of the words “governor” and “cybernetic” • Manages container clusters • Inspired and informed by Google’s experiences and internal systems • Supports multiple cloud and bare-metal environments • Supports multiple container runtimes • 100% Open source, written in Go Manage applications, not machines
across cloud providers and on-prem data centers • Ability to manage 2000+ machines with lots of compute resources • Separation of concerns ◦ Admins vs developers • Maximize utilization without compromising performance • Self healing • Building block for Distributed Systems
each other’s performance • users don’t worry about interference • Predictability - repeated runs of same app gives ~equal perf • allows strong performance SLAs Cons: • Usability - how do I know how much I need? • system can help with this • Utilization - strong isolation: unused resources get lost • costly - system has to keep them available for requester • mitigate with overcommitment • challenge: how to do it safely Strong isolation
of a resource container is asking to use with a strong guarantee of availability • CPU (fractional cores) • RAM (bytes) • scheduler will not over-commit requests Limit: • max amount of a resource container can access • scheduler ignores limits (overcommitment) Repercussions: • Usage > Request: resources might be available • Usage > Limit: killed or throttled Limit Request
• request > 0 && limit == request for all containers in a Pod • Sensitive or Critical Apps Best Effort: lowest protection • request == 0 (limit == node size) for all containers in a Pod • Data processing Apps Burstable: medium protection • request > 0 && limit > request for any container in a Pod Limit Request
implemented? • CPU: some Best Effort/Burstable container using more than its request is throttled • CPU shares + CPU quota • Memory: some Best Effort/Burstable container using more than its request is killed • OOM score + user-space evictions • Storage: Isolated on a best-effort basis. • User space evictions to improve node stability • Evict images, dead containers and pods (based on QoS) to free up disk space • Evictions based on disk space & inodes Limit Request
Reserve resources for System daemons ◦ Kubelet, Docker, systemd, sshd, etc. • Node Overhead a function of pod & container density (Dashboard) • Statically configurable via Kubelet • Scheduler uses Allocatable as “usable capacity” • Eviction thresholds ◦ Hard, Soft, minimum reclamation Capacity Allocatable System Daemons
kubelet) • gather node & container stats • export via REST Run Heapster as a pod in the cluster • aggregates stats • just another container, no special access Writes metrics to InfluxDB, can be viewed by Grafana Dashboard • Observe cpu & memory usage Or plug in your own monitoring system! • Sysdig, Prometheus, Datadog, Stackdriver, etc.
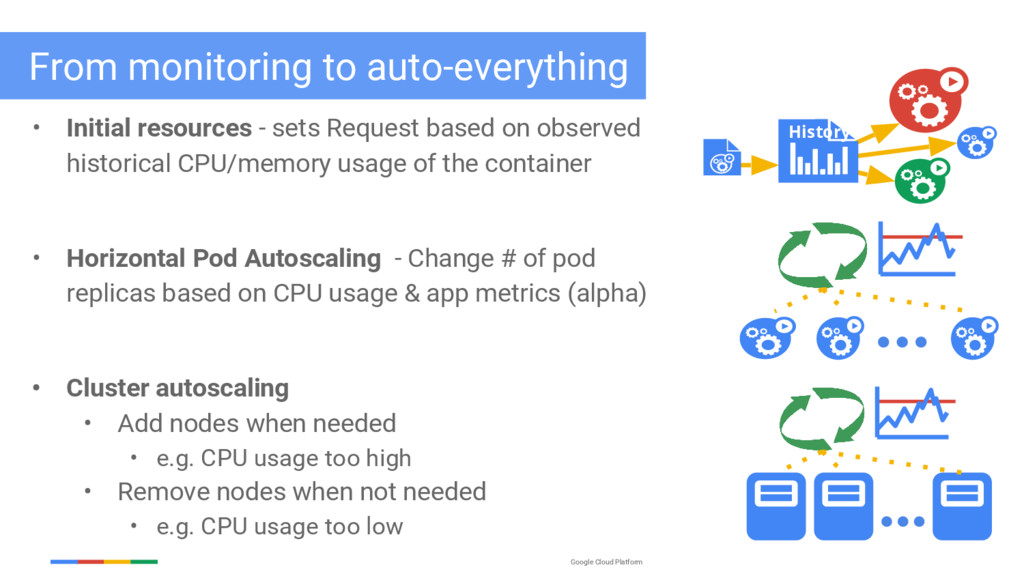
- sets Request based on observed historical CPU/memory usage of the container • Horizontal Pod Autoscaling - Change # of pod replicas based on CPU usage & app metrics (alpha) History
- sets Request based on observed historical CPU/memory usage of the container • Horizontal Pod Autoscaling - Change # of pod replicas based on CPU usage & app metrics (alpha) • Cluster autoscaling • Add nodes when needed • e.g. CPU usage too high • Remove nodes when not needed • e.g. CPU usage too low History
across all pods • applies to each type of resource (CPU, mem) • user must specify request or limit • maximum number of a particular kind of object Ensure no user/app/department abuses the cluster Applied at admission time Just another API object
on the cluster • uses the Kubernetes API to learn cluster state and request bindings • you can run multiple schedulers in parallel, responsible for different pods 1) Predicate functions determine which nodes a pod is eligible to run on 2) Priority functions determines which of those nodes is “best”
mem) • node affinity/anti-affinity • label(s) on node, label query on pod • e.g. “put the pod on a node in zone abc” • e.g. “put the pod on a node with an Intel CPU” • inter-pod affinity/anti-affinity • label(s) on pod, label query on pod • which other pods this pod must/cannot co-exist with • e.g. “co-locate the pods from service A and service B in the same node/zone/... since they communicate a lot with each other” • e.g. “never run pods from service A and service B on the same node” • others
score combining these factors: • spreading or best-fit (resources) • node affinity/anti-affinity (“soft” version) • e.g. “put the pod in zone abc if possible” • inter-pod affinity/anti-affinity (“soft” version) • e.g. “co-locate the pods of service A and service B in the same zone as much as possible” • e.g. “spread the pods from service A across zones” • node has image(s) the container needs already cached
GPU support (e.g. multiple GPUs/node) Runtime-extensible resource set Usage-based scheduling Dedicated nodes - mix private and shared nodes in a single cluster Priority/preemption - when quota overcommitted and cluster full, who runs Improved QoS enforcement • Pod & QoS cgroups (alpha in v1.5) • Linux disk quota for tracking and isolation • Exclusive CPUs, NUMA, etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}