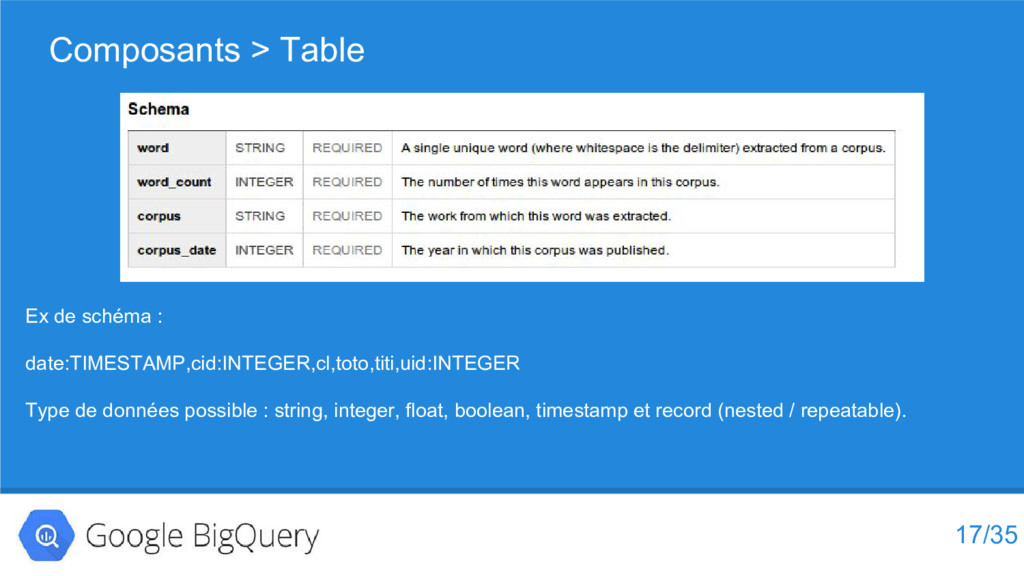{kind=link}
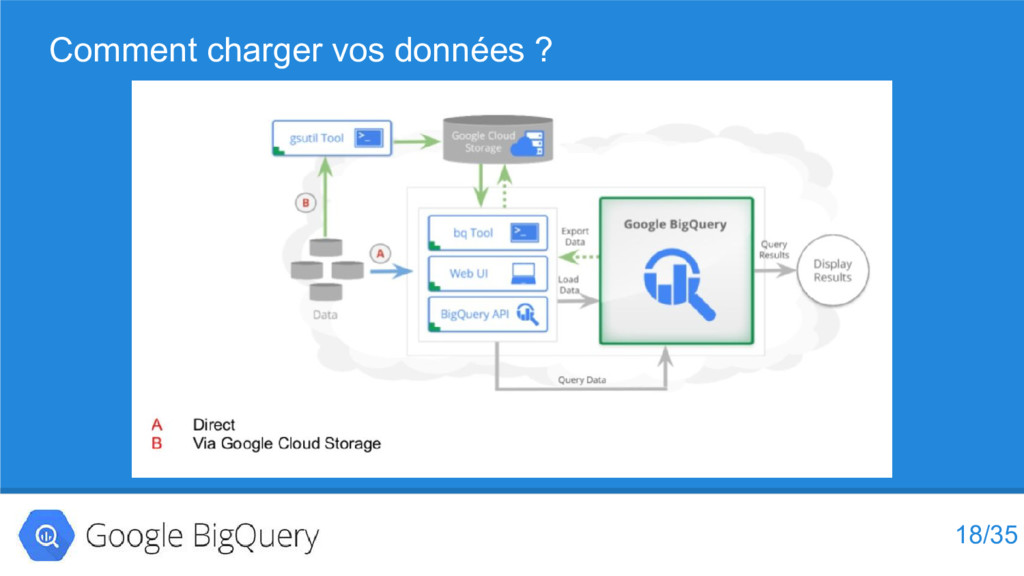{kind=link}
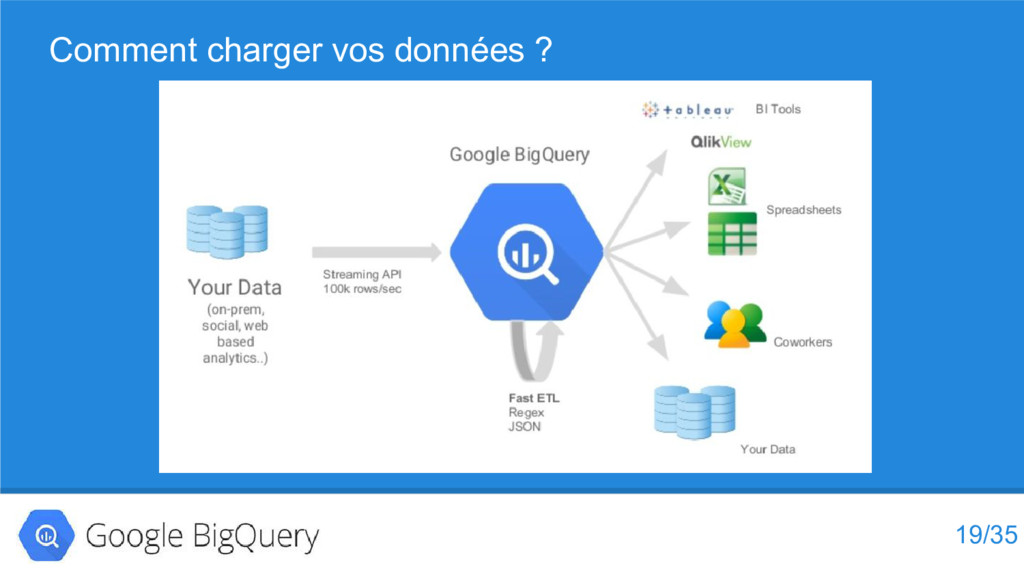{kind=link}
{kind=link}
{kind=link}
{kind=link}
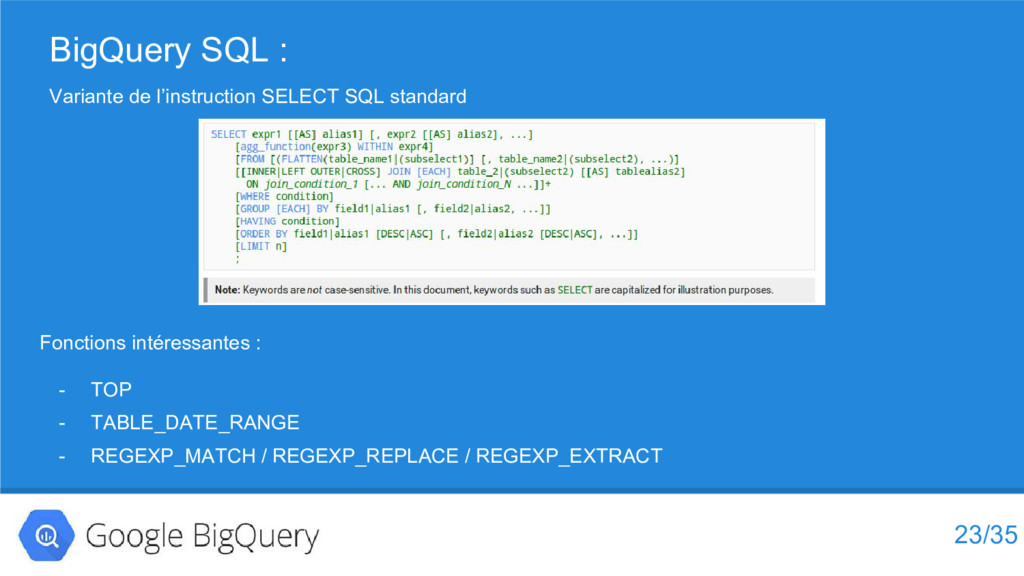{kind=link}
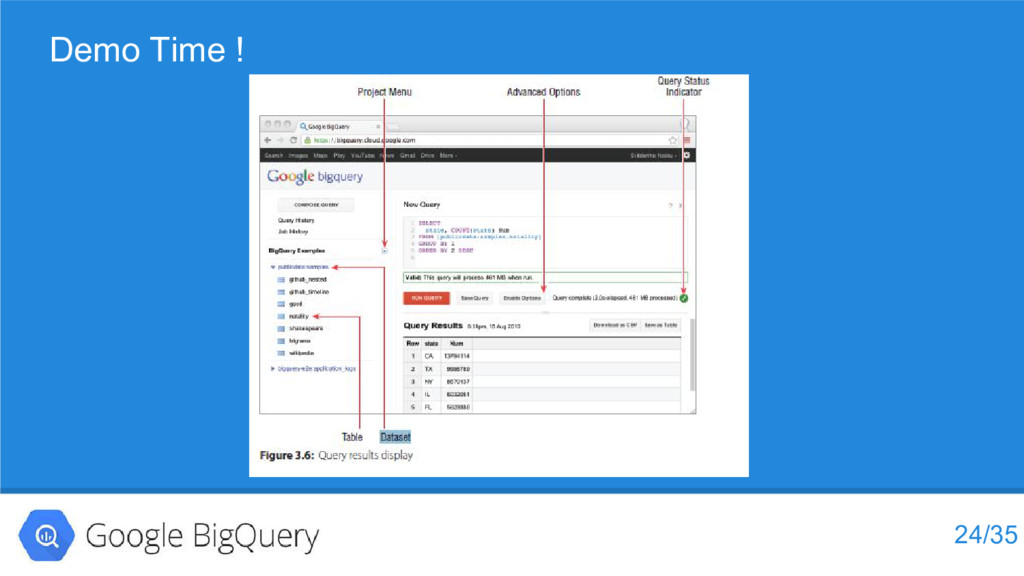{kind=link}
{kind=link}
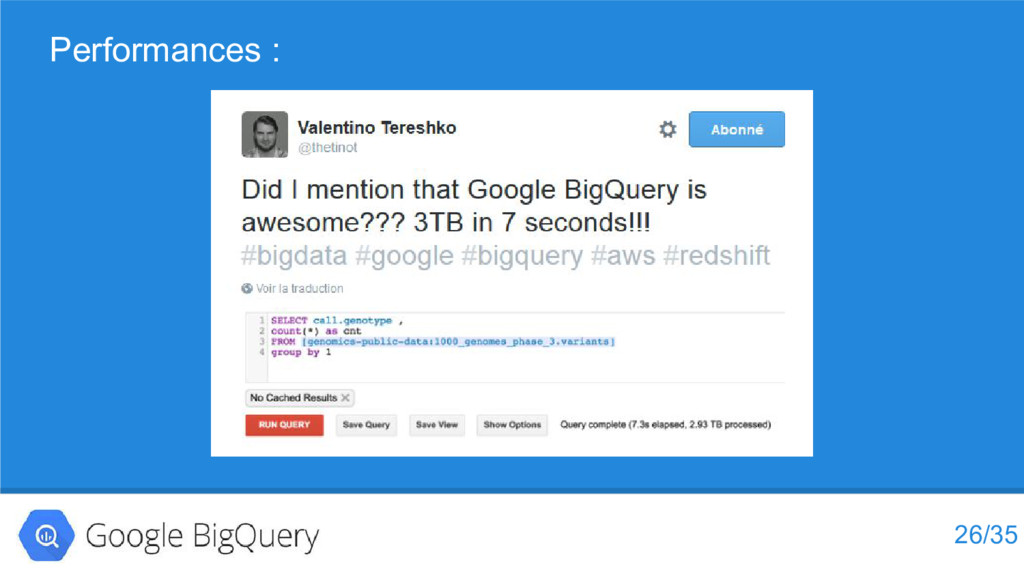{kind=link}
{kind=link}
{kind=link}
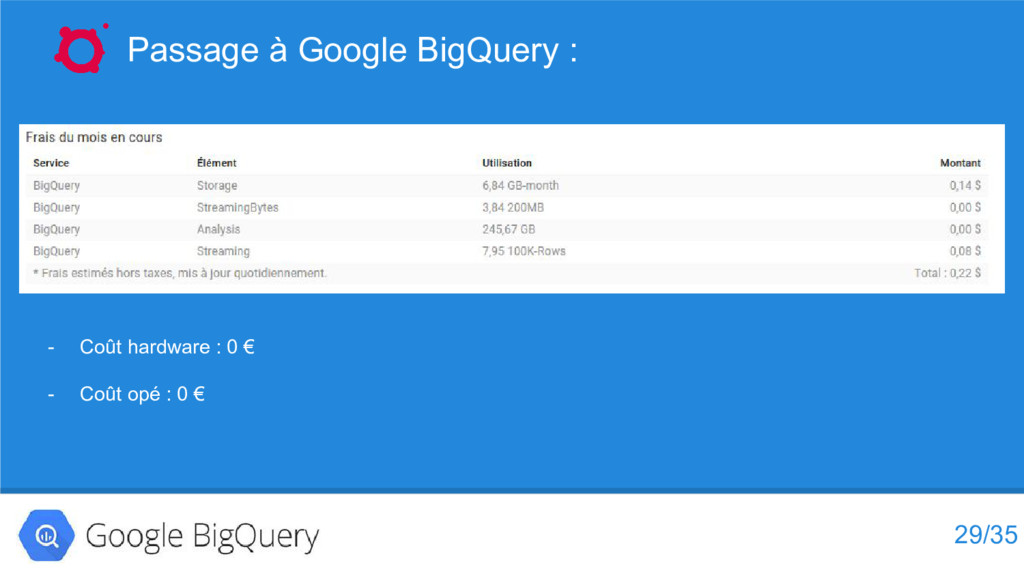{kind=link}
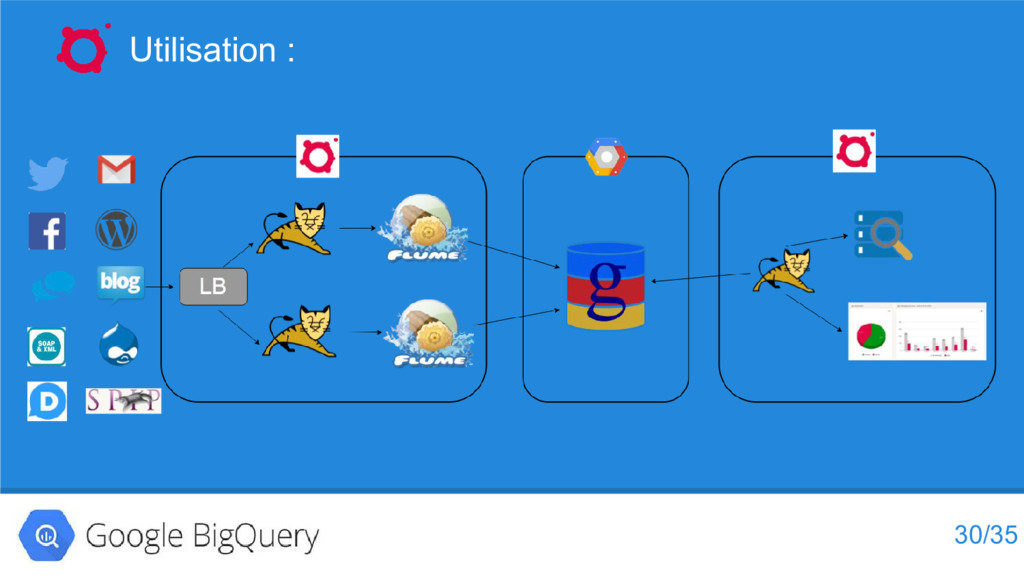{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}