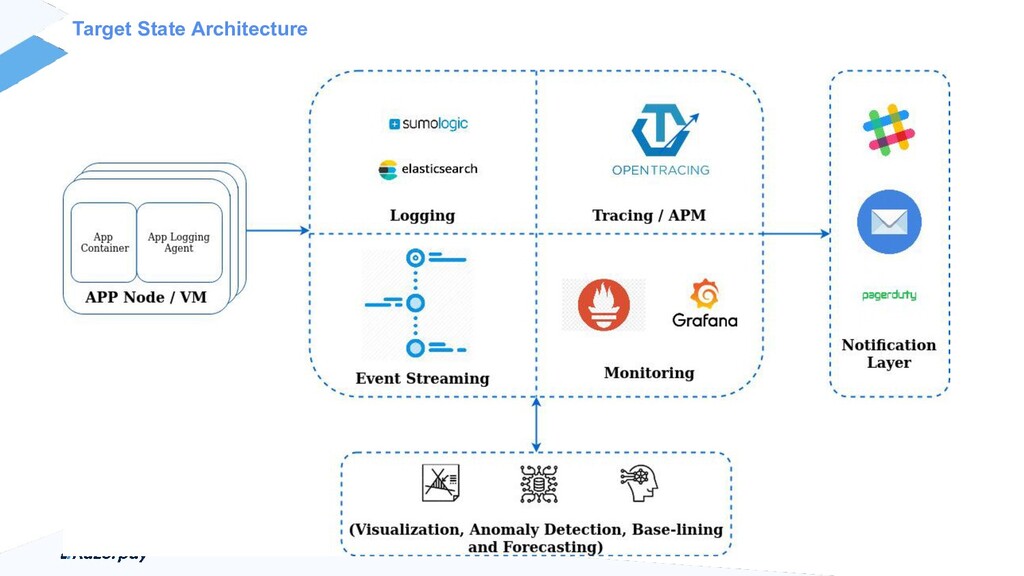
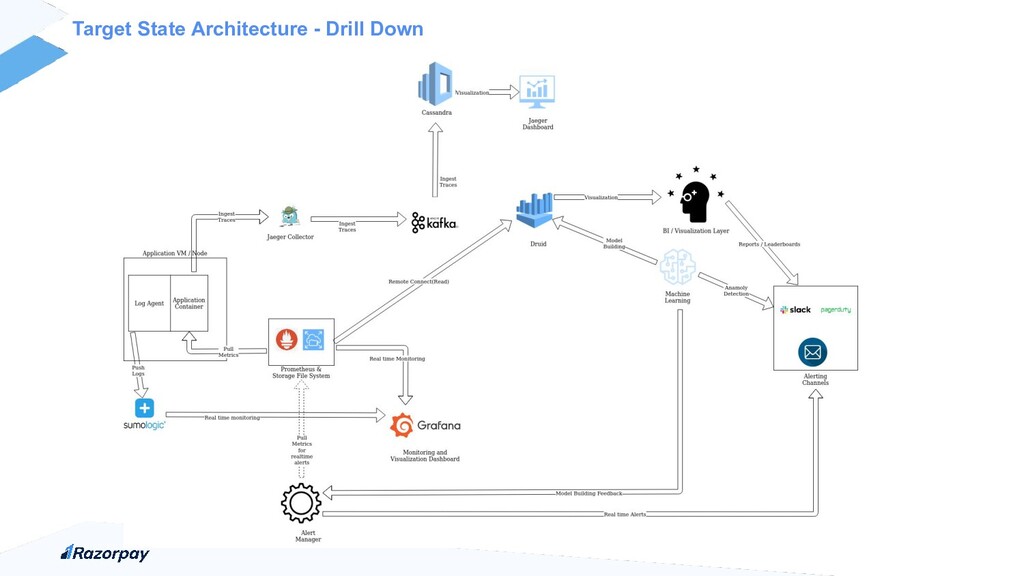
Talk around our journey of moving from Paid APM tools into open source observability platforms. We focus on our path, success and failure stories. More specifically, when does it make sense to build vs buy, what are the challenges in building home grown solutions and leveraging and building upon some existing stuff. Alongside, also some interesting contribution ideas to the Open Telemetry Collector, its limitations, Scaling Issues amongst others
{kind=link}
{kind=link}
{kind=link}
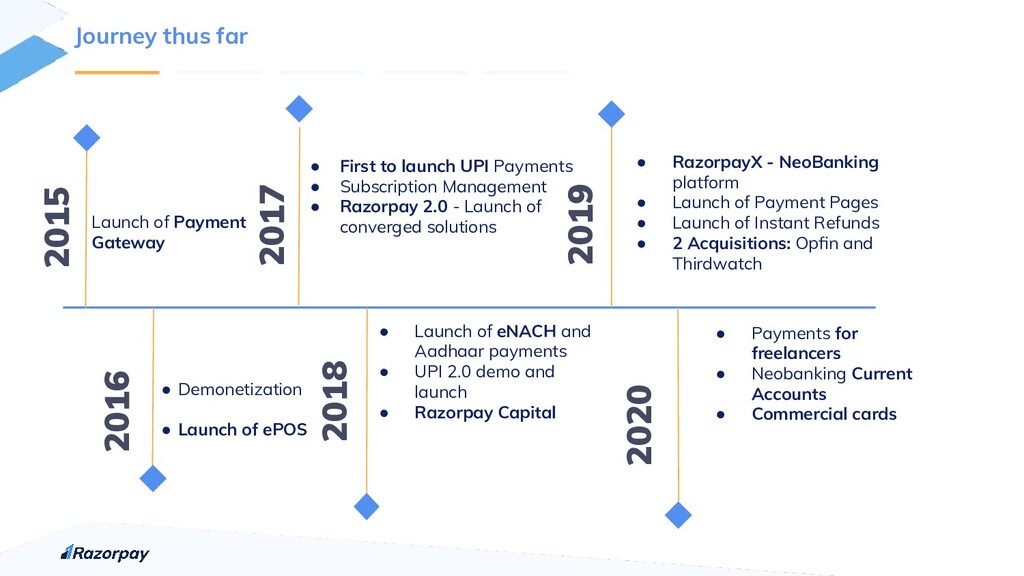{kind=link}
{kind=link}
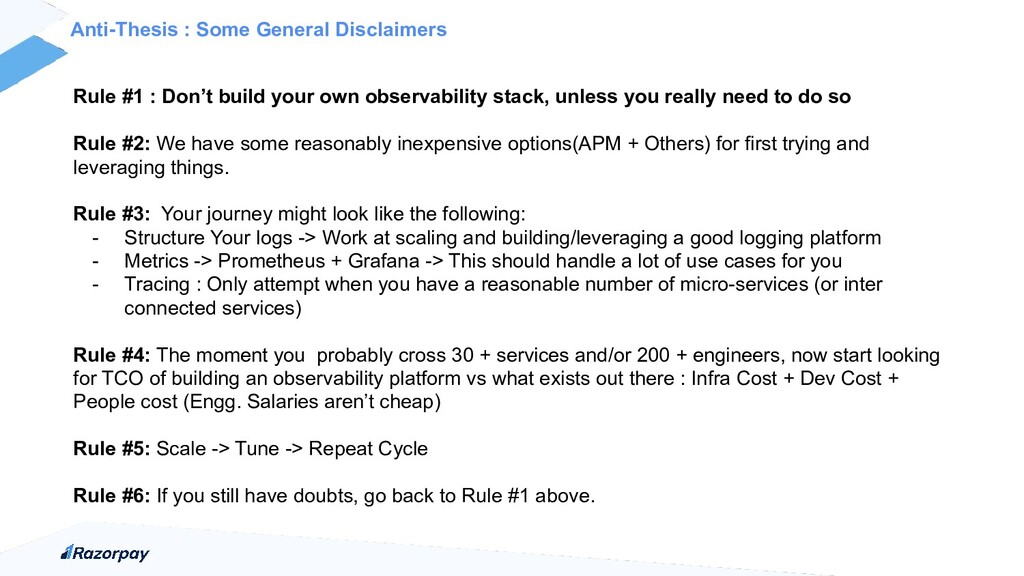{kind=link}
{kind=link}
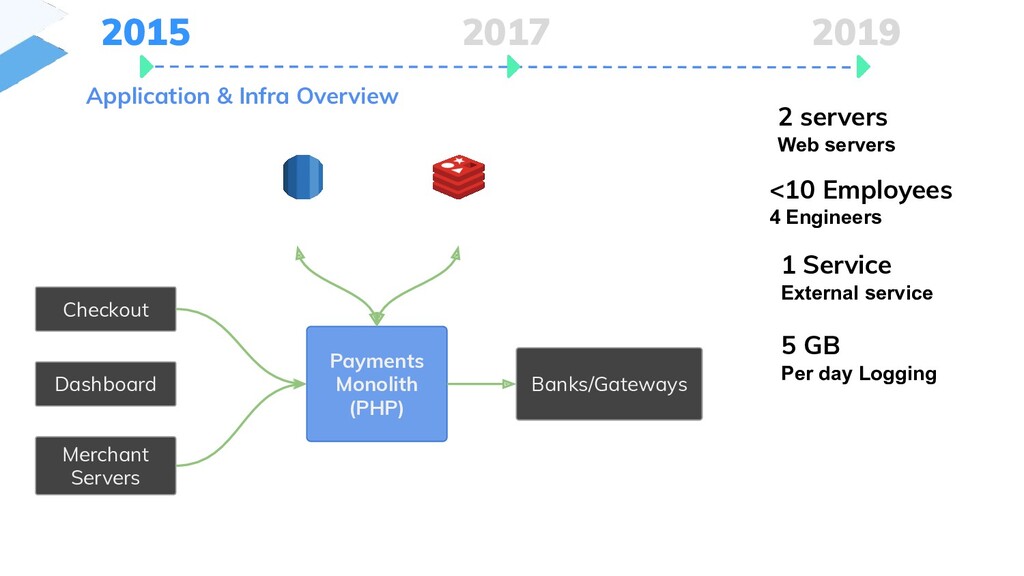{kind=link}
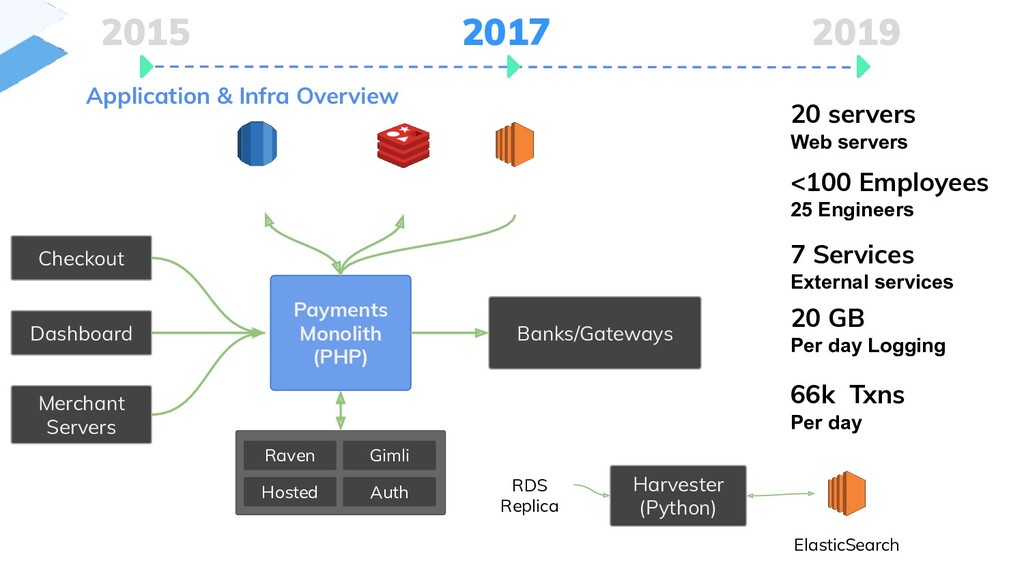{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}