Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Jubatusにおける ⼤大規模分散オンライン機械学習 @先端⾦金金融テクノロジー研究会
Search
Yuya Unno
June 01, 2012
Technology
18
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Jubatusにおける ⼤大規模分散オンライン機械学習 @先端⾦金金融テクノロジー研究会
Yuya Unno
June 01, 2012
More Decks by Yuya Unno
See All by Yuya Unno
深層学習で切り拓くパーソナルロボットの未来 @東京大学 先端技術セミナー 工学最前線
unnonouno
0
29
深層学習時代の自然言語処理ビジネス @DLLAB 言語・音声ナイト
unnonouno
0
53
ベンチャー企業で言葉を扱うロボットの研究開発をする @東京大学 電子情報学特論I
unnonouno
0
50
PFNにおけるセミナー活動 @NLP2018 言語処理研究者・技術者の育成と未来への連携WS
unnonouno
0
20
進化するChainer @JSAI2017
unnonouno
0
30
予測型戦略を知るための機械学習チュートリアル @BigData Conference 2017 Spring
unnonouno
0
29
深層学習フレームワーク Chainerとその進化
unnonouno
0
31
深層学習による機械とのコミュニケーション @DeNA TechCon 2017
unnonouno
0
43
最先端NLP勉強会 “Learning Language Games through Interaction” @第8回最先端NLP勉強会
unnonouno
0
25
Other Decks in Technology
See All in Technology
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
0
120
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
2
180
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
180
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
220
Road to SRE NEXTの今までとこれから
hiroyaonoe
0
310
AICoEでAIネイティブ組織への進化
yukiogawa
0
170
世界、断片、モデル。そして理解
ardbeg1958
1
110
AI Driven AI Governance
pict3
0
380
CIで使うClaude
iwatatomoya
0
250
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
150
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
2
3.5k
技術イベント終了後、運営の 事後タスクは丁寧に (心がけています)/ #tamagawadev
nishiuma
1
100
Featured
See All Featured
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Everyday Curiosity
cassininazir
0
250
Un-Boring Meetings
codingconduct
0
340
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
870
The Pragmatic Product Professional
lauravandoore
37
7.4k
Building AI with AI
inesmontani
PRO
1
1.1k
WCS-LA-2024
lcolladotor
0
680
Transcript
Jubatusにおける ⼤大規模分散オンライン機械学習 海野 裕也 (株) Preferred Infrastructure 研究開発部⾨門 <
[email protected]
> 2012/6/1先端⾦金金融テクノロジー研究会
株式会社 Preferred Infrastructure l 略略称 PFI l 設⽴立立 2006年年3⽉月 l 代表者 ⻄西川 徹 l 社員数
26名(2012/4現在) l 所在地 〒113-‐‑‒0033 東京都⽂文京区本郷2-‐‑‒40-‐‑‒1 l URL http://preferred.jp/ l 事業概要 検索索/推薦(レコメンデーション)分野での製品開発 販売、サービス提供および技術提供 ⼤大規模分散コンピューティング分野での技術提供 2 会社概要
ミッション:最先端の技術を最短路路で実⽤用化 テクノロジーとサービス・プロダクトとの間のギャップを埋め テクノロジーが持つポテンシャルを最⼤大限に引き出すこと 研究ベースの技術が想定しているものと実世界には⼤大きな壁が存在する l アカデミックの第⼀一線で研究しているリサーチャーと、アカデミックな研究を理理解し、 実装・実⽤用化できるエンジニアを集合させる l 世の中に必要とされている技術の中でも、特に難しい課題を選び抜き、それに対する 解を提供していくこと
3 Basic Technologies Academic Researches Products Services
実績 製品導⼊入/技術提供 l メディア業界 Ø ⽇日経BP 全社横断検索索 Ø 朝⽇日新聞社 公式ニュースサイトasahi.com Ø 株式会社インプレスビジネスメディア Ø
⽇日本放送協会 NHKニュース Ø 株式会社電通 ザッピングエンジン「XAPPY」 l EC/Webサービス業界 Ø 株式会社イプロス 製造技術データベースサイト Ø 国⽴立立情報学研究所 図書情報サービスWebcat Plus Ø 株式会社エフルート モバイル検索索サービス Ø 株式会社はてな ソーシャルブックマークサービス 4
アジェンダ l ビッグデータ分析の現状 l 機械学習の基礎 l 特徴抽出と特徴分析 l 利利⽤用事例例 l
Jubatus l オンライン分散解析基盤 l まとめ 5
ビッグデータ分析の現状 6
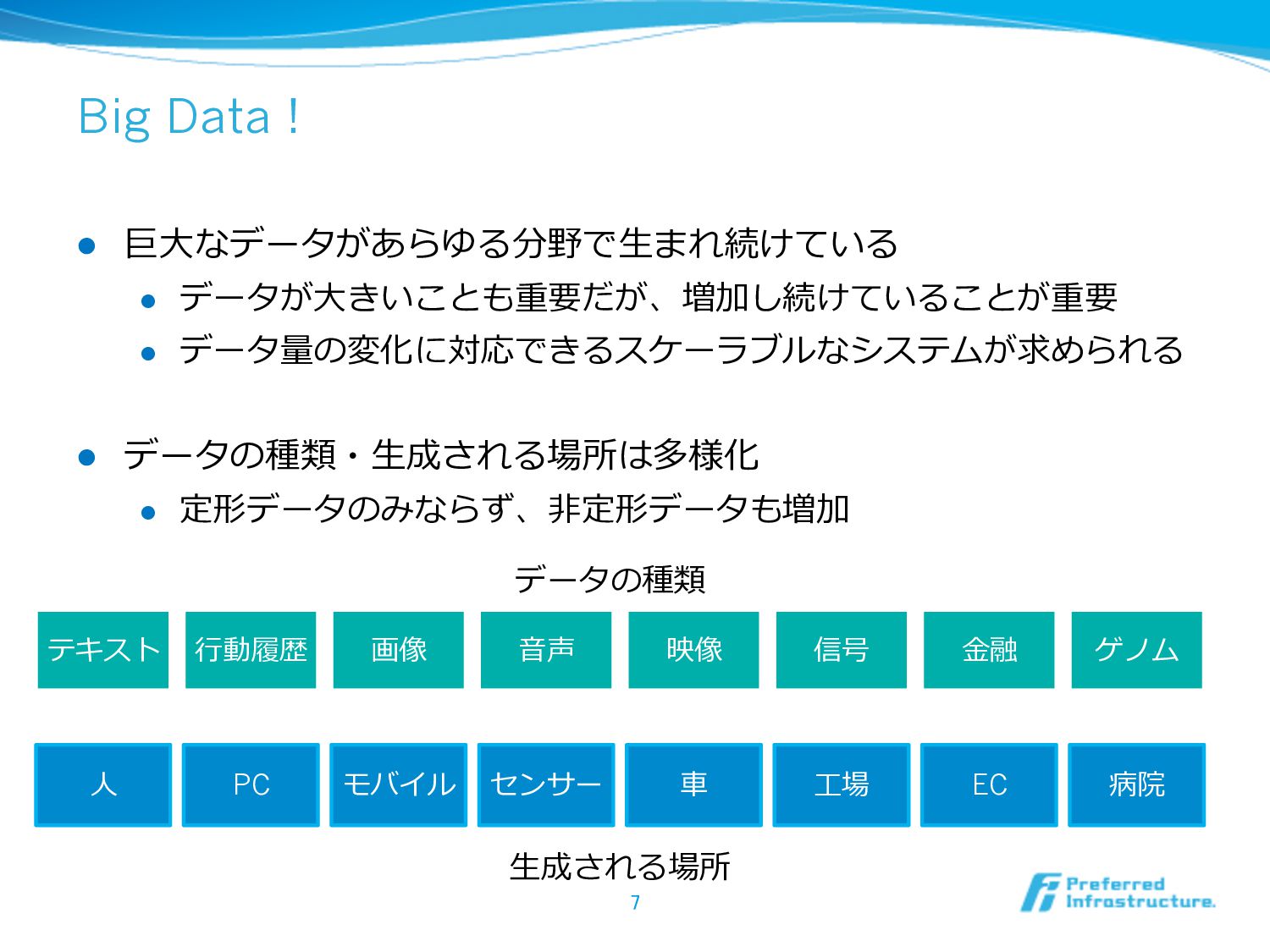
Big Data ! l 巨⼤大なデータがあらゆる分野で⽣生まれ続けている l データが⼤大きいことも重要だが、増加し続けていることが重要 l データ量量の変化に対応できるスケーラブルなシステムが求められる l
データの種類・⽣生成される場所は多様化 l 定形データのみならず、⾮非定形データも増加 7 テキスト ⾏行行動履履歴 画像 ⾳音声 映像 信号 ⾦金金融 ゲノム ⼈人 PC モバイル センサー ⾞車車 ⼯工場 EC 病院 ⽣生成される場所 データの種類
ビッグデータ解析の現状 l ウェブから他の産業領領域へ l ウェブ領領域では成功事例例多数(Google, Amazon, Facebook) l ウェブ以外の分野でのビッグデータ活⽤用の可能性は未知数 l
⾦金金融・保険・医療療・⼩小売・運輸・製造・インフラ l 新しい技術・戦略略・ビジネス構築が必要になっていく l 分析は量量のみならず多様化・質・速さへ l データの種類や性質は様々であり分野の専⾨門的知識識も必要 l 単なる集計のみならず予測・発⾒見見・分類など深い分析が必要 l いくつかの分析ではリアルタイム処理理が鍵となる →即時処理理、即時対応 情報の在庫を作らない 8
データ活⽤用の3STEP STEP 1. ⼤大量量のデータを捨てずに蓄積できるようになってきた STEP 2. データを分析することで、現状の把握、理理解ができる STEP 3. 状況を理理解し、現状の改善、予測ができる
l 世の中は、Step1 から Step2 を踏み出した段階 9 9 蓄積 理理解 予測 より深い解析へ 本の購買履履歴を 全て記録できる ようになった! この本が実際に 売れているのは 意外にも30代の 男性達だ! この⼈人は30代 男性なので、こ の本を買うので はないか?
ビッグデータ解析の現状と今後の課題 l ⼤大規模データを扱えるインフラ l 強⼒力力な分析ツール l データ分析のための継続的なノウハウの蓄積 l データ分析を⾏行行える⼈人材育成 l
データ分析結果を産業を超えて共有できる仕組み作り l 適切切なデータを取得できるようにする⼯工夫 l 取っていたデータの分析ではなく、 分析するためにデータを狙って取得する試みが必要 10
機械学習の基礎
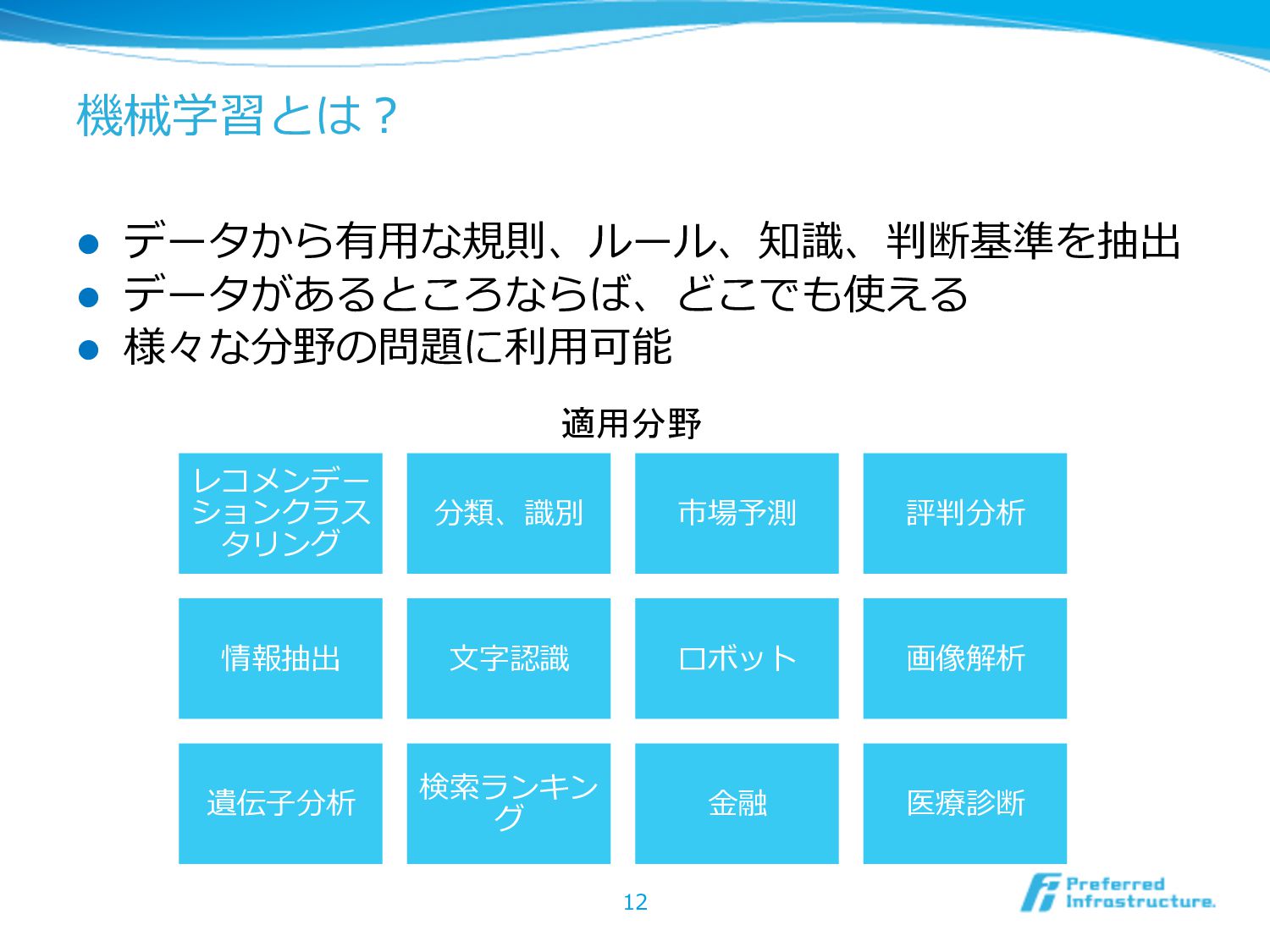
機械学習とは? l データから有⽤用な規則、ルール、知識識、判断基準を抽出 l データがあるところならば、どこでも使える l 様々な分野の問題に利利⽤用可能 12 レコメンデー ションクラス
タリング 分類、識識別 市場予測 評判分析 情報抽出 ⽂文字認識識 ロボット 画像解析 遺伝⼦子分析 検索索ランキン グ ⾦金金融 医療療診断 適用分野
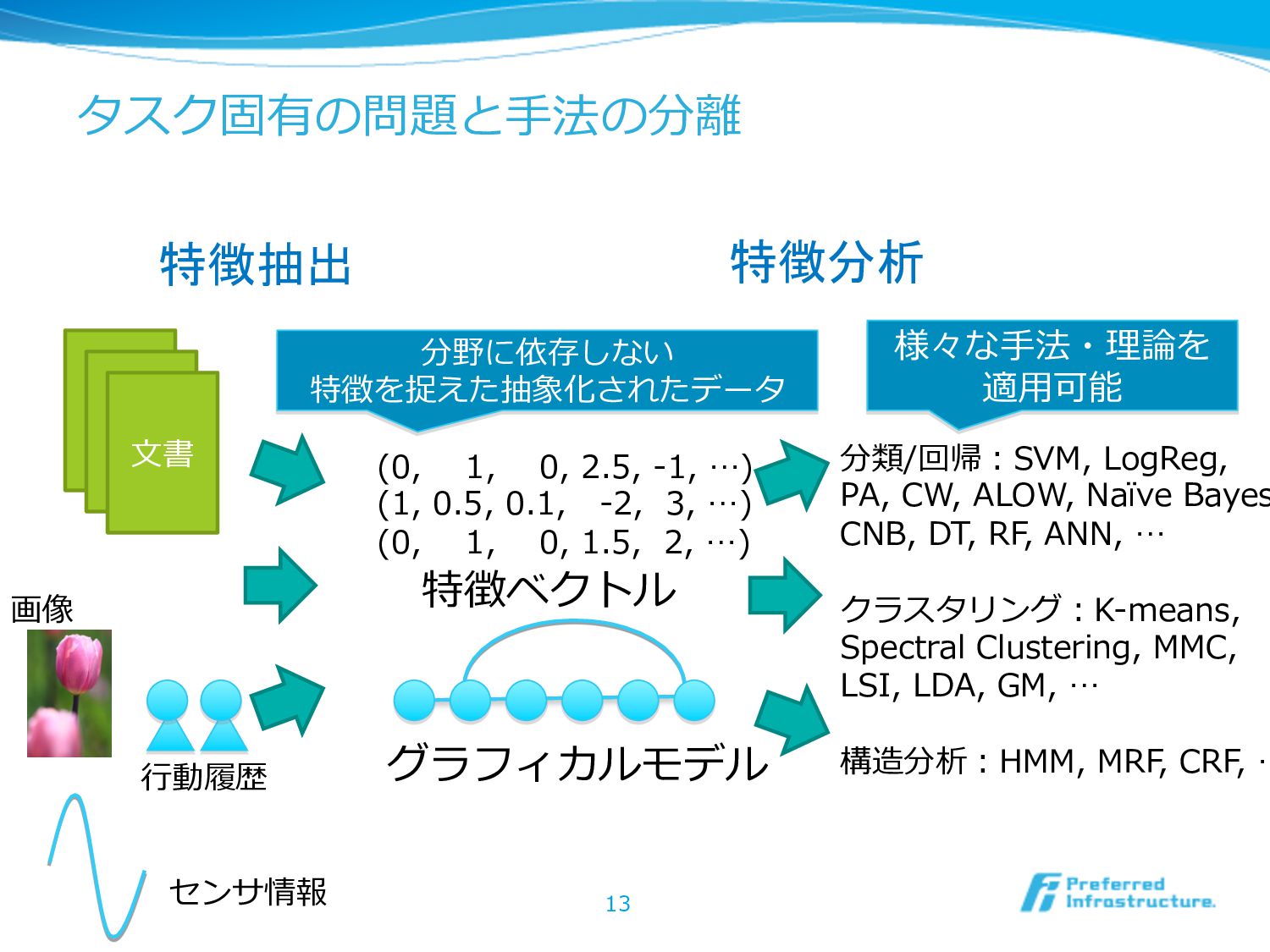
タスク固有の問題と⼿手法の分離離 13 ⽂文書 (0, 1, 0, 2.5, -‐‑‒1, …) (1,
0.5, 0.1, -‐‑‒2, 3, …) (0, 1, 0, 1.5, 2, …) 特徴ベクトル グラフィカルモデル 分類/回帰:SVM, LogReg, PA, CW, ALOW, Naïve Bayes CNB, DT, RF, ANN, … クラスタリング:K-‐‑‒means, Spectral Clustering, MMC, LSI, LDA, GM, … 構造分析:HMM, MRF, CRF, … 画像 センサ情報 ⾏行行動履履歴 分野に依存しない 特徴を捉えた抽象化されたデータ 様々な⼿手法・理理論論を 適⽤用可能 特徴抽出 特徴分析
タスク固有の問題と⼿手法の分離離(続) l 特徴抽出と特徴分析を分離離することが重要 l データの種類、ドメイン、利利⽤用⽬目的に依存せず、様々な分析を利利 ⽤用可能なしくみを作ることができる l 利利点 l システム開発・専⾨門家教育のコストを⼤大きく下げることができる
l 特徴抽出では各問題ドメインに専念念 l 特徴分析では各分析⼿手法に専念念 14
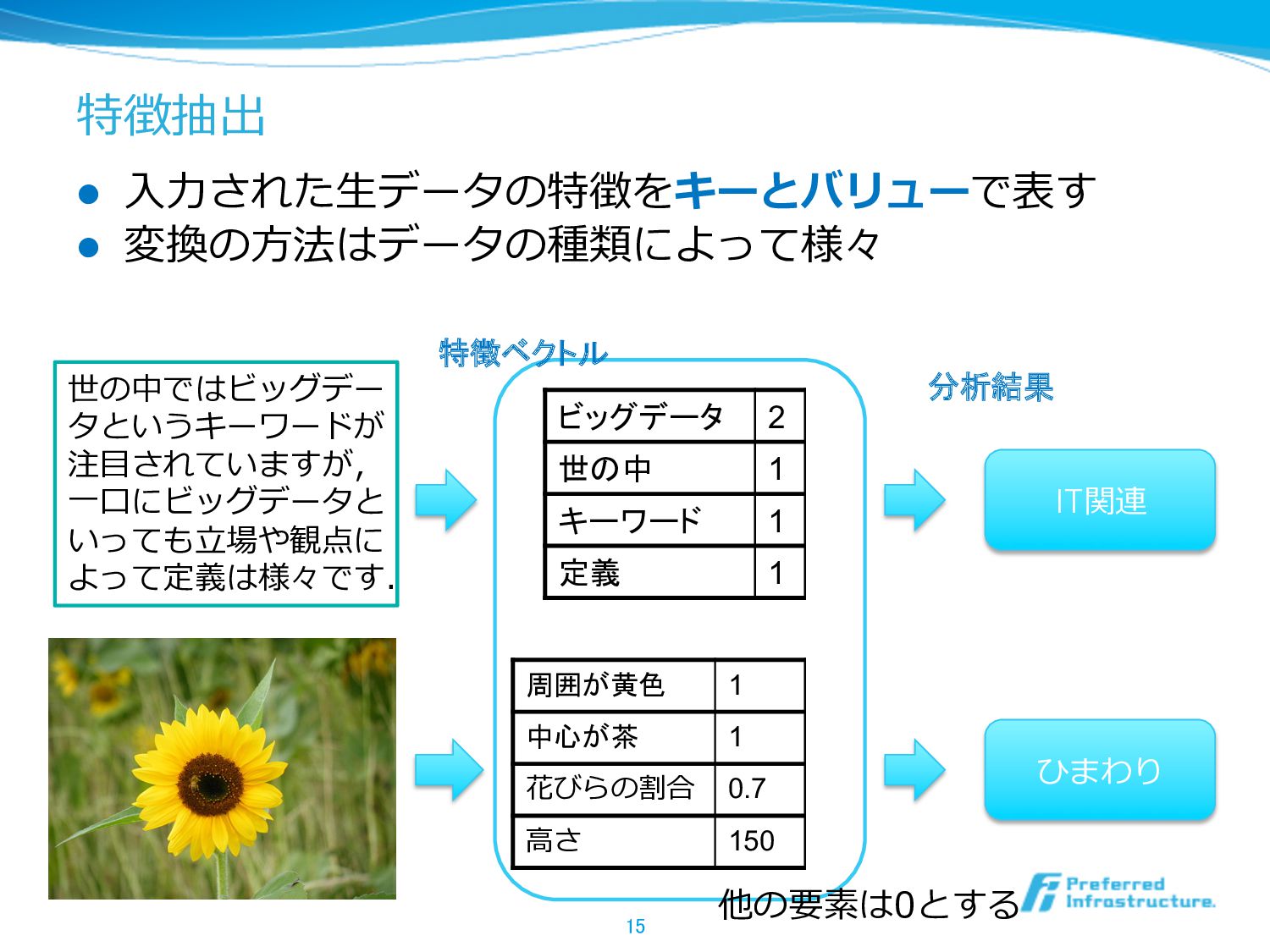
特徴抽出 l ⼊入⼒力力された⽣生データの特徴をキーとバリューで表す l 変換の⽅方法はデータの種類によって様々 15 周囲が黄色 1 中心が茶 1
花びらの割合 0.7 ⾼高さ 150 世の中ではビッグデー タというキーワードが 注⽬目されていますが, ⼀一⼝口にビッグデータと いっても⽴立立場や観点に よって定義は様々です. 他の要素は0とする ビッグデータ 2 世の中 1 キーワード 1 定義 1 IT関連 ひまわり 特徴ベクトル 分析結果
特徴分析 l 予測 l ⼊入⼒力力xから出⼒力力yを推定(分類:yがカテゴリ値 回帰:yが連続値) l 近傍探索索 l 似たデータはこれまで無かったか,それらはどういうデータか
l 統計分析 l 平均・最⼤大/最⼩小・エントロピー・モーメント・相関 l 外れ値、コンセプトドリフト分析 l これまでのデータ傾向から外れた値はあるか、傾向は変わってるか l クラスタリング l 似たデータ同⼠士を纏め上げ、グループ化する l 原因分析 l 複数の特徴の中で最も現象を説明し得る原因は何か? 16
特徴分析(続) l 1つの分析⼿手法だけで⽬目標を達成することは少なく、複数の分析 を組合せることが重要となる l 次にいくつか具体的な利利⽤用シーン毎に分析パターンを紹介する 17
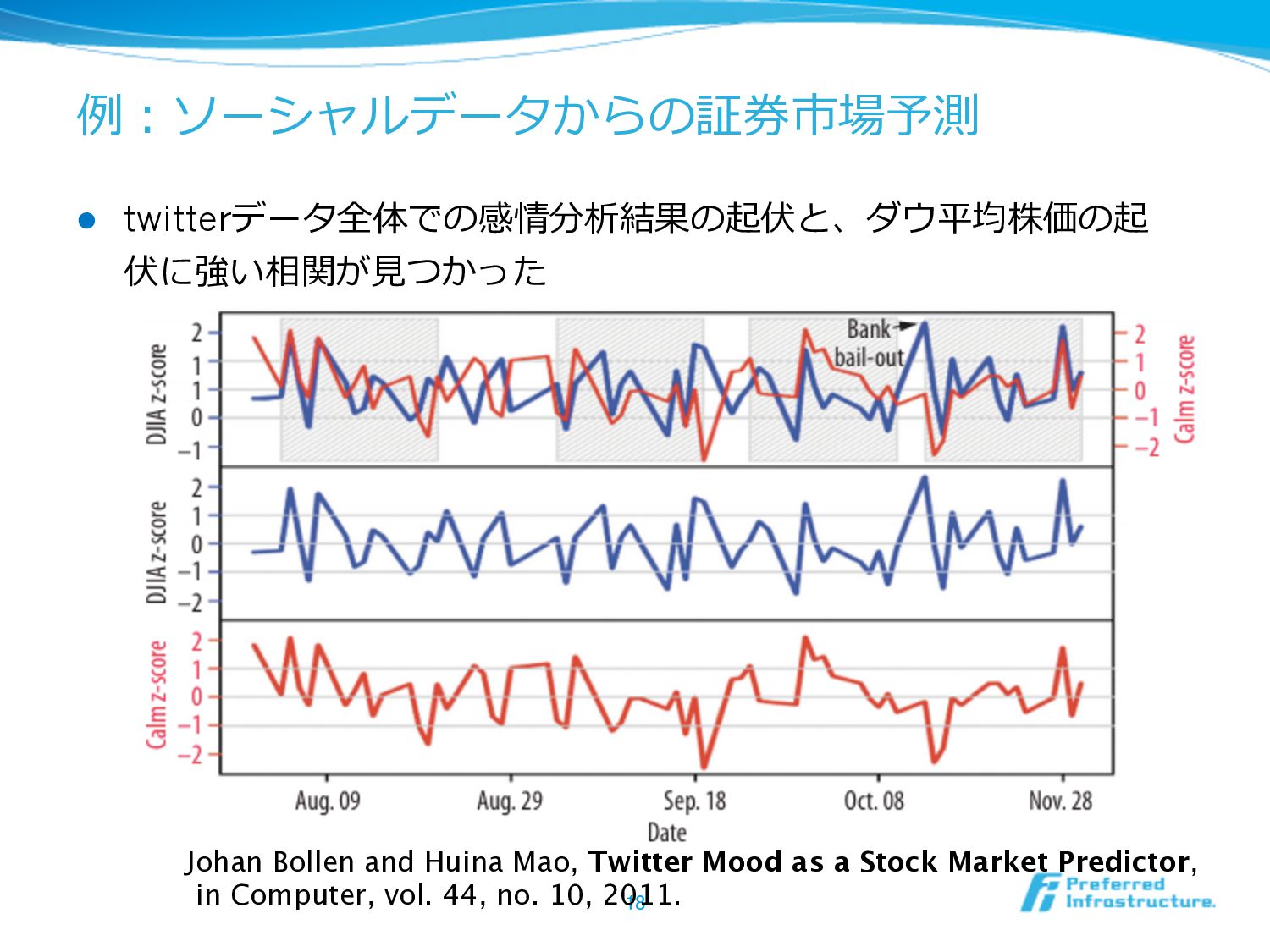
例例:ソーシャルデータからの証券市場予測 l twitterデータ全体での感情分析結果の起伏と、ダウ平均株価の起 伏に強い相関が⾒見見つかった 18 Johan Bollen and Huina Mao,
Twitter Mood as a Stock Market Predictor, in Computer, vol. 44, no. 10, 2011.
例例1:ECサイトの分析 19 l ユーザー分析 l 属性予測 l 性別、年年齢、家族構成、地域、嗜好、過去の⾏行行動 l ⾏行行動予測
l 商品を購⼊入するか、良良い評判を作るか、継続的に会社と関わるか l ユーザーへの推薦 l ユーザーの近傍探索索を⾏行行い、似たユーザーを調べどのような商品 を購⼊入するかどうかを調べ、推薦する l ユーザーへのサポート l 外れ値、コンセプトドリフトを調べ、何か問題が起きているか、 ⾏行行動パターンが変わってきているのかを分析する
例例2:ネットワーク管理理 l 電⼒力力消費量量の予測 l パケットデータなどと、実際の測定値の関係を分析し、パケッ トデータのみから電⼒力力消費量量を予測できるようにする l ネットワーク保守・セキュリティ l 通信パターン、パケットなどから外れ値検出を⾏行行い、障害検知や
攻撃検知を⾏行行う l サーバー構成・ネットワーク構成の最適化 l 利利⽤用⽅方法が似ているサーバー・サービスをクラスタリングによっ てまとめ上げ、それらが近くなるように配置する l 原因分析 l 何か障害が発⽣生した時に、その原因が何かを膨⼤大な候補の中から いくつかに絞り込む 20
例例3:⼩小売情報分析 l 発注数の最適化 l 過去の売上数、店舗、気象、地域、ニュース、ユーザーからの反 響など様々な情報を元に最適な発注数を予測、リスク分析も⾏行行う l ⽋欠品、代替え分析 l ⽋欠品情報はデータで表されない隠れた情報.これまでの売上デー
タの傾向や似た商品での代替えが起きているかで分析を⾏行行う l この実現のため商品間の類似度度を測ったり、売上の相関を調べる l ユーザーのモデル化 l クラスタリング、分類などを利利⽤用し、ユーザーに対し、いくつか タグ付けを⾏行行いユーザー全容を把握できるようにする l 店舗のモデル化 l 複数の店舗情報を分析し、店舗毎の強い点、弱い点などを分析 21
例例4:ソーシャルモニタリング l SNSなどのデータを分析し、企業、商品、⼈人、イベントなどにつ いての⾔言及を分析し、マーケティング・製品開発などに活かす l 特徴抽出では、⾔言語処理理技術が重要となってくる l 評判分析 l ⾔言及対象に対し、肯定/否定/中⽴立立
l 客観的、主観的な記述の抽出 l 評判情報の要約 l ⾔言及対象の分析、真偽判定、評判属性毎に要約(価格、機能など) l 共参照解析なども重要に l 影響度度分析 l 発⾔言毎の影響度度分析、グラフ構造の中⼼心性分析も重要に 22
Jubatus 23
Jubatus登場の背景 l 既存システムは次の3つの⽬目標を同時に達成することが困難 l 1)リアルタイム性の確保 l 2)データを⽔水平分散処理理 l 3)深い分析 l
分散並列列処理理 (MapReduce/Hadoopなど) l スケールアウト構成による性能向上、耐障害性 l 基本的にバッチ処理理、解析結果はすぐ返ってこない l 計算モデルの⾃自由度度が⾼高い分オーバーヘッドも⼤大きい l オンライン / ストリーム処理理 (CEPなど) l 到着したデータをその場で処理理して解析し、結果を出⼒力力する l 多くは単純な処理理しか⾏行行えない 24
Jubatus 25 リアルタイム ストリーム 分散並列列 深い解析 l NTT SIC*とPreferred Infrastructureによる共同開発
l 2011年年10⽉月よりOSSで公開 http://jubat.us/ * NTT SIC: NTT研究所 サイバーコミュニケーション研究所 ソフトウェアイノベーションセンタ
特徴1: リアルタイム / ストリーム処理理 l 解析結果は、データ投⼊入後すぐ返って来る l 分類などの学習/分析も⼀一瞬で処理理 l twitterの内容を分析して分類するのは6000QPS
l 分類、統計分析、回帰、近傍探索索など様々な処理理をリアルタイム 、ストリームで処理理 l データを貯めることなく、その場で処 l 従来バッチで処理理していた様々な解析をリアルタイム・ストリー ムで同様の精度度処理理できるよう、新しく解析⼿手法を開発 26
特徴2: 分散並列列処理理 l スケールアウト:ノードを追加することで、性能向上ができる l 処理理量量に応じてシステムの⼤大きさを柔軟に変更更可能 l ⼩小さいデータから⼤大きなデータの処理理まで同じシステムで処理理 l 耐故障性も確保
l 各ノードが完全に独⽴立立な処理理なら簡単だが、それぞれが情報を蓄 積し、それらを共有して処理理するのは⼤大変 ⇒ モデルの緩やかな共有で解決(後述) 27
特徴3:深い解析 l 単純な集計、統計処理理だけではなく、分類・近傍探索索など様々な 機械学習⼿手法をサポート l ユーザーはデータを投⼊入すればこれらの分析処理理を実現できる l ⾮非定形データを扱えるように、データからの特徴抽出もサポート l 多くの機械学習ライブラリはここがサポートされていない
l 特徴抽出はプラグイン化され、今後サポート対象のデータ種類、 分野を増やしていく 28
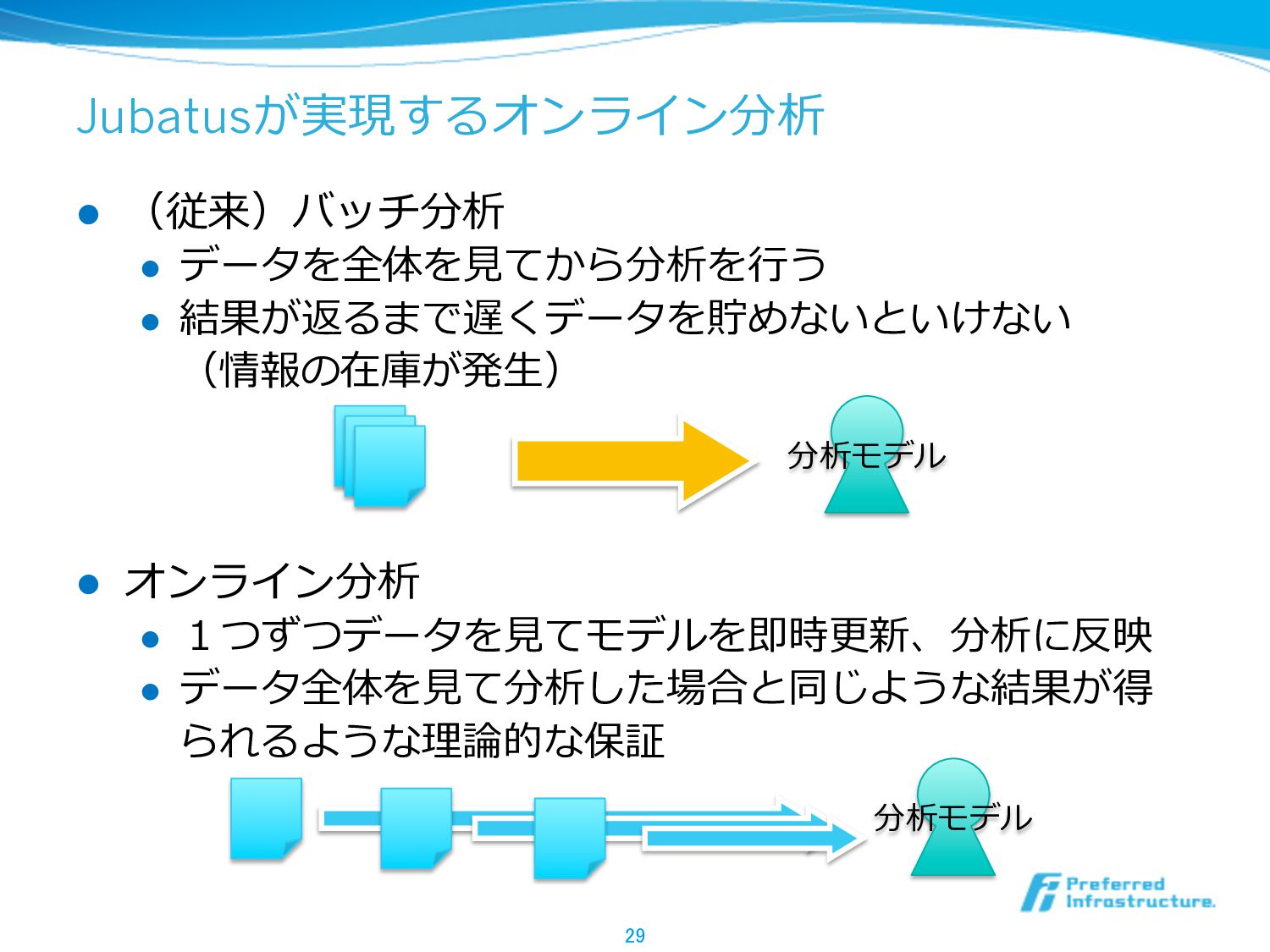
Jubatusが実現するオンライン分析 l (従来)バッチ分析 l データを全体を⾒見見てから分析を⾏行行う l 結果が返るまで遅くデータを貯めないといけない (情報の在庫が発⽣生) l オンライン分析
l 1つずつデータを⾒見見てモデルを即時更更新、分析に反映 l データ全体を⾒見見て分析した場合と同じような結果が得 られるような理理論論的な保証 29 分析モデル 分析モデル
オンライン分析の特徴 l オンライン分析は解析速度度が速い l レイテンシが⼩小さく、スループットも⼤大きい l データを貯める必要が無い l Jubatusは最新のオンライン分析⼿手法を実装 l
分類の例例 l Perceptron (1958) l Passive Aggressive (PA) (2003) l Confidence Weighted Learning (CW) (2008) l AROW (2009) l Normal HERD (NHERD) (2010) 30 近年年急激に性能 が向上
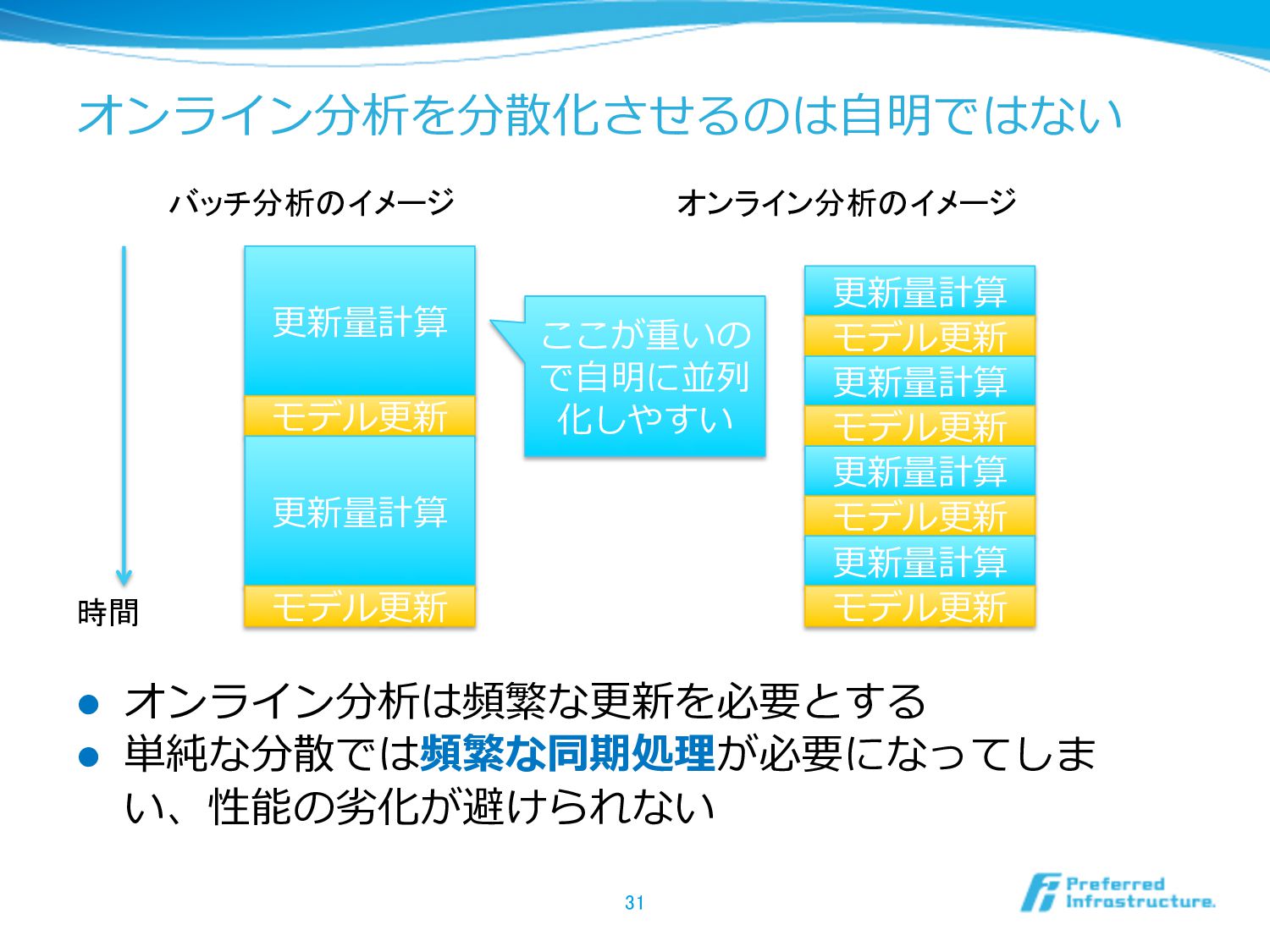
オンライン分析を分散化させるのは⾃自明ではない l オンライン分析は頻繁な更更新を必要とする l 単純な分散では頻繁な同期処理理が必要になってしま い、性能の劣劣化が避けられない 31 バッチ分析のイメージ オンライン分析のイメージ 更更新量量計算
モデル更更新 時間 更更新量量計算 モデル更更新 更更新量量計算 モデル更更新 更更新量量計算 モデル更更新 更更新量量計算 モデル更更新 更更新量量計算 モデル更更新 ここが重いの で⾃自明に並列列 化しやすい
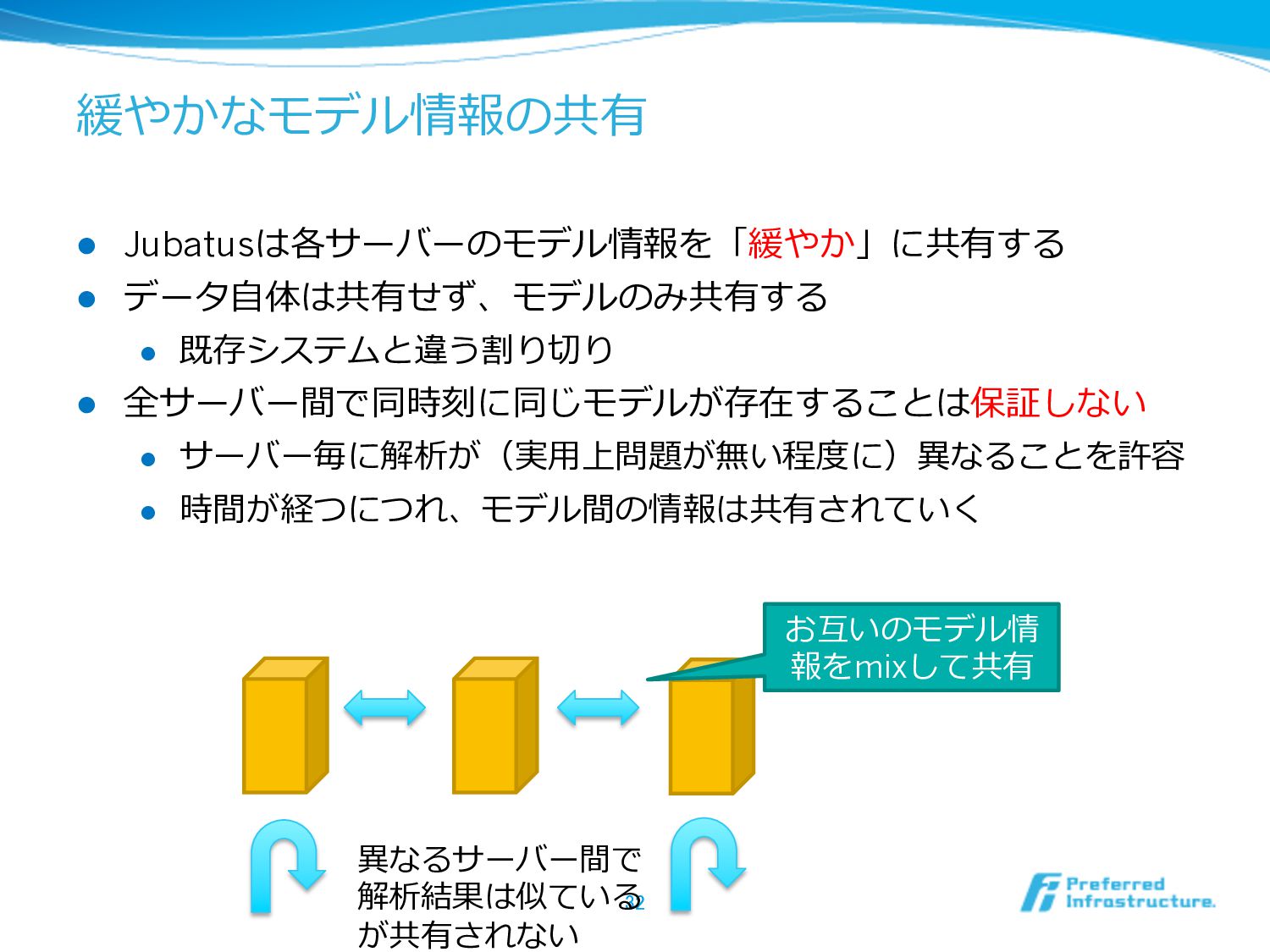
緩やかなモデル情報の共有 l Jubatusは各サーバーのモデル情報を「緩やか」に共有する l データ⾃自体は共有せず、モデルのみ共有する l 既存システムと違う割り切切り l 全サーバー間で同時刻に同じモデルが存在することは保証しない l
サーバー毎に解析が(実⽤用上問題が無い程度度に)異異なることを許容 l 時間が経つにつれ、モデル間の情報は共有されていく 32 異異なるサーバー間で 解析結果は似ている が共有されない お互いのモデル情 報をmixして共有
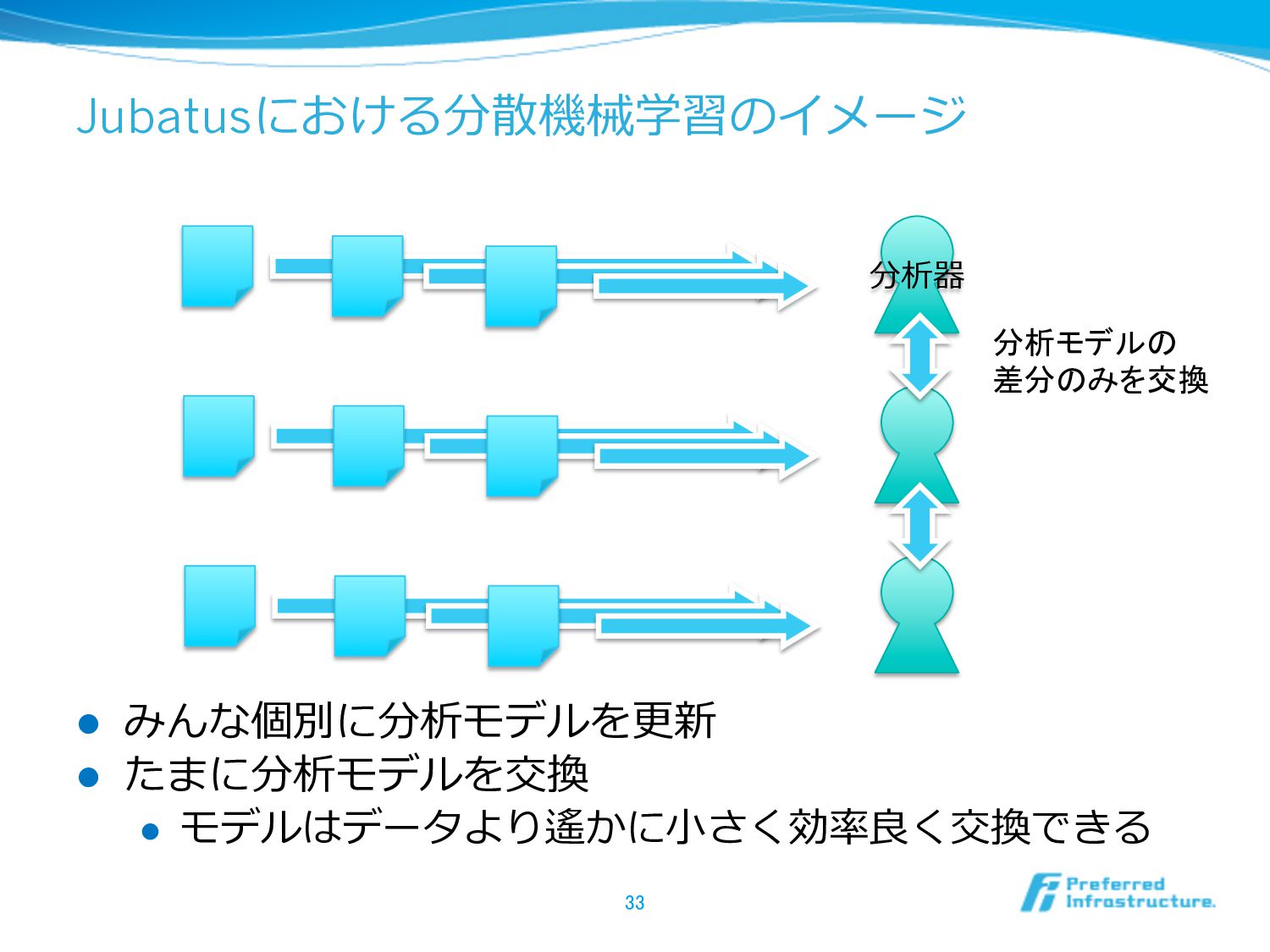
Jubatusにおける分散機械学習のイメージ l みんな個別に分析モデルを更更新 l たまに分析モデルを交換 l モデルはデータより遙かに⼩小さく効率率率良良く交換できる 33 分析器 分析モデルの
差分のみを交換
分析ロジックの抽象化 l Jubatusでは分析ロジックを3種類の処理理に分解 l 分析ロジック開発者はどう分散させるか、データを共有す るか、耐障害性を保証するかを考える必要ががない l c.f. MapReduceではロジックをMapとReduceの⼆二つに分解 l
UPDATE l データを受け取ってモデルを更更新する l ANALYZE l データを受け取って解析結果を返す l MIX(システムが勝⼿手に呼び出す) l 内部モデルを混ぜ合わせる 34
3つの操作:UPDATE l 分析モデル情報を更更新する l クライアントが結果を待つ必要は特にない 35 分析器
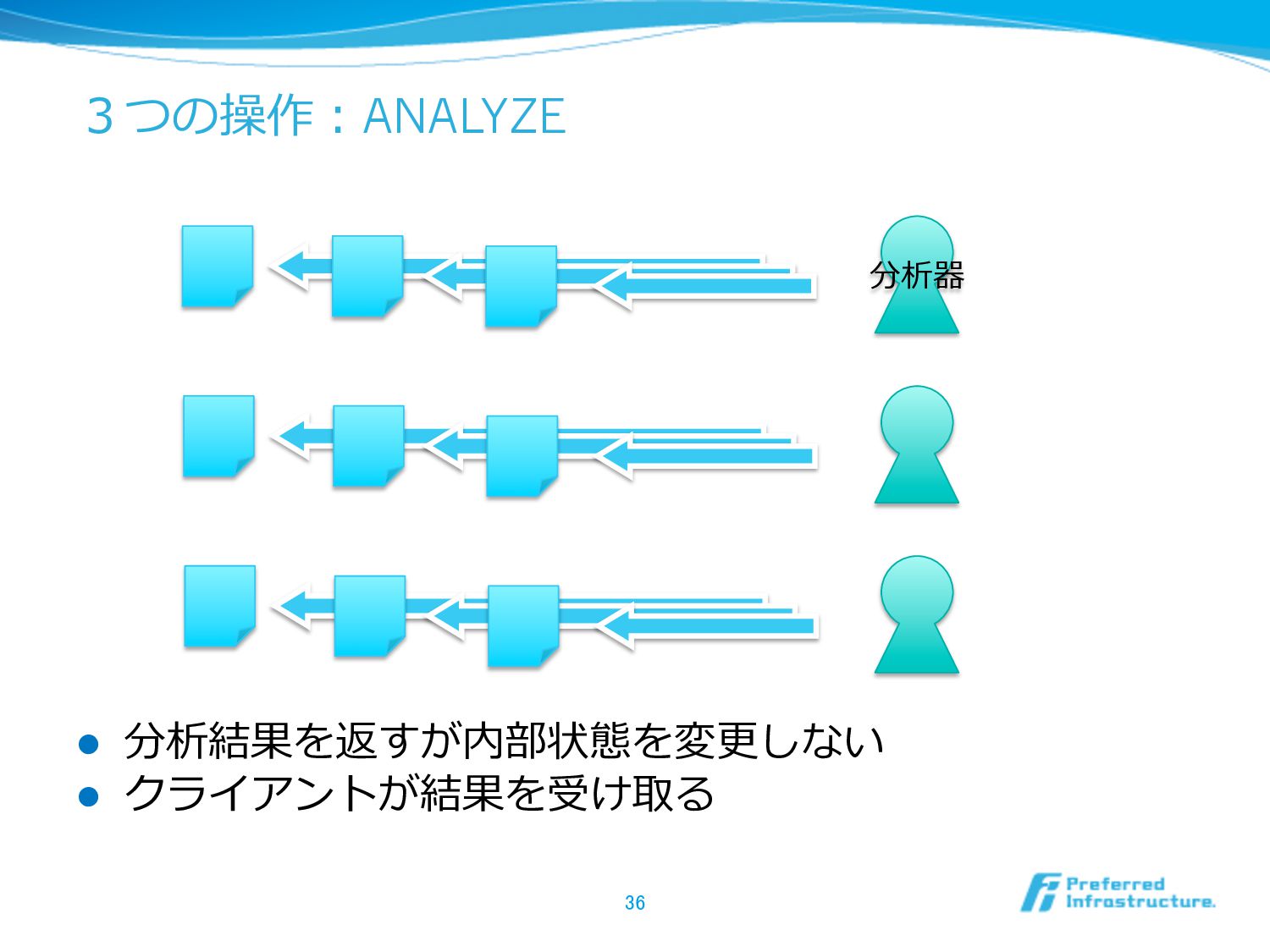
3つの操作:ANALYZE l 分析結果を返すが内部状態を変更更しない l クライアントが結果を受け取る 36 分析器
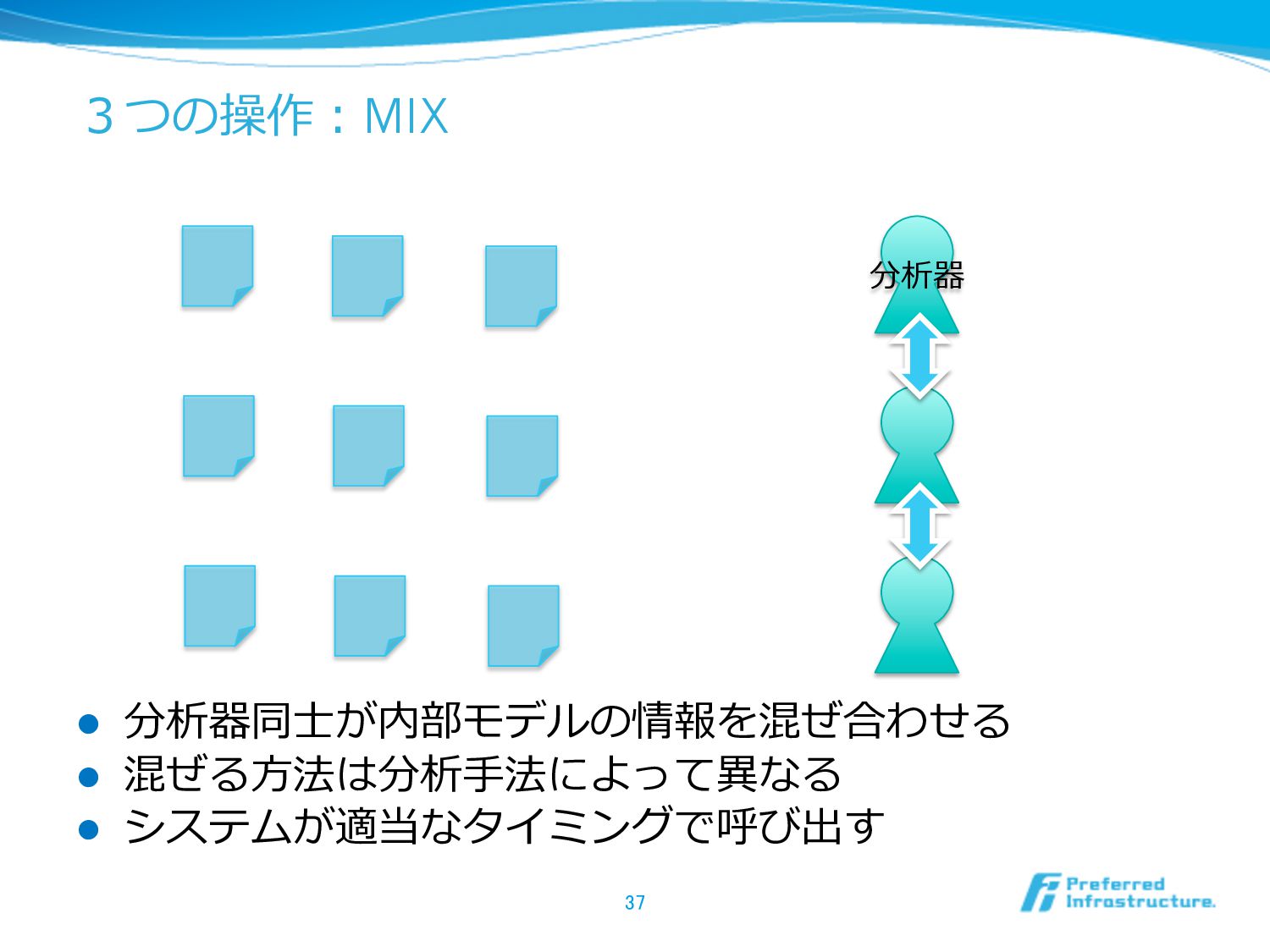
3つの操作:MIX l 分析器同⼠士が内部モデルの情報を混ぜ合わせる l 混ぜる⽅方法は分析⼿手法によって異異なる l システムが適当なタイミングで呼び出す 37 分析器
3つの処理理の例例:統計処理理の場合 l 平均値を計算する⽅方法を考えてみる l 内部状態は今までの合計(sum)とデータの個数(count) l UPDATE l sum +=
x l count += 1 l ANALYZE l return (sum / count) l MIX l sum = sum1 + sum2 l count = count1 + count2 38
「緩いモデル共有」の特徴 l 分散オンライン機械学習と相性が良良い l 独⽴立立に処理理するのでスループットが⾼高い l もともと100%の精度度達成が難しいのを逆⼿手に取り、 サーバー間で結果が異異なることを許容する l 任意の並⾏行行計算を実現できるわけではない
l 逐次処理理した結果と厳密に⼀一致しない l MIXするまで他のノード計算結果は反映されない 39
Jubatusの分析 l 現在, 以下の分析をサポート l 分類 l 教師有多クラス分類:Perceptron, PA, CW,
AROW l 回帰 l 教師有回帰分析:PA l 近傍探索索 l Inverted File Index, LSH l 統計 l 平均、分散、エントロピー、モーメント l また、グラフデータを対象にした分析もサポート予定 l ソーシャルデータやネットワーク分析なども可能となる 40
Jubatusクライアント l Jubatusの機能を利利⽤用するための各種⾔言語⽤用のクライアントを⽤用意 l C++ l Python l Ruby l
Java l Haskel l この他の⾔言語も現在サポート準備中 l これらのクライアントは、サーバーIDLから⾃自動⽣生成されている 41
42
まとめ 43
Jubatusの今後 l これまでは、実現可能性を確かめることに重点をおいていた l 適⽤用範囲の拡⼤大 l 様々なドメインのタスクに取り組み、それを開発にフィードバック l 使いやすくする l
安定性を⾼高める l 実際の利利⽤用例例にそくしたアプリケーションの開発 l クライアント、ツールの充実、ドキュメント整備 l 新機能開発 l 特に外れ値検出、コンセプトドリフト l グラフ解析 l ⼀一緒にJubatusの可能性を検証できるパートナーを探しています! 44
Copyright © 2006-2012 Preferred Infrastructure All Right Reserved.
![Jubatusにおける ⼤大規模分散オンライン機械学習 海野 裕也 (株) Preferred Infrastructure 研究開発部⾨門 <[email protected]> 2012/6/1先端⾦金金融テクノロジー研究会](https://files.speakerdeck.com/presentations/17ff13dfed274f71ac605910e99e4c95/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}