Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Tutorial on Migrating Phase Field Codes to GPUs
Search
Daniel Wheeler
July 21, 2022
Science
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Tutorial on Migrating Phase Field Codes to GPUs
Daniel Wheeler
July 21, 2022
More Decks by Daniel Wheeler
See All by Daniel Wheeler
Semi-supervised Learning Approaches For Microstructure Classification
wd15
0
160
Deep Materials Informatics: Illustrative Applications of Deep Learning in Materials Science
wd15
0
280
Fitting Free Energies with Neural Networks
wd15
0
170
SymPhas: Symbolic Algebra for Phase-Field Simulations
wd15
0
250
PFHUB REIMPLEMENTATION FOR FAIR DATA COLLECTION
wd15
0
140
Preparing for Exascale Phase-Field Simulations: Phase-Field Modeling in ExaAM and AEOLUS
wd15
0
180
Selected Highlights of Accelerated Microstructure Design Using the High Performance Materials Simulation Framework Pace3D
wd15
0
180
Phase Field Methods + FEniCS/Firedrake
wd15
0
1.2k
Phase Field Modeling with COMSOL Multiphysics
wd15
0
790
Other Decks in Science
See All in Science
データベース09: 実体関連モデル上の一貫性制約
trycycle
PRO
0
1.4k
水耕栽培:古代の知恵から宇宙農業まで
grow_design_lab
0
150
JSAI2026企画セッションKS-14 インタビュー集『⼈⼯知能と哲学と四つの問い』が提起する⼈⼯知能のこれからの課題 趣旨説明 / JSAI2026 Special Session: A Collection of Interviews, “Artificial Intelligence, Philosophy, and Four Questions”
ykiyota
0
370
機械学習 - 授業概要
trycycle
PRO
0
550
データベース03: 関係データモデル
trycycle
PRO
1
580
共生概念の整理と AIアライメントの構想
hiroakihamada
0
230
検索と推論タスクに関する論文の紹介
ynakano
1
250
東北地方における過去20年間の降水量の変化
naokimuroki
1
320
MATSUO Makiko
genomethica
0
170
AIPシンポジウム 2025年度 成果報告会 「因果推論チーム」
sshimizu2006
3
550
J-STAGE全文XML登載必須化について
xspa2012
0
1.1k
因果推論と機械学習
sshimizu2006
1
1.2k
Featured
See All Featured
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
670
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
400
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Navigating Weather and Climate Data
rabernat
0
280
Building the Perfect Custom Keyboard
takai
2
810
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
Transcript
Tutorial on Migrating Phase Field Codes to GPUs Jin Zhang
Voorhees Group, Northwestern University May 11, 2022
Outline The GPU hardware Brief introduction to CUDA Example: Allen-Cahn
equation The standard way: CUDA The ‘easy’ way: Standard C++ 2 / 22
The hardware: GPU 3 / 22
The hardware: GPU 3 / 22
The hardware: GPU 3 / 22
The hardware: GPU 3 / 22
The hardware: GPU 3 / 22
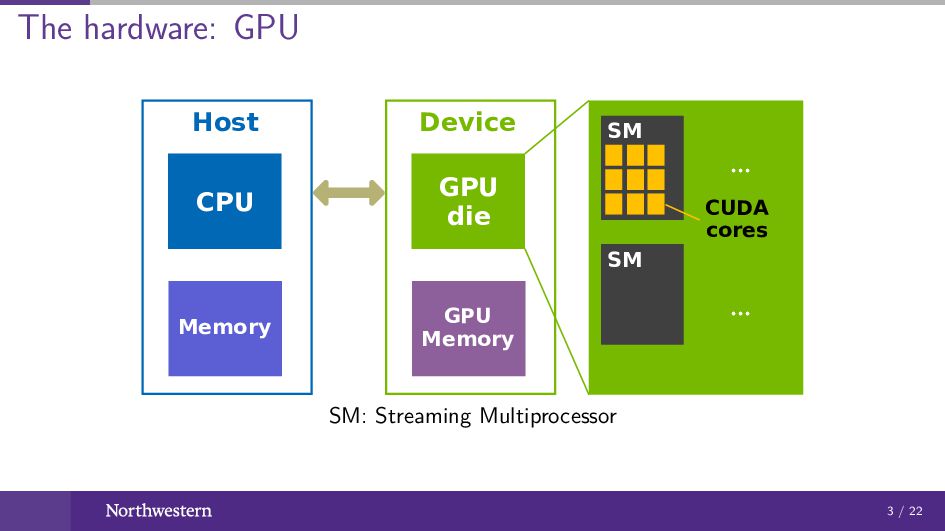
The hardware: GPU CPU Memory Host GPU die GPU Memory
Device ... ... SM SM ... ... CUDA cores SM: Streaming Multiprocessor 3 / 22
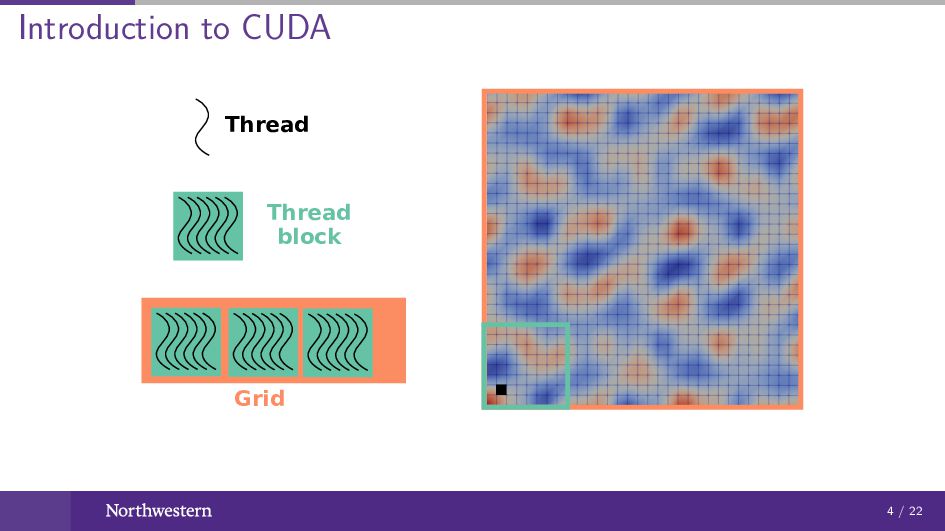
Introduction to CUDA Thread Thread block Grid 4 / 22
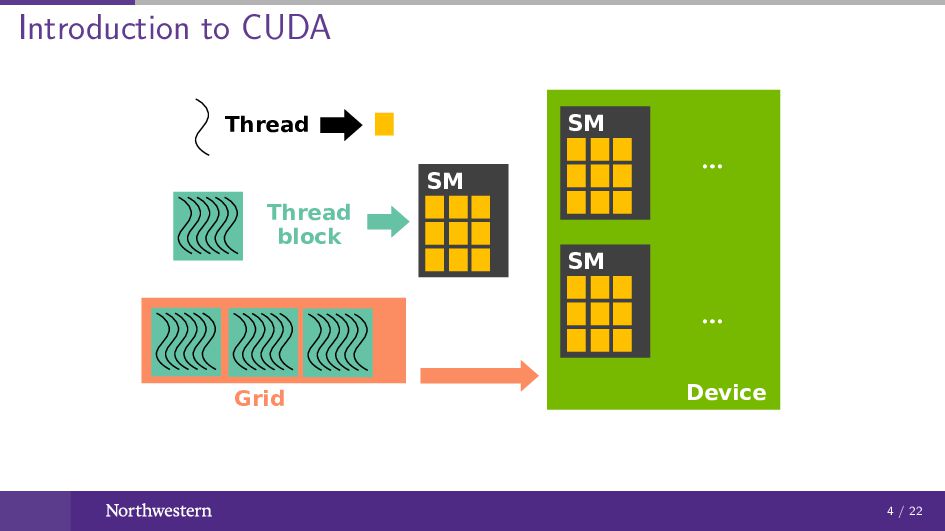
Introduction to CUDA Thread Thread block Grid ... ... SM
... ... Device SM SM 4 / 22
Introduction to CUDA CUDA development tools Need an NVIDIA GPU
Install NVIDIA Driver Install compiler: CUDA Toolkit/NVIDIA HPC SDK 4 / 22
Phase field Allen-Cahn equation ∂u ∂t = 2∇2u − u(1
− u)(1 − 2u) Discretization (2D) ∂u ∂t ij = u(n+1) ij − u(n) ij ∆t + O(∆t) (∇2u)ij = u(n) i+1j + u(n) i−1j + u(n) ij+1 + u(n) ij−1 − 4u(n) ij ∆x2 + O(∆x2) 5 / 22
Phase field Allen-Cahn equation ∂u ∂t = 2∇2u − u(1
− u)(1 − 2u) Discretization (2D) unew ij = uij + ∆t∆uij where ∆uij = 2 ui+1j + ui−1j + uij+1 + uij−1 − 4uij ∆x2 − gij gij = uij(1 − uij)(1 − 2uij) 5 / 22
Our task Implement a CPU code Modify it to run
on GPU 6 / 22
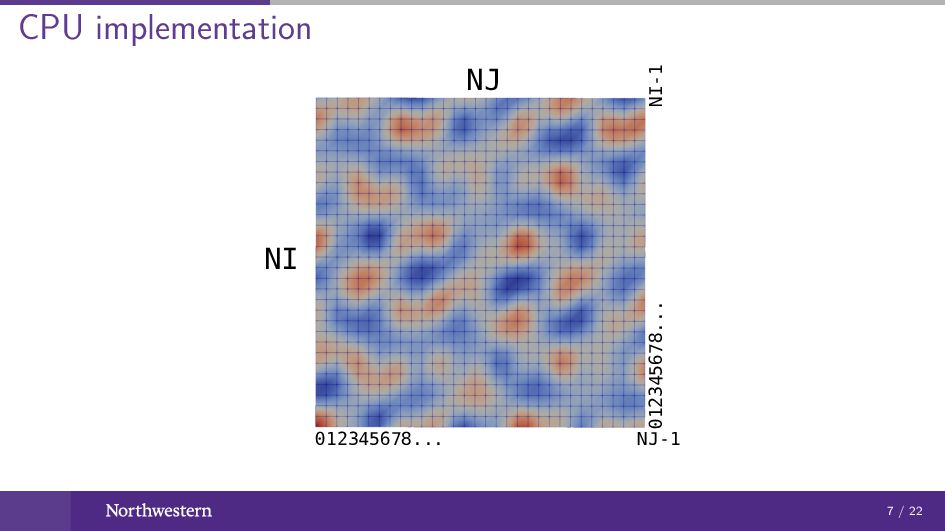
CPU implementation NJ NI 012345678... NJ-1 012345678... NI-1 7 /
22
CPU implementation 1 int main(int argc , char *argv [])
2 { 3 double *u, *u1; // order parameter 4 u = (double *)malloc(NI*NJ * sizeof(double)); // old value 5 u1 = (double *)malloc(NI*NJ * sizeof(double)); // new value 6 // ... 7 ic(u); // initial condition 8 for (long t=1L; t<=n; t++){ // loop timesteps 9 sweep(u, u1 , e, dt); // u1 = u + du 10 double *tmp = u1; u1 = u; u = tmp; // u <-> u1 11 } 12 } 8 / 22
CPU implementation 1 void sweep(double *u, double *u1 , double
e, double dt){ 2 for (int i=0;i<NI;i++){ 3 for (int j=0;j<NJ;j++){ 4 // periodic boundary condition 5 int im = (i< 1) ? NI -1 : i-1; // i-1 6 int ip = (i>NI -2) ? 0 : i+1; // i+1 7 int jm = (j< 1) ? NJ -1 : j-1; // j-1 8 int jp = (j>NJ -2) ? 0 : j+1; // j+1 9 double g = u[i,j]*(1.0-u[i,j])*(1.0 -2.0*u[i,j]); 10 double du = e*(u[im ,j]+u[ip ,j]+u[i,jm]+u[i,jp] -4.0*u[i,j]) - g; 11 u1[i,j] = u[i,j] + du*dt; 12 } 13 } 14 } System size NI×NJ, Index: 0 1 2 N-1 N-2 9 / 22
CPU implementation 1 void sweep(double *u, double *u1 , double
e, double dt){ 2 for (int i=0;i<NI;i++){ 3 for (int j=0;j<NJ;j++){ 4 // periodic boundary condition 5 int im = (i< 1) ? NI -1 : i-1; // i-1 6 int ip = (i>NI -2) ? 0 : i+1; // i+1 7 int jm = (j< 1) ? NJ -1 : j-1; // j-1 8 int jp = (j>NJ -2) ? 0 : j+1; // j+1 9 double g = u[i,j]*(1.0-u[i,j])*(1.0 -2.0*u[i,j]); 10 double du = e*(u[im ,j]+u[ip ,j]+u[i,jm]+u[i,jp] -4.0*u[i,j]) - g; 11 u1[i,j] = u[i,j] + du*dt; 12 } 13 } 14 } Index: 0 1 2 N-1 N-2 Neighbors: i,j i m ,j i p ,j i,j m i,j p 10 / 22
CPU implementation 1 void sweep(double *u, double *u1 , double
e, double dt){ 2 for (int i=0;i<NI;i++){ 3 for (int j=0;j<NJ;j++){ 4 // periodic boundary condition 5 int im = (i< 1) ? NI -1 : i-1; // i-1 6 int ip = (i>NI -2) ? 0 : i+1; // i+1 7 int jm = (j< 1) ? NJ -1 : j-1; // j-1 8 int jp = (j>NJ -2) ? 0 : j+1; // j+1 9 double g = u[i,j]*(1.0-u[i,j])*(1.0 -2.0*u[i,j]); 10 double du = e*(u[im ,j]+u[ip ,j]+u[i,jm]+u[i,jp] -4.0*u[i,j]) - g; 11 u1[i,j] = u[i,j] + du*dt; 12 } 13 } 14 } g = u(1 − u)(1 − 2u), ∆uij = 2 ∆x2 ui−1j + ui+1j + uij−1 + uij+1 − 4uij − gij 11 / 22
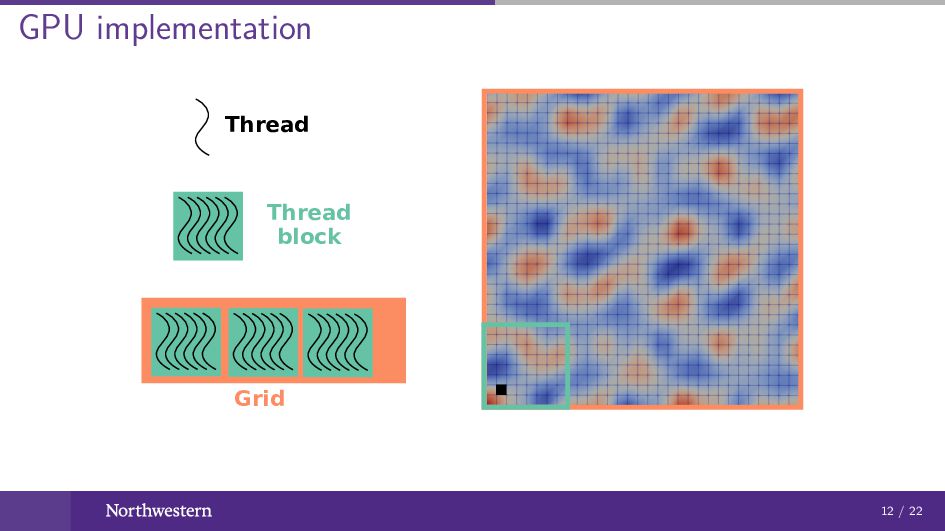
GPU implementation Thread Thread block Grid 12 / 22
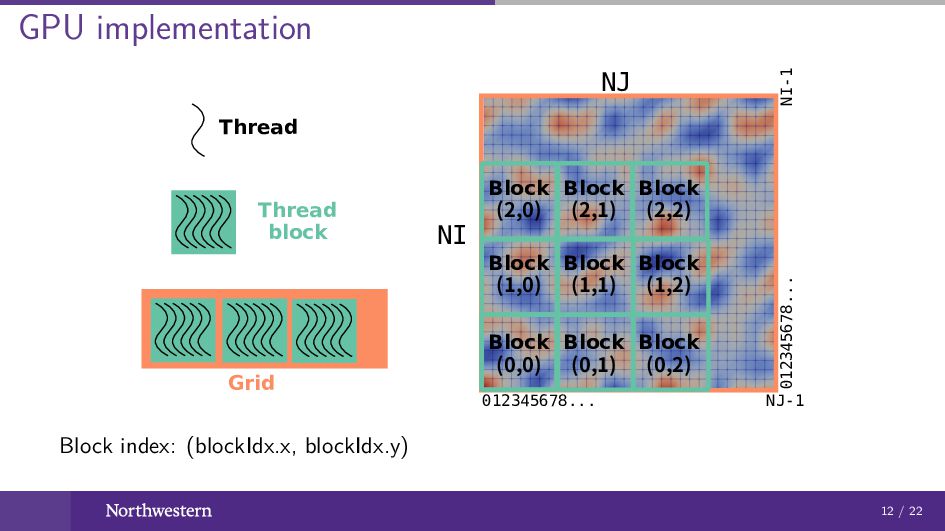
GPU implementation NJ NI 012345678... NJ-1 012345678... NI-1 Thread Thread
block Grid Block (0,0) Block (0,1) Block (0,2) Block (1,0) Block (1,1) Block (1,2) Block (2,0) Block (2,1) Block (2,2) Block index: (blockIdx.x, blockIdx.y) 12 / 22
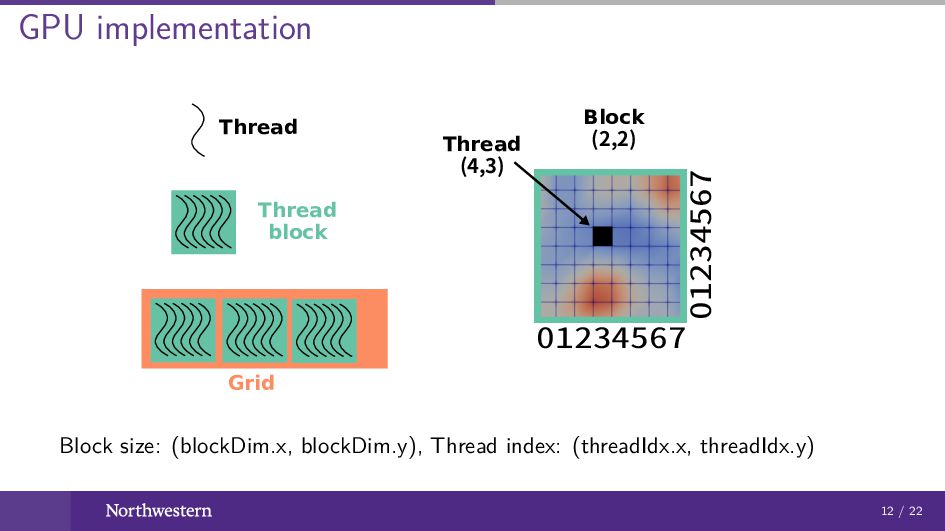
GPU implementation Thread Thread block Grid Block (2,2) 01234567 01234567
Thread (4,3) Block size: (blockDim.x, blockDim.y), Thread index: (threadIdx.x, threadIdx.y) 12 / 22
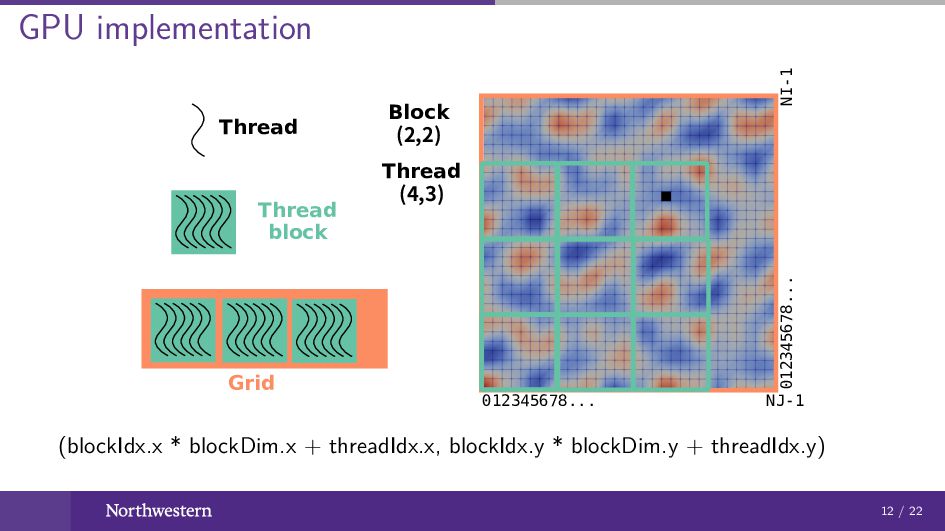
GPU implementation 012345678... NJ-1 012345678... NI-1 Thread Thread block Grid
Block (2,2) Thread (4,3) (blockIdx.x * blockDim.x + threadIdx.x, blockIdx.y * blockDim.y + threadIdx.y) 12 / 22
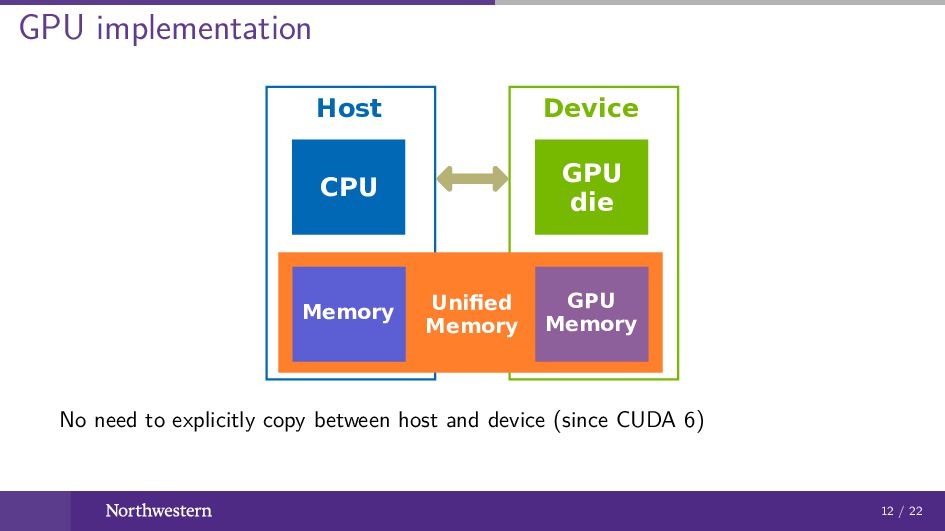
GPU implementation CPU Host GPU die Device Unified Memory Memory
GPU Memory No need to explicitly copy between host and device (since CUDA 6) 12 / 22
CUDA implementation 1 int main(int argc , char *argv [])
2 { 3 double *u, *u1; // order parameter 4 cudaMallocManaged ( &u, NI*NJ * sizeof(double)); // old value 5 cudaMallocManaged (&u1 , NI*NJ * sizeof(double)); // new value 6 dim3 dimBlock(BLOCK_X , BLOCK_Y); 7 dim3 dimGrid(NI/BLOCK_X , NJ/BLOCK_Y); 8 // ... 9 ic(u); // initial condition 10 for (long t=1L; t<=n; t++){ 11 sweep<<<dimGrid, dimBlock>>>(u, u1 , e, dt); 12 double *tmp = u1; u1 = u; u = tmp; // u <-> u1 13 } 14 } 13 / 22
CUDA implementation 1 __global__ 2 void sweep(double *u, double *u1
, double e, double dt){ 3 int i = blockIdx.x * blockDim.x + threadIdx.x; 4 int j = blockIdx.y * blockDim.y + threadIdx.y; 5 // periodic boundary condition 6 int im = (i< 1) ? NI -1 : i-1; // i-1 7 int ip = (i>NI -2) ? 0 : i+1; // i+1 8 int jm = (j< 1) ? NJ -1 : j-1; // j-1 9 int jp = (j>NJ -2) ? 0 : j+1; // j+1 10 11 double g = u[i,j]*(1.0-u[i,j])*(1.0 -2.0*u[i,j]); 12 double du = e*(u[im ,j]+u[ip ,j]+u[i,jm]+u[i,jp] -4.0*u[i,j]) - g; 13 u1[i,j] = u[i,j]+du*dt; 14 } 14 / 22
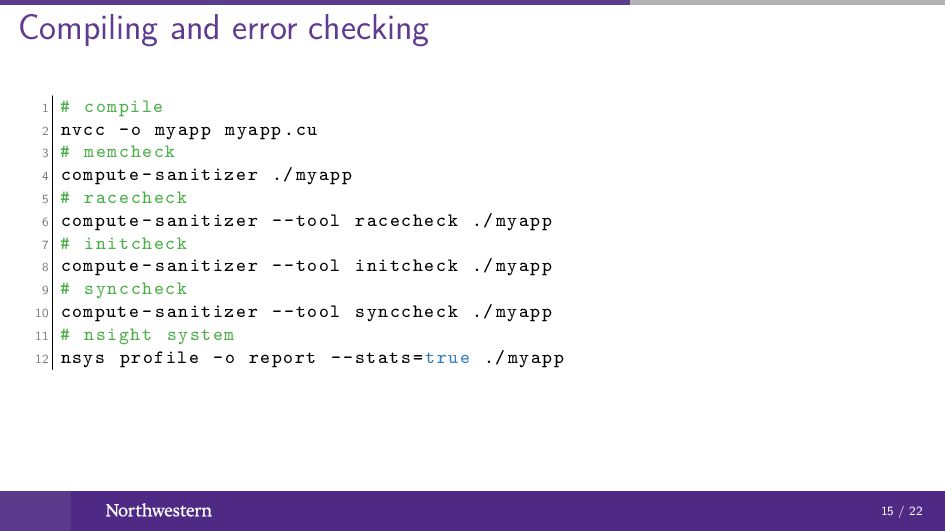
Compiling and error checking 1 # compile 2 nvcc -o
myapp myapp.cu 3 # memcheck 4 compute -sanitizer ./ myapp 5 # racecheck 6 compute -sanitizer --tool racecheck ./ myapp 7 # initcheck 8 compute -sanitizer --tool initcheck ./ myapp 9 # synccheck 10 compute -sanitizer --tool synccheck ./ myapp 11 # nsight system 12 nsys profile -o report --stats=true ./ myapp 15 / 22
Compare CPU and GPU code 1 # compile CPU code
2 gcc -o myapp myapp.c -lm 3 # compile GPU code 4 nvcc -o myapp myapp.cu 5 # compare the result 6 paraview --state=compare.pvsm 7 diff cpu.vtk gpu.vtk 8 # timing 9 time ./ myapp 16 / 22
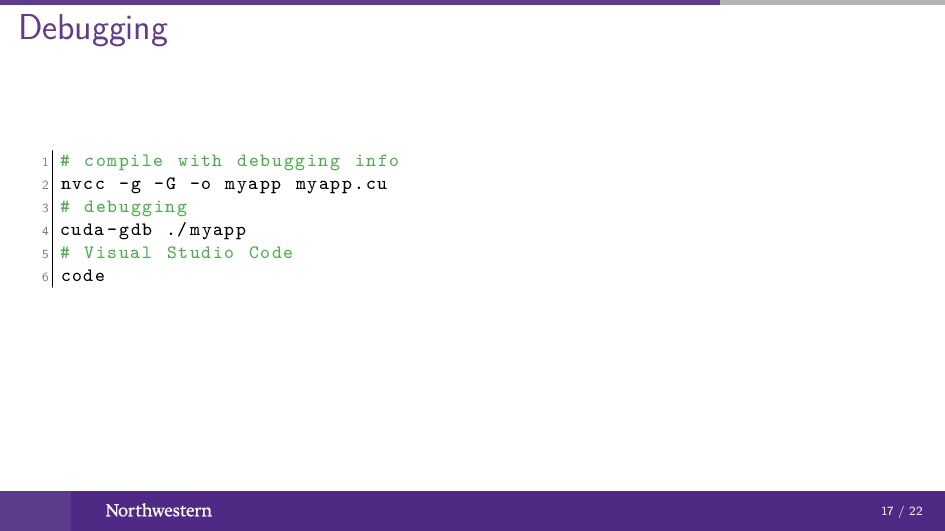
Debugging 1 # compile with debugging info 2 nvcc -g
-G -o myapp myapp.cu 3 # debugging 4 cuda -gdb ./ myapp 5 # Visual Studio Code 6 code 17 / 22
Profiling Nsight Systems blank Nsight Compute 1 # Nsignt Systems
2 nsys profile -o report --stats=true ./ myapp 3 # Nsight Compute 4 sudo ncu -k mykernel -o report ./ myapp 18 / 22
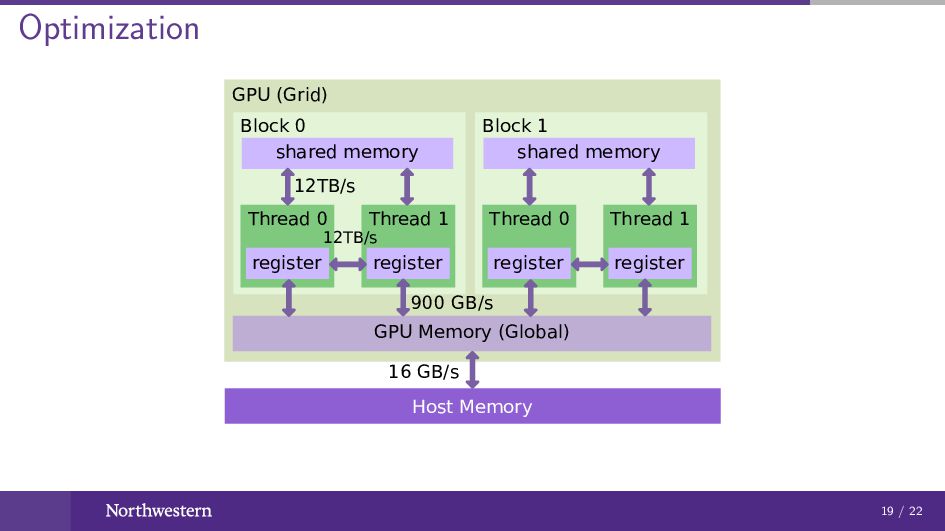
Optimization Size of a block (multiple of 32) Memory hierarchy
Contiguous memory access Parallel reduction Warp (warp-level primitives) Shared memory (bank conflict) 19 / 22
Optimization Host Memory GPU (Grid) GPU Memory (Global) 16 GB/s
Block 0 Thread 0 register shared memory Thread 1 register Block 1 Thread 0 register shared memory Thread 1 register 900 GB/s 12TB/s 12TB/s 19 / 22
Best practices Have a CPU code at first Have a
working GPU code before any optimization Use profiling tools to find the bottleneck The execution order of threads is random 20 / 22
An ‘easy’ way: Standard C++ Parallelism (C++20) 1 void sweep(double
*u, double *u1 , double e, double dt){ 2 auto v = std:: ranges :: views :: iota(0, NI*NJ); 3 std:: for_each( 4 std:: execution :: par_unseq , 5 std:: begin(v), std::end(v), 6 [=] (auto idx){ 7 int i = idx / NJ; 8 int j = idx % NJ; 9 // periodic boundary condition 10 int im = (i< 1) ? NI -1 : i-1; // i-1 11 int ip = (i>NI -2) ? 0 : i+1; // i+1 12 int jm = (j< 1) ? NJ -1 : j-1; // j-1 13 int jp = (j>NJ -2) ? 0 : j+1; // j+1 14 double g = u[i,j]*(1.0-u[i,j])*(1.0 -2.0*u[i,j]); 15 double du= e*(u[im ,j]+u[ip ,j]+u[i,jm]+u[i,jp] -4.0*u[i,j]) - g; 16 u1[i,j] = u[i,j]+du*dt; 17 }); 18 } 21 / 22
Migrating your code to GPUs If your code uses a
library, check its GPU support If you have a Mac or an AMD GPU, check OpenCL High-order time stepping Adaptive time stepping Implicit time stepping: cuSPARSE, cuSOLVER Other spatial discretization: FFT, FV, FEM 22 / 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CPU implementation 1 int main(int argc , char *argv [])](https://files.speakerdeck.com/presentations/97dab9f99f0e473bb6652156dfee2daa/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CUDA implementation 1 int main(int argc , char *argv [])](https://files.speakerdeck.com/presentations/97dab9f99f0e473bb6652156dfee2daa/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}