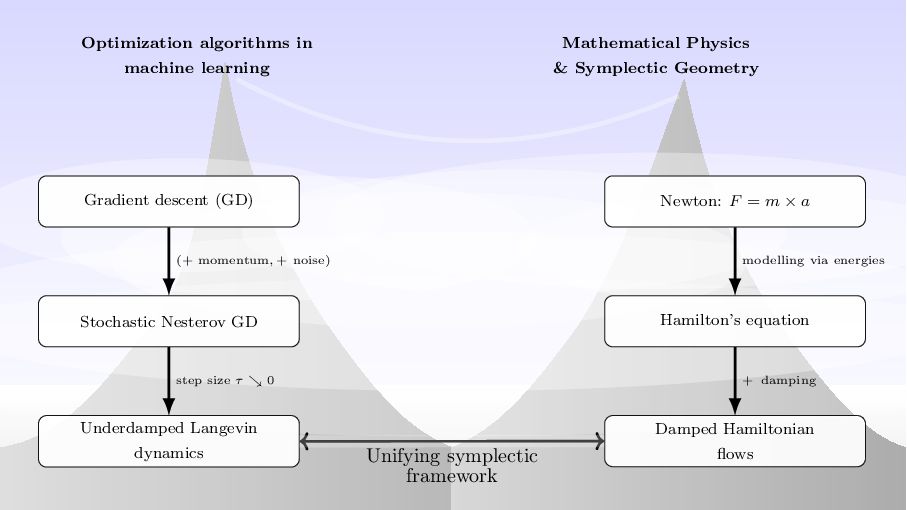
Gradient-based optimization algorithms are indispensable for most modern machine learning applications, since they are used to train convolutional neural networks (CNNs) for image classification or transformers for natural language processing. Often, the weights are optimized using the Adam algorithm, a momentum-based modification of gradient descent. In the vanishing step-size limit, these momentum-based algorithms can be described as second-order damped dynamics with a time-dependent Hamiltonian interpretation.
In this talk, I will gently introduce the contact geometry behind time-dependent Hamiltonian systems and show how viewing momentum-based methods in machine learning through this geometric lens can help elucidate their properties.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Bibliography [1] D. Kingma and J. Ba, “Adam: A method](https://files.speakerdeck.com/presentations/cbe74067065e418aa57713272523f911/slide_14.jpg){kind=link}