Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
機械学習 - 決定木からはじめる機械学習
Search
Y. Yamamoto
PRO
April 20, 2026
Science
1.5k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
機械学習 - 決定木からはじめる機械学習
1. 決定木
Y. Yamamoto
PRO
April 20, 2026
More Decks by Y. Yamamoto
See All by Y. Yamamoto
データベース12: 正規化(2/2) - データ従属性に基づく正規化
trycycle
PRO
0
1.2k
データベース11: 正規化(1/2) - 望ましくない関係スキーマ
trycycle
PRO
0
1.2k
データベース10: 拡張実体関連モデル
trycycle
PRO
0
1.2k
データベース09: 実体関連モデル上の一貫性制約
trycycle
PRO
0
1.4k
機械学習 - ニューラルネットワーク入門
trycycle
PRO
0
1.1k
データベース08: 実体関連モデルとは?
trycycle
PRO
0
1.2k
機械学習 - SVM
trycycle
PRO
2
1.2k
機械学習 - K近傍法 & 機械学習のお作法
trycycle
PRO
1
1.6k
データベース06: SQL (3/3) 副問い合わせ
trycycle
PRO
1
1k
Other Decks in Science
See All in Science
AkarengaLT vol.40
hashimoto_kei
0
110
ダメな自分の育て方―性格タイプの「劣等機能」から理解するニガテ克服術
ppillc
0
200
Inside the Mind of an LLM
baggiponte
0
200
20251212_LT忘年会_データサイエンス枠_新川.pdf
shinpsan
0
300
生成AIと司法書士の未来.pdf
tagtag
PRO
0
130
Kaggle: NeurIPS - Open Polymer Prediction 2025 コンペ 反省会
calpis10000
0
620
Kritische evaluatie van GenAI-output voor literatuuronderzoek
voginip
0
190
JSAI2026企画セッションKS-14 インタビュー集『⼈⼯知能と哲学と四つの問い』が提起する⼈⼯知能のこれからの課題 趣旨説明 / JSAI2026 Special Session: A Collection of Interviews, “Artificial Intelligence, Philosophy, and Four Questions”
ykiyota
0
370
不動産業界における業界特化のデータ整備とAI活用 ─Vertical DataとVertical AI─
estie
1
770
水耕栽培を始める前に知っておきたい植物の科学
grow_design_lab
0
260
AIを用いた PID制御で部屋 の温度制御をしてみた
nearme_tech
PRO
0
170
先端因果推論特別研究チームの研究構想と 人間とAIが協働する自律因果探索の展望
sshimizu2006
3
950
Featured
See All Featured
Optimising Largest Contentful Paint
csswizardry
37
3.8k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.5k
How to build a perfect <img>
jonoalderson
1
5.8k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
260
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
KATA
mclloyd
PRO
35
15k
Faster Mobile Websites
deanohume
310
32k
Chasing Engaging Ingredients in Design
codingconduct
0
230
Transcript
決定木からはじめる機械学習 ⼭本 祐輔 名古屋市⽴⼤学 データサイエンス研究科
[email protected]
第3回 機械学習発展 (導入編)
授業資料 2 https://mlnote.hontolab.org/
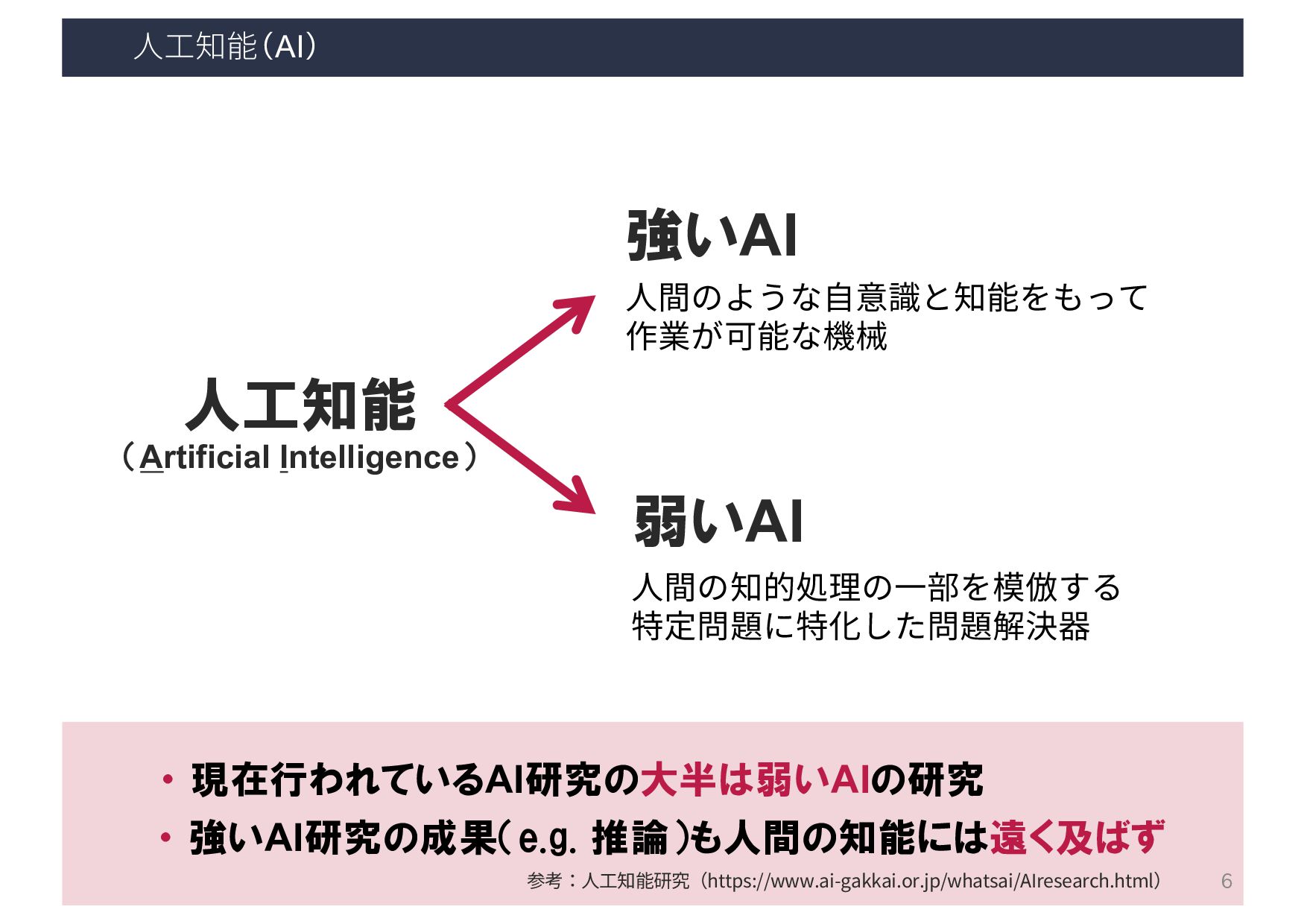
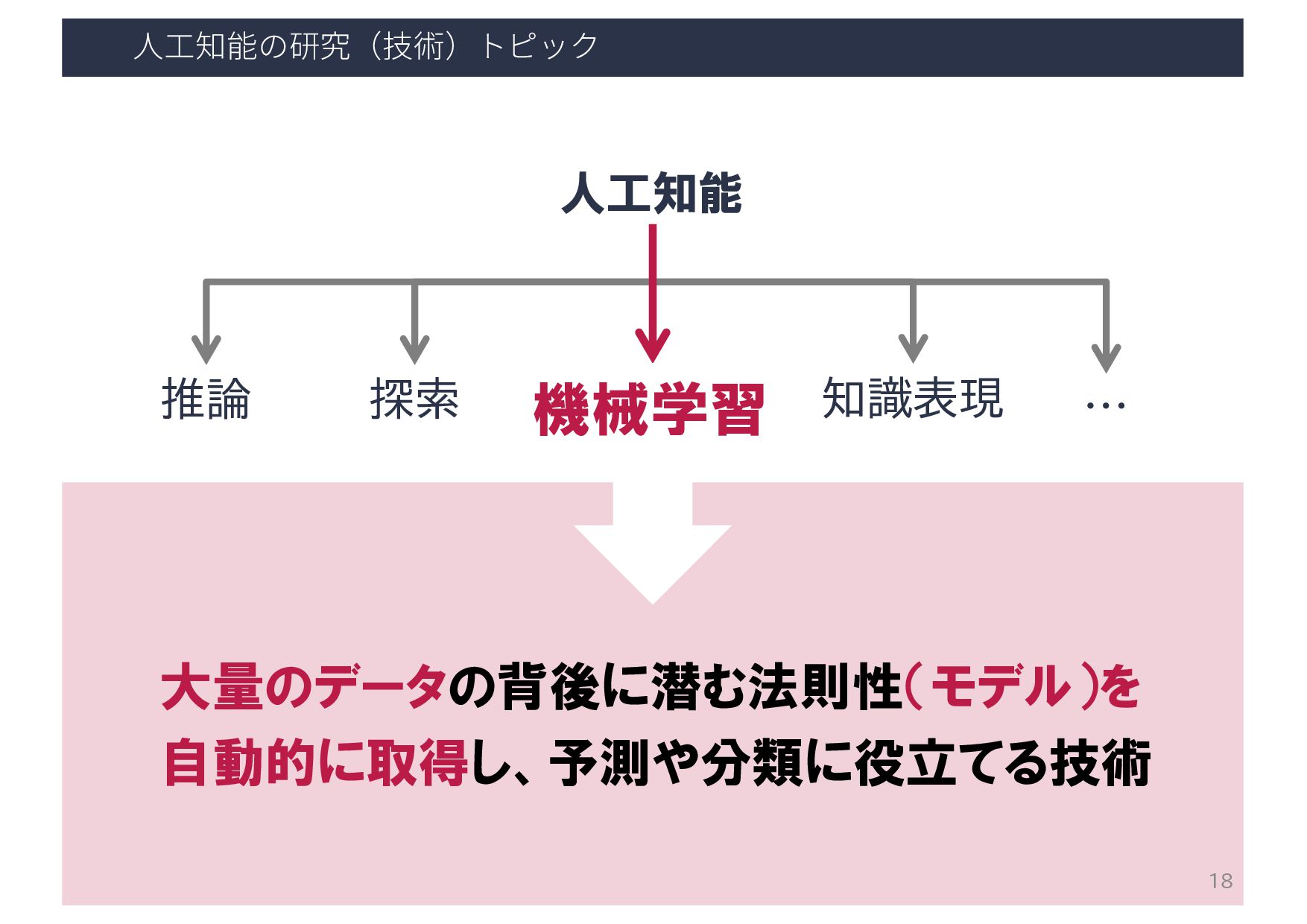
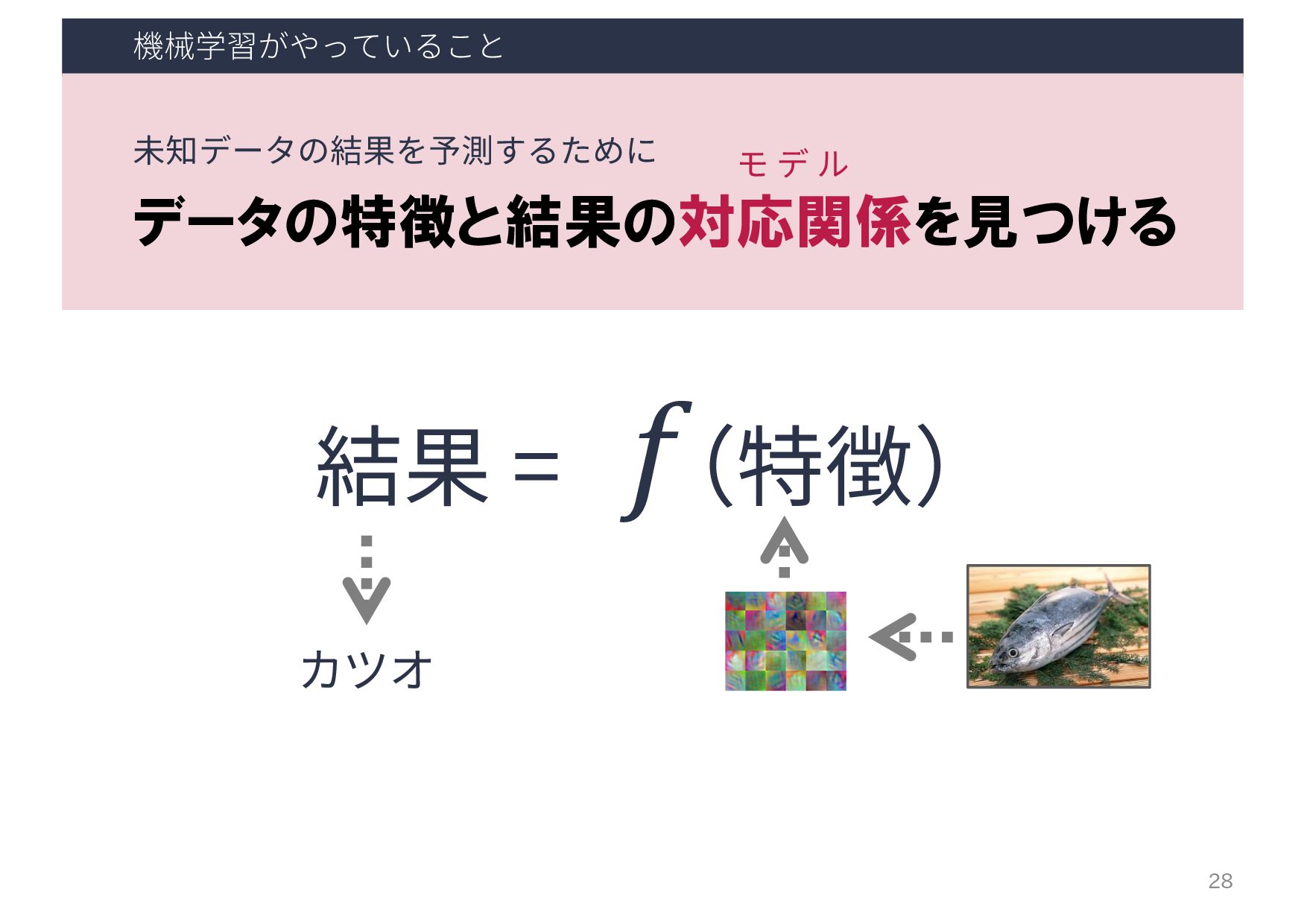
⼈⼯知能の研究(技術)トピック 人工知能 推論 探索 機械学習 知識表現 … 機械学習 大量のデータの背後に潜む法則性(モデル)を 自動的に取得し、予測や分類に役立てる技術
3
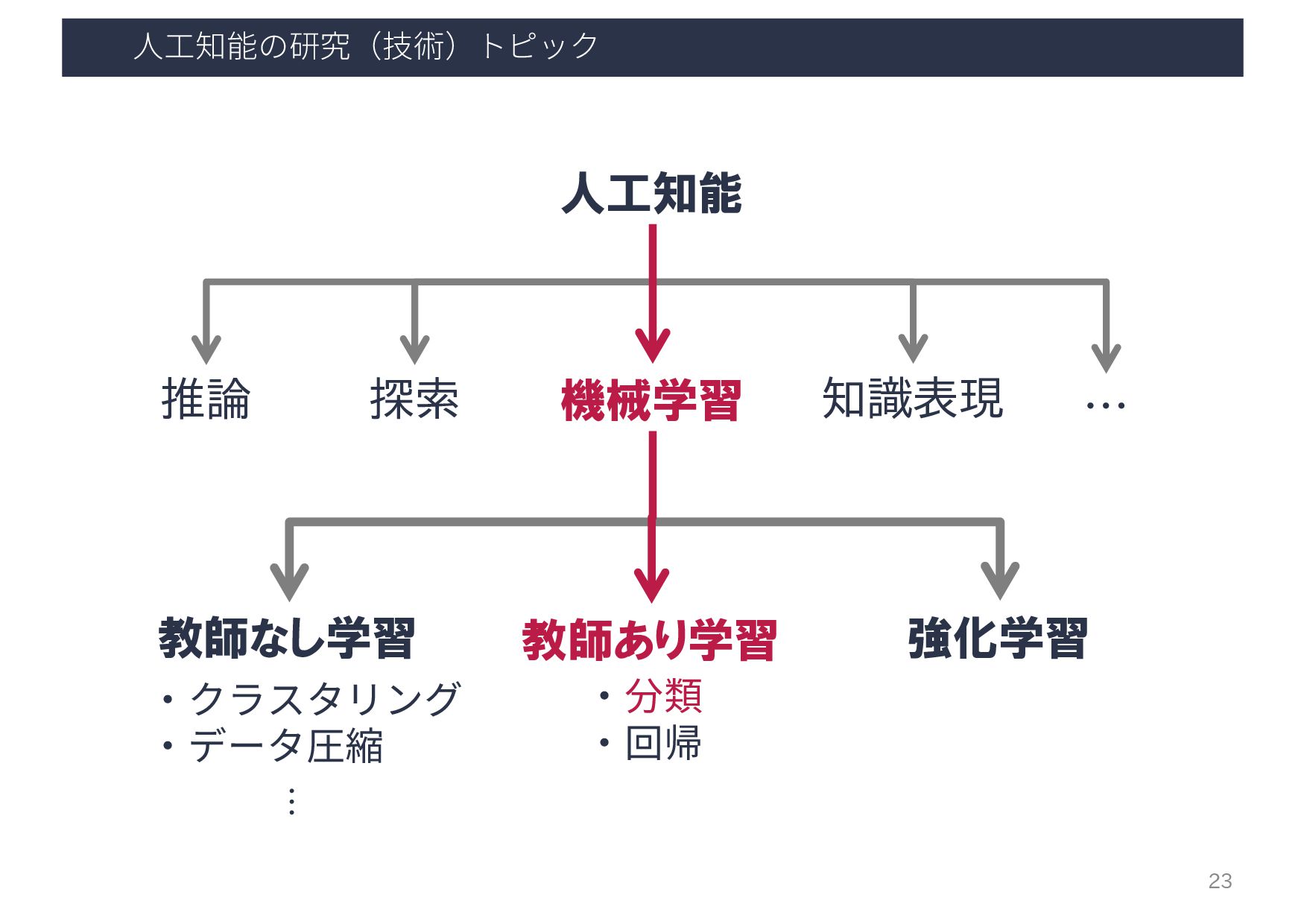
⼈⼯知能の研究(技術)トピック 人工知能 推論 探索 機械学習 知識表現 … 教師あり学習 教師なし学習 強化学習
・クラスタリング ・データ圧縮 ・分類 ・回帰 ・順序回帰 … 機械学習 4 …
機械学習の流れ(教師あり学習) ⼤量のデータ (正解ラベル付き) 前 処 理 特徴 抽出 学習 (モデル構築)
機械学習(ML)アルゴリズム 学習済み モデル ML 学習フェーズ 5
機械学習の流れ(教師あり学習) ⼤量のデータ (正解ラベル付き) 前 処 理 特徴 抽出 学習 (モデル構築)
機械学習(ML)アルゴリズム 学習済み モデル ML 推論 特徴 抽出 ? 前 処 理 未知データ (ラベルなし) 予測結果 推論フェーズ MLアルゴリズム 学習フェーズ 6
教師あり学習の歴史(⼀部抜粋) ロジスティック回帰 サポートベクターマシン 決定木 パーセプトロン 単純ベイズ分類器 ランダムフォレスト k-近傍法 ベイジアンネットワーク 深層学習
1958年 1957年 1951年 1979年 1985年 1992年 1960年代 2001年 2010年代 本⽇体験するのはコレ (初学者が勉強しやすい) 7
決定⽊の概要(問題定義) 入力 分類ラベルのついた ベクトルの集合(表データ) 出力 ラベルを予測するための ルールを要約した⽊ 利用するケース 予測モデルに加えて, 分類ルールを確認したいとき
ID 柄色 柄形 臭い 毒 1 紫 直線 あり あり 2 朱 末広 刺激 なし … … … … … キノコの記録 毒キノコを分類するルールを抽出 臭い あり なし 柄の色が緑 yes no 毒あり1% 毒あり100% … 8
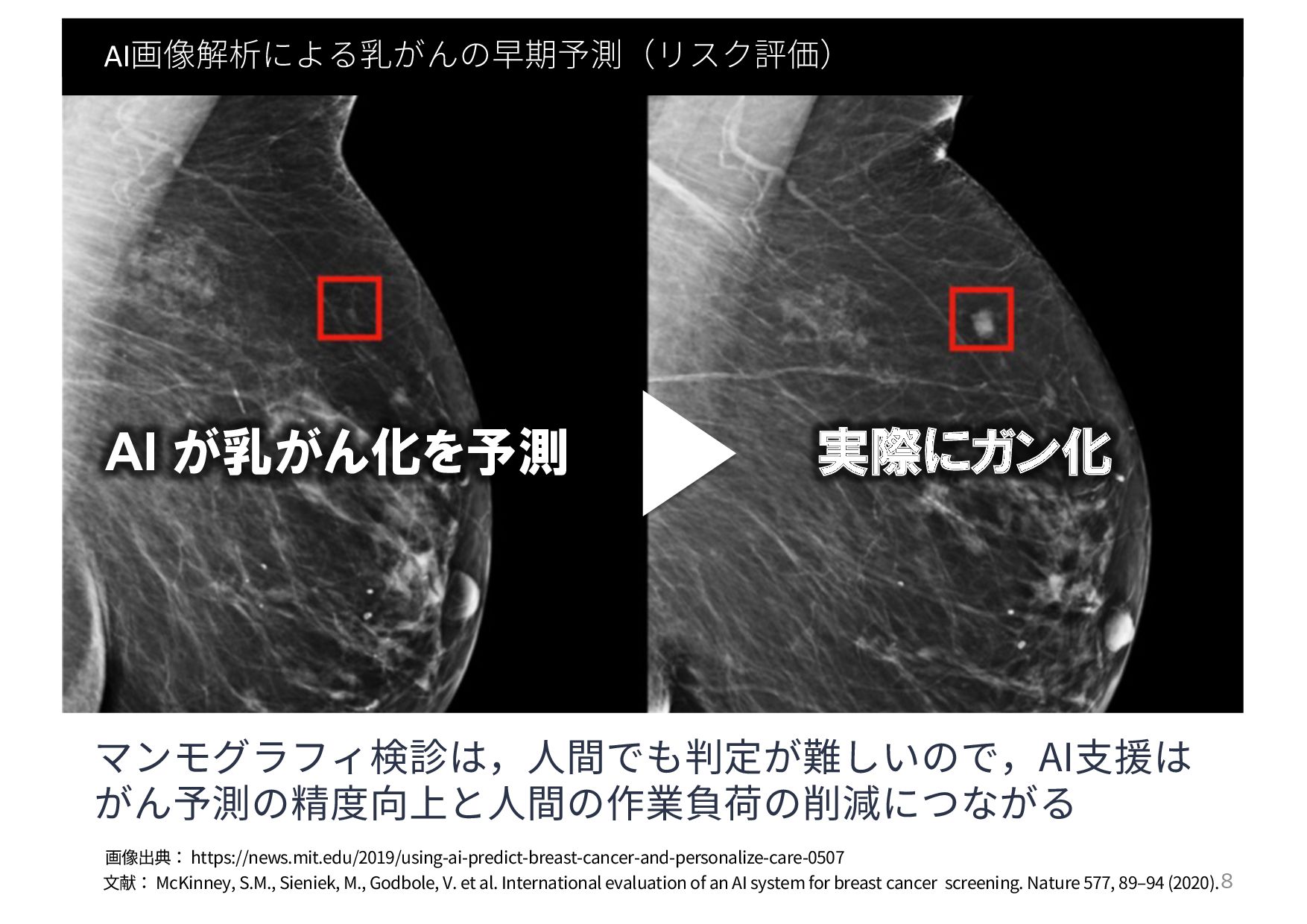
例: 迷惑メール分類問題 9 Email(通常メール)かSpam(広告メール)が ラベリングされたメールの本⽂を使って 迷惑メール分類器を作りたい HAM or SPAM ?
迷惑メールデータセット @UCI Machine Learning Repository 10 データセット: https://archive.ics.uci.edu/ml/datasets/spambase 4601通の英⽂メールに 関するデータセット
• ある単語がメールに占める割合 (例: business, free, address) • email or spamの2値ラベル • ある⽂字がメールに占める割合 (例: !, $, #) • 連続した⼤⽂字の⻑さの平均値 • 連続した⼤⽂字の⻑さの最⼤値 • 連続した⼤⽂字の⻑さの総和
データを分類するif-thenルールを出力 迷惑メール問題に対する決定⽊の出⼒例 11 画像出典: T. Hastie et al. (2009): “The
Elements of Statistical Learning”, Springer.
例: 毒キノコ分類問題 12 ID 柄色 柄形 臭い 毒 1 紫
直線 あり あり 2 朱 末広 刺激 なし … … … … … キノコの記録 毒キノコ分類ルール 臭い あり なし 柄の色が緑 yes no 毒あり1% 毒あり100% … 毒々しい⾊ → 毒あり 柄が縦に割ける → 毒なし ⾍が⾷べている → 毒なし 迷信 決定⽊ どうやってデータから分類ルールを見つけるか?
決定⽊アルゴリズムの直感的アイデア 柄の⾊が緑 有毒 無毒 データの割合 有毒 無毒 データの割合 YES NO
カサの裏にヒダ 有毒 無毒 データの割合 有毒 無毒 データの割合 YES NO vs. 分類ルールを仮適応したときにデータの不純度 (の加重平均)が最も小さくなるようなルールを選ぶ 13 異なるクラスの データの混じり度合 が⼩さいのはどっち?
決定⽊アルゴリズムの直感的アイデア 分類ルールを仮適応したときにデータの不純度 (の加重平均)が最も小さくなるようなルールを選ぶ 柄の⾊が緑 有毒 無毒 データの割合 有毒 無毒 データの割合
YES NO カサの裏にヒダ 有毒 無毒 データの割合 有毒 無毒 データの割合 YES NO > 分類後の データの不純度 14
不純度(impurity)の数学的定義 ある集合Sについて,ラベルがnS 個あり,その集合 内の要素がクラスkに属する割合をpk とすると, = " !"# $! 𝑝!
(1 − 𝑝! ) = 1 − " !"# $! 𝑝! % ジニ係数 IG (S) = − " !"# $! 𝑝! log 𝑝! エントロピー E(S) 15
エントロピーの計算例 16 以下の集合SのエントロピーE(S)を計算してみよう 𝑝(•) = 6 10 𝑝(•) = 4
10 , E 𝑆 = −𝑝 • log 𝑝 • − 𝑝 • log 𝑝 • = − 6 10 log 6 10 − 4 10 log 4 10 = 0.673
ジニ不純度とエントロピーを図⽰ 正例・負例の2クラスしかなく、 正例の割合を𝑝とする(負例の割合は 1 − 𝑝 ) エントロピー ジニ係数 2
x ジニ係数 𝑝 集合内の正例と 負例の数が等しい ときにどちらも 最⼤値をとる 17
分類ルールの良さの求め⽅ 18 分類後の集合の不純度の加重平均で評価 集合のサイズを重みとする平均 E 𝑆1 = − 3 6
log 3 6 − 3 6 log 3 6 = 0.693 E 𝑆2 = − 3 4 log 3 4 − 1 4 log 1 4 = 0.562 ルールの良さ = 6 10 𝐸 𝑆1 + 4 10 𝐸 𝑆2 = 𝟎. 𝟔𝟒𝟏 10個中6個がS1 10個中4個がS2 ルールA
決定⽊のアルゴリズム 1. 3. ステップ2で選択したルールでデータを分割 2. 4. 5. 分割の必要がなくなったら終了 全データについて,各特徴による分割パターン をすべて調査
データの不純度にもとづき,最適な分割ルール をひとつ選択 分割されたデータ群に対して,上記⼿順を 繰り返し適⽤ 19
予測⽊の成⻑の抑制(1/2) 予測木をできるだけ汎用的にするために 木の大きさを制限する(過学習の防止) • ⽊の葉っぱに含まれているデータの数 • 不純度の変化量 • ⽊の深さ •
⽊の葉っぱでの誤り率 20 ある事柄を説明するために、必要以上に多くを仮定するべきでない (オッカムの剃刀) 画像出典: wikipedia.org
予測⽊の成⻑の抑制(2/2) ここの深さまで 木の深さで制限 わざわざ点を分けても 不純度がほとんど変化しない 深すぎ 不純度の変化量で制限 予測木をできるだけ汎用的にするために 木の大きさを制限する(過学習の防止) 21
予測⽊の成⻑の抑制(2/2) ここの深さまで 木の深さで制限 不純度の変化量で制限 わざわざ点を分けても 不純度がほとんど変化しない 深すぎ 予測木をできるだけ汎用的にするために 木の大きさを制限する(過学習の防止) 22
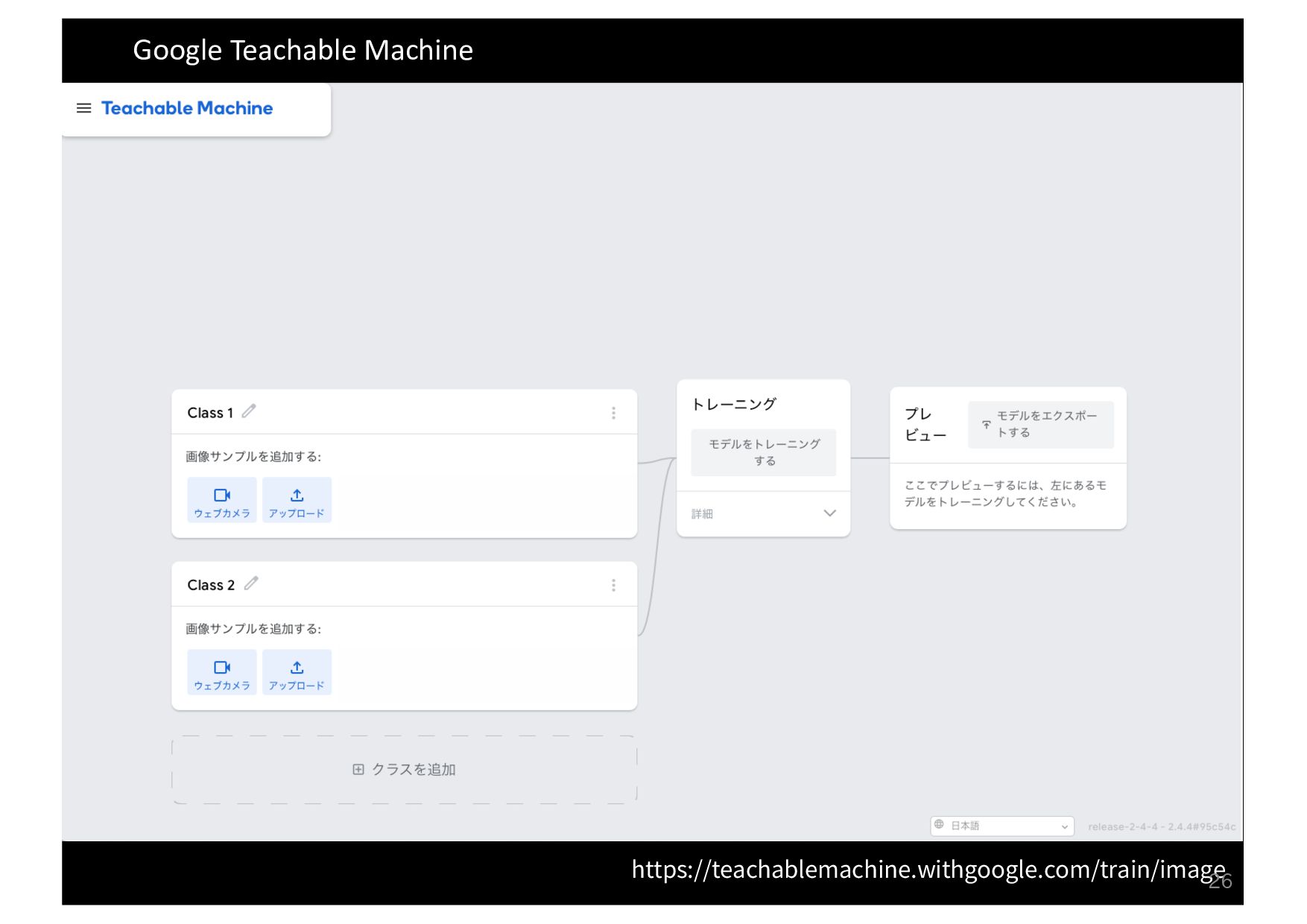
Hands-on タイム 以下のURLにアクセスして, 決定木による教師あり学習を体験しましょう https://mlnote.hontolab.org/ 23
余談: Why Python?(1/3) 24 CARET 機械学習 ライブラリ
余談: Why Python?(2/3) 25 機械学習 ライブラリ 前処理 ⾃然⾔語処理 画像処理 ウェブ
アプリ
余談: Why Python?(3/3) 26 機械学習 ライブラリ By Google By Facebook
深層学習 Pythonはデータサイエンスを全方位でカバー
数理的に考える分類問題(1/2) X 0 Y ? ▲ •と×のデータ集合が与えられたときに, 未知の2次元データが•か×をどう分類する? Q.
数理的に考える分類問題(2/2) X 0 Y ? ▲ •と×のデータを2分するような直線を見つける A. 直線より上側なら「×」 直線より上側なら「•」
ax+by+c=0
決定⽊が⾏っていること in 特徴空間(データ空間) X1 0 X2 t1 NO X1 ≦
t1 YES X2 ≦ t2 NO YES S1 S2 X1 ≦ t3 NO YES S3 X2 ≦ t4 NO YES S4 S5 t2 t3 S1 S2 t4 S4 S5 S3 直線で特徴空間を複数回分割する
分類モデルと分離(超)平⾯の関係 30 決定⽊ サポートベクタマシン ニューラルネットワーク 出典:https://tjo-en.hatenablog.com/entry/2014/01/06/234155 ランダムフォレスト
今後の予定 回 実施⽇ トピック 1 04/13 ガイダンス 2 04/20 pandas⼊⾨
3 04/27 決定⽊からはじめる機械学習 4 05/11 クラスタリング1:k-means & 階層的クラスタリング 5 05/18 クラスタリング2:密度ベースクラスタリング 6 05/25 分類1:K近傍法 & 教師あり機械学習のお作法 7 06/01 分類2:サポートベクターマシン 8 06/08 分類3:ニューラルネットワーク⼊⾨ 31
![決定木からはじめる機械学習 ⼭本 祐輔 名古屋市⽴⼤学 データサイエンス研究科 [email protected] 第3回 機械学習発展 (導入編)](https://files.speakerdeck.com/presentations/5e94d8d0e65b47589f075f85a271ff9e/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}