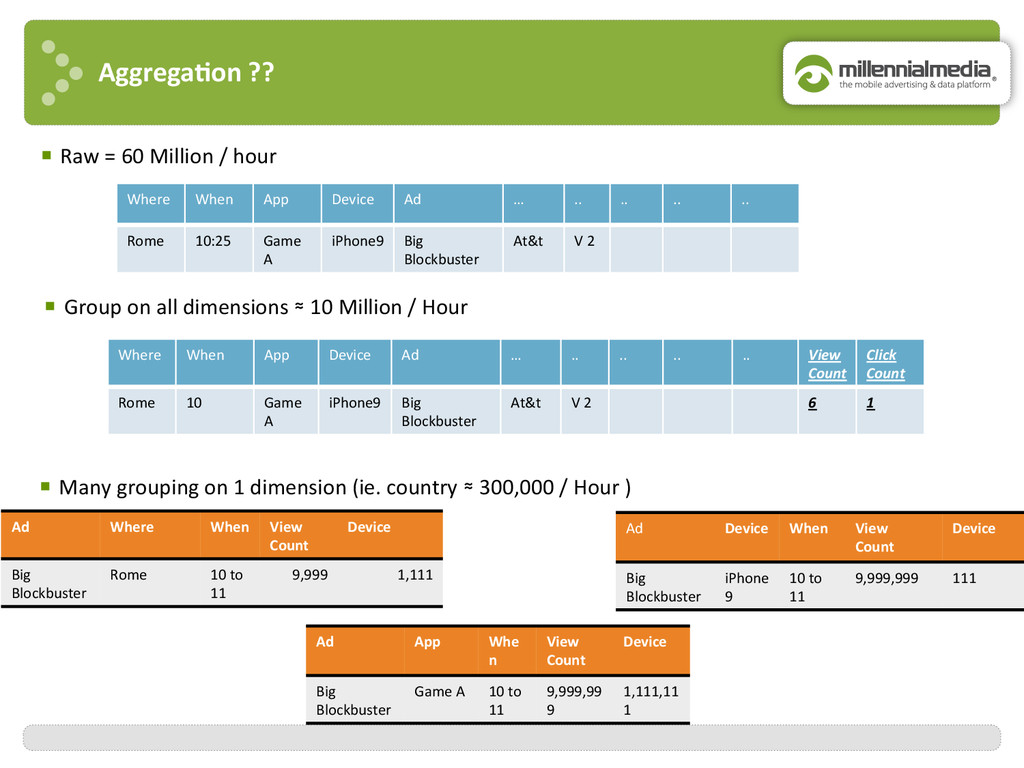
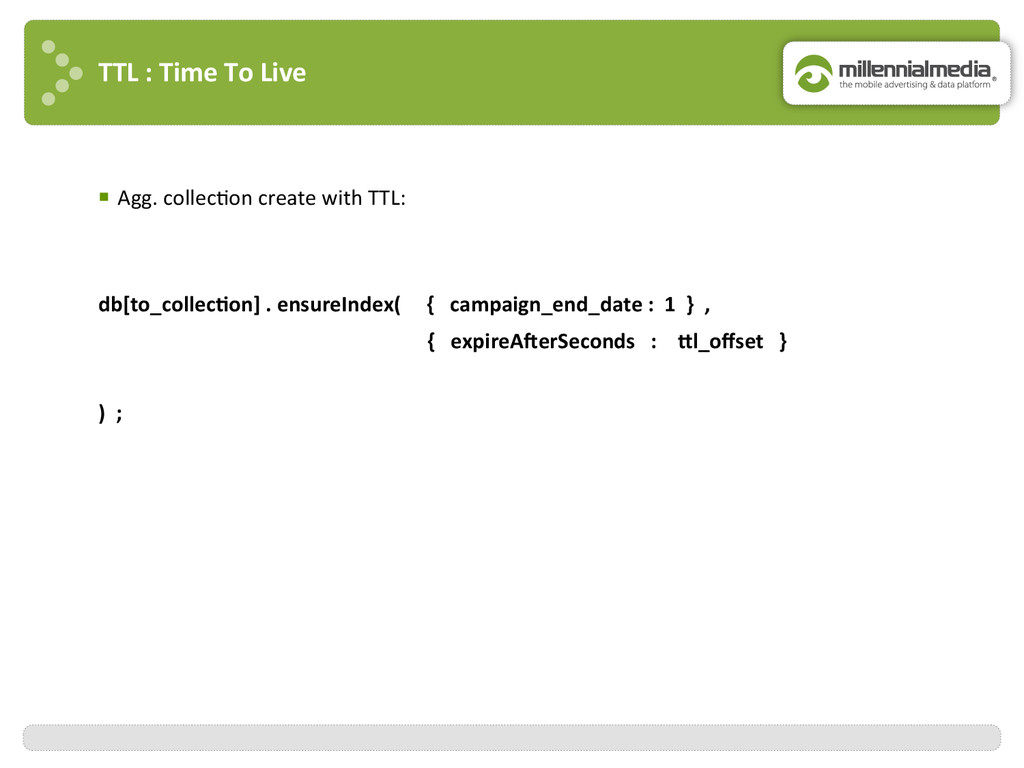
month : 12 , day : 01 , campaign : ABC } { year : 2013 , month : 12 , day : 01 , campaign : ABC } { year : 2013 , month : 12 , day : 02 , campaign : ABC } { year : 2013 , month : 12 , day : 01 , campaign : XYZ } { year : 2013 , month : 11 , day : 30 , campaign : XYZ } { year : 2013 , month : 12 , day : 02 , campaign : ABC } { year : 2013 , month : 12 , day : 01 , campaign : XYZ } { _id : ABC , count : 2 } { _id : XYZ , count : 1 } db . agg_campaigns_day . aggregate ( $match { month : 12 } , $group { _id : “$campaign” , count : { $sum : 1 } } ) ; $match $group
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
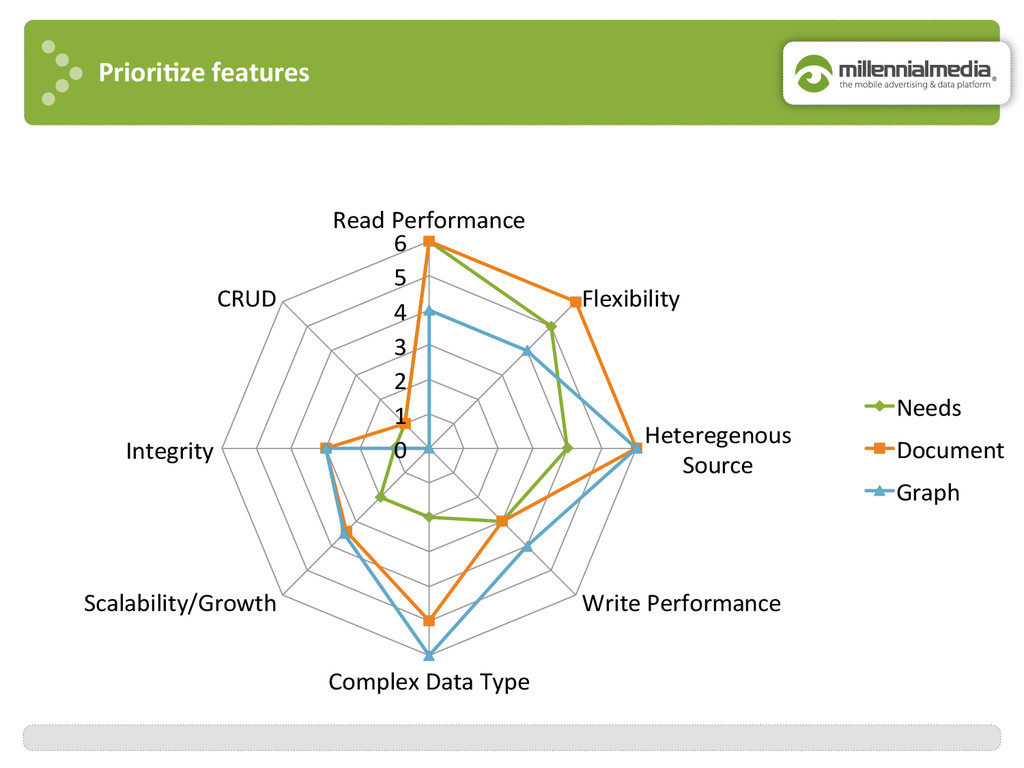{kind=link}
{kind=link}
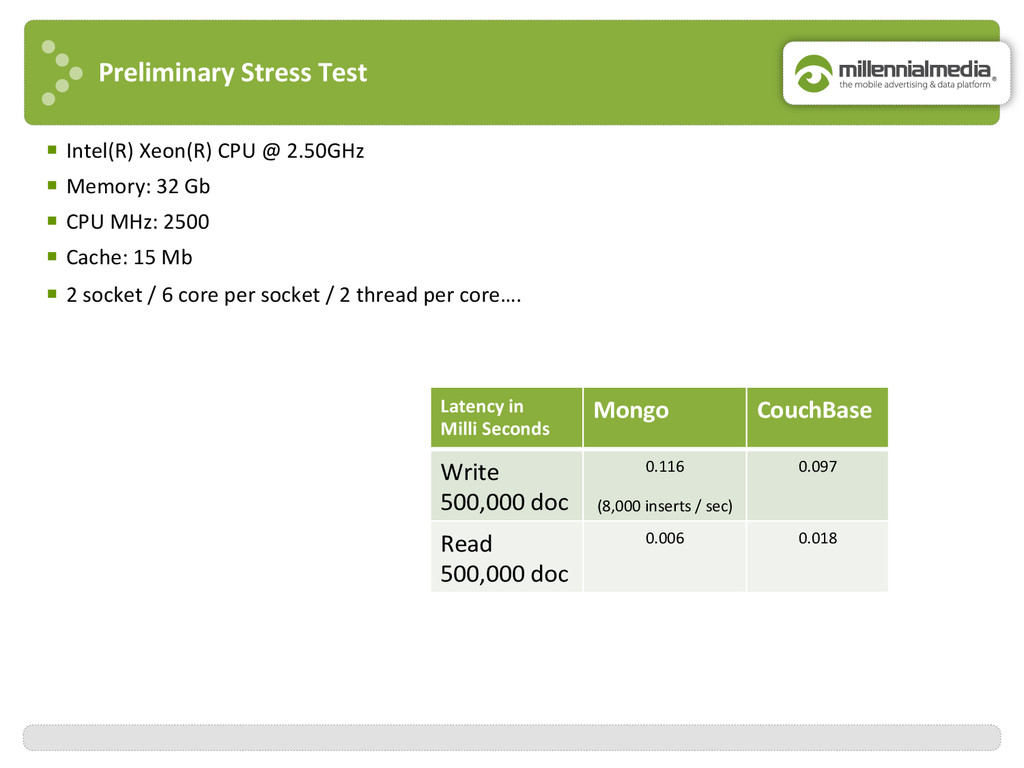{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
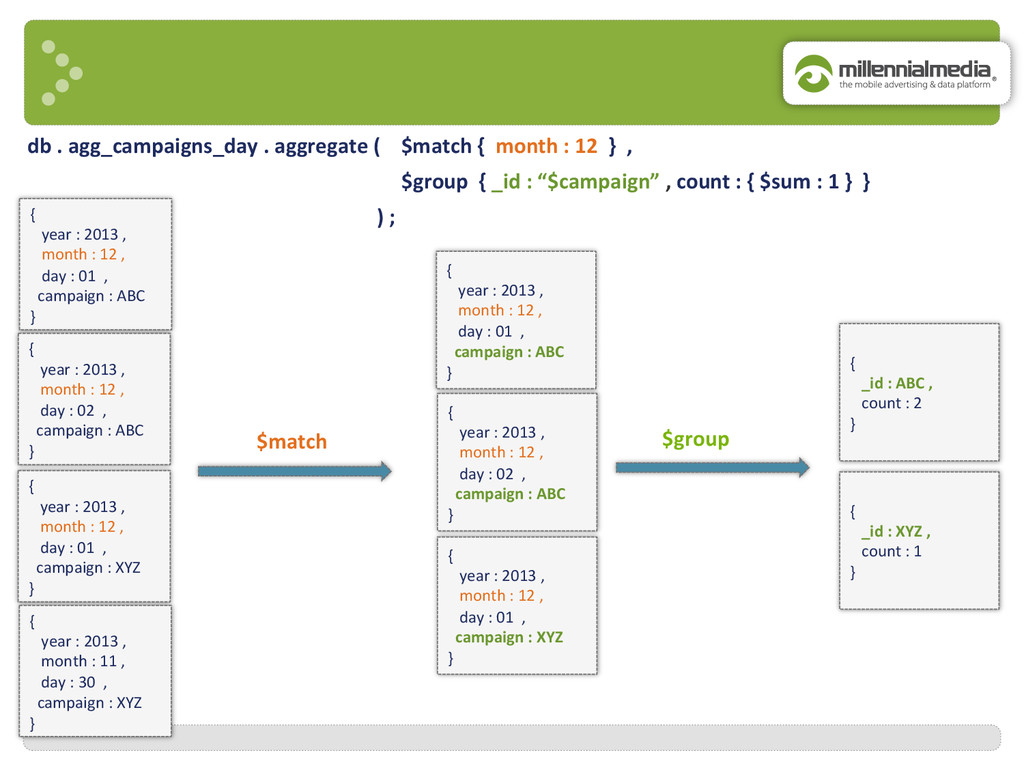{kind=link}
{kind=link}
{kind=link}
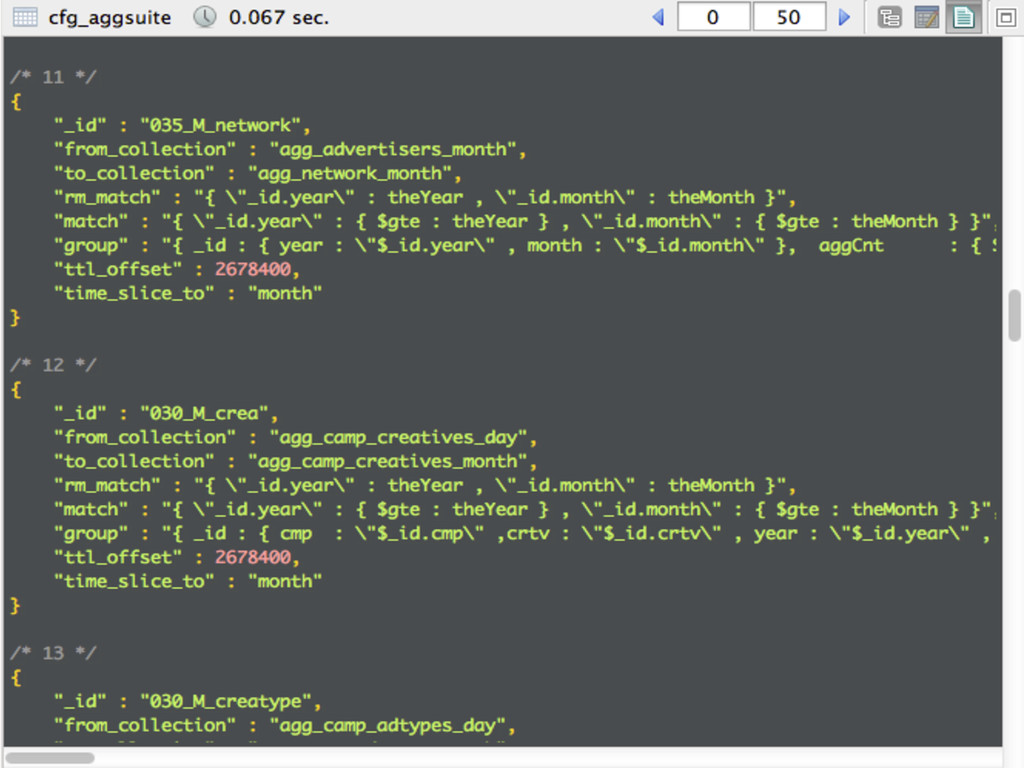{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you Bertrand Dolimier DataBase Architect [email protected]](https://files.speakerdeck.com/presentations/78a583007d63013181db7a39b831a766/slide_34.jpg){kind=link}
{kind=link}