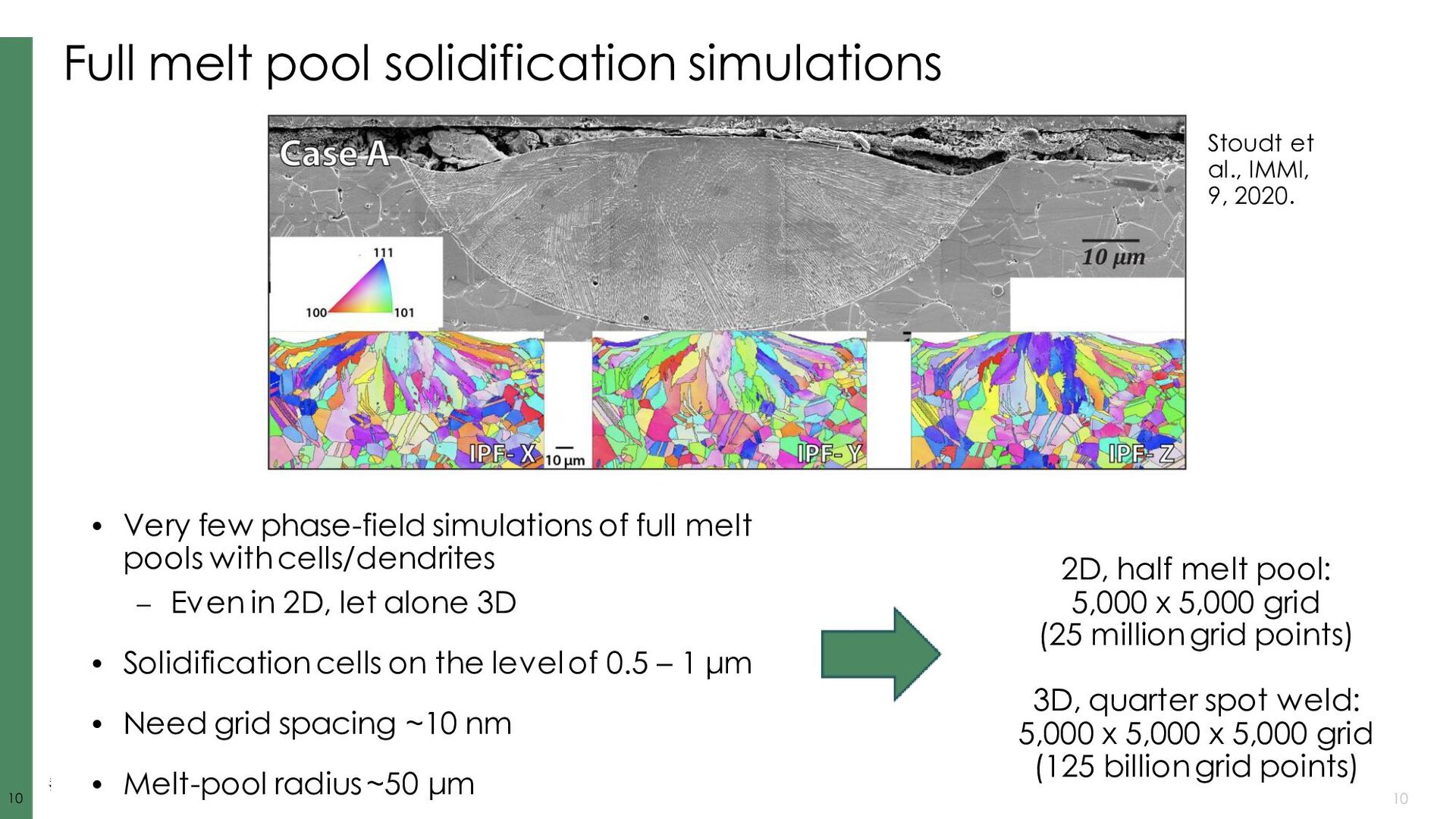
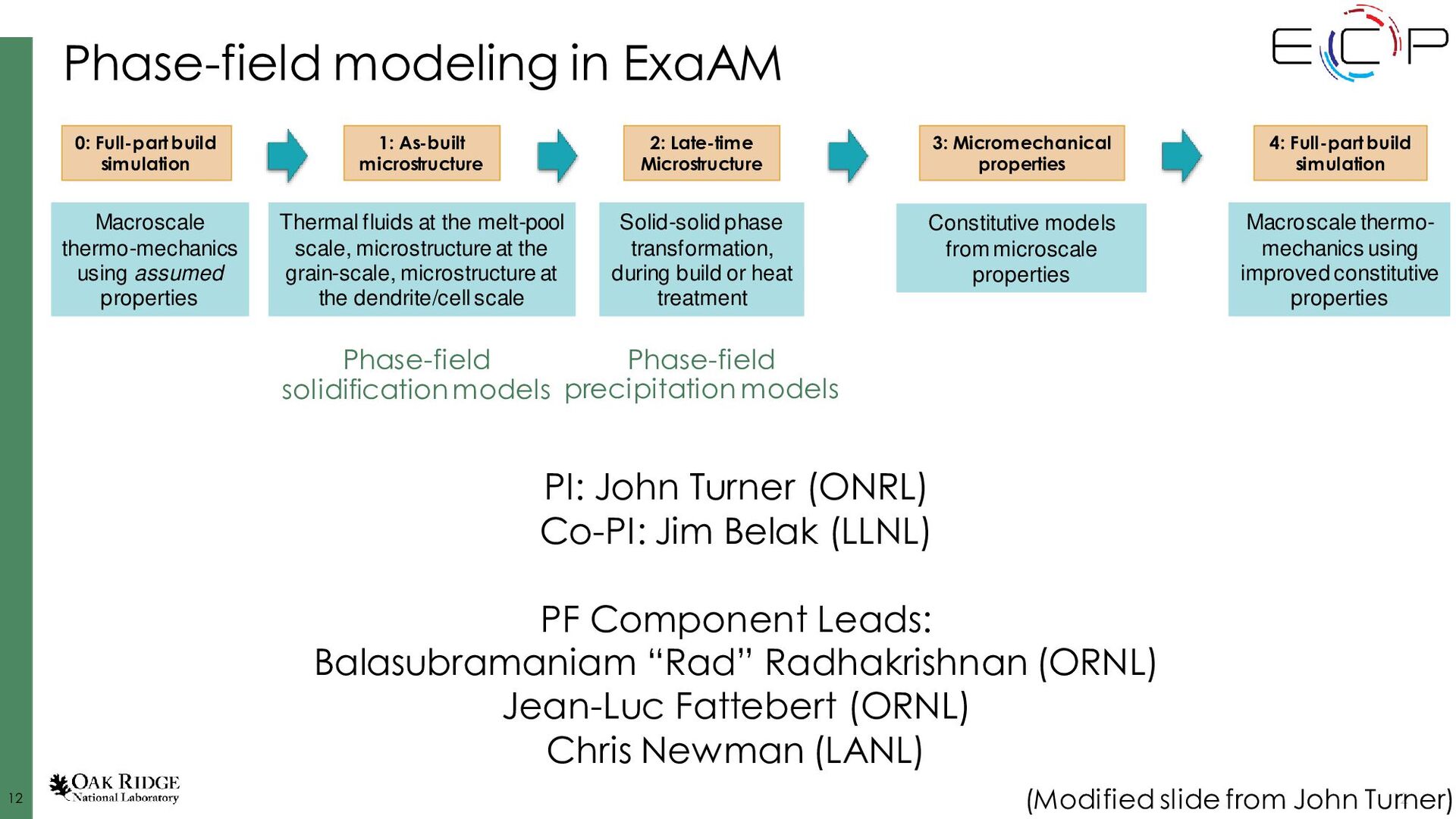
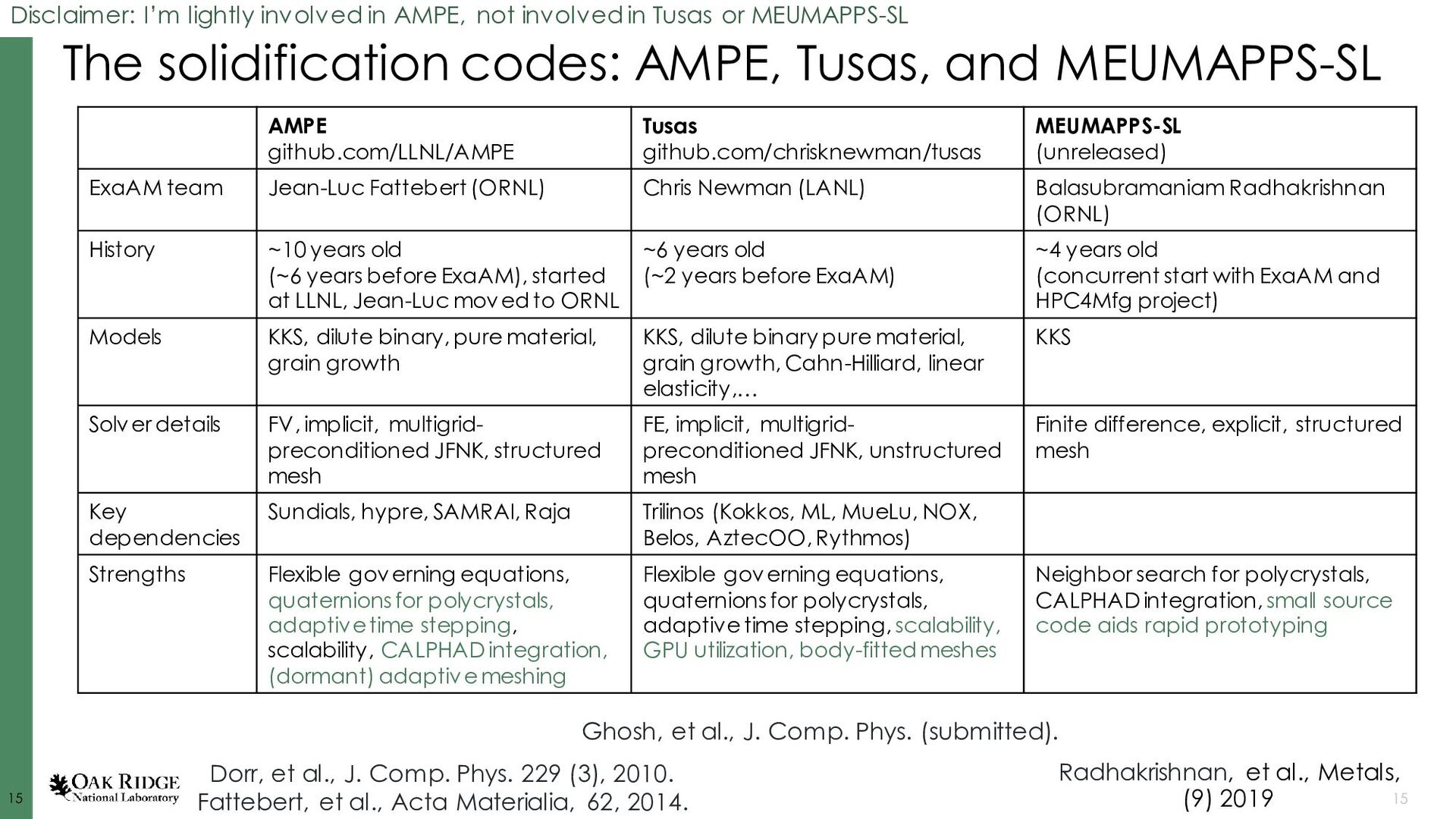
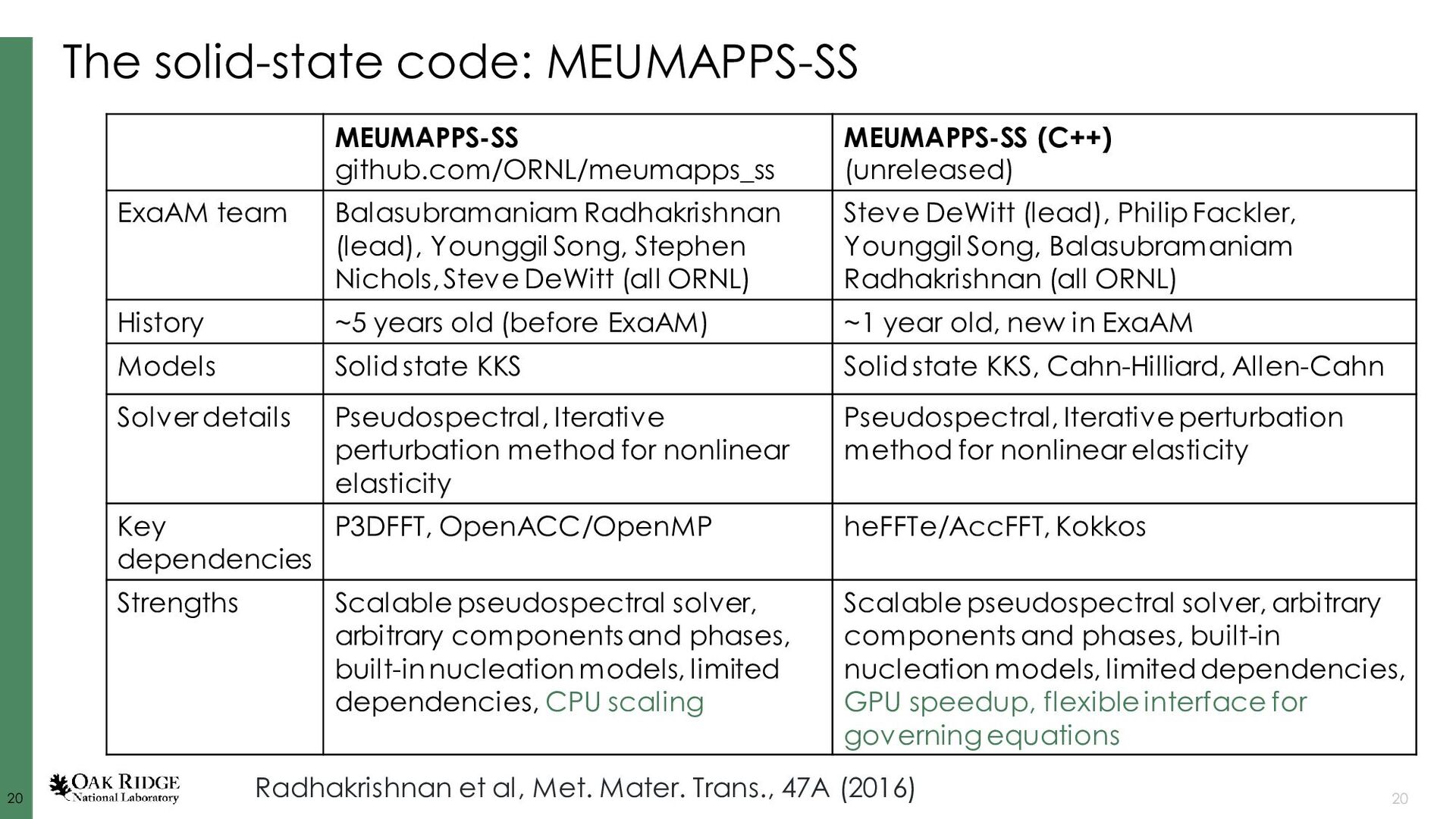
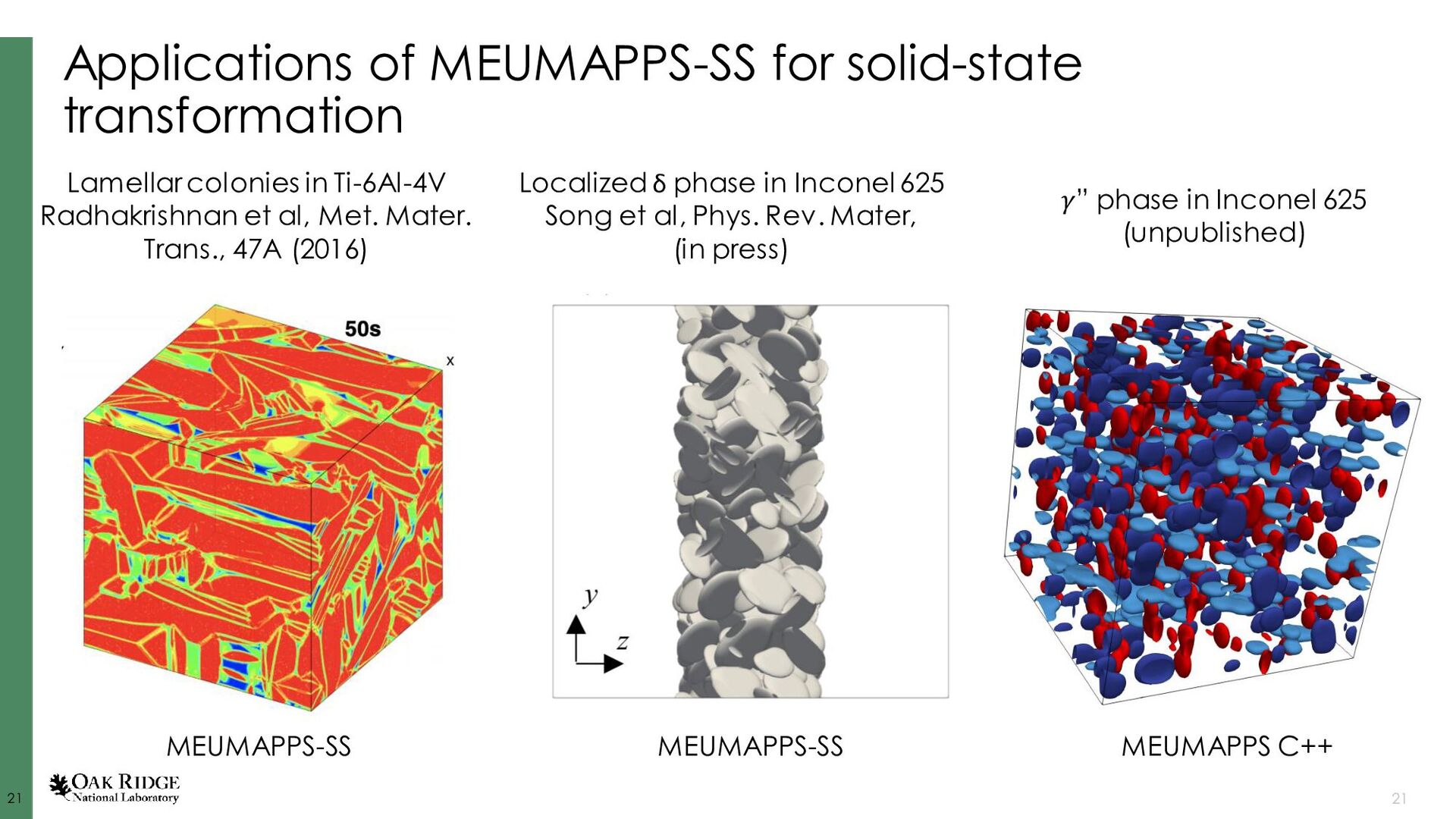
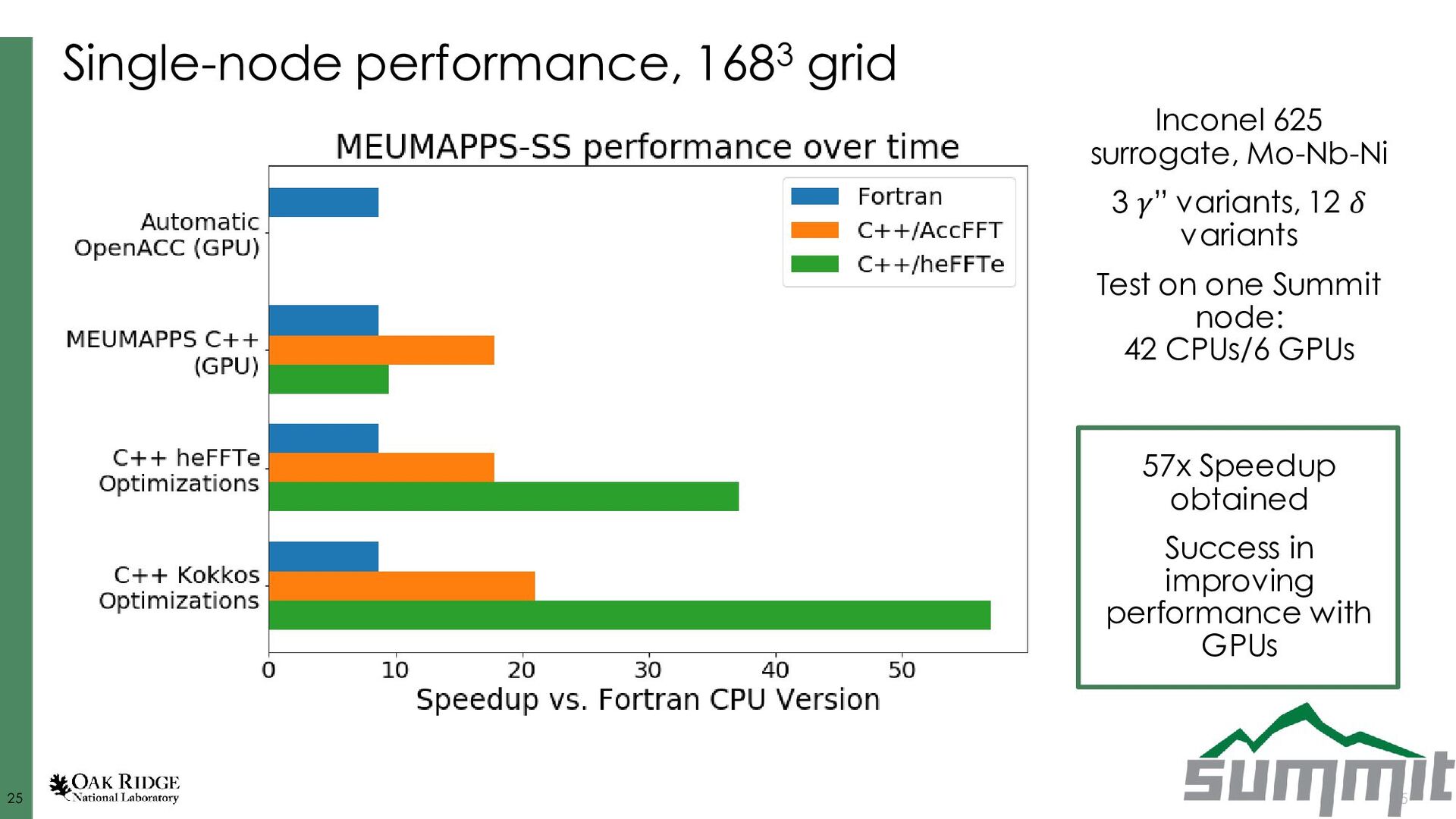
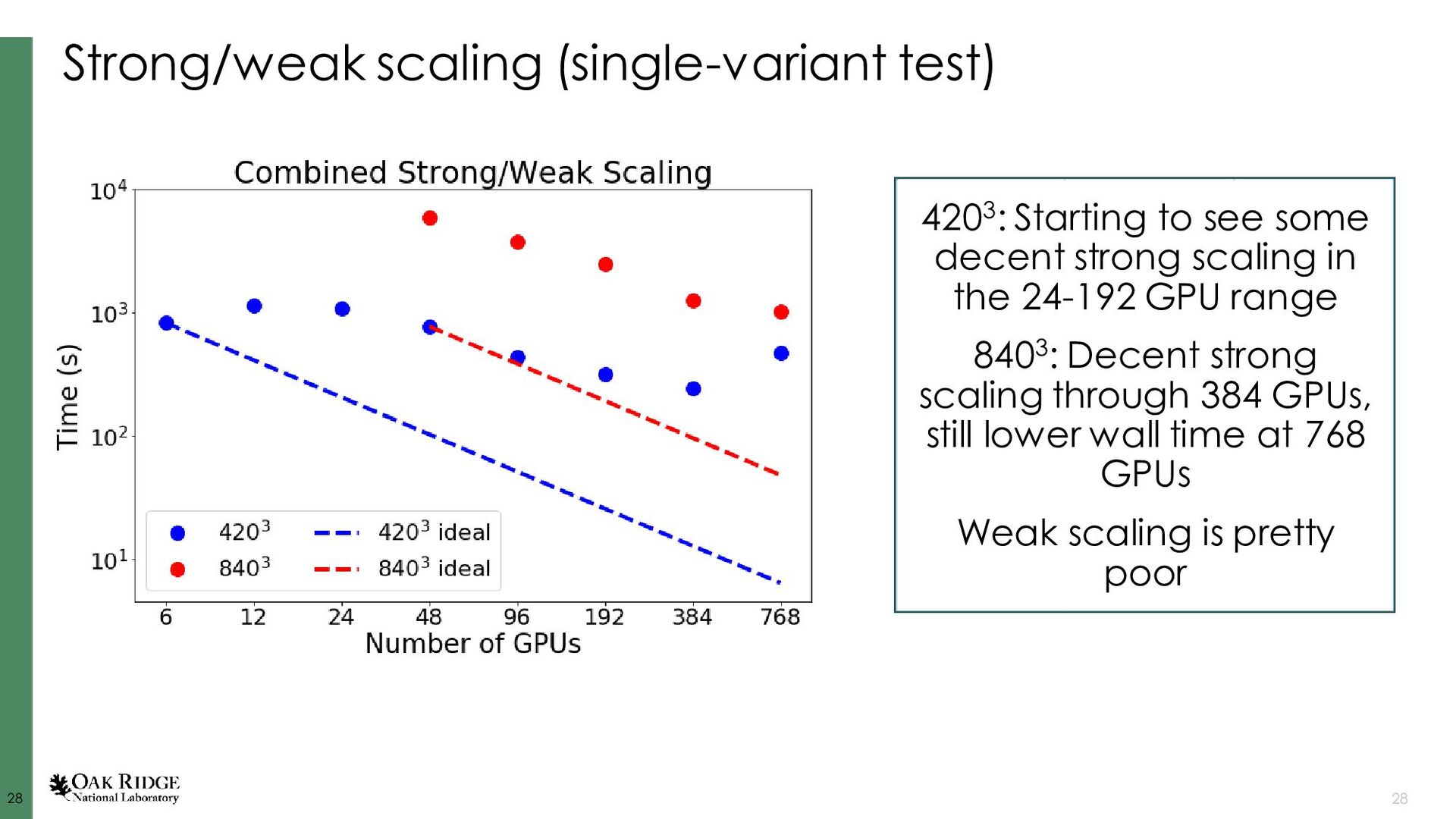
Dorr, et al., J. Comp. Phys. 229 (3), 2010. Fattebert, et al., Acta Materialia, 62, 2014. Disclaimer: I’m lightly involved in AMPE, not involved in Tusas or MEUMAPPS-SL AMPE github.com/LLNL/AMPE Tusas github.com/chrisknewman/tusas MEUMAPPS-SL (unreleased) ExaAM team Jean-Luc Fattebert (ORNL) Chris Newman (LANL) Balasubramaniam Radhakrishnan (ORNL) History ~10 years old (~6 years before ExaAM), started at LLNL, Jean-Luc moved to ORNL ~6 years old (~2 years before ExaAM) ~4 years old (concurrent start with ExaAM and HPC4Mfg project) Models KKS, dilute binary, pure material, grain growth KKS, dilute binary pure material, grain growth, Cahn-Hilliard, linear elasticity,… KKS Solver details FV, implicit, multigrid- preconditioned JFNK, structured mesh FE, implicit, multigrid- preconditioned JFNK, unstructured mesh Finite difference, explicit, structured mesh Key dependencies Sundials, hypre, SAMRAI, Raja Trilinos (Kokkos, ML, MueLu, NOX, Belos, AztecOO, Rythmos) Strengths Flexible governing equations, quaternions for polycrystals, adaptive time stepping, scalability, CALPHAD integration, (dormant) adaptive meshing Flexible governing equations, quaternions for polycrystals, adaptive time stepping, scalability, GPU utilization, body-fitted meshes Neighbor search for polycrystals, CALPHAD integration, small source code aids rapid prototyping Ghosh, et al., J. Comp. Phys. (submitted). Radhakrishnan, et al., Metals, (9) 2019
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
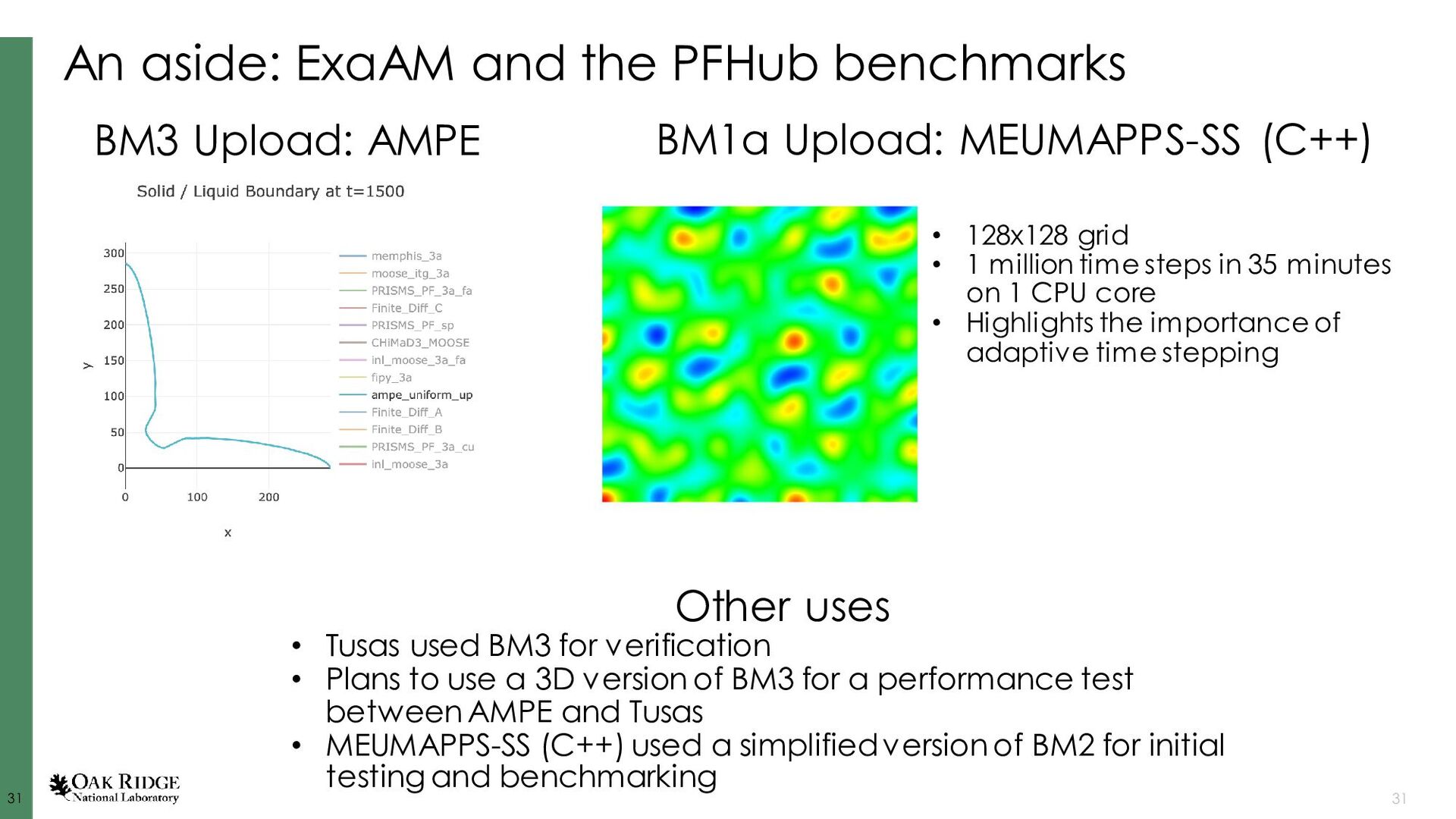{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
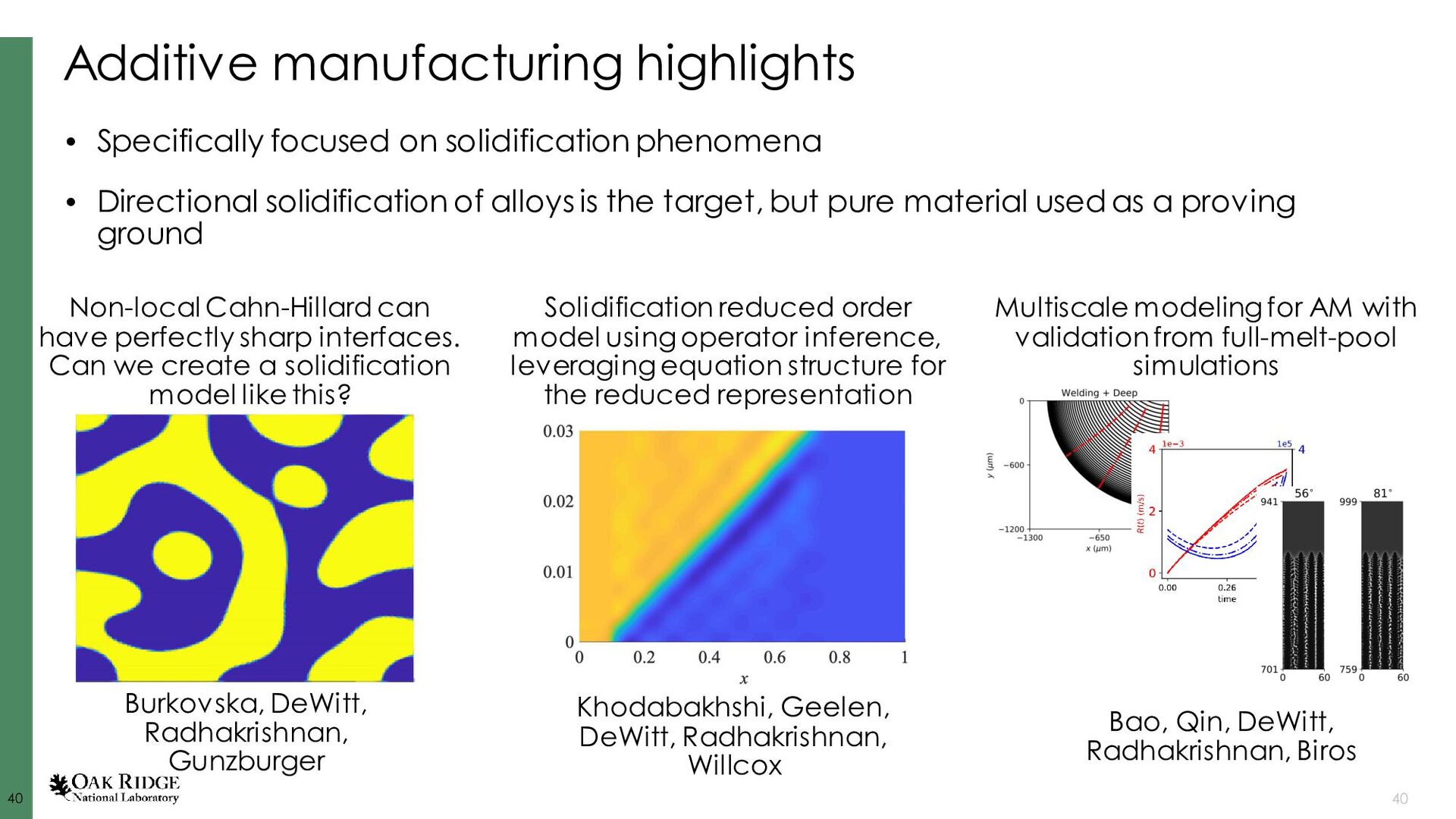{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Questions: [email protected] 1h on 6 GPUS 1683, 10,000](https://files.speakerdeck.com/presentations/dca790b0df0f47b79bc7942e1d28958f/slide_45.jpg){kind=link}