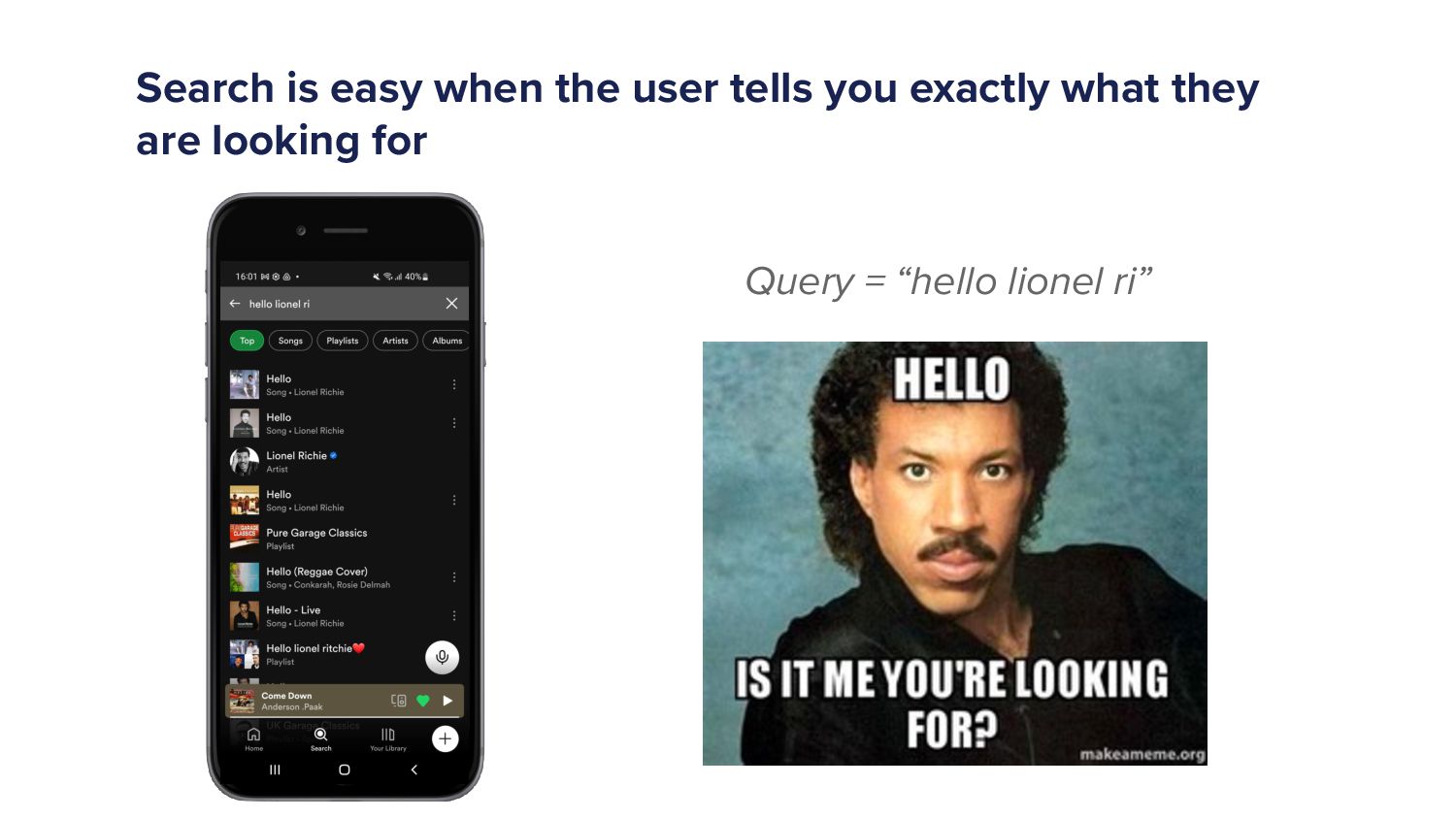
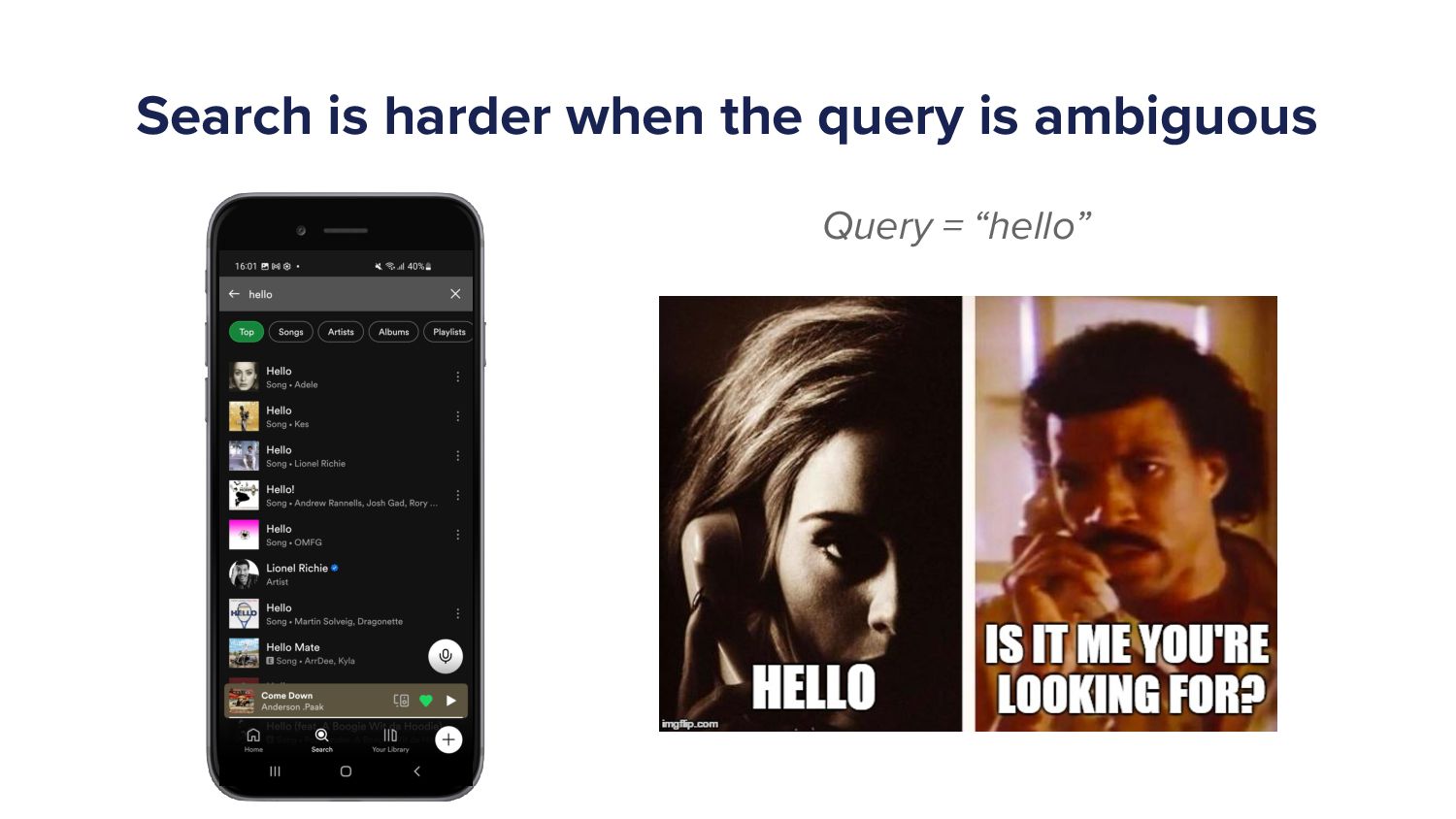
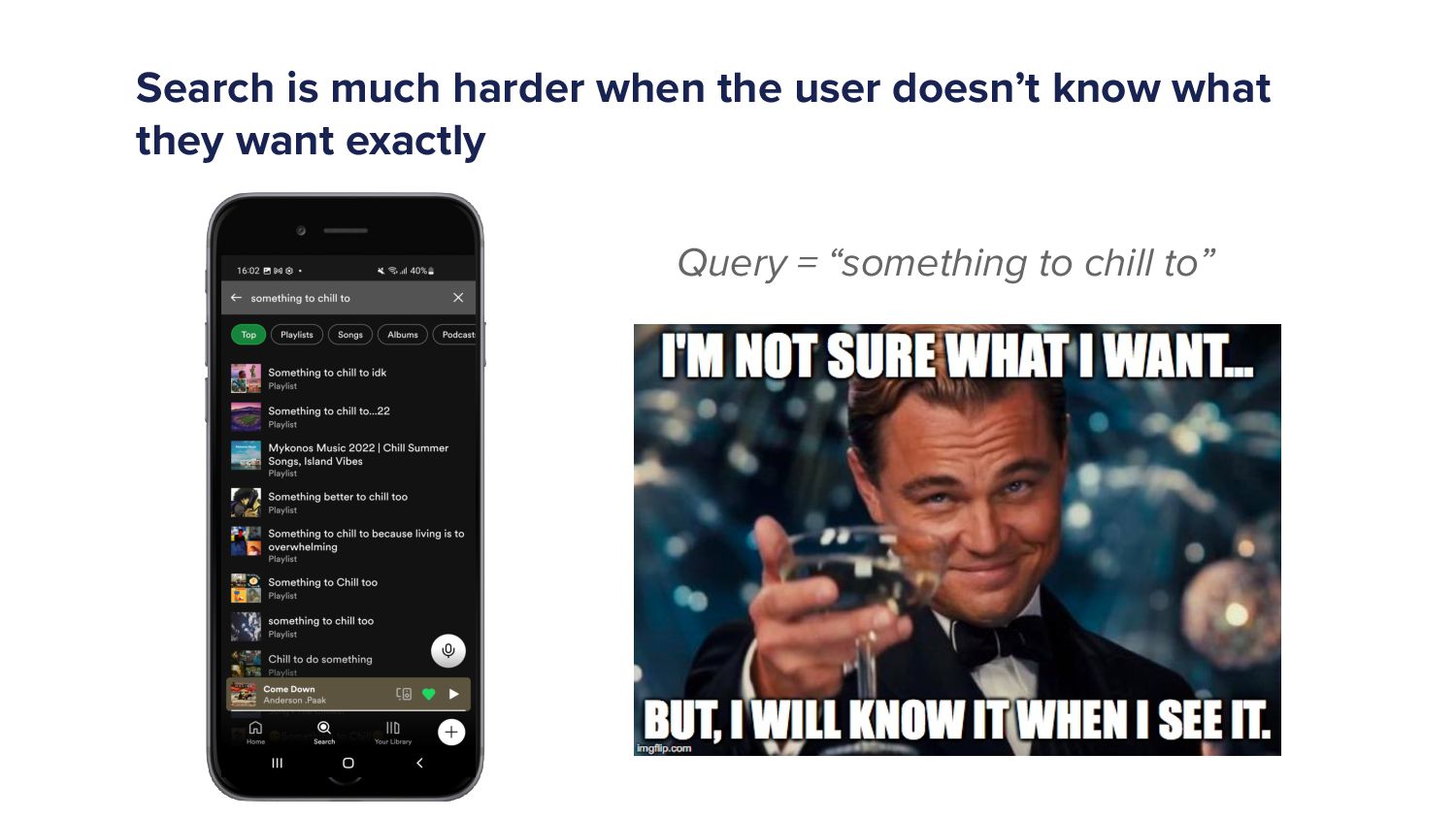
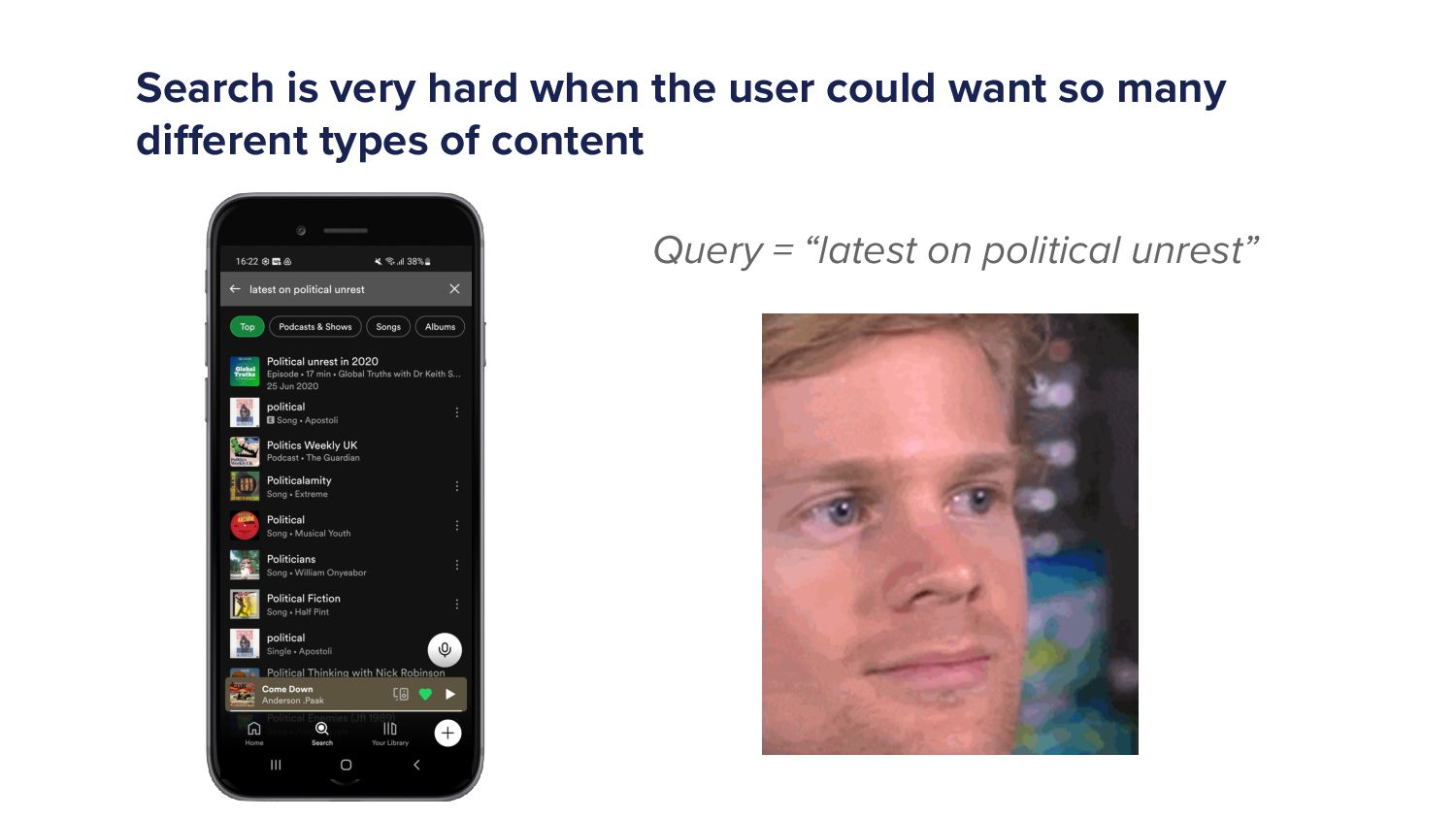
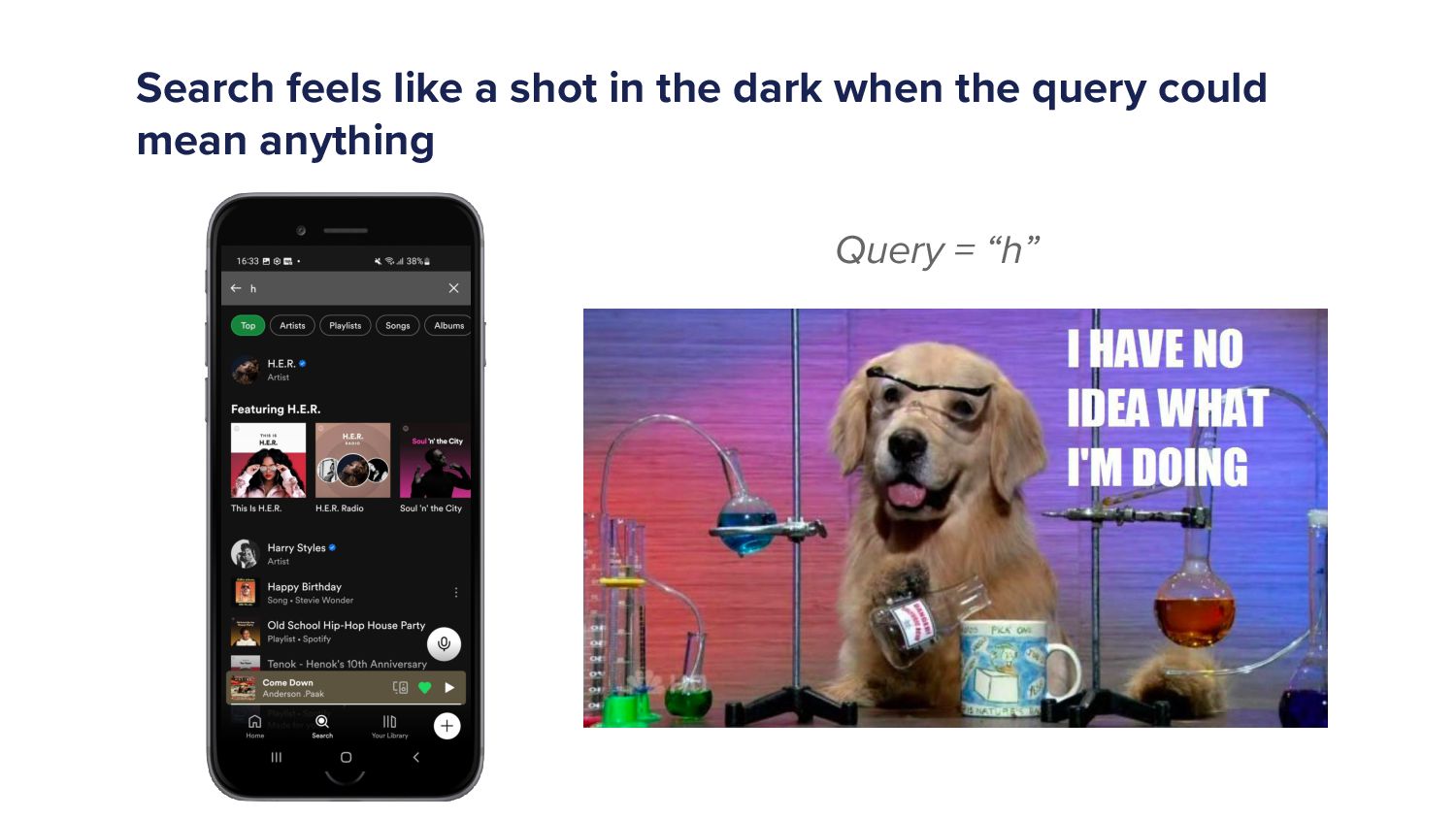
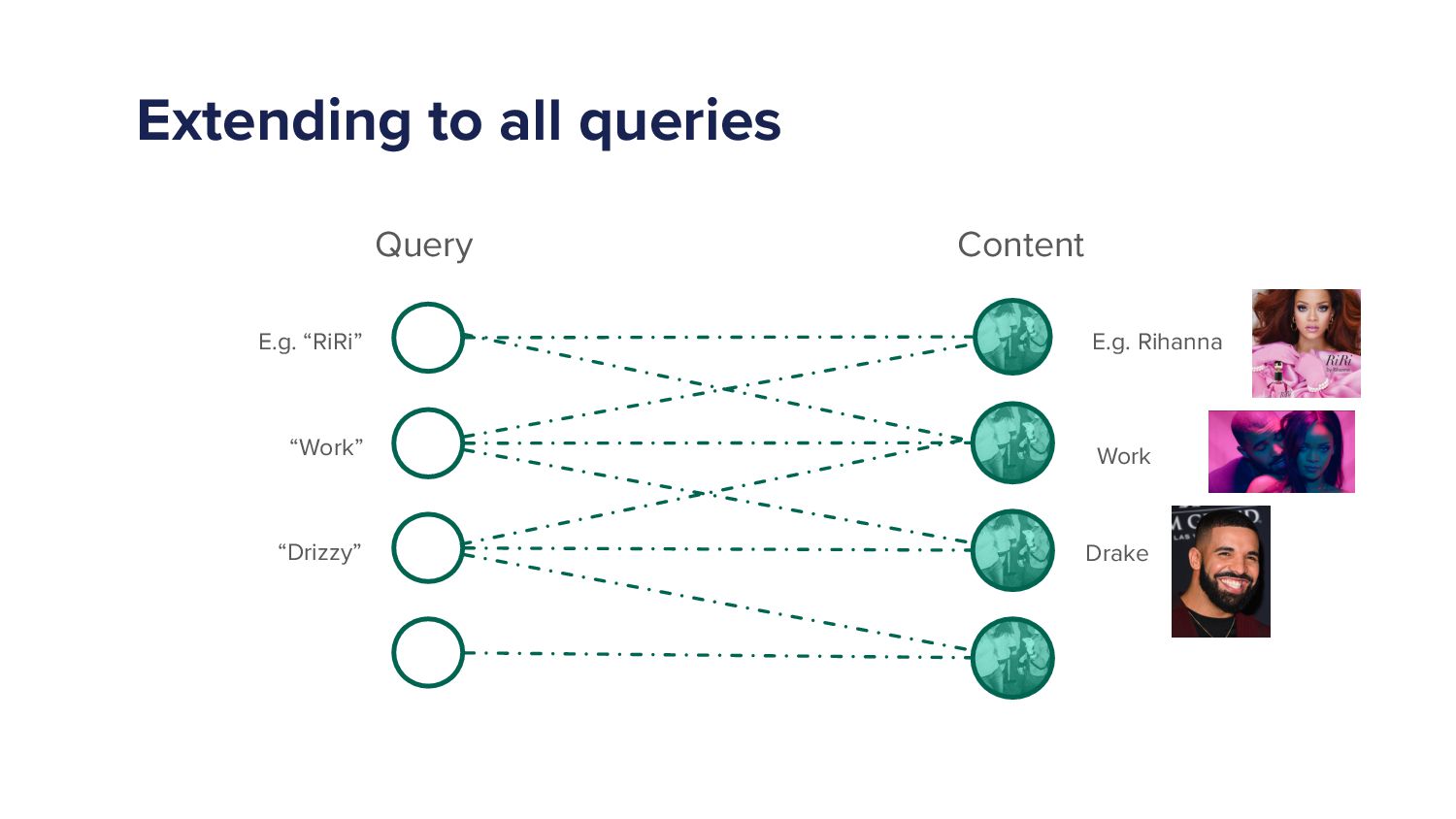
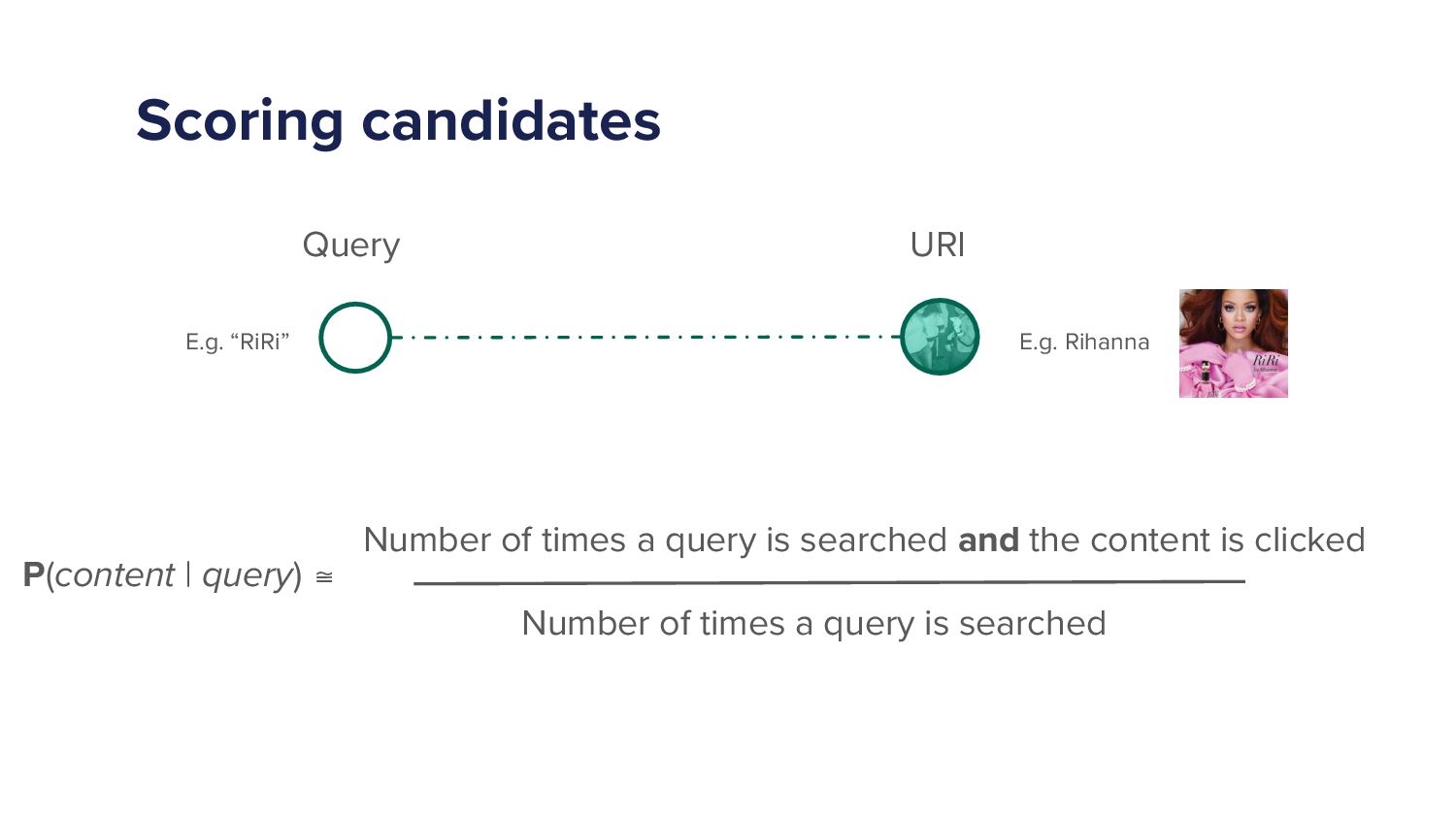
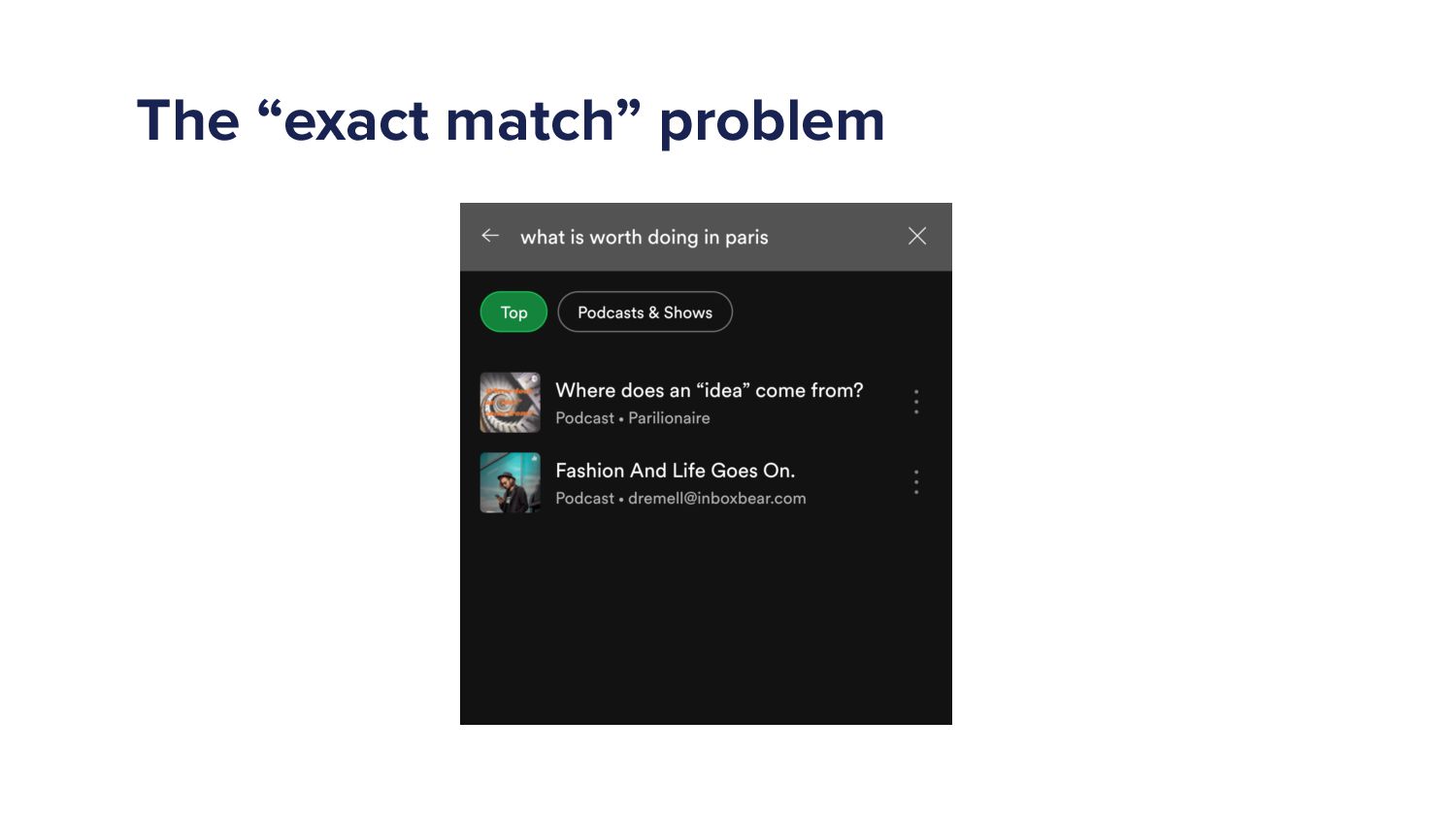
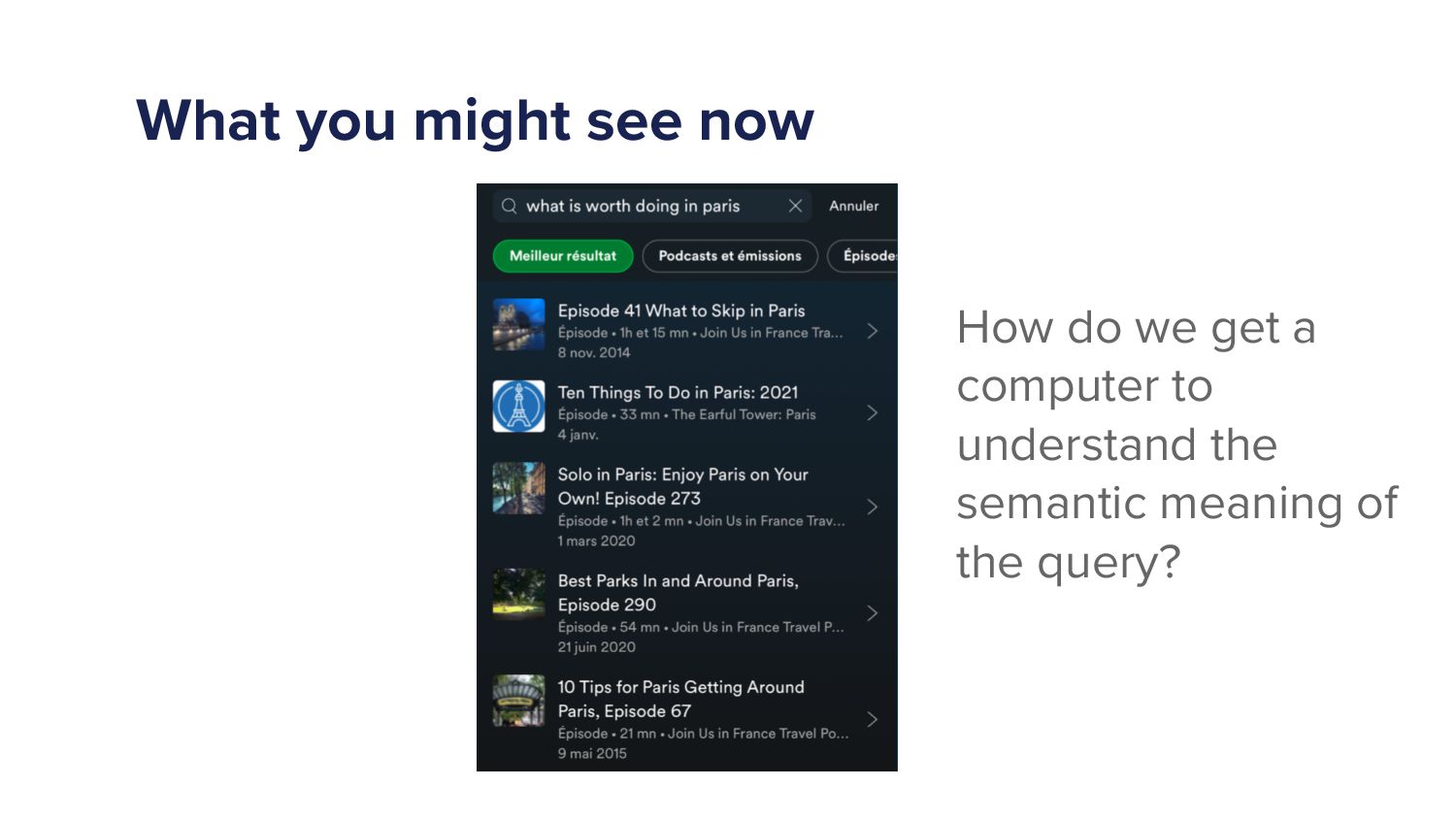
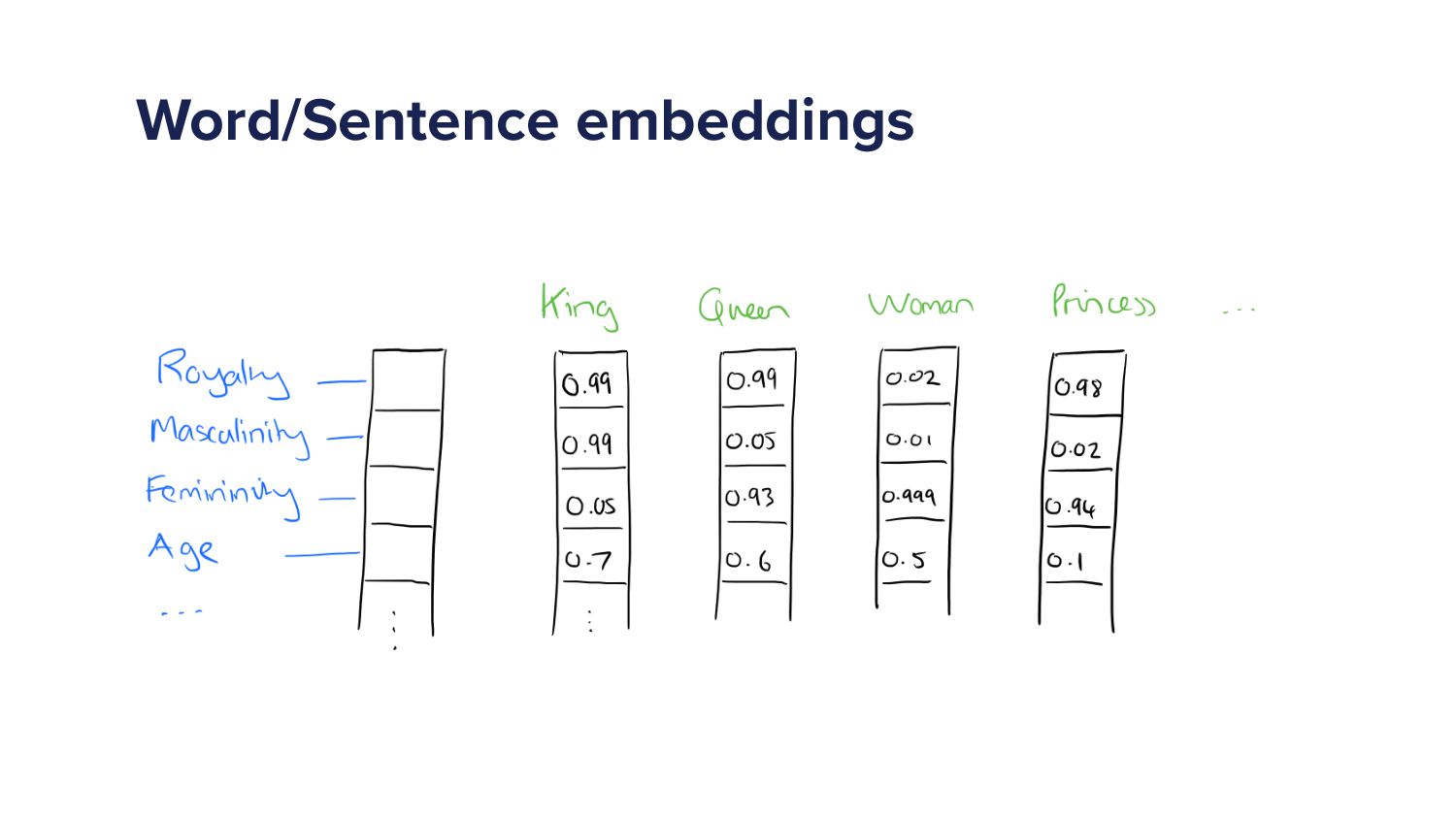
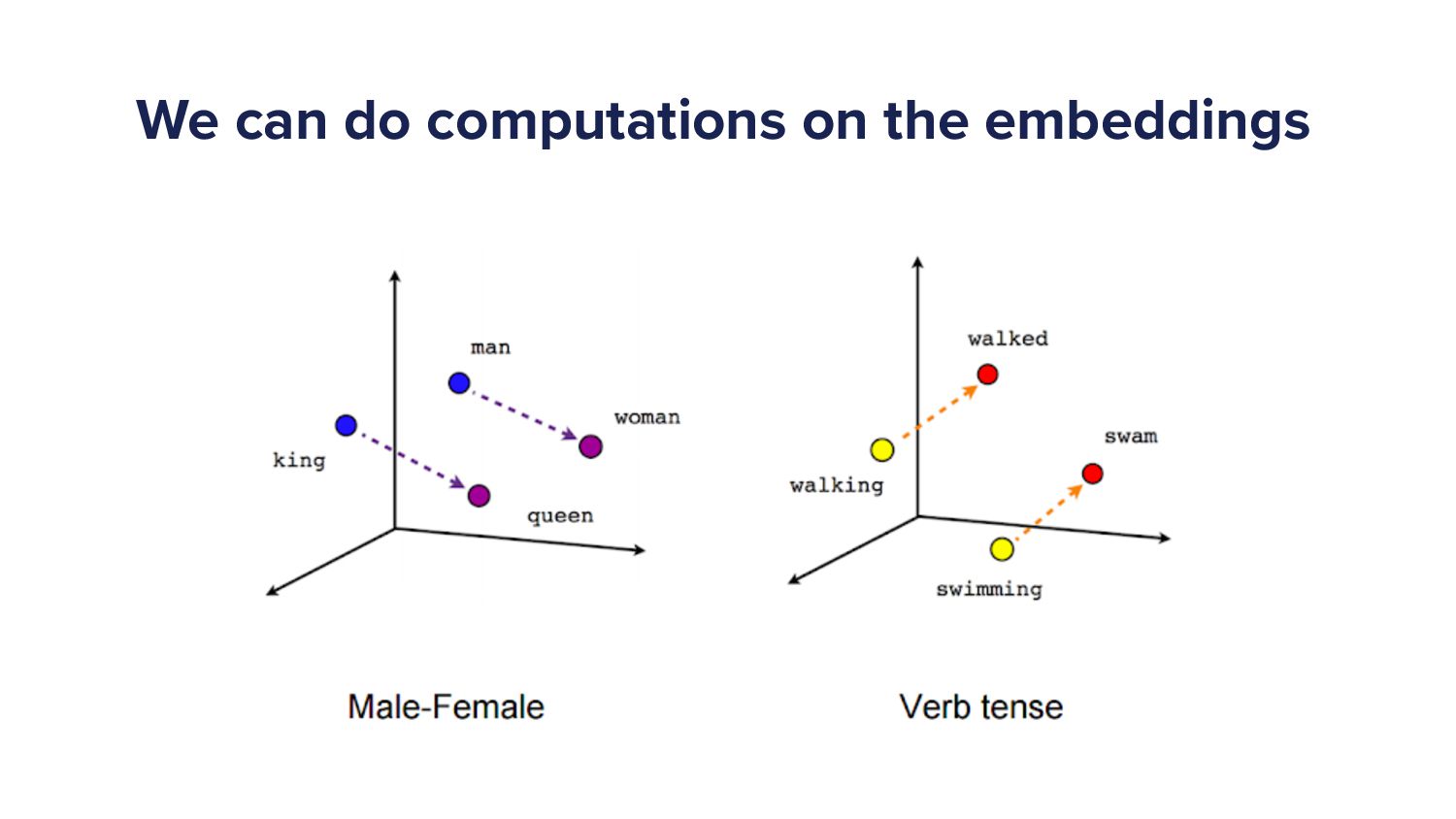
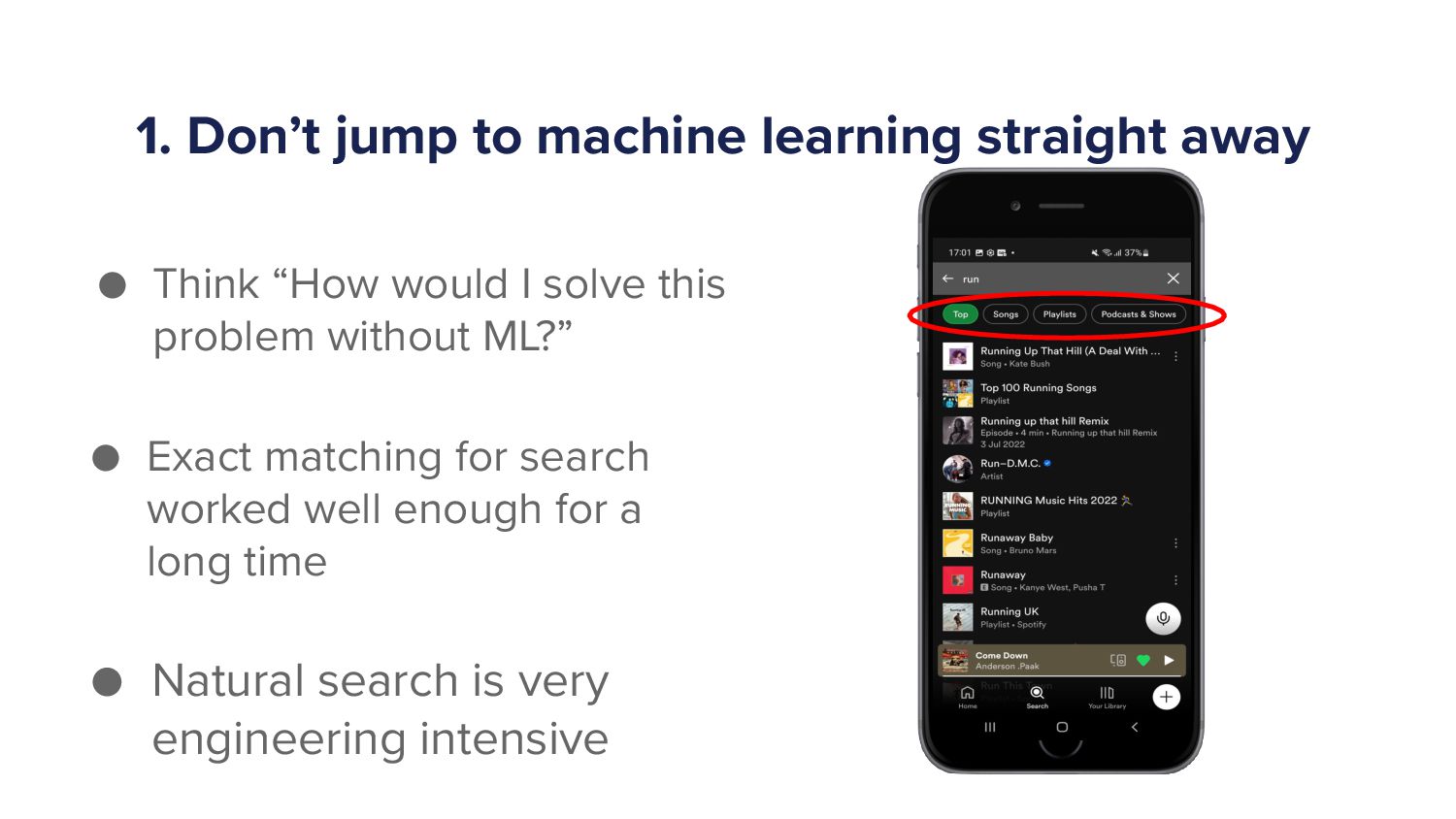
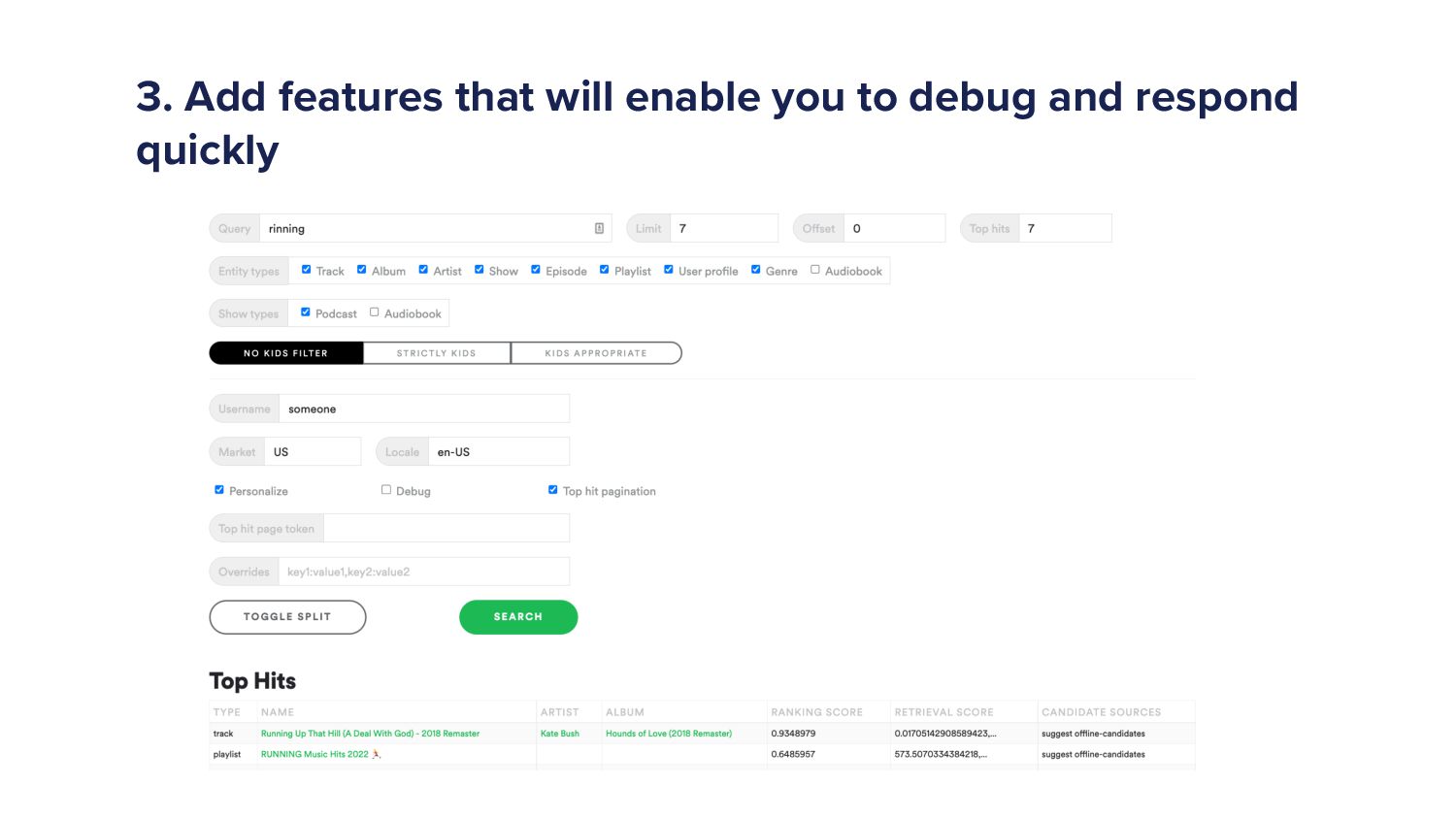
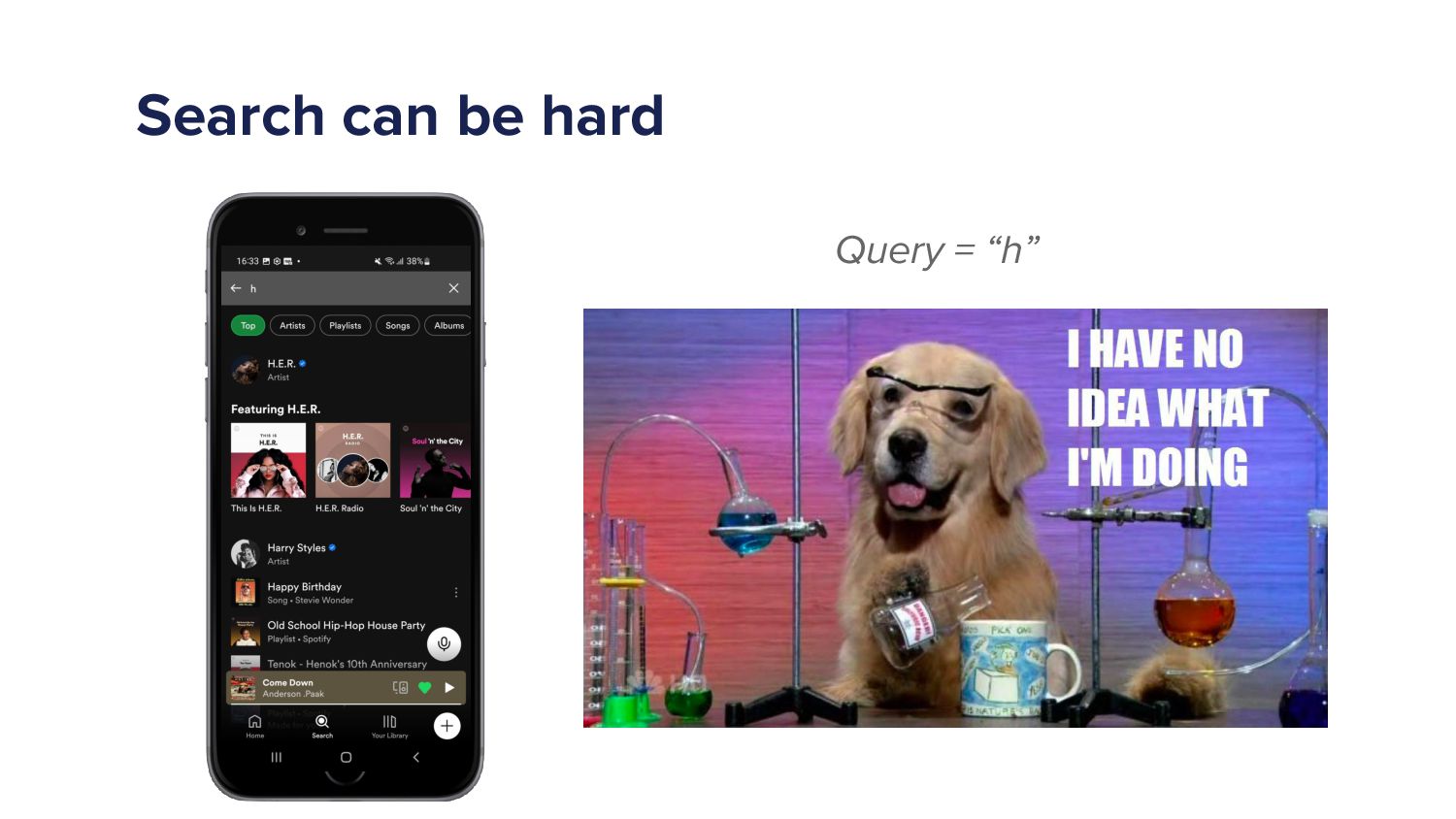
When a Spotify user types a query into the search bar it sets off a cascade of algorithms which ultimately ends in the user being shown a set of music and/or podcast results. This cascade of processes can be very complex as we must try to understand exactly what the user is looking for and choose a handful of results from a set of 10s of millions of potential options. As more and more items are added to the Spotify catalogue, from music to podcasts and soon audiobooks too, the Search team has increased in size and scope to try to tackle the growing challenges. In this talk I'll give an overview of the components of a typical search system and explain some of the challenges that arise in search systems. Then I'll talk about some of the new algorithms that we've developed over the last year that have led to huge improvements in Search quality. Finally, I'll outline some of the general lessons that I've personally learned with building machine learning models.
Head to www.turingfest.com to learn more about Europe's best cross-functional tech conference.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
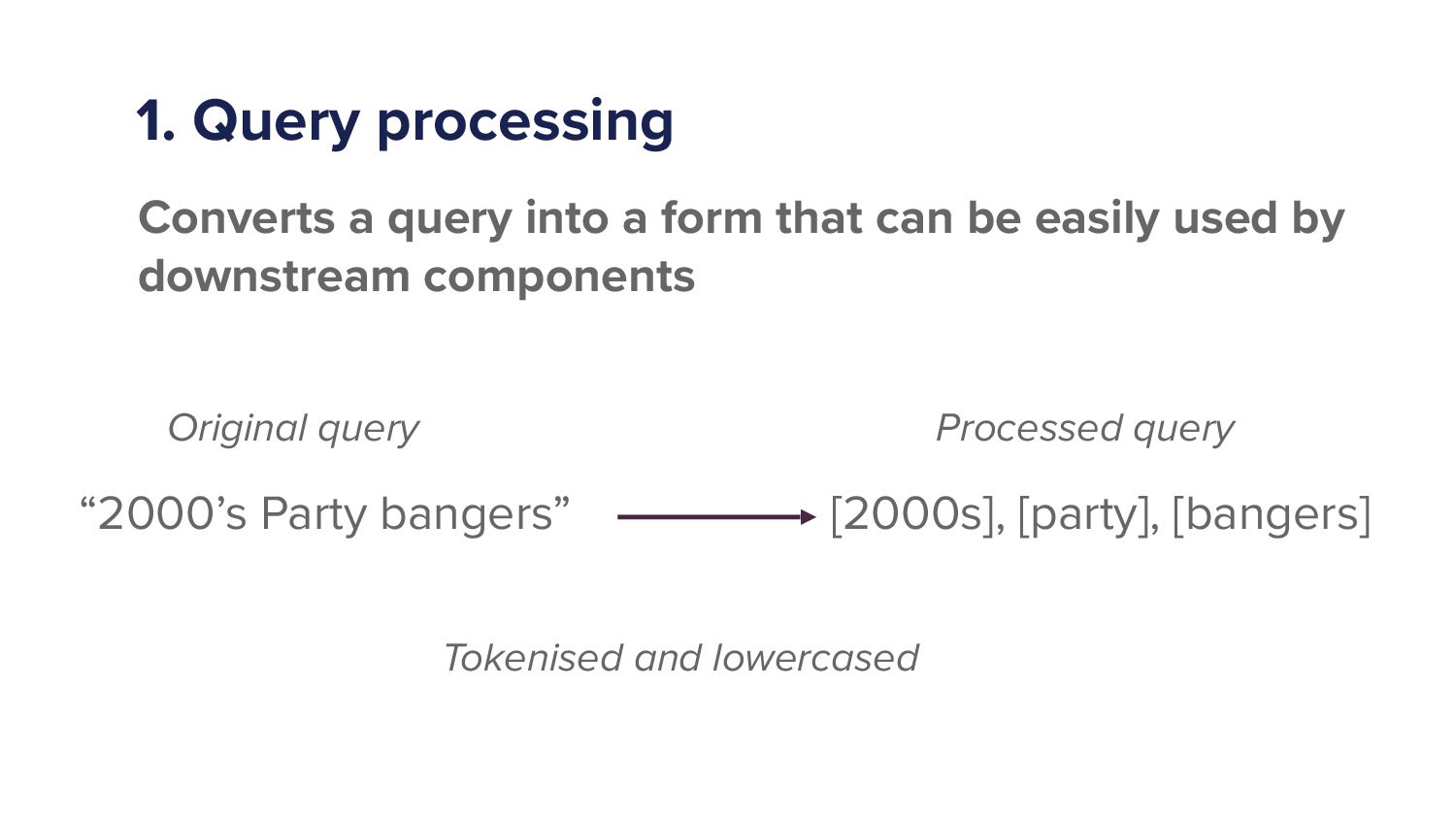{kind=link}
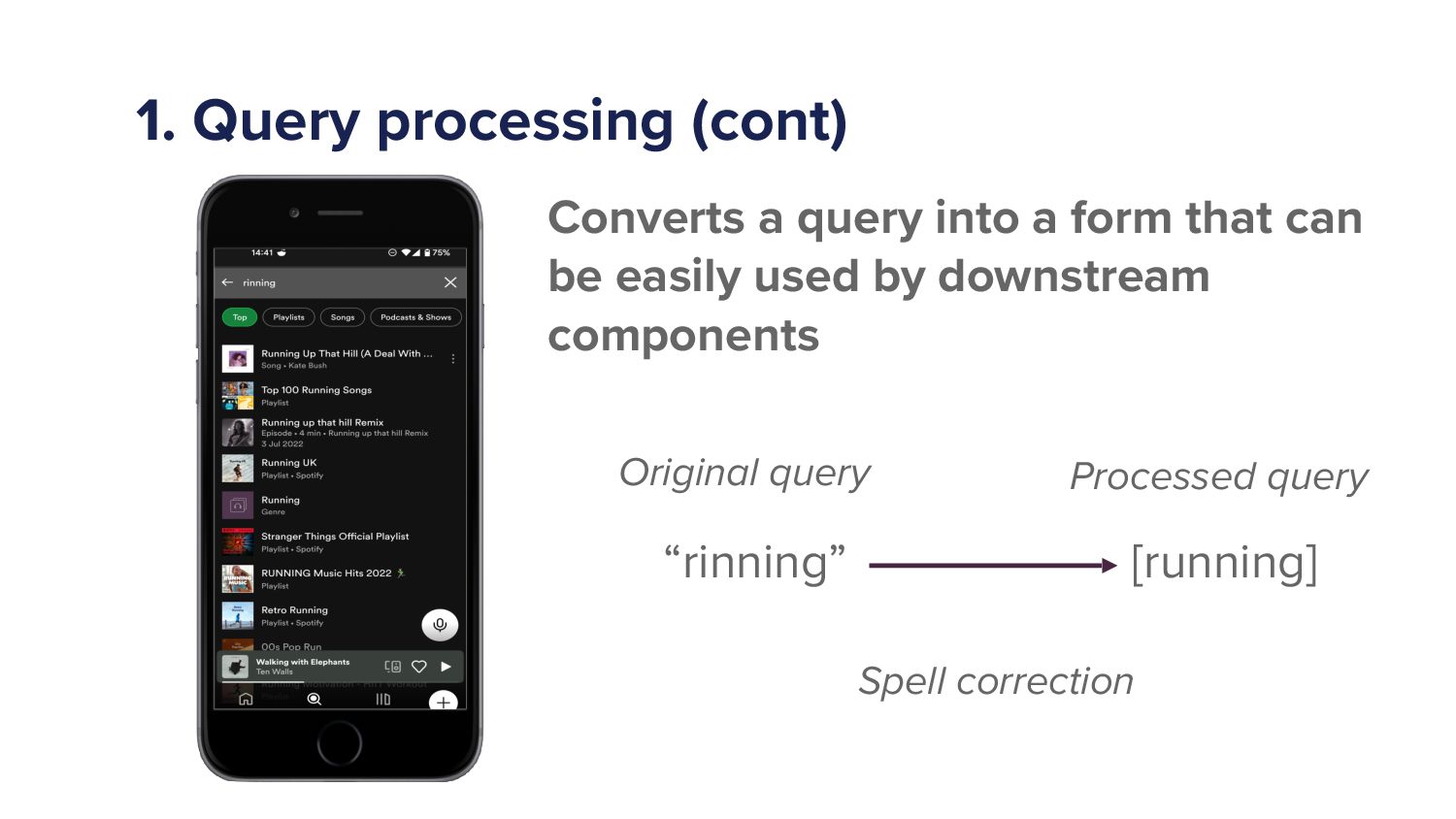{kind=link}
{kind=link}
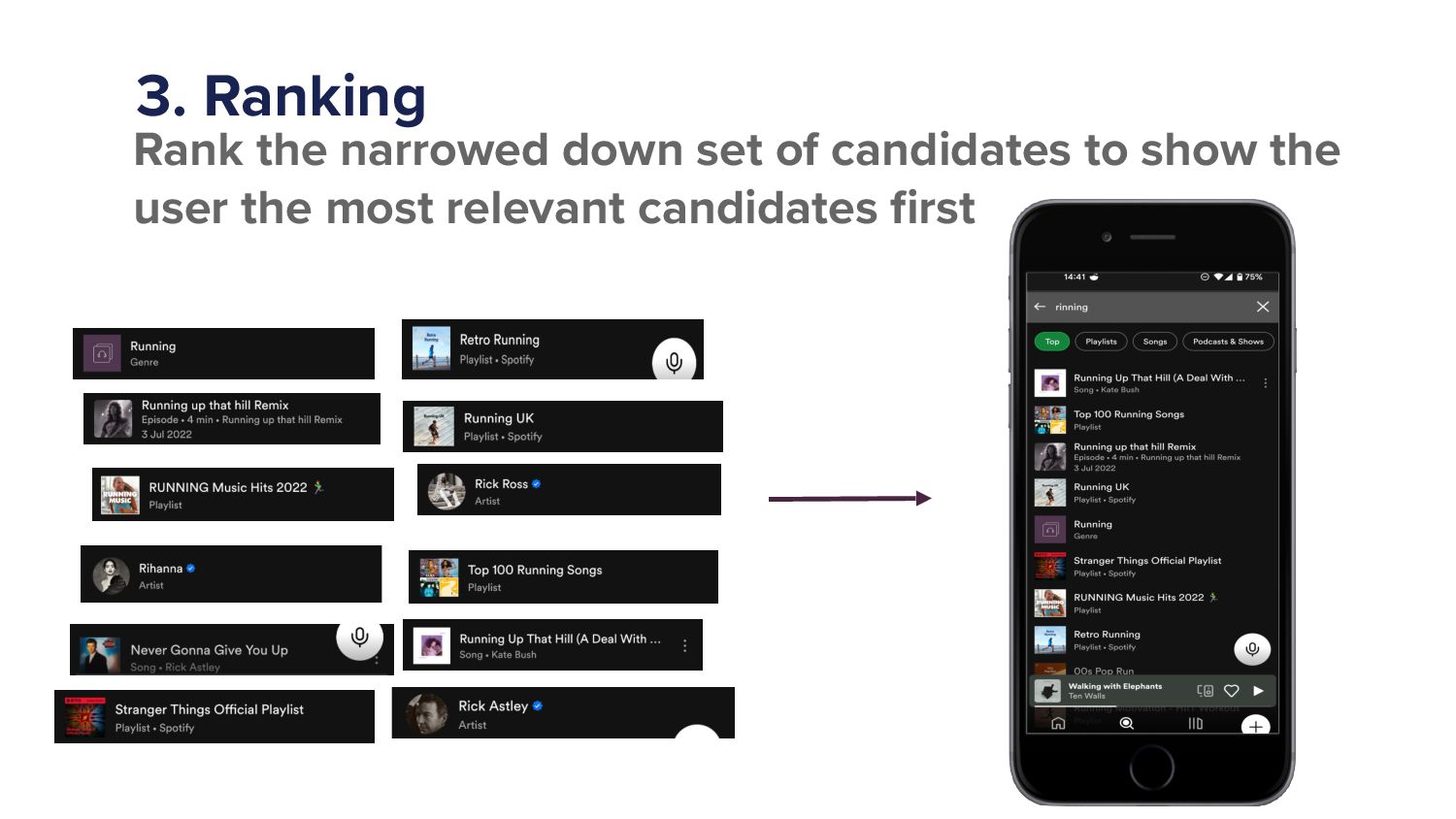{kind=link}
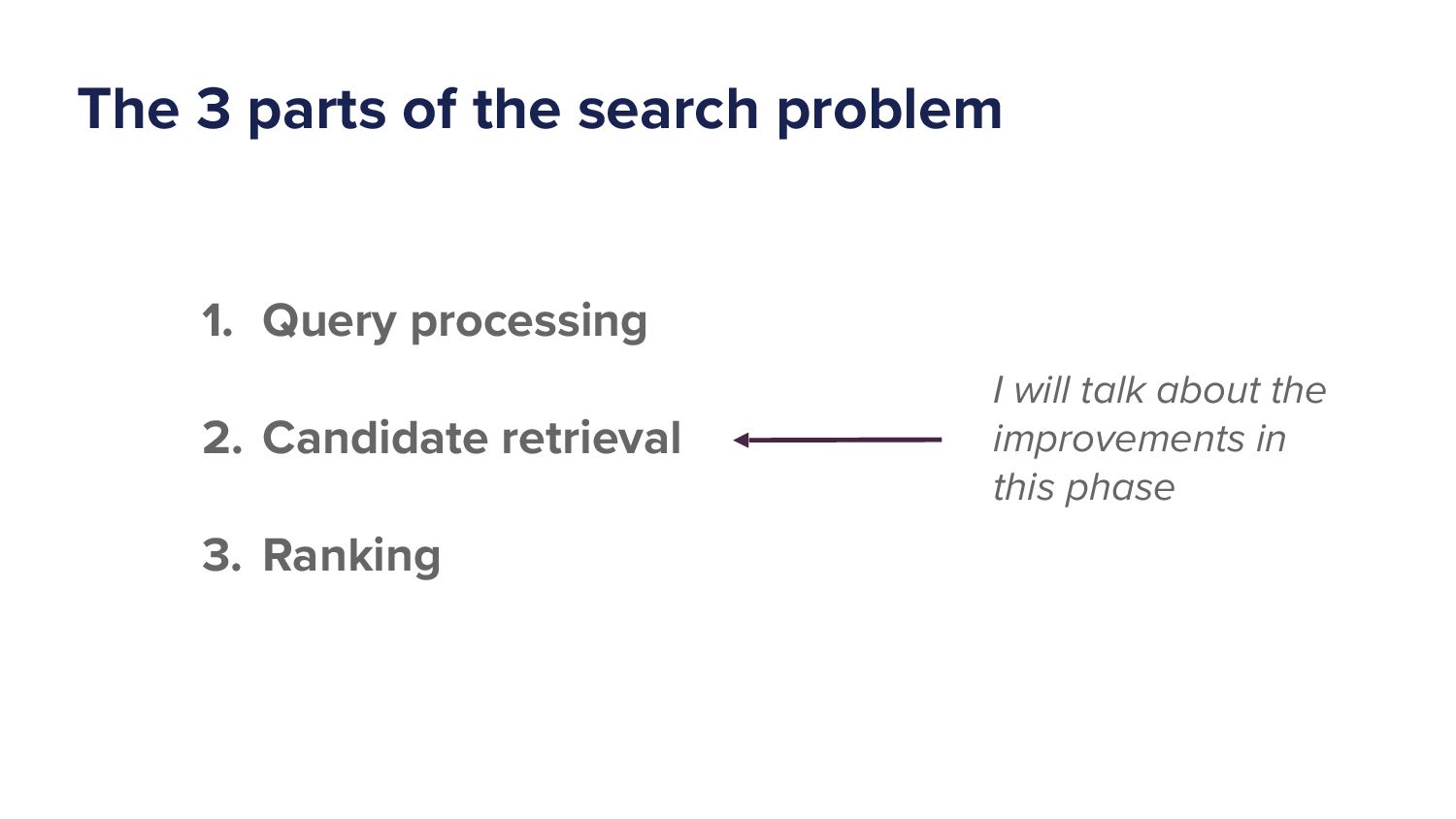{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}