+ ℒ01- u ℒ+,-, ︓ℓ2 単眼Depthとオプティカルフロー[80, 65] u ℒ./ ︓motion trajectory の正則化 u ℒ01- ︓static-dynamicシーン分解のエントロピーloss Mip-NeRF360で提案した正則化 (参考) u ⾒た⽬・レンダリングの画質は改善するが、数値評価は変わらず u 各項の詳細はsupplementary materialを参照
2. NSFF[35]のデータセット(100-250frame) u Source Viewの選択: 𝑖 − 𝑟, 𝑖 + 𝑟 u Dynamic model: r = 3 u Static model: u データセット1はターゲット時間から12フレーム以内での近傍の明確な視点を全て選択 u データセット2に関しては[34]の⽅法で𝑟!"# を求めて$%!"#. &%& としている(𝑁'( = 16) u Setup u カメラPose︓COLMAPで算出 u Ray 𝑟! に対して128のcoarse-to-fine samplingを⾏う[70] u OptimizerはAdam u 最適化︓3のデータセット10秒動画1つに対してA100×8で2⽇ u rendering映像は768×432、20秒程度 u 最適化パラメータはsupplementary materialを参照
⻑時間のシーンに対応可能 u 感想 u シーンをStaticとDynamicに分けてそれぞれでrenderingし、最後にcombinedする考 え⽅はシンプル u 細かい違いがあって試すにも慣れてないと難しい u 既存⼿法の活⽤が多数あるため、システムとして複雑 u 最適化項⽬が多い(IBR、Motion Trajectory、Segmentation)
for appearance acquisition. ArXiv, 2008.03824, 2020. u [10] Perre Charbonnier et al, Two deterministic half-quadratic regularization algorithms for computed imaging. ICIP , vol.2, pages 168-172, 1994. u [34] Zhengqi Li et al, Learning the depths of moving people by watching frozen people. CVPR 2019 u [35] Zhengqi Li et al, Neural scene flow for space-time view synthesis of dynamic scenes. CVPR 2021. u [50] Keunhong Park et al, HyperNeRF: A higher-dimensional representation for topologically varying neural radiance fields. arXiv:2106.1328, 2021. u [65]Zachary Teed et al, RAFT: Recurrent all-pairs field transforms for optical flow. EECV 2020. u [67]Chaoyang Wang et al, Neural prior for trajectory estimation. CVPR 2022. u [70]Qianqian Wang et al, IBRNet: Learning Multi-View Image-Based Rendering, CVPR 2021 u [80]Zhoutong Zhang et al, Consistent depth of moving objects in video, ACM Transactions on Graphcis. 40(4):1-12, 2021
{kind=link}
{kind=link}
{kind=link}
{kind=link}
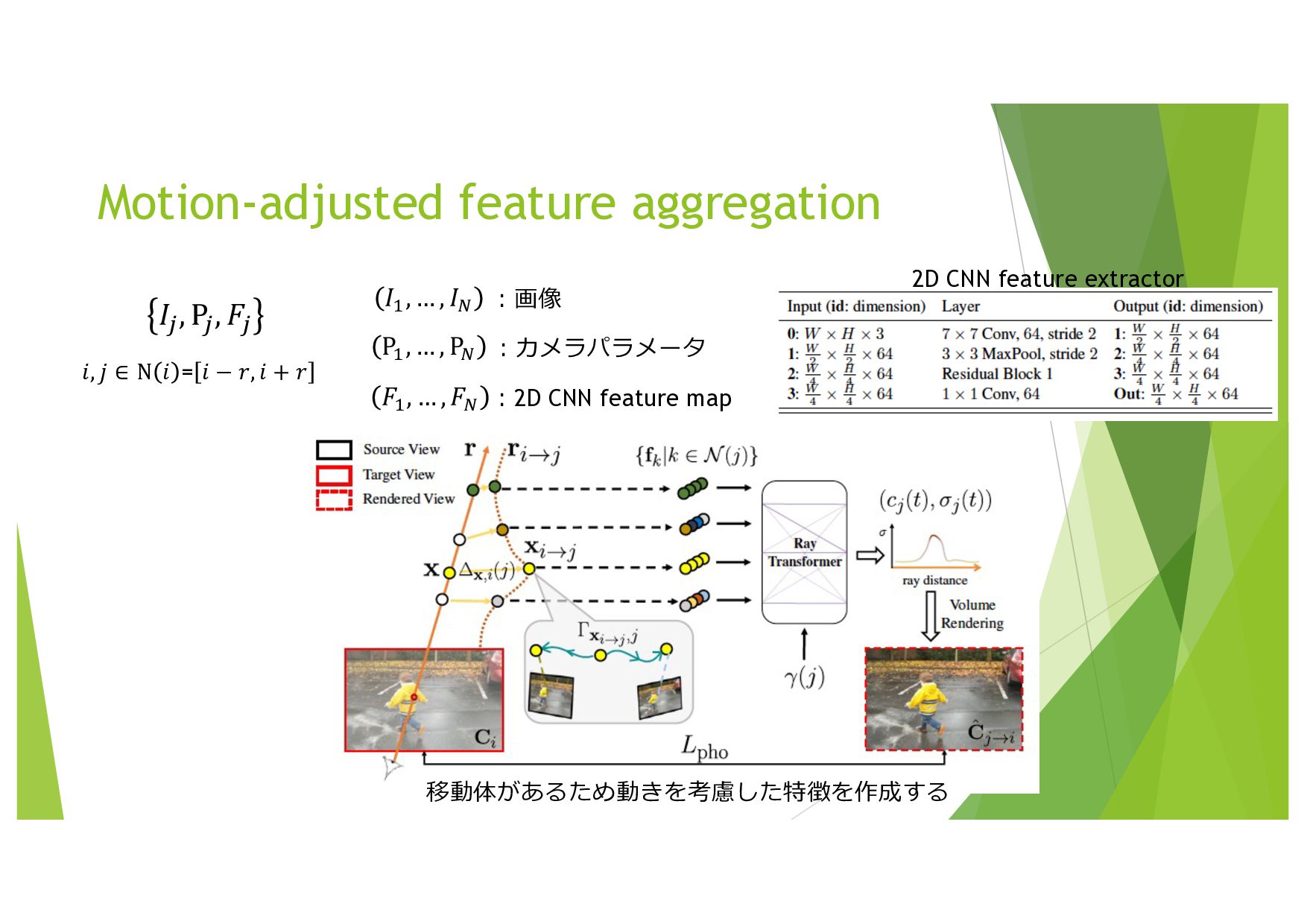{kind=link}
![Motion trajectory fields︓移動体の軌跡 u 学習された基底関数で記述されたmotion trajectory fieldで表現 Motion trajectory fields[67]](https://files.speakerdeck.com/presentations/e7034498b04c4672a750b8aa360c1249/slide_5.jpg){kind=link}
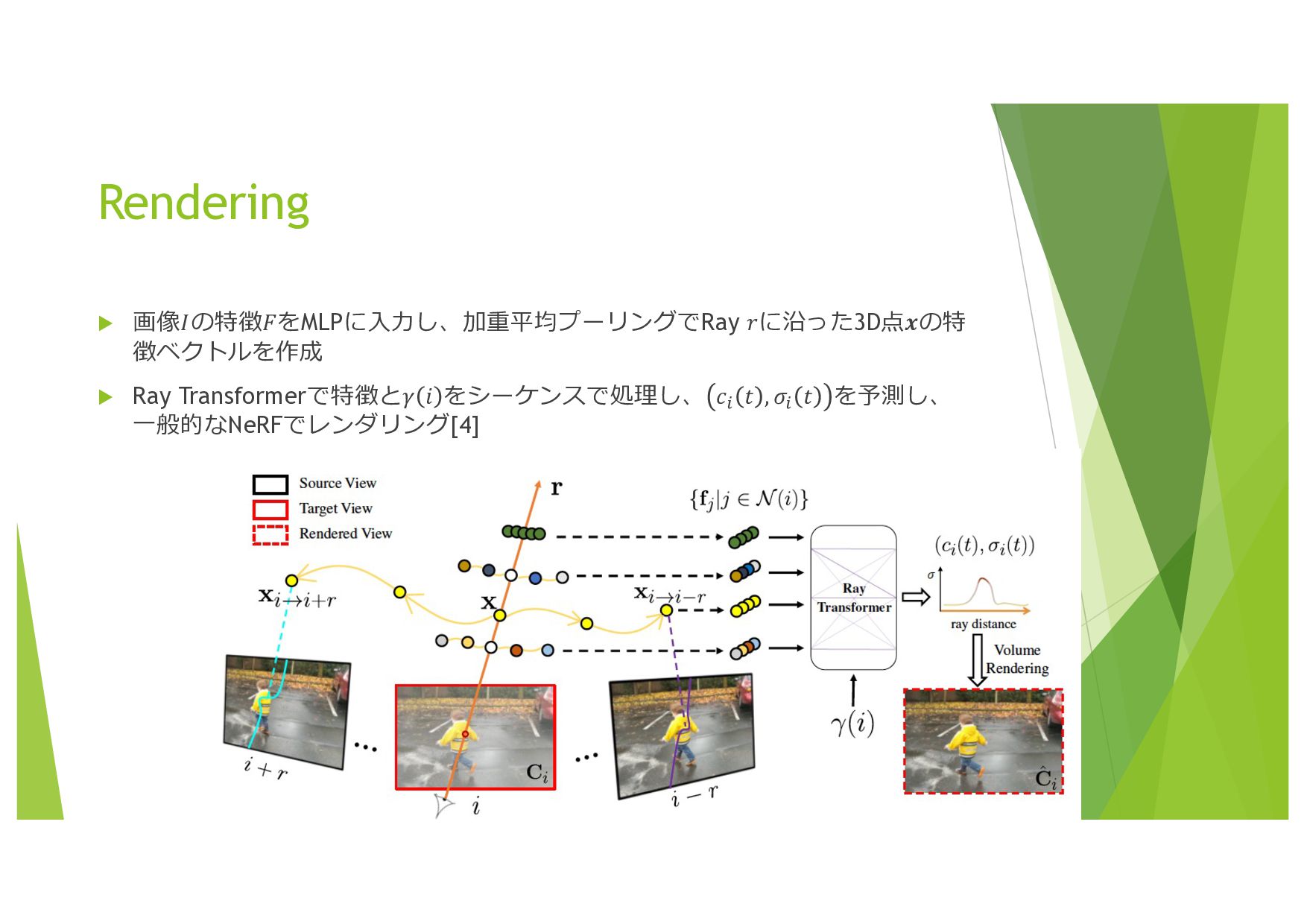{kind=link}
{kind=link}
{kind=link}
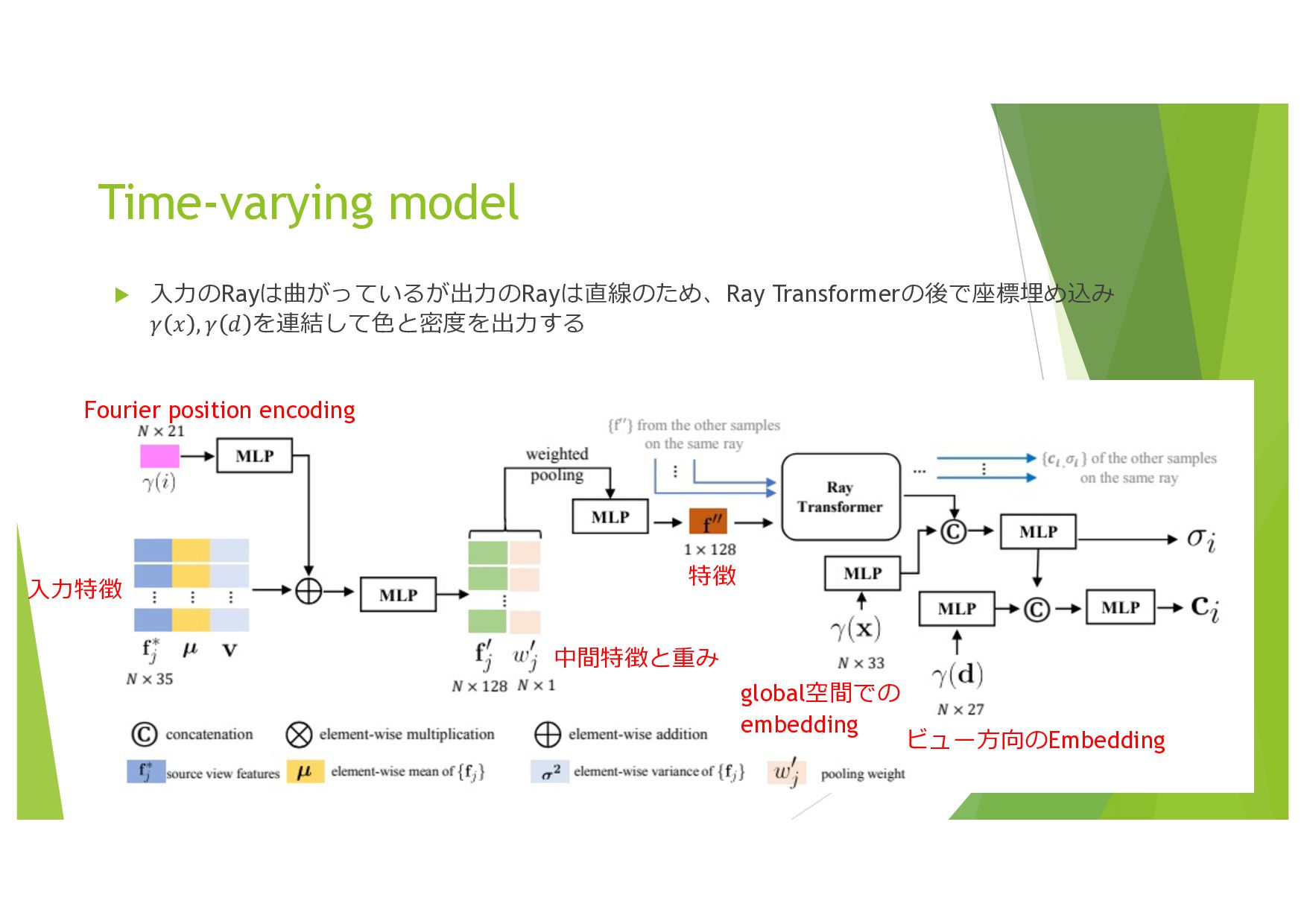{kind=link}
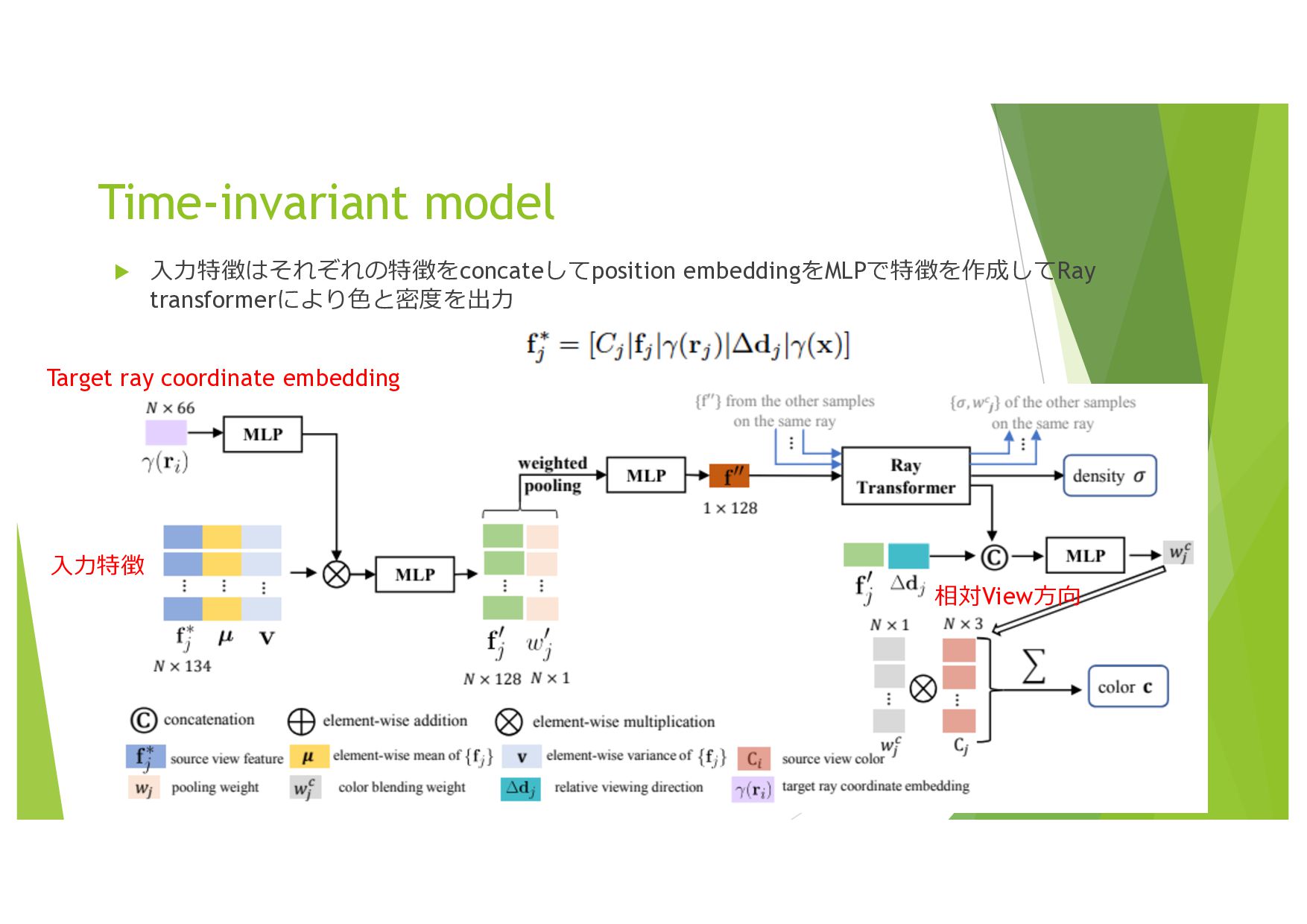{kind=link}
{kind=link}
{kind=link}
{kind=link}
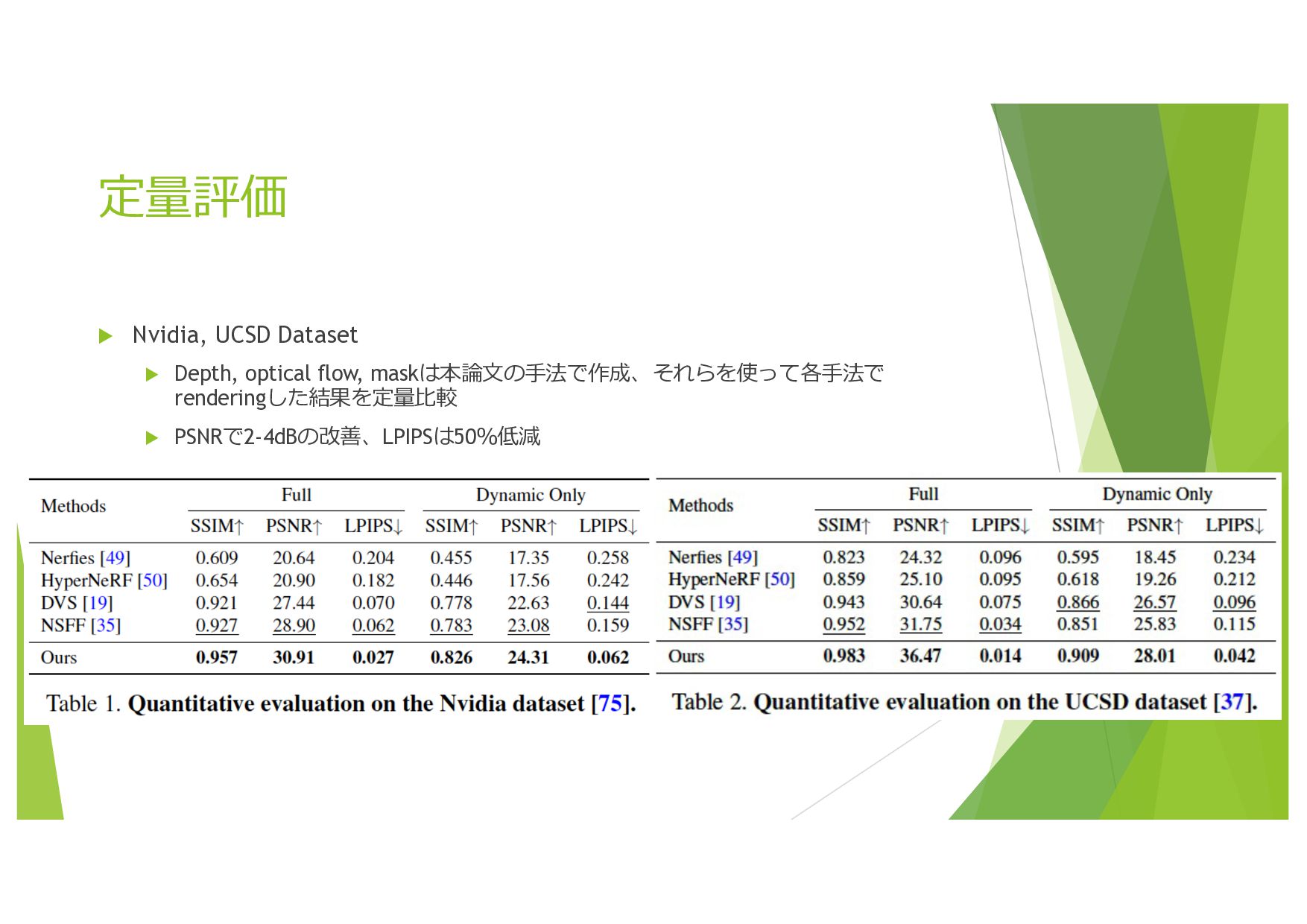
![Implementation details u データセット 1. Nvidia Dataset[75]、UCSD Dynamic Scenes Dataset[37]](https://files.speakerdeck.com/presentations/e7034498b04c4672a750b8aa360c1249/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
![映像でのレンダリング u [35] データセット(10秒映像)のIBR結果 ※GitHubから引⽤](https://files.speakerdeck.com/presentations/e7034498b04c4672a750b8aa360c1249/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
![参考⽂献 u [4] Sai Bi et al, Neural reflectance fields](https://files.speakerdeck.com/presentations/e7034498b04c4672a750b8aa360c1249/slide_20.jpg){kind=link}