Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
「巨人の肩の上」で自作ライブラリを作る技術 / pyconjp2024
Search
Shotaro Ishihara
September 22, 2024
Technology
1.3k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
「巨人の肩の上」で自作ライブラリを作る技術 / pyconjp2024
「巨人の肩の上」で自作ライブラリを作る技術 (PyConJP 2024)
https://2024.pycon.jp/ja/talk/CLJQ37
Shotaro Ishihara
September 22, 2024
More Decks by Shotaro Ishihara
See All by Shotaro Ishihara
大規模言語モデルは誰を覚えているか / Who Do Large Language Models Memorize?
upura
0
87
[ACL 2026 Demo] Fast-MIA: Efficient and Scalable Membership Inference for LLMs
upura
0
87
Fast-MIA: Efficient and Scalable Membership Inference for LLMs
upura
0
49
JAPAN AI CUP Prediction Tutorial
upura
2
1.2k
情報技術の社会実装に向けた応用と課題:ニュースメディアの事例から / appmech-jsce 2025
upura
0
400
日本語新聞記事を用いた大規模言語モデルの暗記定量化 / LLMC2025
upura
0
760
Quantifying Memorization in Continual Pre-training with Japanese General or Industry-Specific Corpora
upura
1
130
JOAI2025講評 / joai2025-review
upura
0
1.7k
AI エージェントを活用した研究再現性の自動定量評価 / scisci2025
upura
1
270
Other Decks in Technology
See All in Technology
Claude Codeとハーネスについて考えてみる
oikon48
19
9.5k
kintone の AI コワーカーを、 Anthropic にエージェントを"ホストさせて"作った話 #devkinmeetup
sugimomoto
0
110
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.2k
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
13
6.2k
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
410
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
0
140
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
130
クラウド上のデータ復旧で見落としがちな制約: 医療系 SaaS の BCP 設計から得た教訓
kakehashi
PRO
0
3.5k
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
4.6k
Compose 新機能総まとめ / What's New in Jetpack Compose
yanzm
0
250
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
100
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
240
Featured
See All Featured
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
380
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
890
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
230
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
330
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
A Modern Web Designer's Workflow
chriscoyier
698
190k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
Site-Speed That Sticks
csswizardry
13
1.3k
Transcript
「巨人の肩の上」 で自作ライブラリ を作る技術 石原祥太郎 (日本経済新聞社) PyCon JP 2024、2024 年 9
月 28 日
特定の目的に向けて既存 技術を調査し、自作の Python ライブラリを実 装・評価する一連の流れ を紹介 2 「巨人の肩の上」で自作ライブラリ https://speakerdeck.com /upura/pyconjp2024
①要件の確認 ②既存ライブラリ・文献の調査 ③方針の策定 ④実装・性能評価・改善 3 開発手順
①要件の確認 ②既存ライブラリ・文献の調査 ③方針の策定 ④実装・性能評価・改善 4 開発手順
大学新聞で編集長などを経て、 日本経済新聞社に入社。現在は 研究開発部門で、独自の大規模 言語モデルの構築に従事。 5 現在のお仕事
> 実践:日本語文章生成 Transformersライブラリで学 ぶ実装の守破離 https://2022.pycon.jp/timetable/?id=EEA8FG 6 PyCon JP 2022
7 国際会議 INLG 2024 (9/23-27) で発表 • 日経電子版で学習した大規模 言語モデル (GPT-2)
の暗記を 分析した研究 [論文] • 日本科学未来館で開催
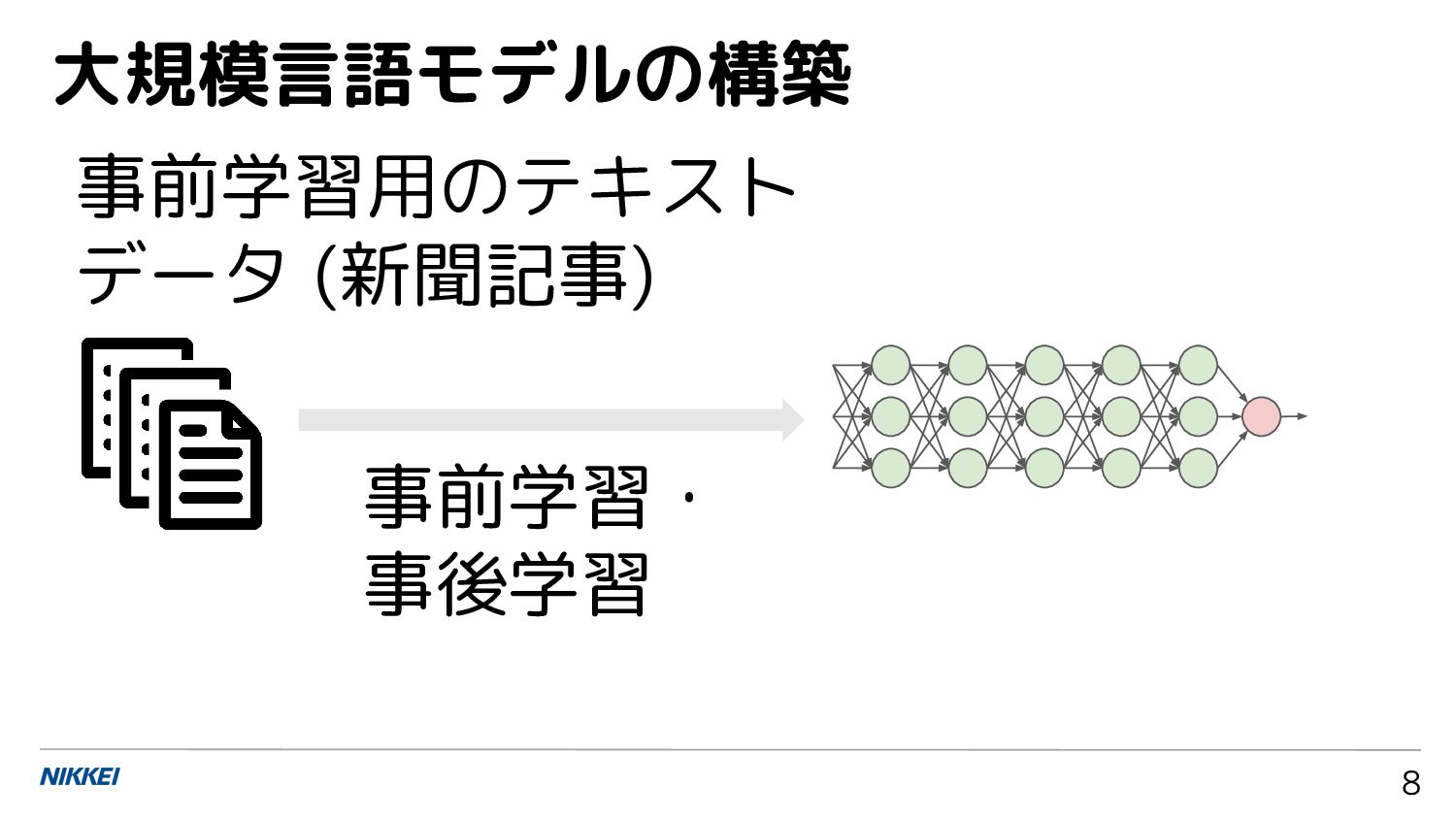
8 大規模言語モデルの構築 事前学習用のテキスト データ (新聞記事) 事前学習・ 事後学習
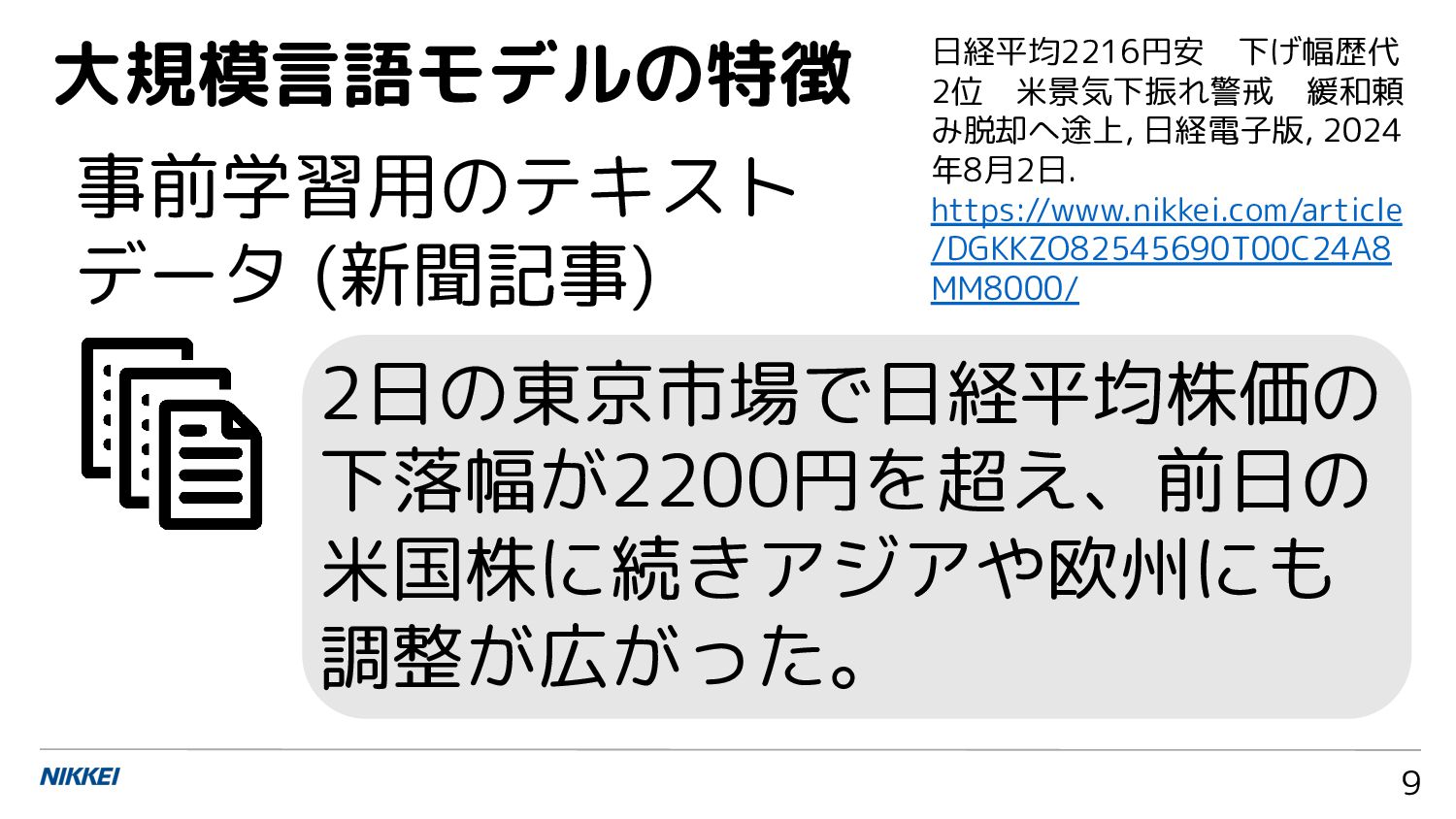
9 大規模言語モデルの特徴 事前学習用のテキスト データ (新聞記事) 2日の東京市場で日経平均株価の 下落幅が2200円を超え、前日の 米国株に続きアジアや欧州にも 調整が広がった。 日経平均2216円安 下げ幅歴代
2位 米景気下振れ警戒 緩和頼 み脱却へ途上, 日経電子版, 2024 年8月2日. https://www.nikkei.com/article /DGKKZO82545690T00C24A8 MM8000/
10 大規模言語モデルの特徴 事前学習用のテキスト データ (新聞記事) 2日の東京市場で日経平均株価の 下落幅が2200円を超え、前日の 米国株に続きアジアや欧州にも 調整が広がった。 いつ?
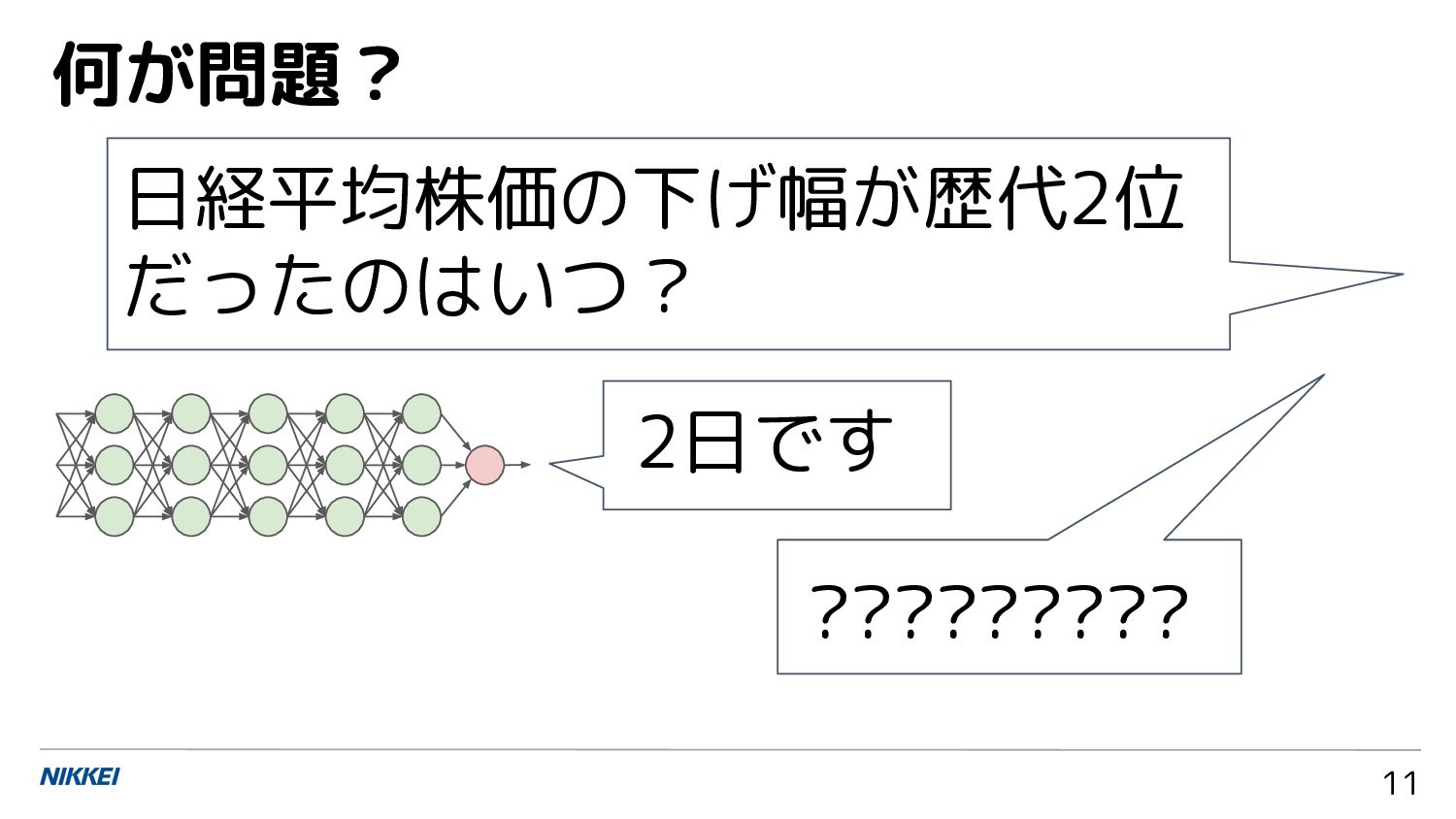
11 何が問題? 日経平均株価の下げ幅が歴代2位 だったのはいつ? 2日です ?????????
12 実現したいこと 事前学習用のテキスト データ (新聞記事) 2024年8月2日の東京市場で日経 平均株価の下落幅が2200円を超 え、前日の米国株に続きアジア や欧州にも調整が広がった。 公開日を
用いて復元
新聞記事から時間表現を抽出し 日付を特定し省略を補完 • 入力:テキスト、公開日時 • 出力:補完されたテキスト 13 題材となる自作ライブラリ
大規模言語モデルの事前学習用 のテキストは大量のため、一定 の性能で高速処理できることが 望ましい 14 自作ライブラリの要件
①要件の確認 ②既存ライブラリ・文献の調査 ③方針の策定 ④実装・性能評価・改善 15 開発手順
16 要件を踏まえ既存の取り組みを調査 • 社内で共有するなど、有識者に質問 • 一つの文献を起点に、芋づる式に探索 • X などで、定期的に情報収集 •
「車輪の再開発」を避ける 既存ライブラリ・文献の調査
時間情報表現を抽出・規格化 ❯ print(TimexParser().parse("彼は2008 年4月から週に3回のジョギングを、朝8時 から1時間行ってきた")) 17 既存ライブラリ①:ja-timex
時間情報表現を抽出・規格化 ❯ [<TIMEX3 tid="t0" type="DATE" value="2008-04-XX" text="2008年4月">] 18 既存ライブラリ①:ja-timex
汎用言語モデルに基づく統合的解析器 ❯ kwja --text "日本サッカー協会は27日、 来年2、3月にホームで開催する男女の日 本代表と北朝鮮代表との試合会場が東京・ 国立競技場に決まったと発表した。" 19 既存ライブラリ②:KWJA
汎用言語モデルに基づく統合的解析器 ❯ + 21D <NE:DATE:27日><体言><修飾><時間> 27 にじゅうしち 27 名詞 6
数詞 7 * 0 * 0 日 にち 日 接尾辞 14 名詞性名詞助数辞 3 * 0 * 0 "代表表記:日/にち 準内容語 カテゴリ:時間" <基本句-主辞> 20 既存ライブラリ②:KWJA
ja-timex の README やドキュメントを起 点に、芋づる式に • 引用している/されている文献を調査 • Connected Papers
などでも関連研究を 調査 21 既存文献の調査
①要件の確認 ②既存ライブラリ・文献の調査 ③方針の策定 ④実装・性能評価・改善 22 開発手順
ja-timex の「実装方針」を参考に、時間 情報表現の抽出と、省略の補完の処理を 分けて考えるべきと判断 • 抽出:ja-timex にお任せ • 補完:独自実装のため性能評価が必要 23
方針の策定
24 KWJA (などの大規模言語モデル) は性能 面で優れているが、実行時間や費用がか かるため、今回は不採用に • ChatGPT など商用 API
も同様 • ja-timex はルールベースで軽量 不採択の理由
①要件の確認 ②既存ライブラリ・文献の調査 ③方針の策定 ④実装・性能評価・改善 25 開発手順
26 1. ライブラリとして実装開始 2. いくつかの記事を手動で変換 3. 規則性を見い出しテストケースを作成 4. テストが通るように実装を追加し、必 要に応じて全体をリファクタリング
「テストファースト」で実装・評価・改善
27 ライブラリとして実装開始 • ディレクトリのルートに setup.py • pip install -e .
で編集モードでインス トール https://packaging.python.org/en/latest/gui des/distributing-packages-using-setuptools /
• プロジェクト名を付けると気分が乗る • 最初は入出力だけを定義することに ❯ from jarote import by_rote ❯
… ❯ by_rote(text, reference_datetime) 28 jaROTE (Reproducing Omitted Time Expressions for Japanese)
29 1. 入力のテキストに対して ja-timex を実 行し、時間情報表現を抽出 2. それぞれに対し、入力の公開日時を参 照して、省略があれば書き換えを実施 3.
書き換えを反映したテキストを返す jaROTE の内部処理
30 • 「日本経済新聞記事オープンコーパス」 の 96 記事を対象に Spreadsheet に入 出力の組を列挙 •
泥臭く取り組みながら、要件を精緻化し ていく 最終的に実現したい処理を手動で実行
31 • たとえば、年に関する文字列を具体的 な数値に変換するケースでまとめ上げ • テスト用ライブラリ pytest で、出力 と期待する結果の一致を確認 規則性を見い出し、テストケースを作成
• 当然、最初は不一致でテストが失敗 • テストが通るように実装を進めていく • 必要に応じて全体をリファクタリング 32 テストが通るように実装を追加
33 • 実装と性能評価が同時並行で完了 • テストケースを見ると処理が分かりや すい • 一方、初期の開発コストは大きくなる 「テストファースト」の特徴
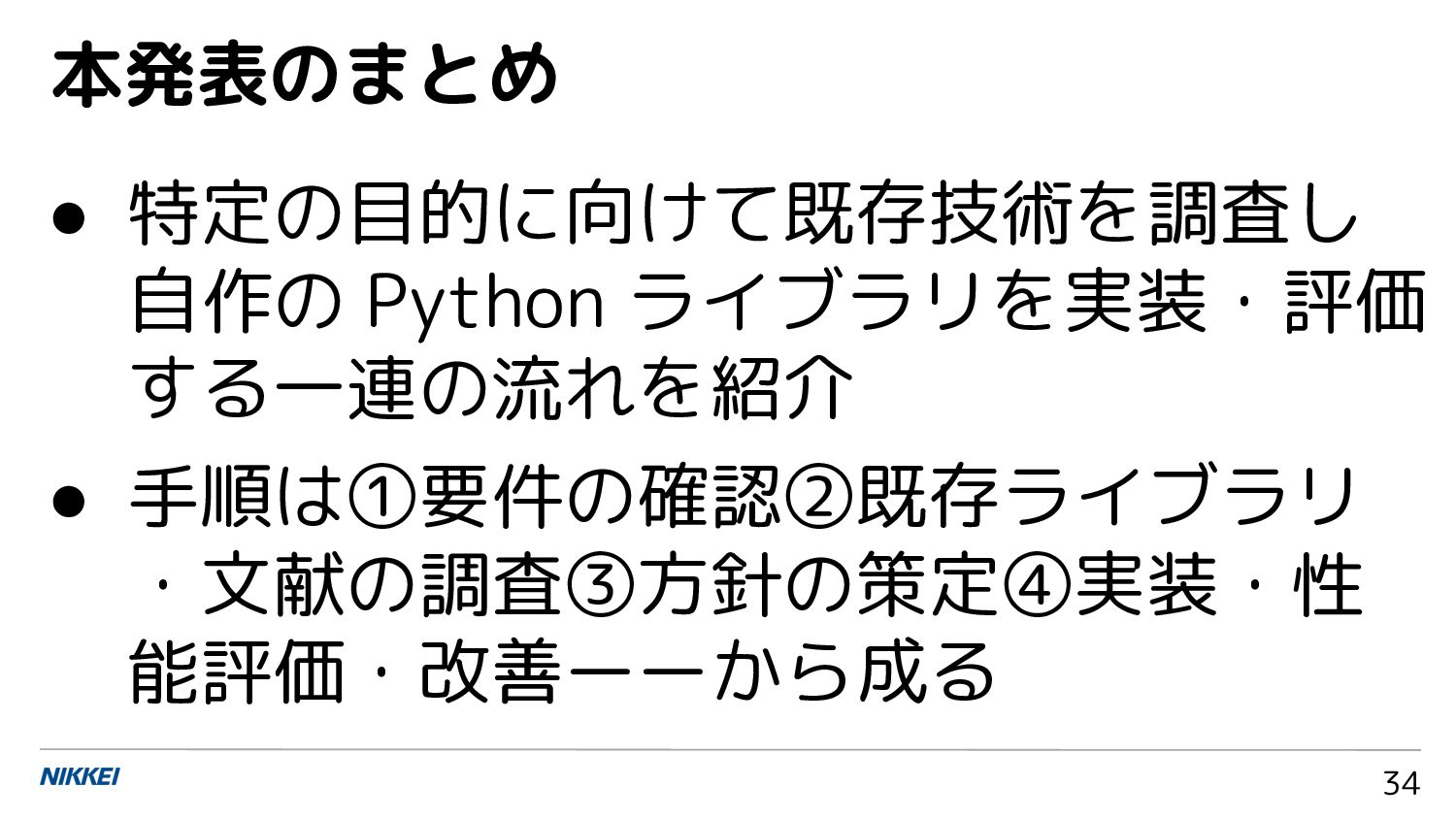
• 特定の目的に向けて既存技術を調査し 自作の Python ライブラリを実装・評価 する一連の流れを紹介 • 手順は①要件の確認②既存ライブラリ ・文献の調査③方針の策定④実装・性 能評価・改善ーーから成る
34 本発表のまとめ
35 • 開発論の具体的な議論 (「テスト ファースト」「テスト駆動開発」など) • jaROTE で時刻表現の省略を補完した テキストは、大規模言語モデルにとっ て価値がある?
本発表で話さなかったこと
• 「巨人」の知見 (ja-timex や KWJA、 過去の発表文献など) に改めてお礼申 し上げます • jaROTE
もその一部になれるよう、鋭 意開発を進めていきます 36 謝辞
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![時間情報表現を抽出・規格化 ❯ [<TIMEX3 tid="t0" type="DATE" value="2008-04-XX" text="2008年4月">] 18 既存ライブラリ①:ja-timex](https://files.speakerdeck.com/presentations/e7eb74b24f154718aa303087dfb1bcd7/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}