ゼミ発表用のサポートベクターマシンの資料です.
主に以下の書籍を参考にしました:
Aurélien Géron, Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, O'reilly Media, 2017
C. M. ビショップ,パターン認識と機械学習 下 ベイズ理論による統計的予測(元田浩ほか訳),丸善出版,2012
赤穂昭太郎,カーネル多変量解析 非線形データ解析の新しい展開,岩波書店,2008
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
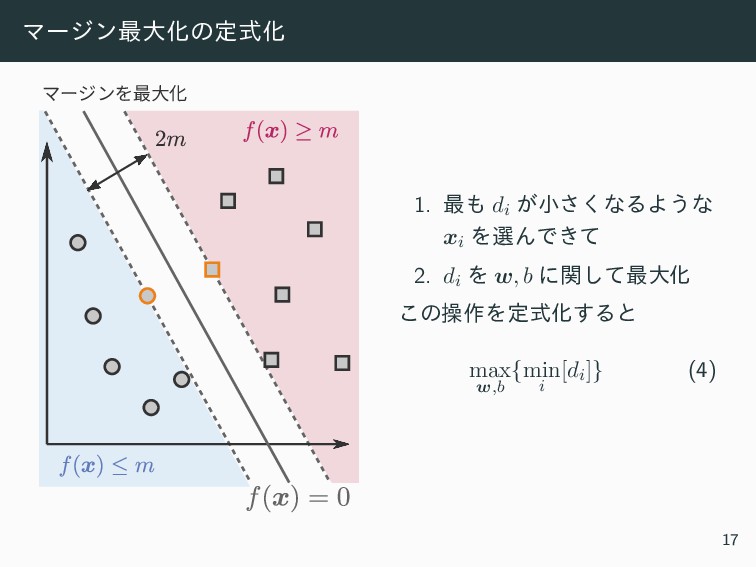
![Ϛʔδϯ࠷େԽͷ؆ུԽ ࣜ (4) Λมܗ͢Δͱ max w,b {min i [di]} =](https://files.speakerdeck.com/presentations/8a21ba84dead40c2922d54f152609ec0/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
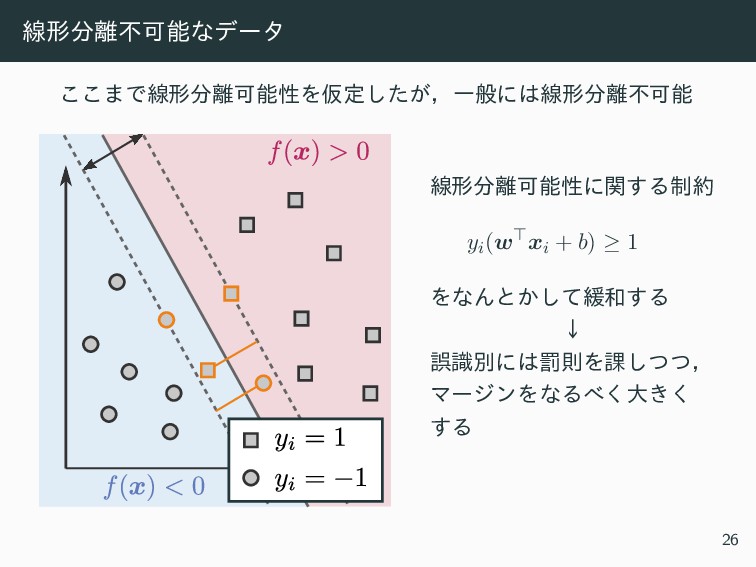{kind=link}
{kind=link}
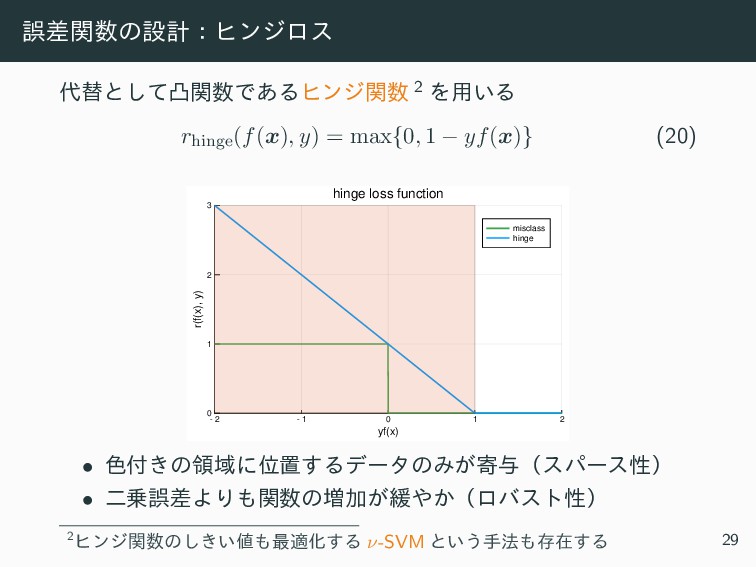
![ޡࠩؔͷઃܭɿූ߸ؔͷ ·ͣࢥ͍ͭ͘ޡࠩؔූ߸ؔΛ༻͍ͨ rmisclass(f(x), y) = 1 − sgn[yf(x)] 2 (19)](https://files.speakerdeck.com/presentations/8a21ba84dead40c2922d54f152609ec0/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
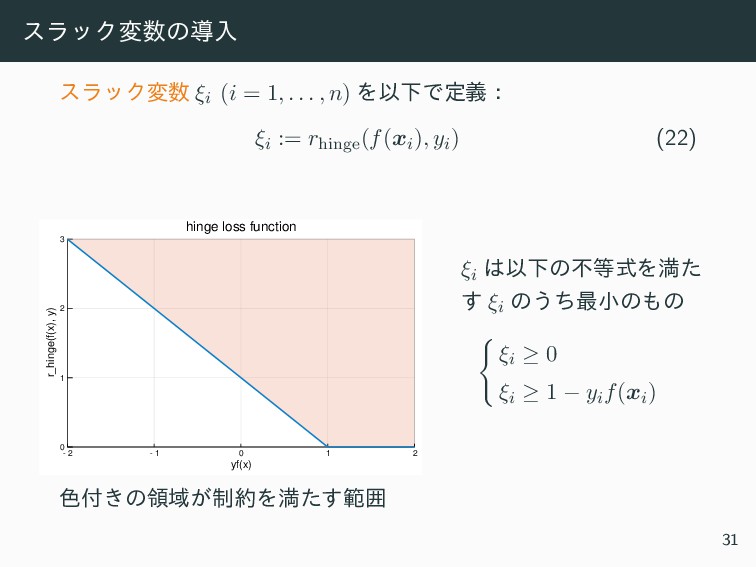{kind=link}
{kind=link}
{kind=link}
{kind=link}
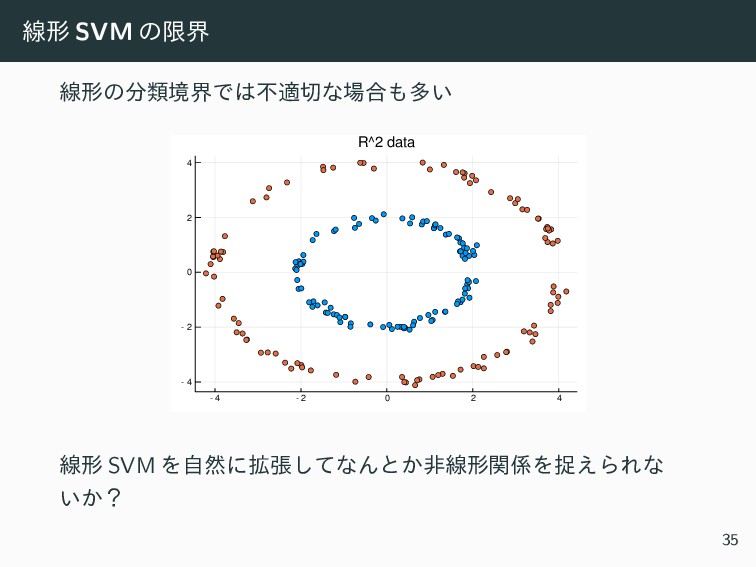{kind=link}
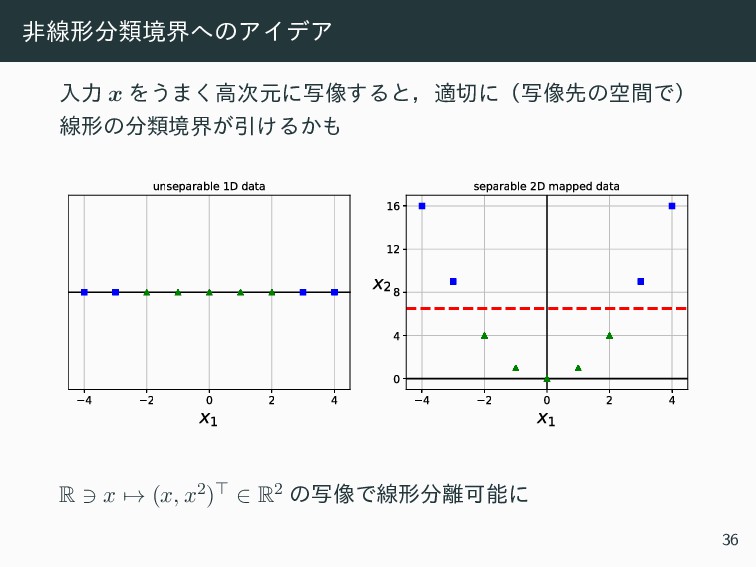{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
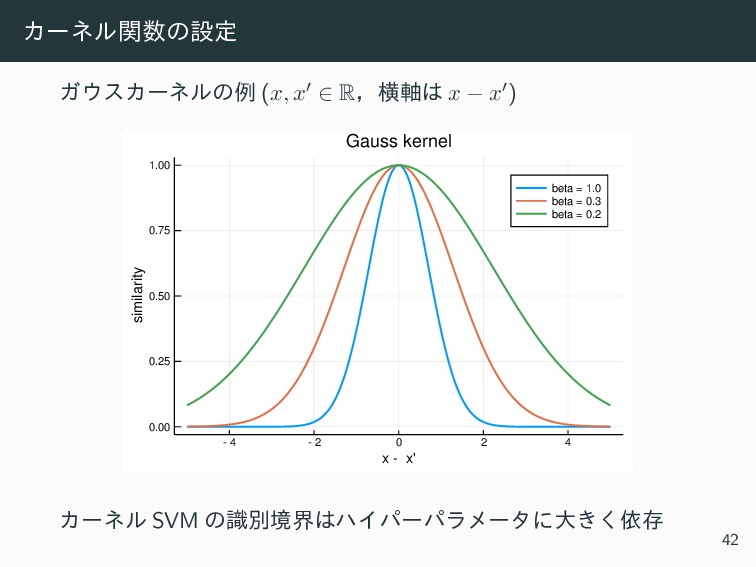{kind=link}
{kind=link}
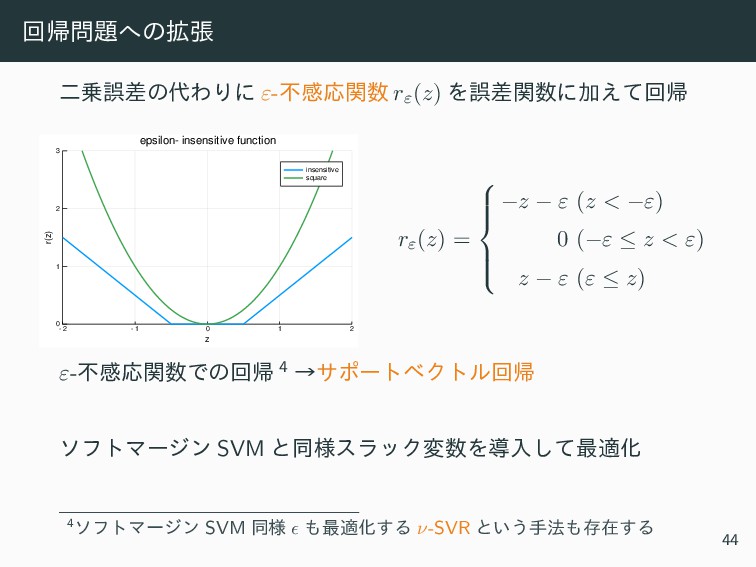{kind=link}
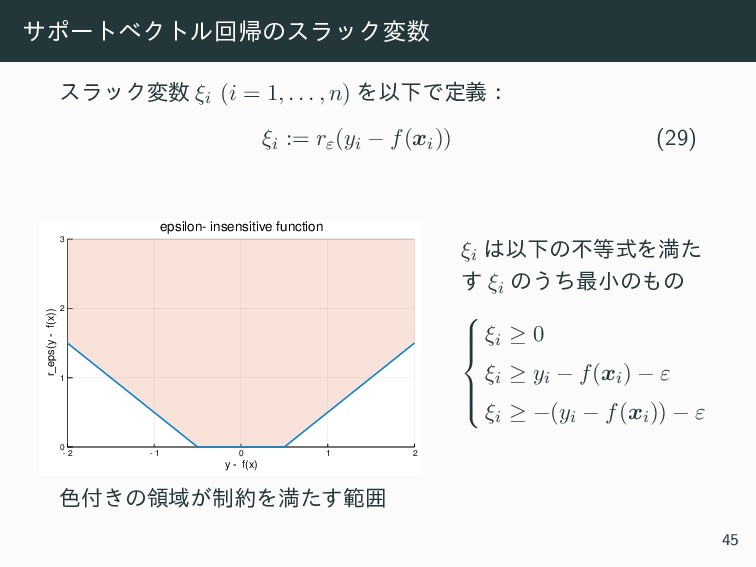{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ࢀߟจݙ I [1] Aur´ elien G´ eron, Hands-On Machine Learning](https://files.speakerdeck.com/presentations/8a21ba84dead40c2922d54f152609ec0/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}