Integration of complex biological data • Parsers for common biological data formats • Extensible framework for custom data • Cookie-cutter interface, highly customizable • Interact using sophisticated web query tools • Programmatic access using web-service API
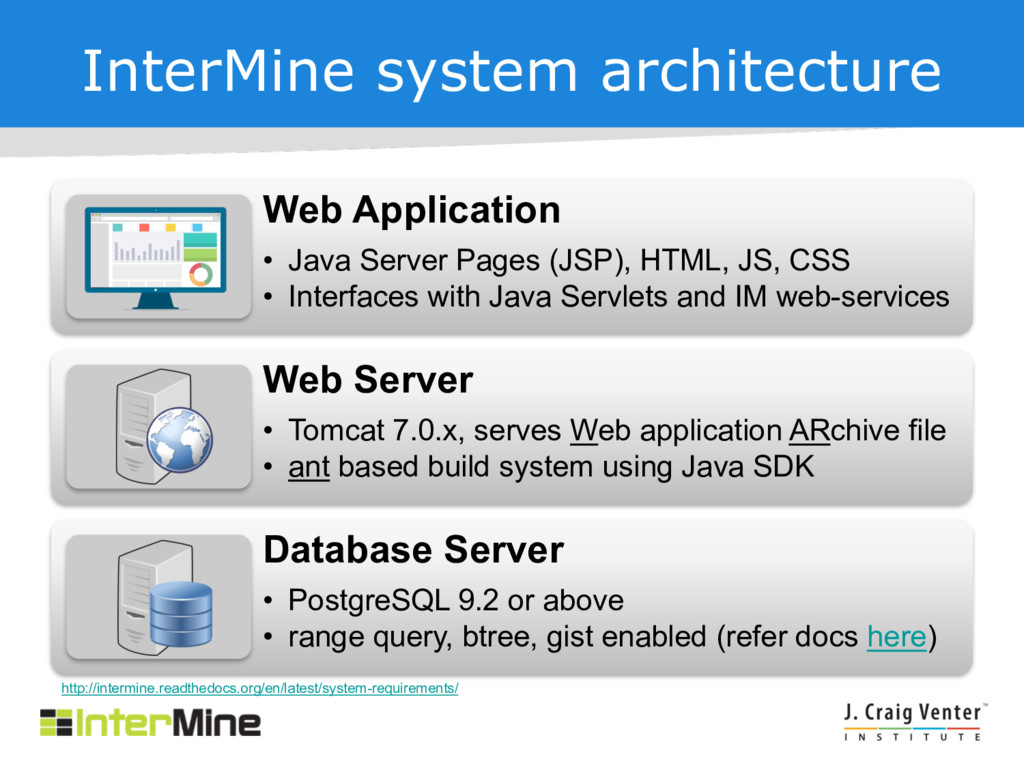
HTML, JS, CSS • Interfaces with Java Servlets and IM web-services Web Server • Tomcat 7.0.x, serves Web application ARchive file • ant based build system using Java SDK Database Server • PostgreSQL 9.2 or above • range query, btree, gist enabled (refer docs here) http://intermine.readthedocs.org/en/latest/system-requirements/
classes, their attributes and their relationships; defined in XML • Represented as Java classes (pure Java beans); auto-generated from XML, automatically map to tables in schema • Core data model; based on Sequence Ontology (SO); refer: bio/core/core.xml and bio/core/genomic_additions.xml http://intermine.readthedocs.org/en/latest/data-model/overview/
is-interface="true" extends="SequenceFeature"> <attribute name="name" type="java.lang.String"/> <attribute name="accession" type="java.lang.String"/> <collection name="features" referenced-type="NewFeature" reverse-reference="protein"/> </class> <class name="NewFeature" is-interface="true"> <attribute name="identifier" type="java.lang.String"/> <attribute name="confidence" type="java.lang.Double"/> <reference name="protein" referenced-type="Protein" reverse-reference="features"/> </class> </model> Model expects standard Java names for classes and attributes • classes: start with an upper case letter and be CamelCase, no underscores or spaces. • fields (attributes, references, collections): should start with a lower case letter and be lowerCamelCase, no underscores or spaces. http://intermine.readthedocs.org/en/latest/data-model/model/
of data source parsers and loaders, covering data types not restricted to: genome sequence (fasta) annotation (gff) ontology (go, so) proteins (uniprot) interactions (psi-mi) pathway (kegg, reactome) homologs (panther, compara, homologene) publications (pubmed) chado (sequence, stock) • Custom sources can be written by following the tutorial: http://intermine.readthedocs.org/en/latest/database/data- sources/custom/ or by referring to code from other mines http://intermine.readthedocs.org/en/latest/database/data-sources/library/
databases: ¡ legumine: core db mapping to data model ¡ items-legumine: db for storing intermediate Items during load ¡ userprofile-legumine: db for storing user specific data • Running build requires special config file in the users’ home area, containing db connection params and other mine specific configs to override ${HOME}/.intermine/legumine.properties http://intermine.readthedocs.org/en/latest/get-started/tutorial/#properties-file
contributes towards the data model • bio/core/core.xml is always used as the base for model merging • The ant build-db command consumes the SOURCE_additions.xml • Model is used to generate tables, Java classes and the webapp http://intermine.readthedocs.org/en/latest/database/database-building/model- merging/ Data Integration • Key(s) for class of object defines equivalence for objects of that class • Primary key defines field(s) used to search for equivalence • For objects which share same primary key, fields are merged and stored as single object http://intermine.readthedocs.org/en/latest/database/database-building/primary-keys/
Calculate/set fields difficult to work with while data loading, because they require 2 or more sources to be loaded already • Order of steps is somewhat important <post-processing> <post-process name="create-references" /> <post-process name="create-chromosome- locations-and-lengths"/> <post-process name="create-gene-flanking- features" /> <post-process name="do-sources" /> <post-process name="create-intron- features"> <property name="organisms" value="3880"/> </post-process> <post-process name="transfer-sequences"/> <post-process name="populate-child- features"/> <post-process name="create-location-range- index" /> <post-process name="create-overlap-view" /> <post-process name="create-attribute- indexes"/> <post-process name="summarise- objectstore"/> <post-process name="create-search-index"/> </post-processing> http://intermine.readthedocs.org/en/latest/database/database-building/post-processing/
• Manual: $ cd dbmodel && ant clean build-db ## initialize db $ ant -Dsource=legumine-gff ## load data sources $ ant -Dsource=legumine-chr-fasta ## load more sources $ cd ../postprocess && ant ## run post-process steps $ cd ../webapp ## build mine webapp $ ant clean remove-webapp default release-webapp • Automated: $ ../bio/scripts/project_build -b -v localhost ~/legumine-dump http://intermine.readthedocs.org/en/latest/database/database-building/build-script/
indexing, zips and stores in db • On webapp (first) load, index is unpacked • By default, all id and text fields are ignored by the indexer • Uses the Apache Lucene whitespace analyzer to identify word boundaries • Control temp directory and classes/fields to be ignored by altering MINE_NAME/dbmodel/resources/keyword_sear ch.properties file http://intermine.readthedocs.org/en/latest/webapp/keyword-search/
InterMine supports industry standard OAuth2 based login flows, implemented by Google, GitHub, Agave, etc. • ThaleMine relies on this infrastructure to authenticate users against the araport.org tenant registered within the Agave infrastructure • Documentation available here: http://intermine.readthedocs.org/en/latest/webapp/ properties/web-properties/#openauth2-settings- aka-openid-connect
warehouse ¡ Performs complex data integration ¡ Allows fast and flexible querying ¡ Well documented programmatic interface ¡ Cookie-cutter, user-friendly web interface ¡ Facilitates cross-talk between “mines” • Caveats ¡ Adding more data requires a full database rebuild (incremental loading is not possible) because of the integration step • About InterMine: ¡ Developed by the Micklem Lab at the University of Cambridge, UK ¡ Written in Java, backed by PostgreSQLdb, deployed under Tomcat. Documentation and downloads available at http://www.intermine.org
¡ Alex Kalderimis ¡ Richard Smith ¡ Sergio Contrino ¡ Josh Heimbach ¡ et al. • Araport Team ¡ Chris Town ¡ Jason Miller ¡ Matt Vaughn ¡ Maria Kim ¡ Svetlana Karamycheva ¡ Erik Ferlanti ¡ Chia-Yi Cheng ¡ Benjamin Rosen ¡ Irina Belyaeva
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}