/ AI Integration Unit Lead • Principal Engineer / AI Integration Unit Lead ヌーラボで AI 機能の企画・設計・実装をリード • Datadog Design Partner LLM o11y・Security プレビュー機能の先行利用・フィードバック • Mastra Contributor 業務で使う OSS への貢献を大切に SPEAKER 02 —
$20 で使い放題 ・Claude Pro ・ChatGPT Plus ・Google AI Pro LLM プロバイダ側の経済圏 ≠ ギャップ 提供者現実 従量で積み上がる ・入力トークン課金 ・出力トークン課金 ・モデル別単価 AI エージェント提供者の世界 このギャップこそ、コスト管理章の出発点。 22 —
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
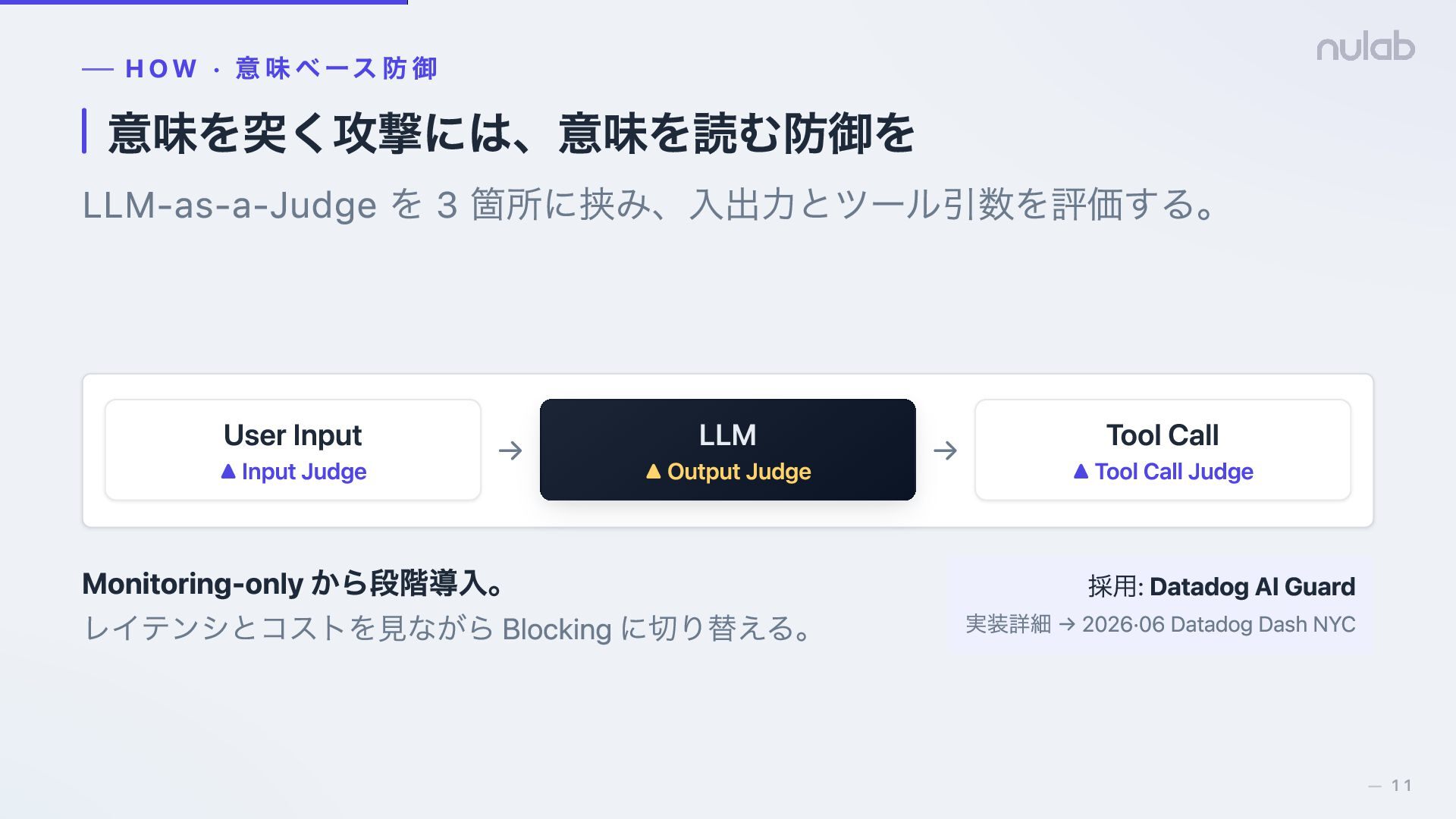{kind=link}
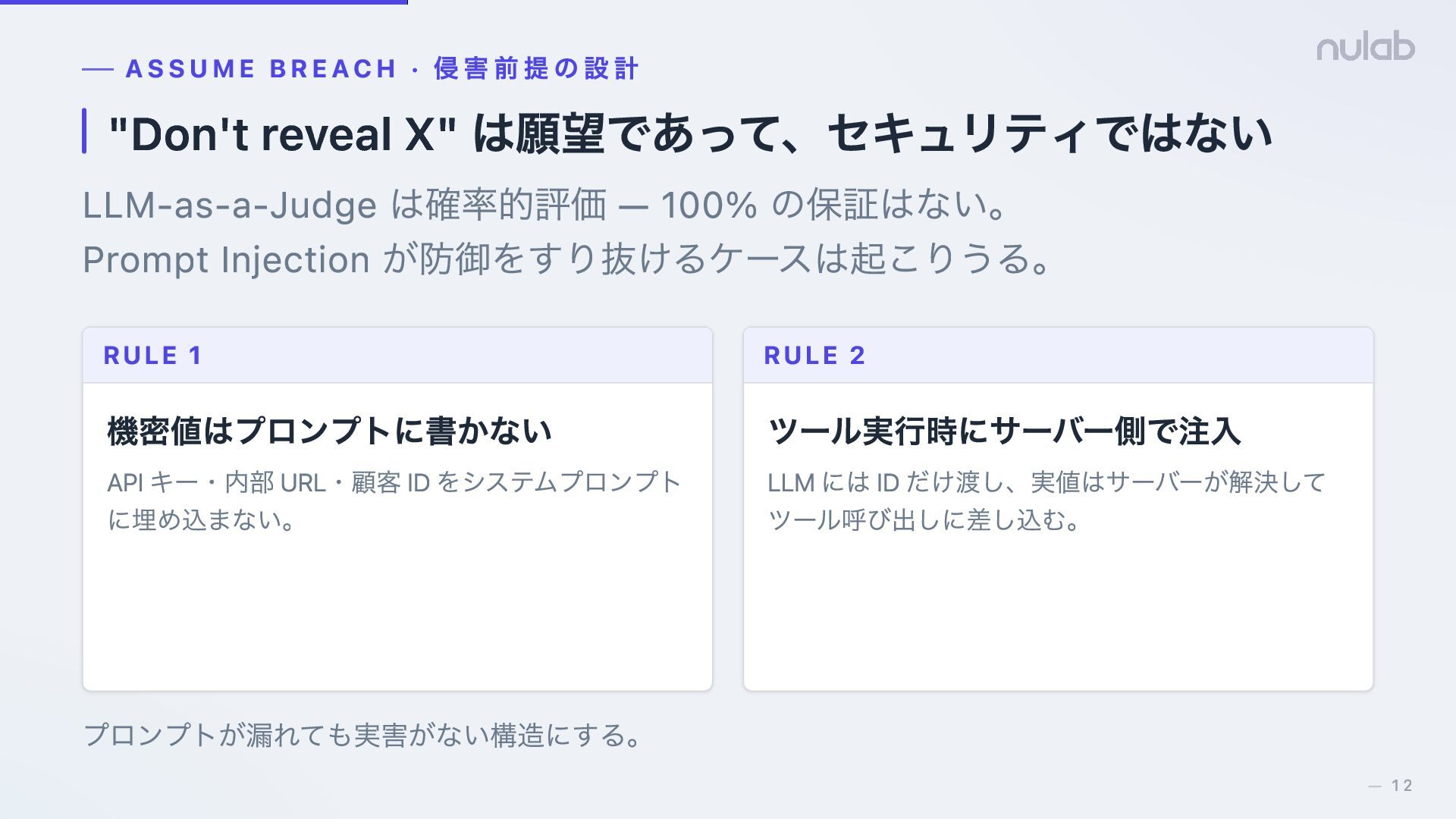{kind=link}
{kind=link}
{kind=link}
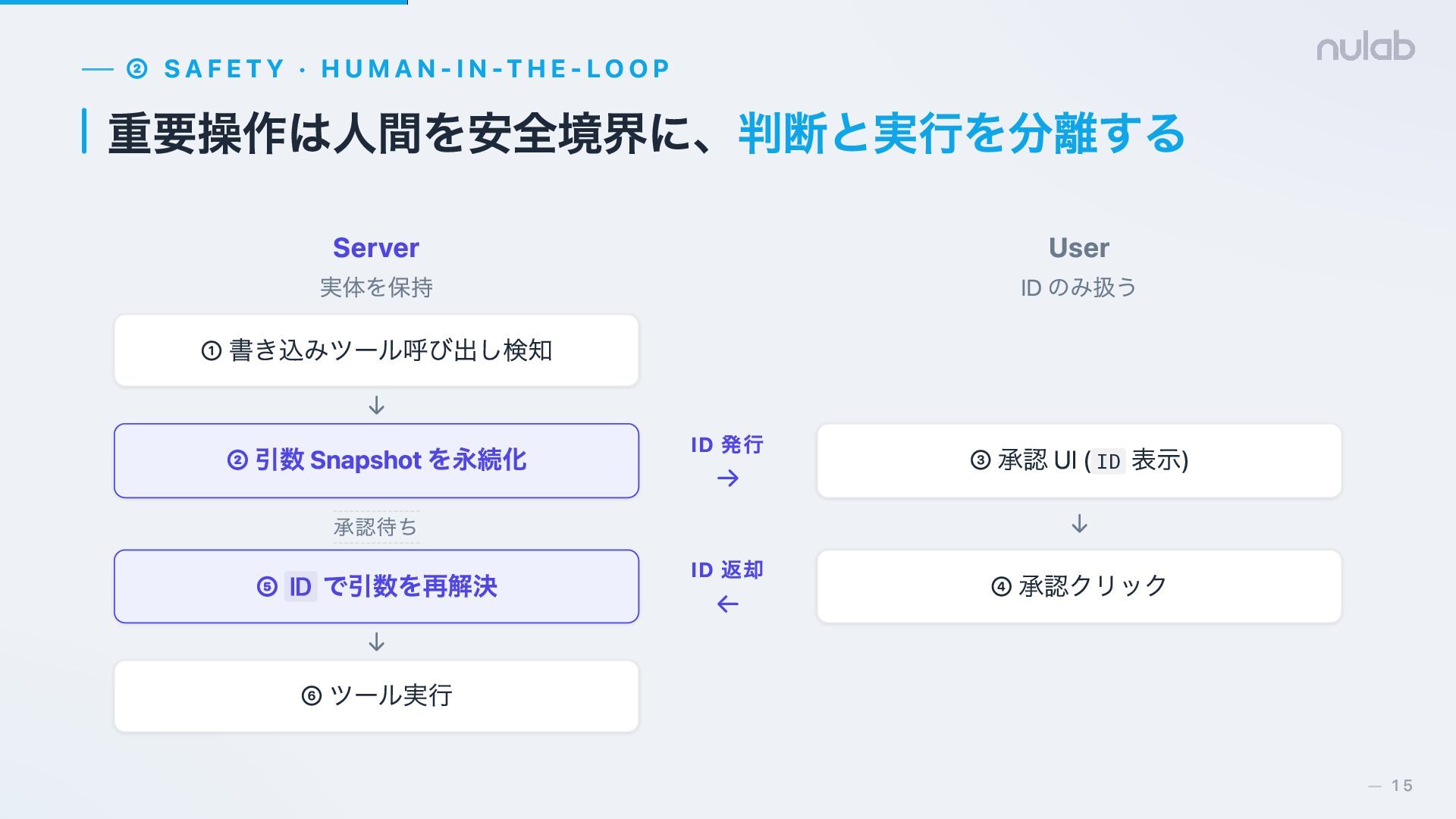{kind=link}
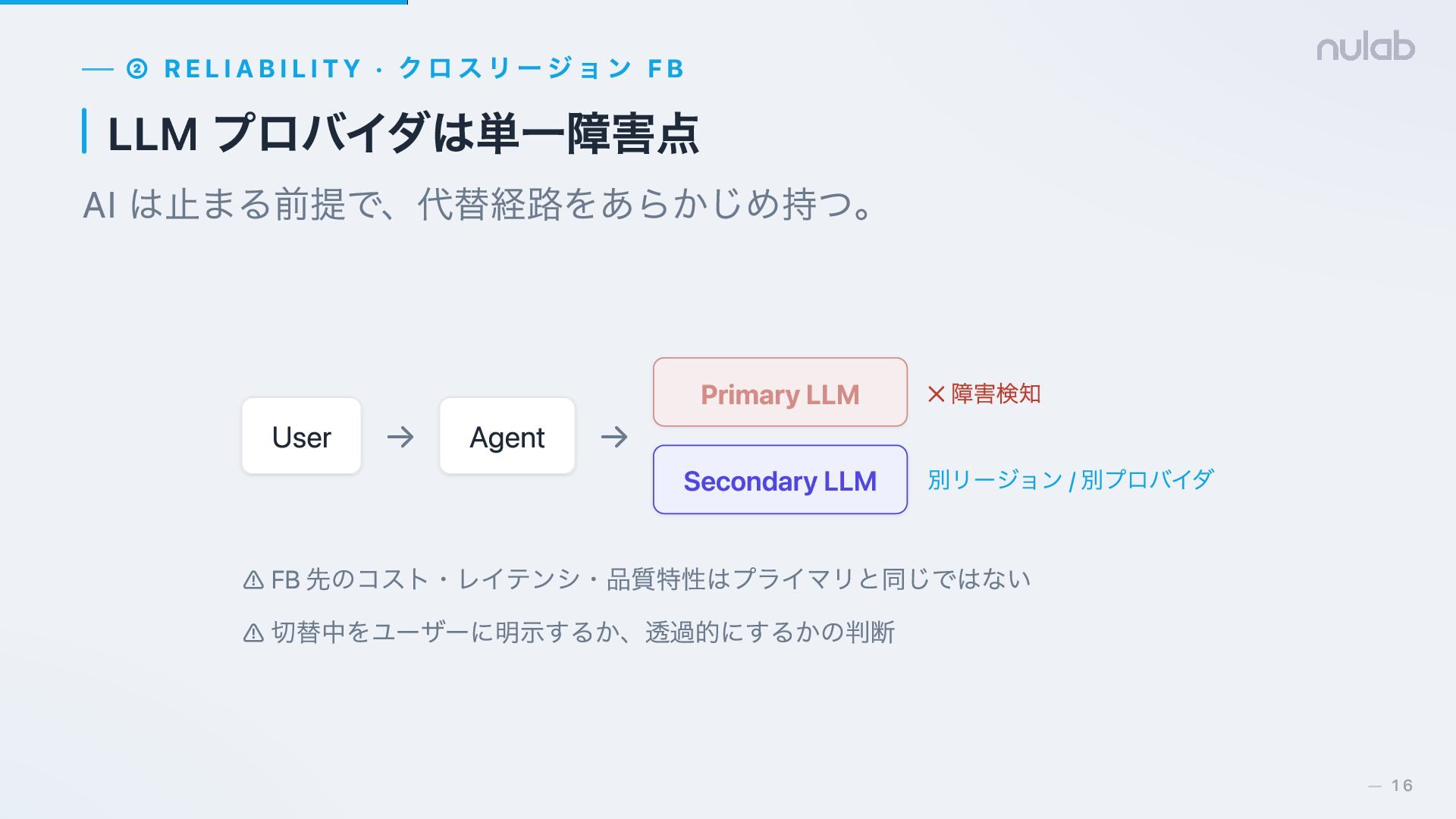{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
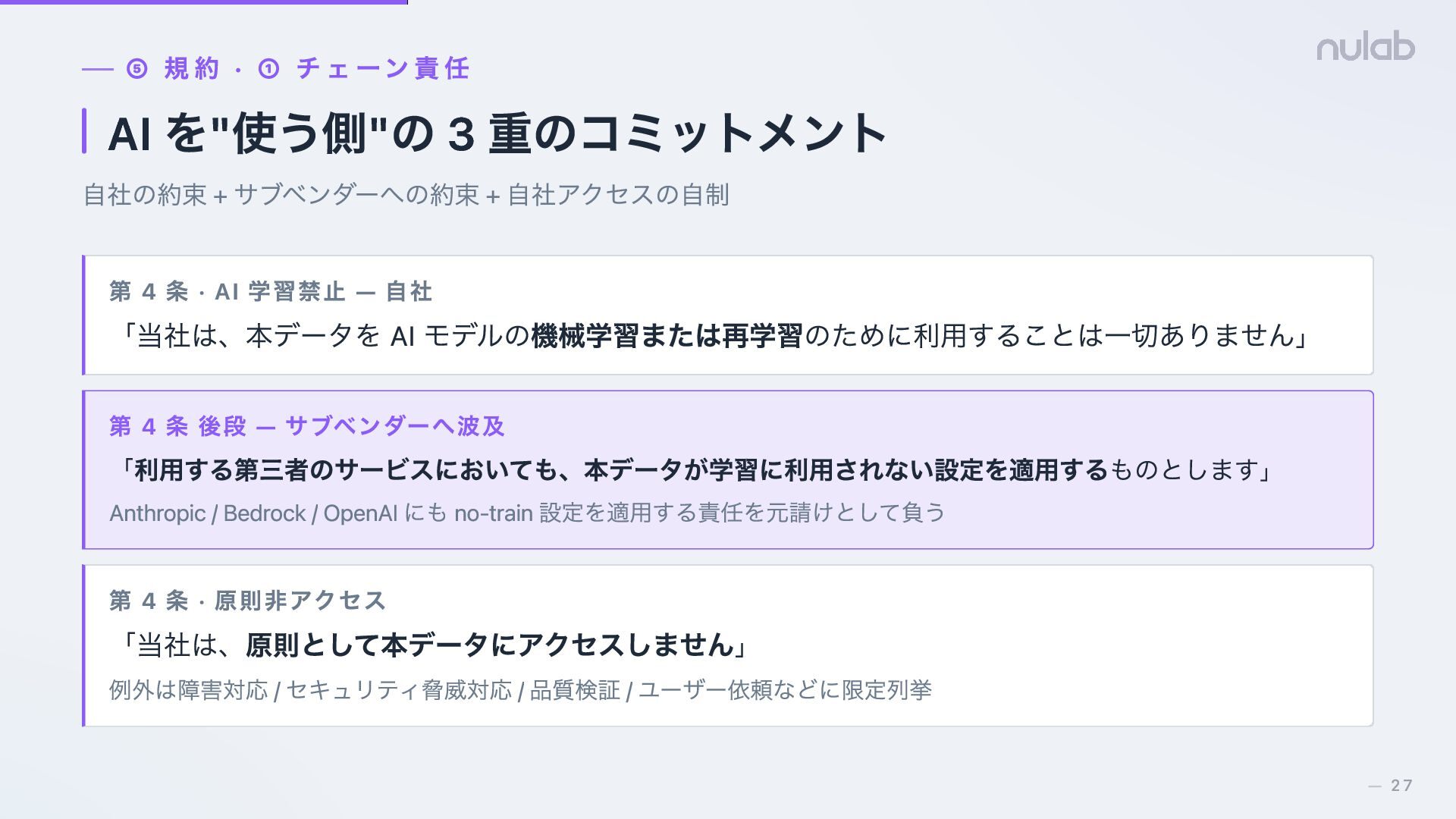{kind=link}
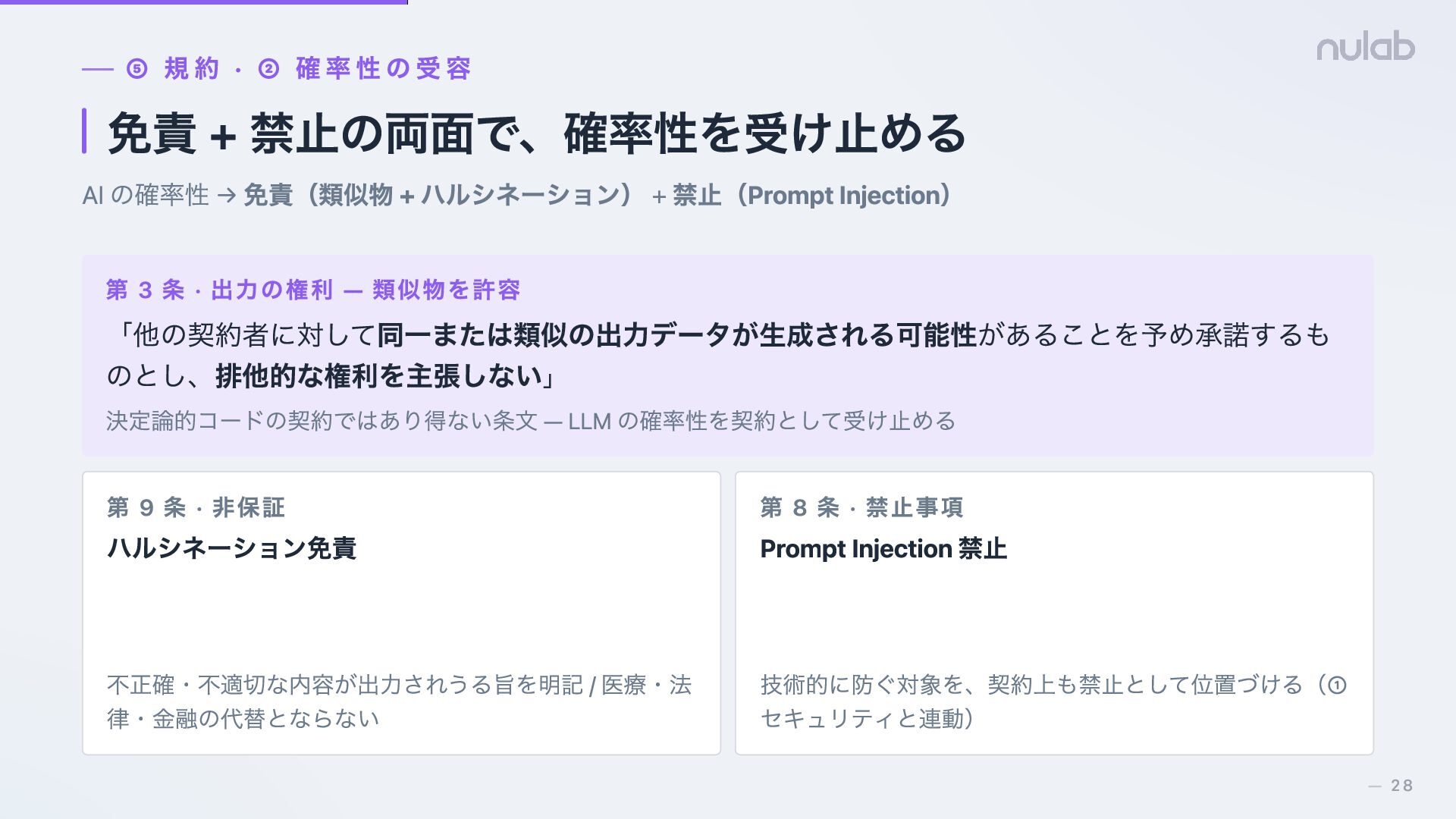{kind=link}
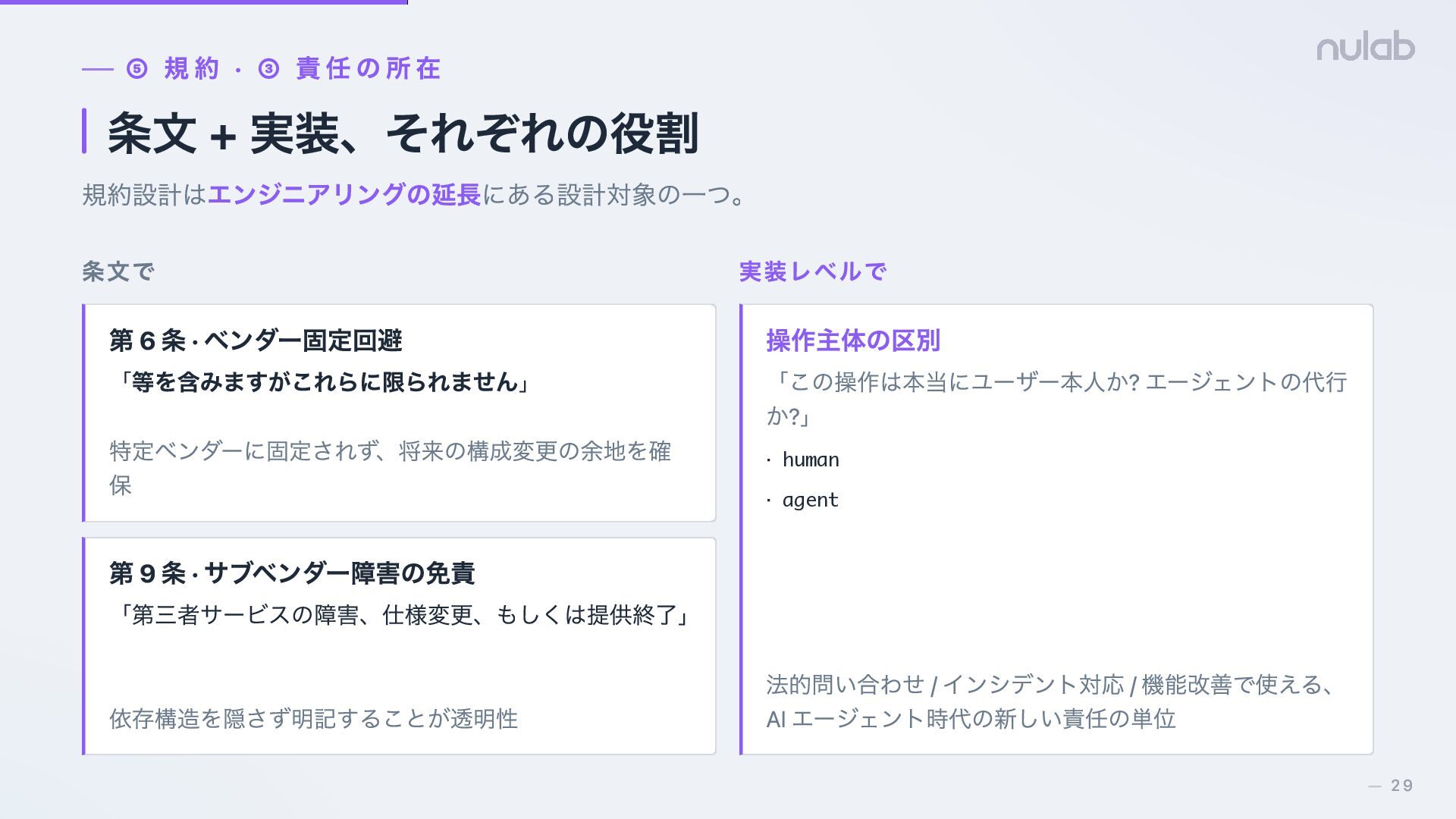{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}