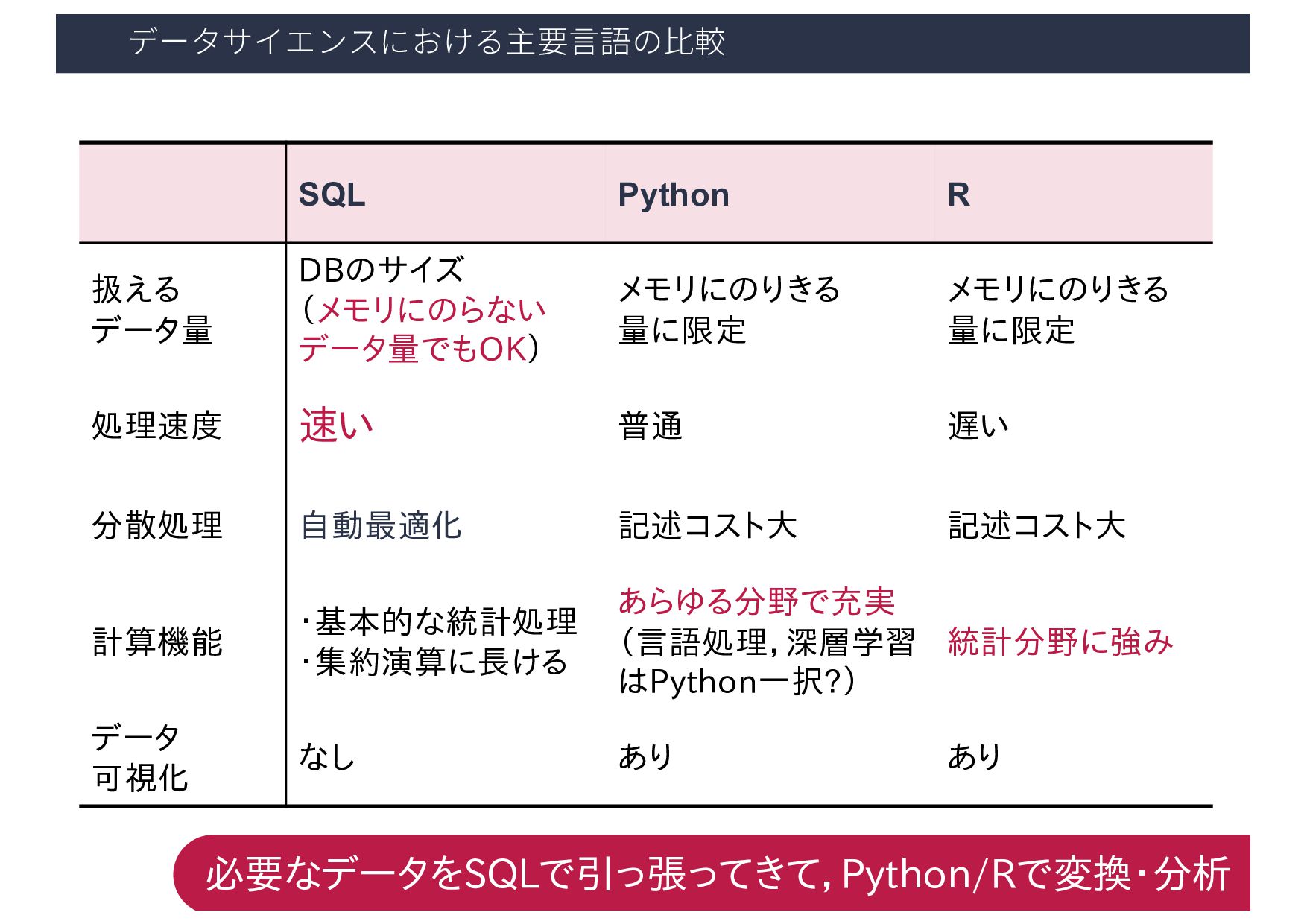
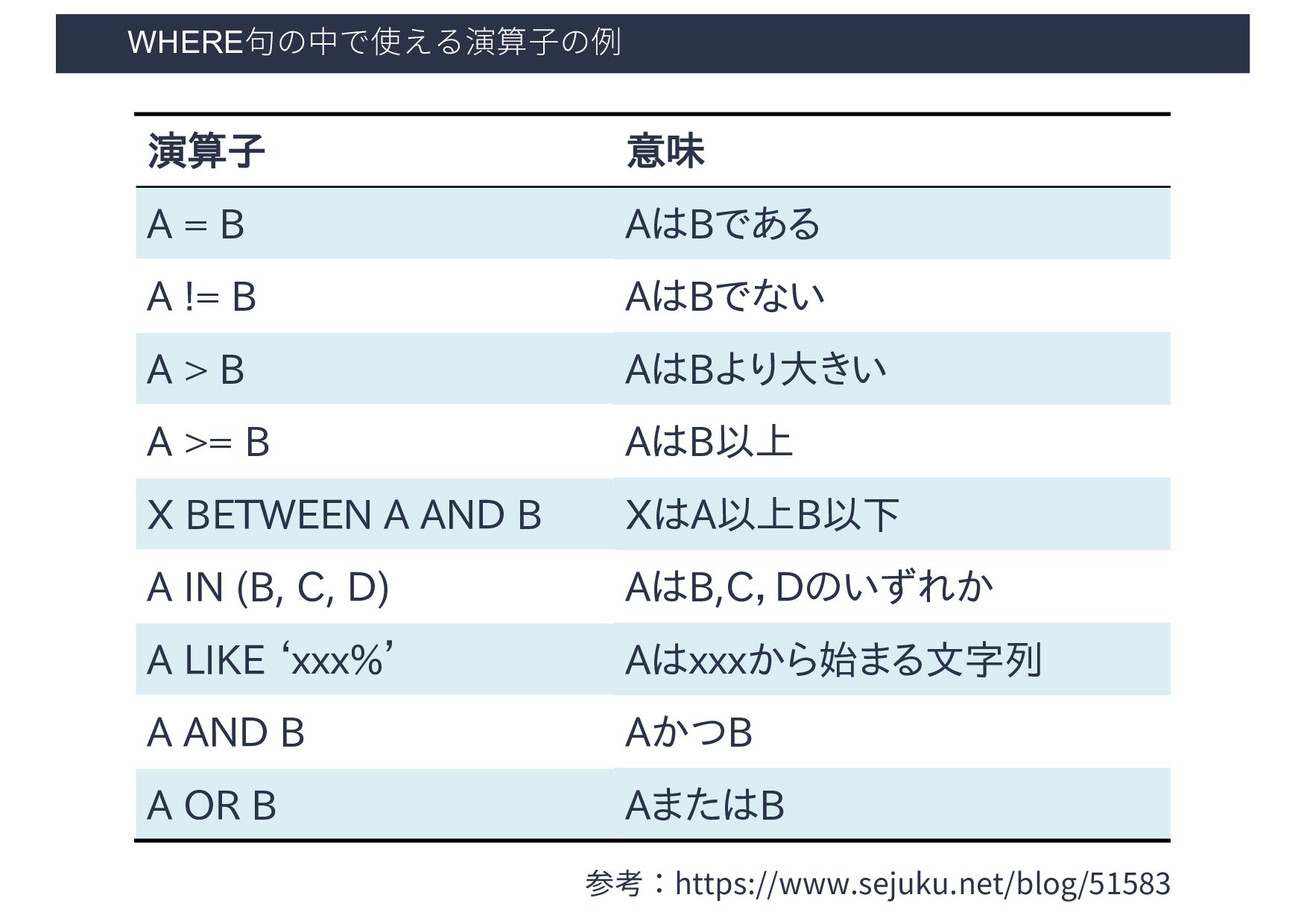
AはBでない A > B AはBより大きい A >= B AはB以上 X BETWEEN A AND B XはA以上B以下 A IN (B, C, D) AはB,C,Dのいずれか A LIKE ‘xxx%’ Aはxxxから始まる文字列 A AND B AかつB A OR B AまたはB 参考:https://www.sejuku.net/blog/51583
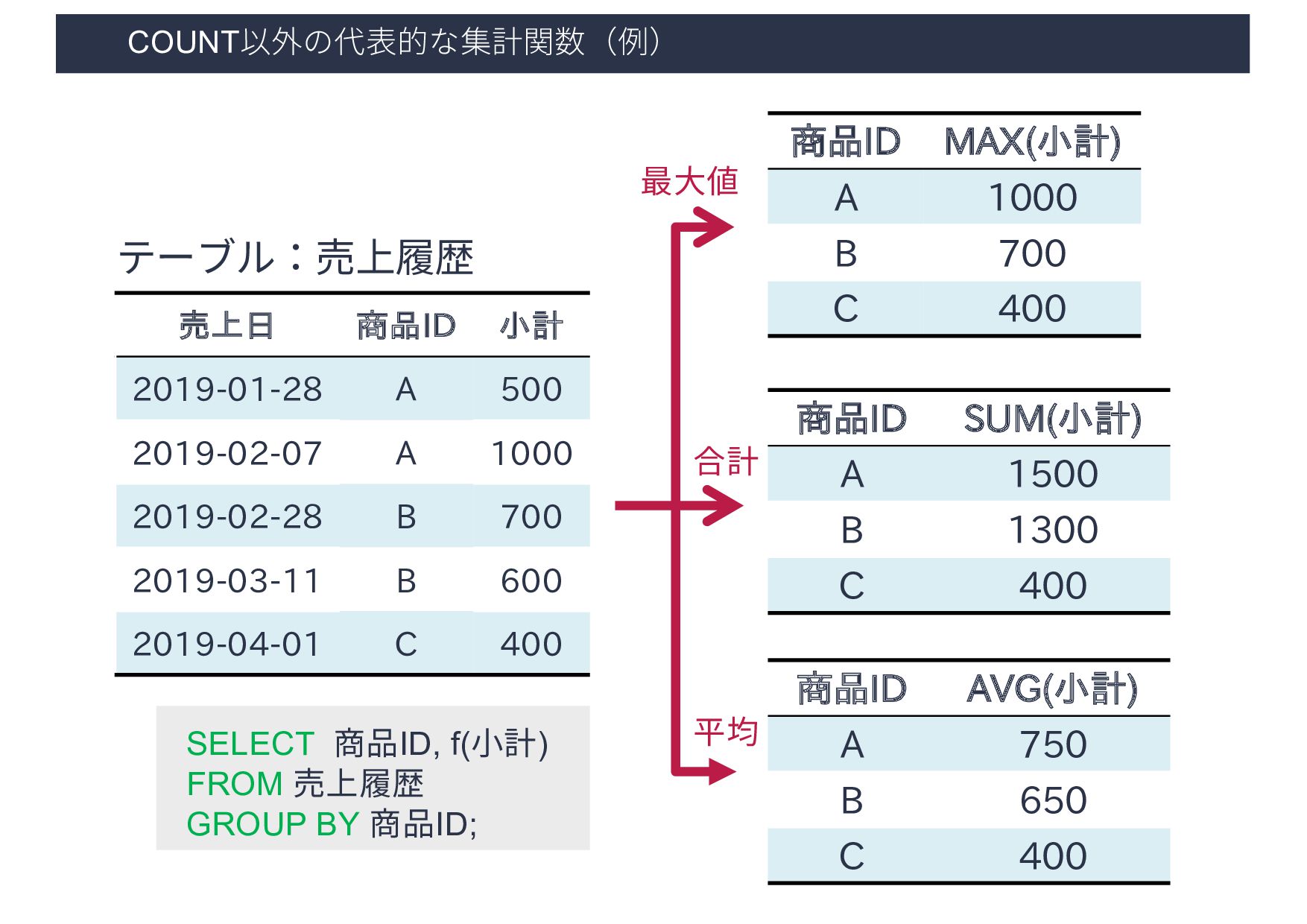
2019-02-28 B 700 2019-03-11 B 600 2019-04-01 C 400 テーブル:売上履歴 商品ID MAX(小計) A 1000 B 700 C 400 商品ID SUM(小計) A 1500 B 1300 C 400 商品ID AVG(小計) A 750 B 650 C 400 最⼤値 合計 平均 SELECT 商品ID, f(⼩計) FROM 売上履歴 GROUP BY 商品ID;
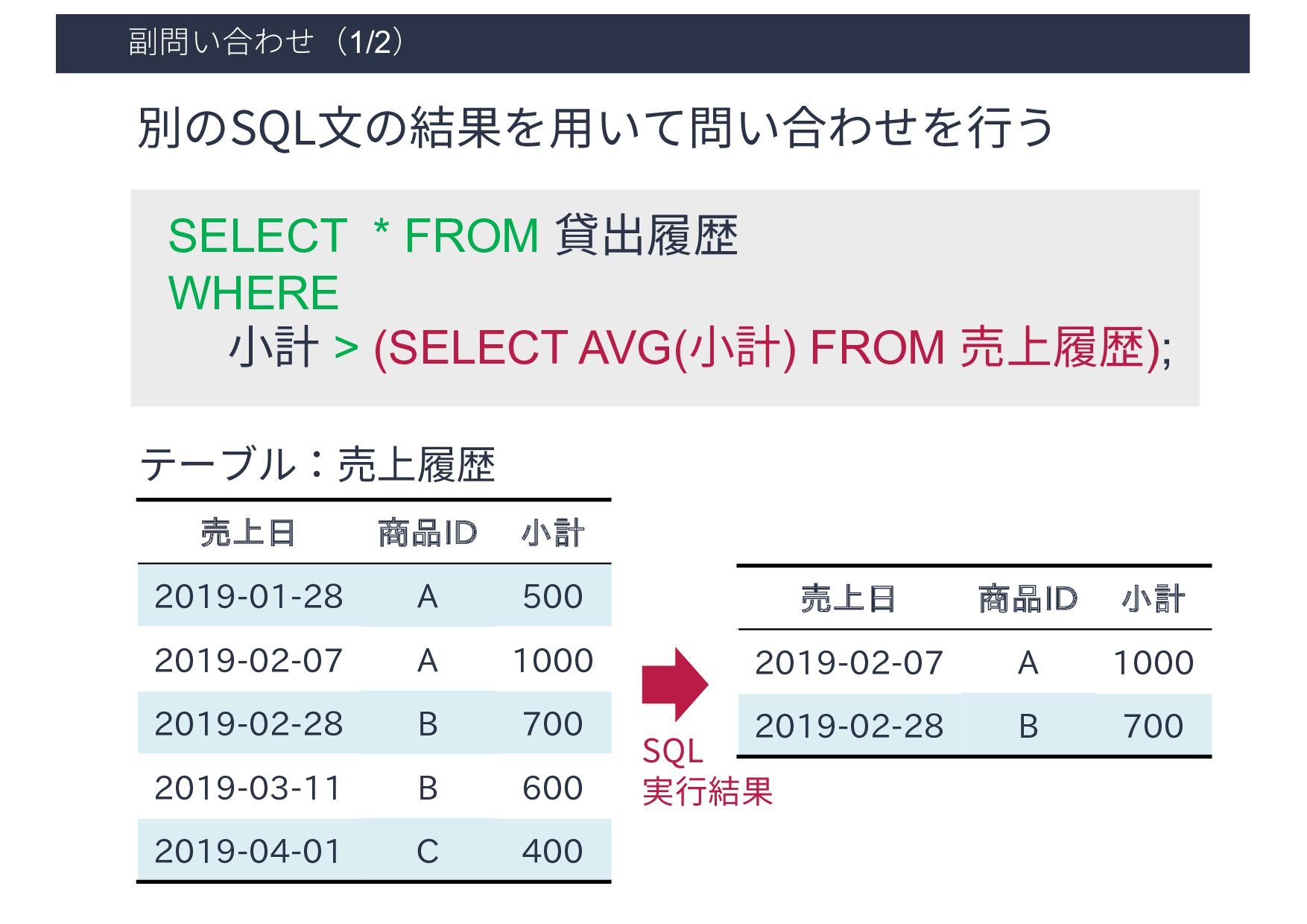
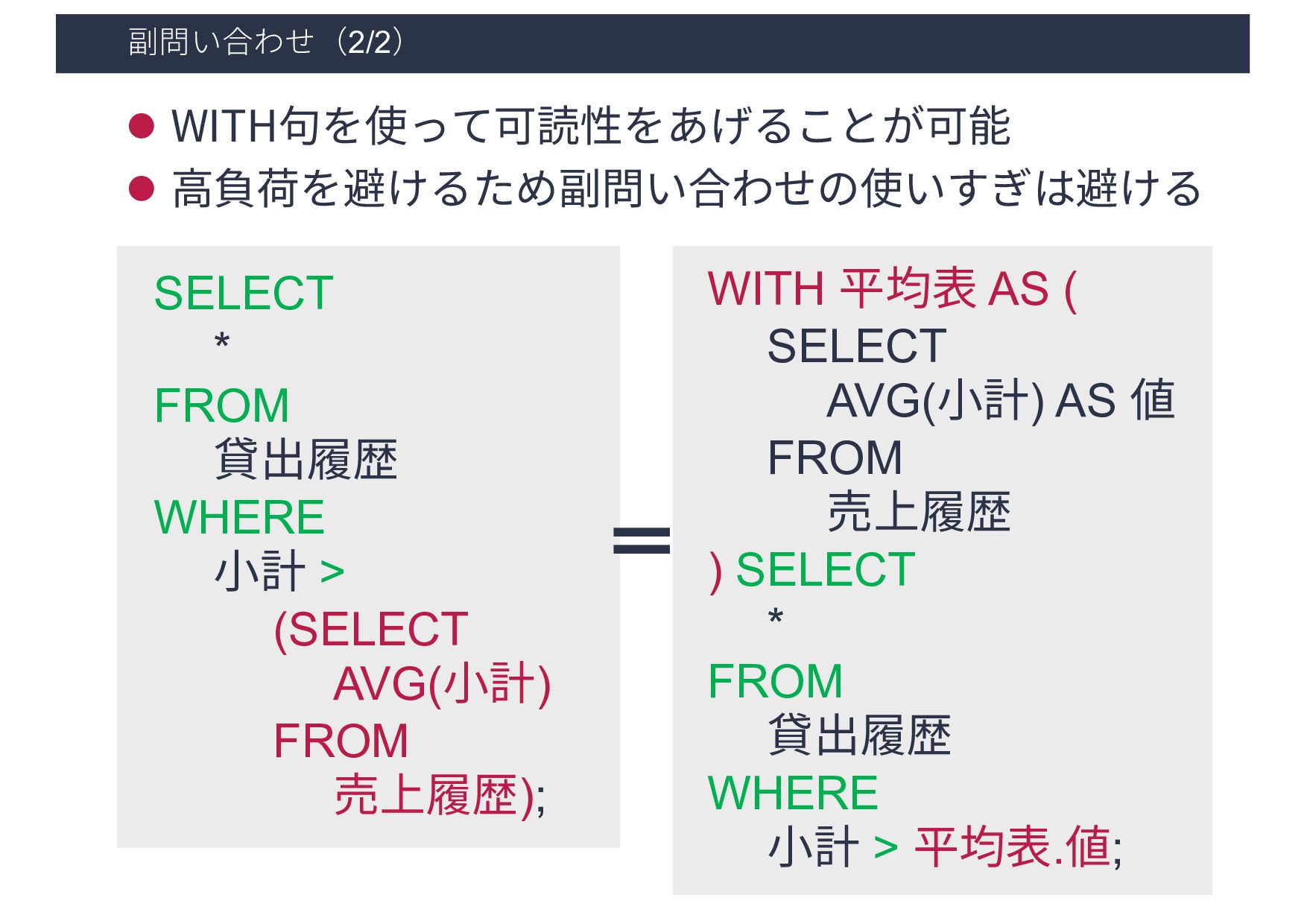
2019-02-28 B 700 2019-03-11 B 600 2019-04-01 C 400 テーブル:売上履歴 SELECT * FROM 貸出履歴 WHERE ⼩計 > (SELECT AVG(⼩計) FROM 売上履歴); 別のSQL⽂の結果を⽤いて問い合わせを⾏う 売上日 商品ID 小計 2019-02-07 A 1000 2019-02-28 B 700 SQL 実⾏結果
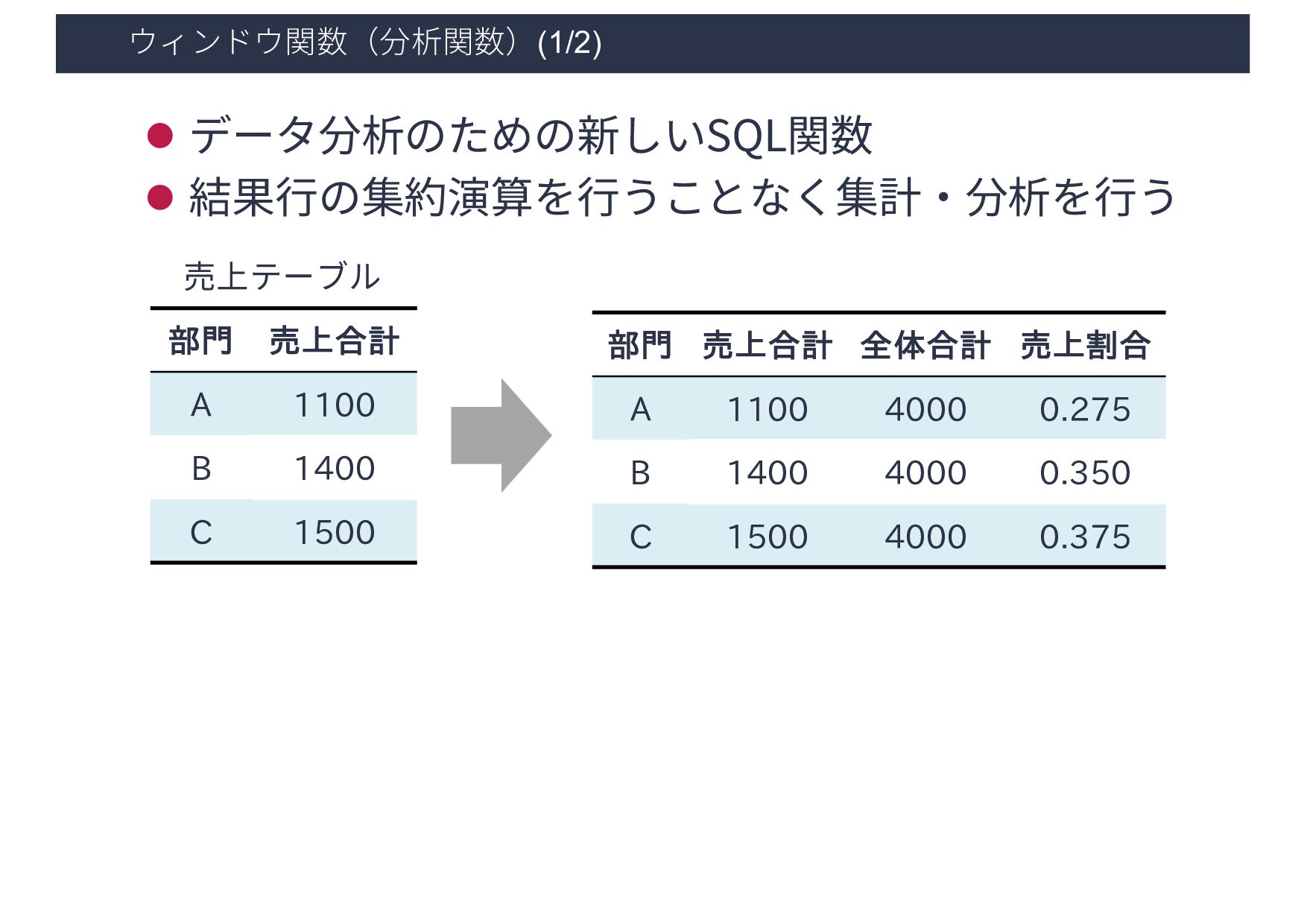
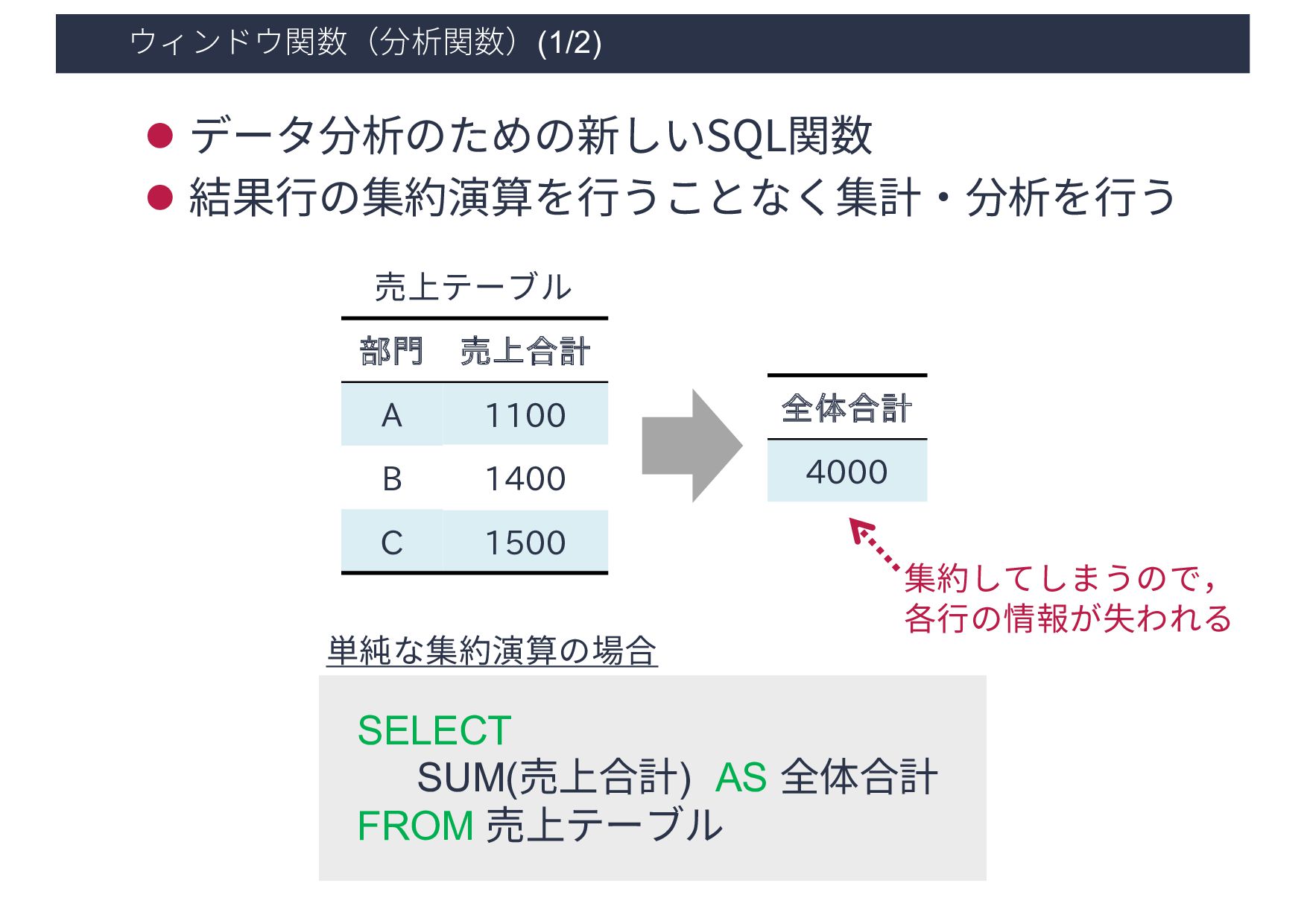
1400 C 1500 部門 売上合計 全体合計 売上割合 A 1100 4000 0.275 B 1400 4000 0.350 C 1500 4000 0.375 SELECT *, SUM(売上合計) OVER() AS 全体合計, 売上合計 / SUM(売上合計) OVER() AS 売上割合 FROM 売上テーブル 売上テーブル ウィンドウ関数を⽤いた場合
![⼭本 祐輔 静岡⼤学 情報学部 [email protected] 2022年度前期 データアナリティクスII – 山本担当モジュール2 2022年4月18日](https://files.speakerdeck.com/presentations/bd5cf3cb631c4aff80ecb4813679f50a/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}