Araport plans to implement a Chado-backed data warehouse, fronted by Tripal, serving as as our core database, used to track multiple versions of genome annotation (TAIR10, Araport11, etc.), evidentiary data (used by our annotation update pipeline), metadata such as publications collated from multiple sources like TAIR, NCBI PubMed and UniProtKB (curated and unreviewed) and stock/germplasm data linked to AGI loci via their associated polymorphisms.
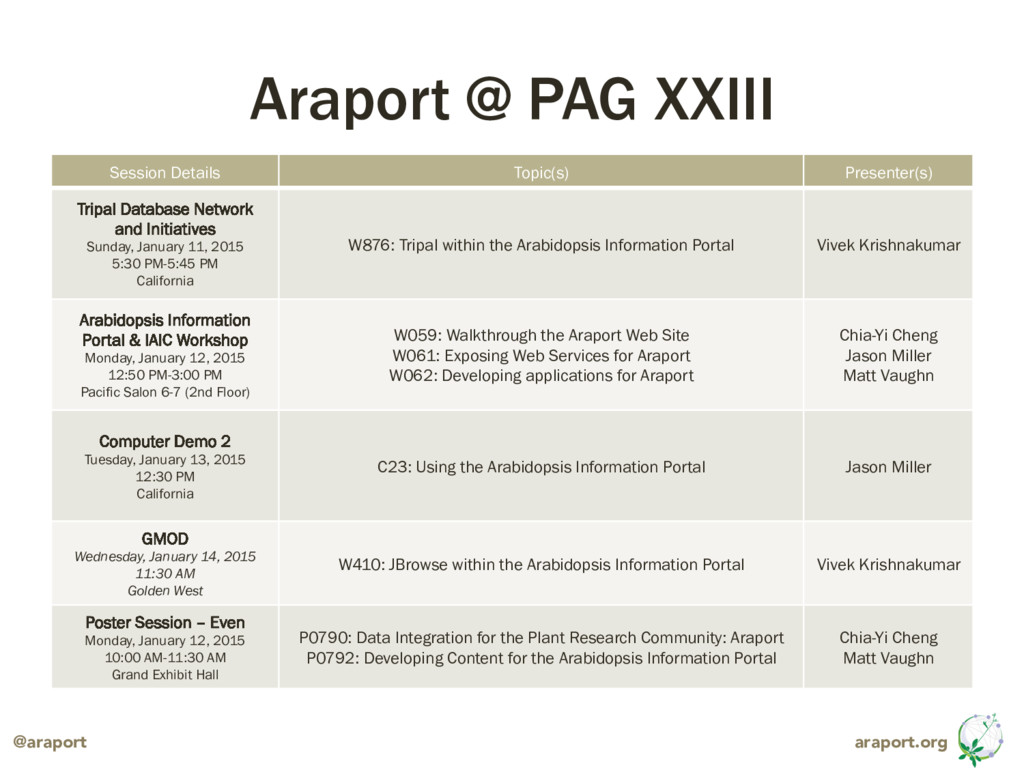
Presentation regarding Tripal and its adoption by the Araport project, made at Tripal Database Network and Initiatives workshop the on 11 Jan 2015, conducted at PAG XXIII in San Diego, CA.
Presented by Vivek Krishnakumar
{kind=link}
{kind=link}
{kind=link}
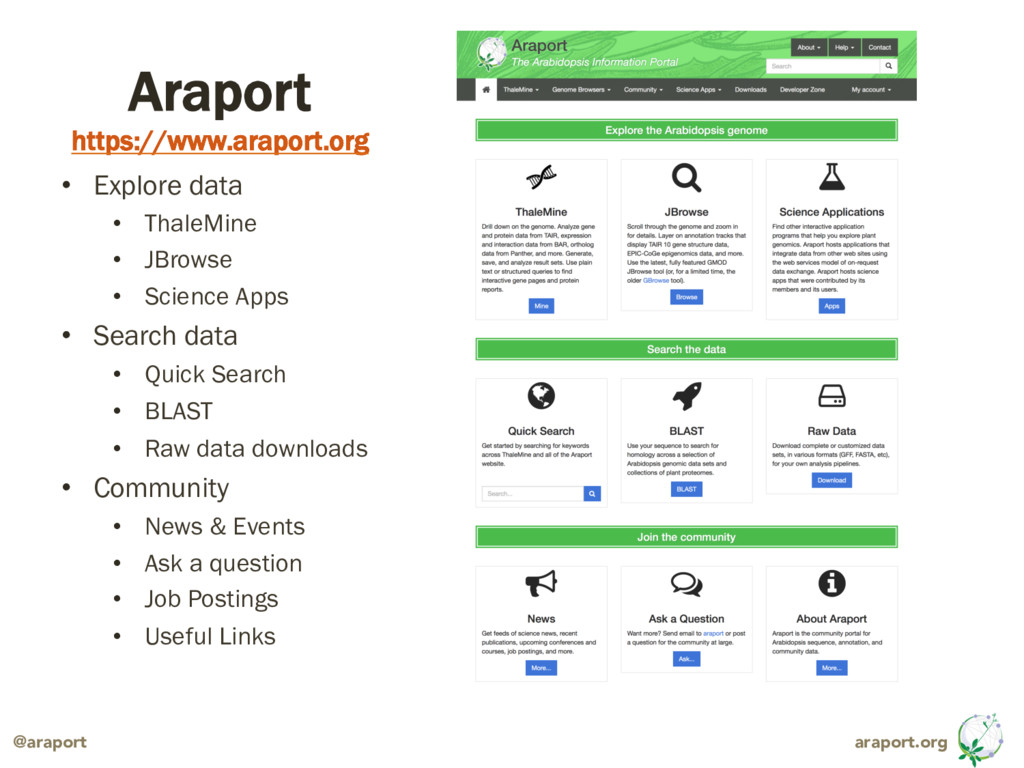{kind=link}
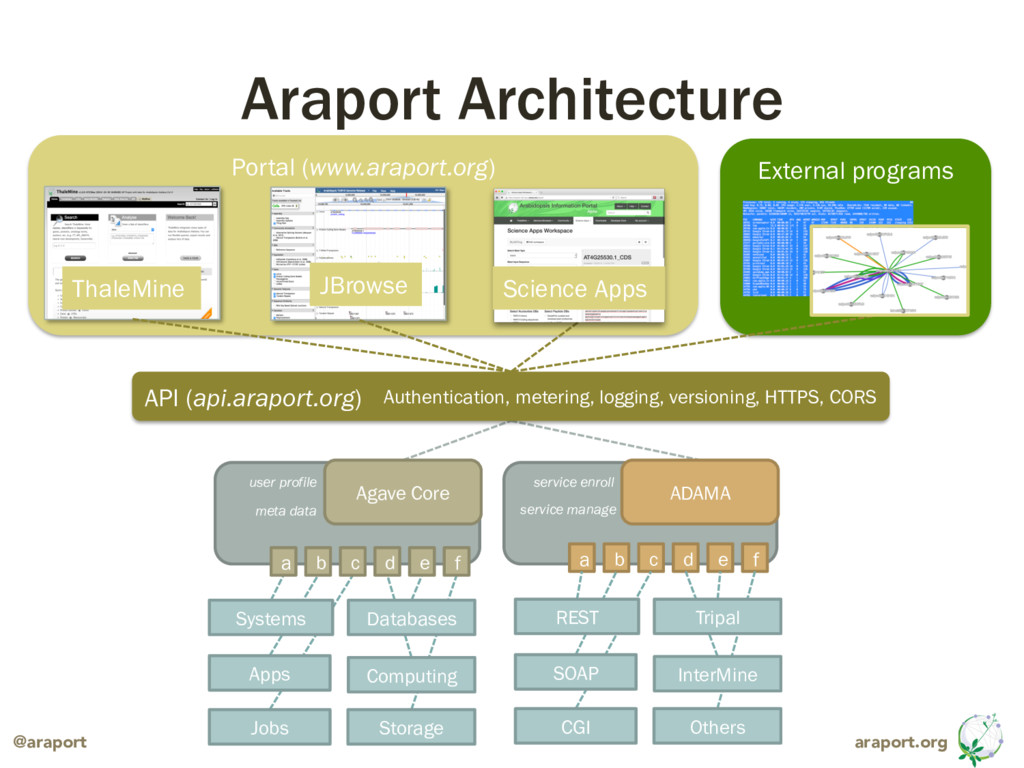{kind=link}
{kind=link}
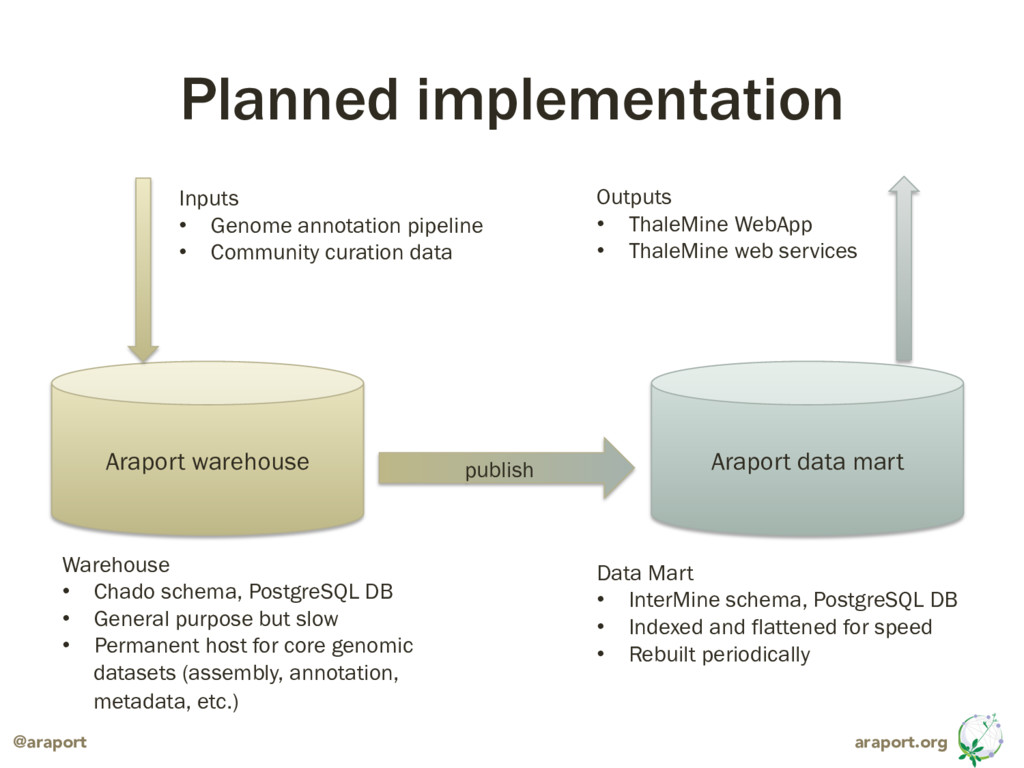{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
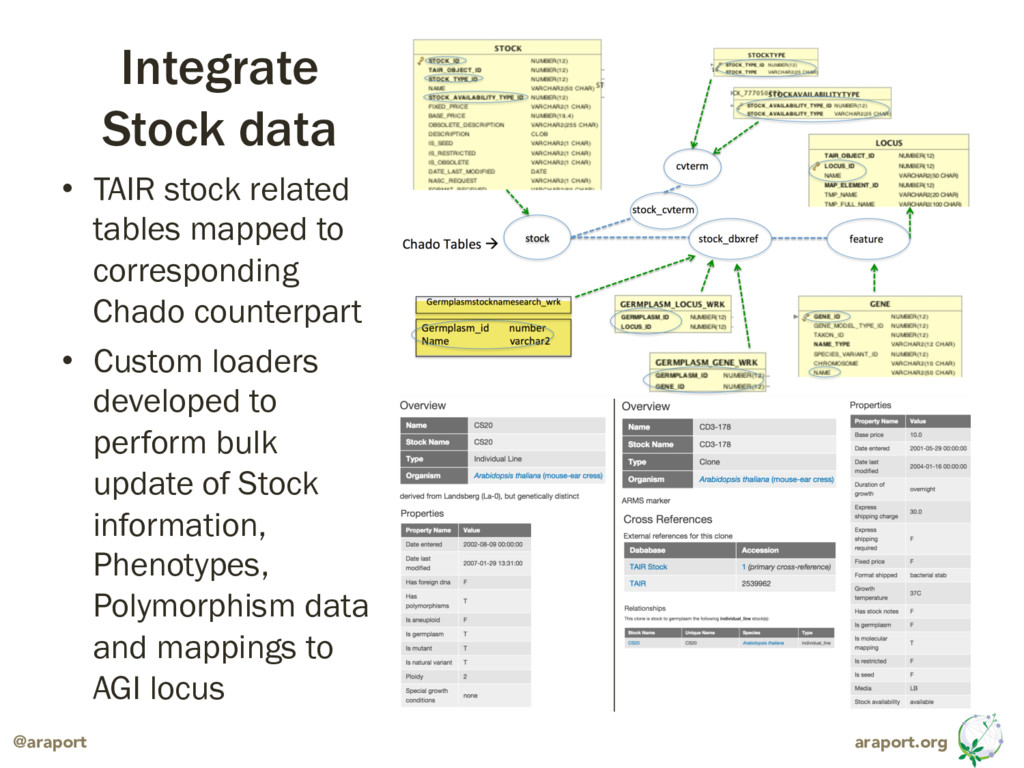{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}