Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
GPU上でのNLP向け深層学習の実装について
Search
Yuya Unno
November 11, 2015
Technology
12
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
GPU上でのNLP向け深層学習の実装について
Yuya Unno
November 11, 2015
More Decks by Yuya Unno
See All by Yuya Unno
深層学習で切り拓くパーソナルロボットの未来 @東京大学 先端技術セミナー 工学最前線
unnonouno
0
29
深層学習時代の自然言語処理ビジネス @DLLAB 言語・音声ナイト
unnonouno
0
53
ベンチャー企業で言葉を扱うロボットの研究開発をする @東京大学 電子情報学特論I
unnonouno
0
50
PFNにおけるセミナー活動 @NLP2018 言語処理研究者・技術者の育成と未来への連携WS
unnonouno
0
20
進化するChainer @JSAI2017
unnonouno
0
30
予測型戦略を知るための機械学習チュートリアル @BigData Conference 2017 Spring
unnonouno
0
29
深層学習フレームワーク Chainerとその進化
unnonouno
0
31
深層学習による機械とのコミュニケーション @DeNA TechCon 2017
unnonouno
0
43
最先端NLP勉強会 “Learning Language Games through Interaction” @第8回最先端NLP勉強会
unnonouno
0
24
Other Decks in Technology
See All in Technology
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
130
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
9
5.3k
ループエンジニアリングでE2Eテストを実践
noriyukitakei
0
340
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
2.5k
AIを駆使した OSS脆弱性調査のすゝめ
saku0512
0
100
GuardrailからGovernanceへ~AIエージェント運用の次の課題~
sbspsy
1
260
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
510
デジタル・デザイン:次の50年を描く「進化する青写真」
y150saya
0
850
依頼文化をやめる日 EM視点で語るPlatform EngineeringとInclusive SRE / Discussing Platform Engineering and Inclusive SRE from an EM's Perspective
shin1988
4
5.1k
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
440
誤解だらけの開発生産性 / Myths and Misconceptions about Developer Productivity
i35_267
1
110
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
180
Featured
See All Featured
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Code Reviewing Like a Champion
maltzj
528
40k
GraphQLとの向き合い方2022年版
quramy
50
15k
30 Presentation Tips
portentint
PRO
1
350
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.4k
Technical Leadership for Architectural Decision Making
baasie
3
440
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Skip the Path - Find Your Career Trail
mkilby
1
160
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
340
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
330
Transcript
GPU上でのNLP向け深層学習 の実装について (株)Preferred Infrastructure 海野 裕也
概要 l データごとに構造の異異なる⾃自然⾔言語処理理の様な 分野で、効率率率的な学習をするにはどうすればよ いか? l 論論⽂文ベースで幾つかの⼯工夫を紹介 2
確率率率的勾配降降下法 until converge: for x, y in trianing data: grad
= calc_grad(x, y) update(w, grad) 3 こちらの並列列化は限度度がある こちらの並列列度度を上げる
ミニバッチ並列列化 until converge: for {x, y} in trianing data: grad
= calc_grad({x, y}) update(w, grad) 4 ⼀一度度にたくさん計算する 並列列に計算できる
ミニバッチの勾配計算の例例(SVM) L hinge (yxTw) l W ∈ RD l x
∈ RD l y ∈ {-1, 1} l L hinge : R à R 5 ∑ L hinge (y⦿(xTw)) l W ∈ RD l x ∈ R{B, D} l y ∈ {-1, 1}B l L hinge : RB à RB Bはミニバッチサイズ ⾏行行列列計算ライブラリに並列列化を押し込む
⾔言語処理理でのミニバッチ並列列化の問題 l = 0 for x, y in sentence: l
= l + dot(softmax(dot(W, h)), y) c, h = LSTM(c, h, x) 6 ループ回数がデータ依存
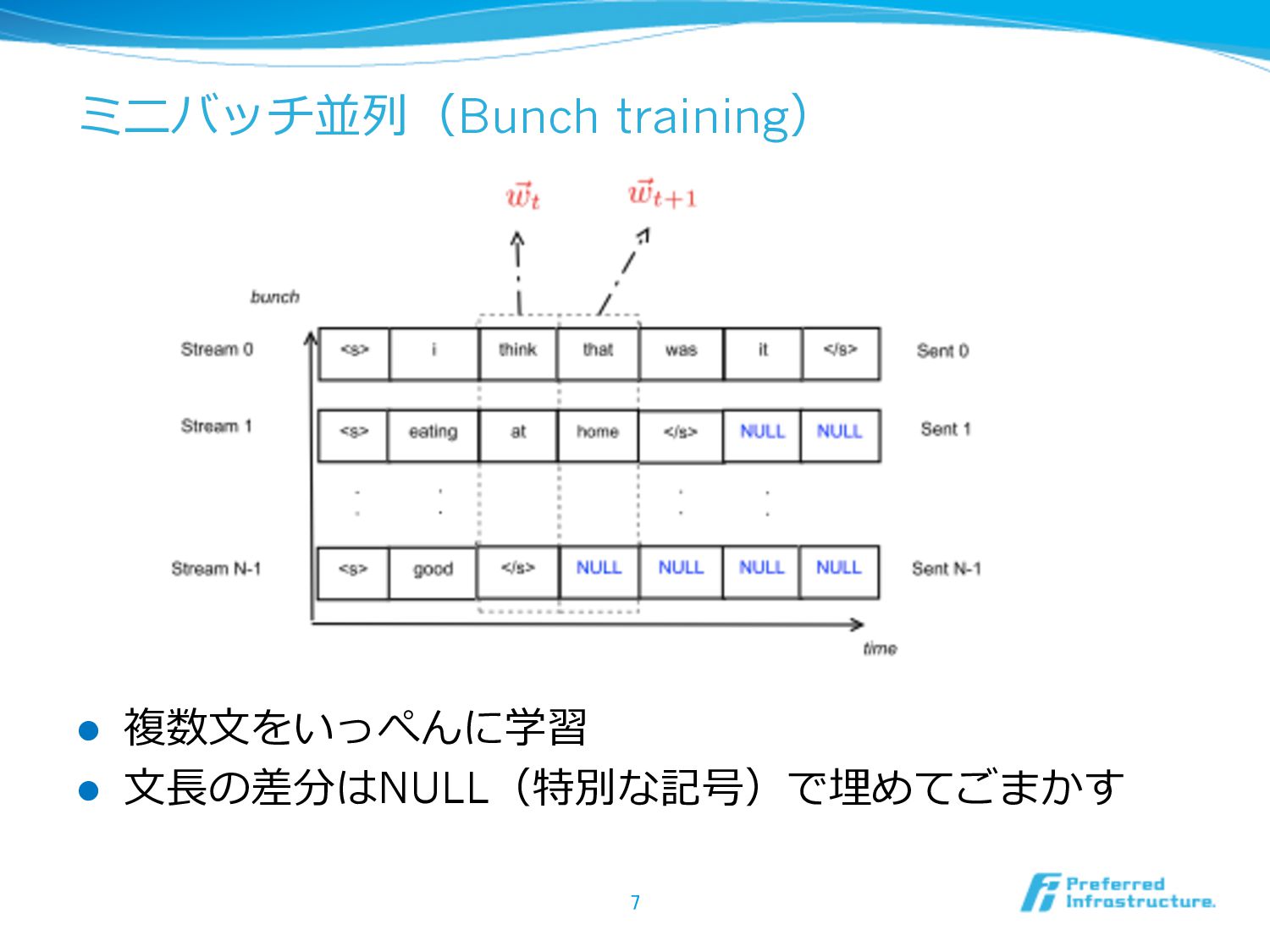
ミニバッチ並列列(Bunch training) l 複数⽂文をいっぺんに学習 l ⽂文⻑⾧長の差分はNULL(特別な記号)で埋めてごまかす 7
NULL埋めによる無駄 8 l ⽂文⻑⾧長はガンマ分布に従うとして[古橋12]、複数サンプリ ングした中で最⼤大⻑⾧長に合わせた時の計算効率率率をプロット 0 0.2 0.4 0.6 0.8
1 1.2 1 2 4 8 16 32 64 128 256
Sentence splicing [Chen+14] l NULLで埋めずに、次々に⽂文を処理理する l 実装は単純ではない気がするが 9
Splicingの効果 l Splicingしないと、50並列列程度度で性能は頭打ち 10
Pipeline [Chen+15] l 層ごとにGPUが担当して、層が深くなるごとに別GPUが 計算を⾏行行う 11
短いチャンクに切切る[Doetsch+14] l 単に短いチャンクに切切って並列列度度を上げる l NULLの量量も減る l 本当に⻑⾧長い依存は学習できなくなる 12
計算グラフを解析 [Hwang+15] l 計算グラフを強連結成分分解 l Recurrentの部分は1つの強連結成分に押し込める l 各強連結成分ごとに並列列計算する 13
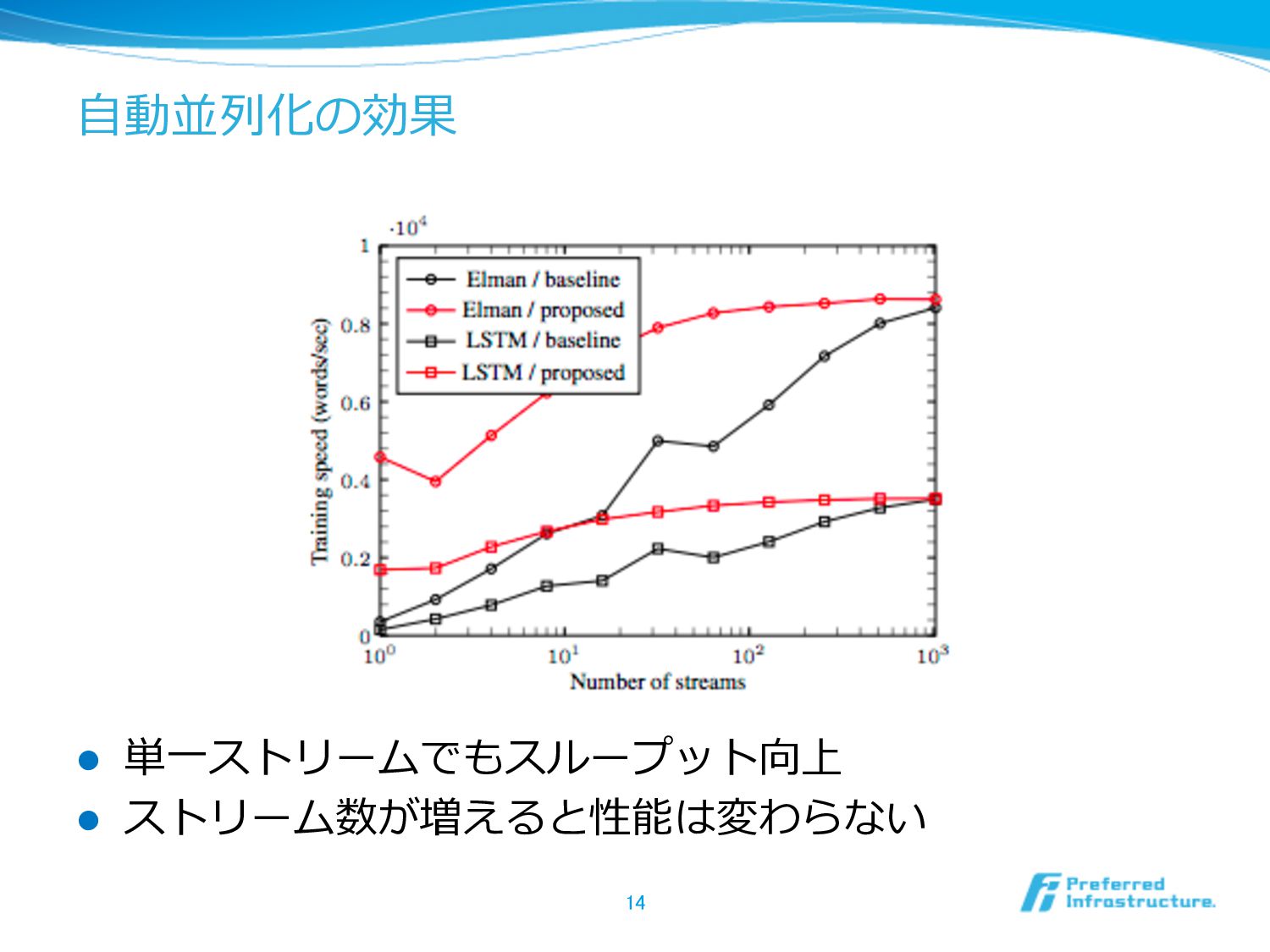
⾃自動並列列化の効果 l 単⼀一ストリームでもスループット向上 l ストリーム数が増えると性能は変わらない 14
おまけ:Bucketing l 予め幾つかの⽂文⻑⾧長⽤用のネットワークを⽤用意して、 処理理データが収まる最⼩小のネットワークを利利⽤用 する l TensorFlowで使われている 15
並列列化の⼯工夫まとめ l ゼロ埋め l ⽂文⻑⾧長の違うデータに0を埋めて、無理理やり計算 l スプライシング l ストリームごとに次々データを流流す l
パイプライン l 層ごとに別GPUを割り当ててスループットを稼ぐ l チャンク l ⽂文を無理理やり切切って⽂文⻑⾧長の差を緩和 l グラフ解析 l 計算系列列中の独⽴立立部分を抽出して⾃自動割当 16
この辺から本題 l 今までみたのは全てシンプルなRecurrentだった ので、基本的に⽂文⻑⾧長(EOSのタイミング)しか 違いがない l より複雑なネットワークの並列列処理理には更更に⼯工 夫が必要 l Encoder-decoderモデル
l Recursive neural network l Attentionモデル系 l Memory networks系 17
並列列化のレベル l GPUデバイス内 l SIMD, メモリ, スレッド, カーネル l メモリ帯域:
~1TB/sec l GPUデバイス間(マルチGPU) l PCI-ex (~100GB/sec) l マシン間 l InfiniBand (~50GB/sec), Ethernet (~1GB/sec) 18
バッチ vs オンライン l ミニバッチサイズを増やしても実時間での精度度 向上が早くなってないように感じる l バッチ学習とオンライン学習と同じ議論論 l 更更新頻度度をあげようとすると、CPUの⽅方が有利利
な可能性は無いか? 19
実装レベルで⽐比較
⽬目についた実装を調査 l Embedding l Recurrent l Recursive 21
Embedding l word2vec l CPU実装、スレッドで並列列化、ロックしないで更更新(ミニバッ チにはしていない)、勾配を陽に持たない l gensim l Python実装、Cythonで⾼高速化
l Polyglot2 l Python実装、Cythonとblasで⾼高速化 l Chainer (word2vec example) l Python実装、cupyでGPUサポート、ミニバッチ 22
Recurrent l theano-rnn l Python実装、theanoでGPU、batchsizeでchunkを作る l Passage l Python実装、theanoでGPU、iteratorでミニバッチを作り、 余ったところはゼロ埋め
l DL4J (rnn example) l Java実装、ND4JでGPU、iteratorでミニバッチを作り、 batchsizeでchunkを作る l Chainer (ptb example) l Python実装、CuPyでGPU、batchsizeでchunkを作る 23
Recursive l Stanford core nlp l Java実装、再帰関数で実装、ミニバッチしていない l deep-recursive l
C++実装、Eigen利利⽤用、データ単位で処理理(ミニバッチしていな い) l RecursiveNeuralTensorNetwork l Python実装、theano利利⽤用、Treeをstack操作に変換してから学 習しているがミニバッチしていなさそう l Chainer (sentiment example) l Python実装、CuPyでGPU、再帰関数で実装、ミニバッチして いない 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![NULL埋めによる無駄 8 l ⽂文⻑⾧長はガンマ分布に従うとして[古橋12]、複数サンプリ ングした中で最⼤大⻑⾧長に合わせた時の計算効率率率をプロット 0 0.2 0.4 0.6 0.8](https://files.speakerdeck.com/presentations/bd98adee93134e49844956269cd7ac37/slide_7.jpg){kind=link}
![Sentence splicing [Chen+14] l NULLで埋めずに、次々に⽂文を処理理する l 実装は単純ではない気がするが 9](https://files.speakerdeck.com/presentations/bd98adee93134e49844956269cd7ac37/slide_8.jpg){kind=link}
{kind=link}
![Pipeline [Chen+15] l 層ごとにGPUが担当して、層が深くなるごとに別GPUが 計算を⾏行行う 11](https://files.speakerdeck.com/presentations/bd98adee93134e49844956269cd7ac37/slide_10.jpg){kind=link}
![短いチャンクに切切る[Doetsch+14] l 単に短いチャンクに切切って並列列度度を上げる l NULLの量量も減る l 本当に⻑⾧長い依存は学習できなくなる 12](https://files.speakerdeck.com/presentations/bd98adee93134e49844956269cd7ac37/slide_11.jpg){kind=link}
![計算グラフを解析 [Hwang+15] l 計算グラフを強連結成分分解 l Recurrentの部分は1つの強連結成分に押し込める l 各強連結成分ごとに並列列計算する 13](https://files.speakerdeck.com/presentations/bd98adee93134e49844956269cd7ac37/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}