ABSTRACT:
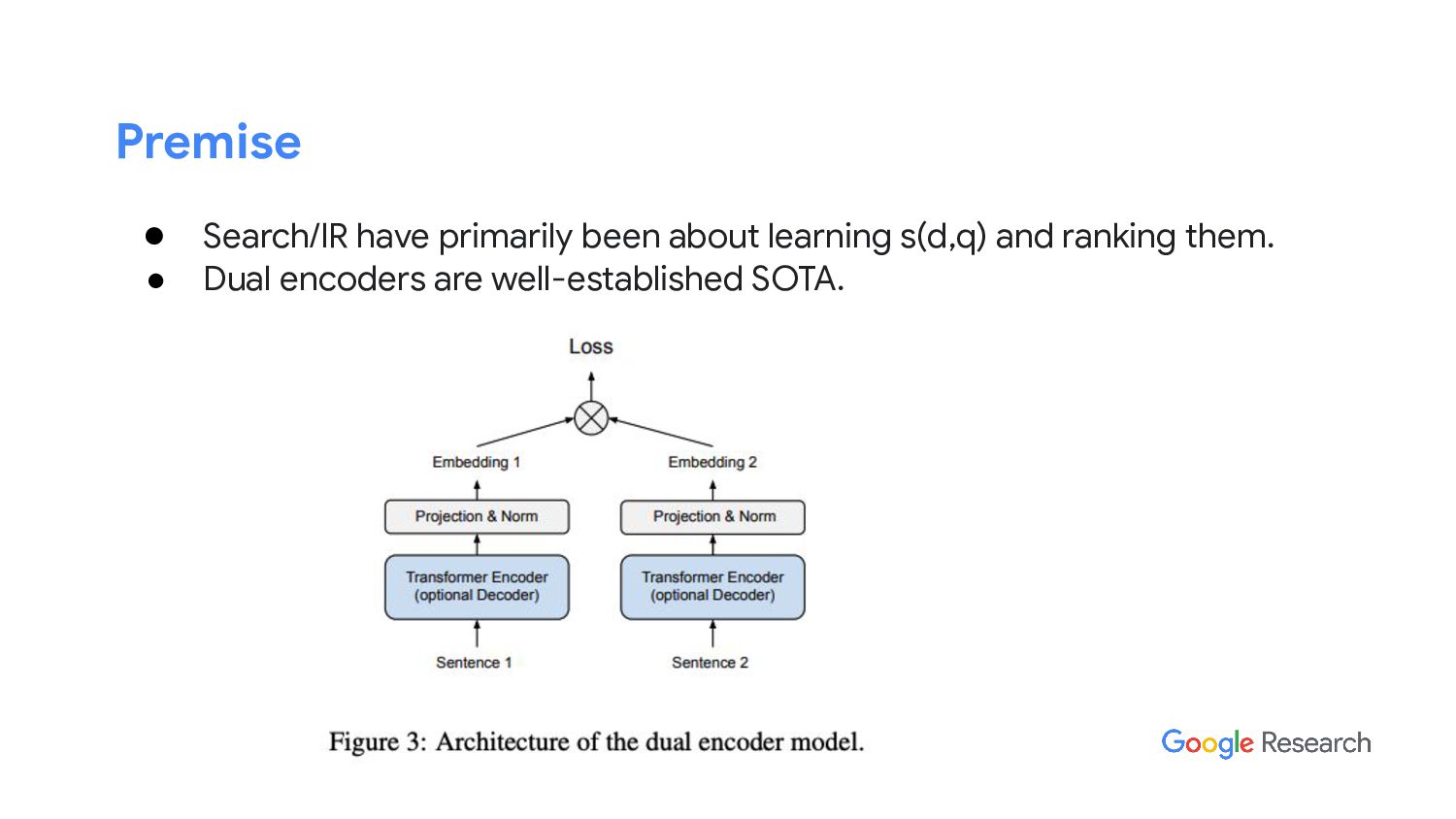
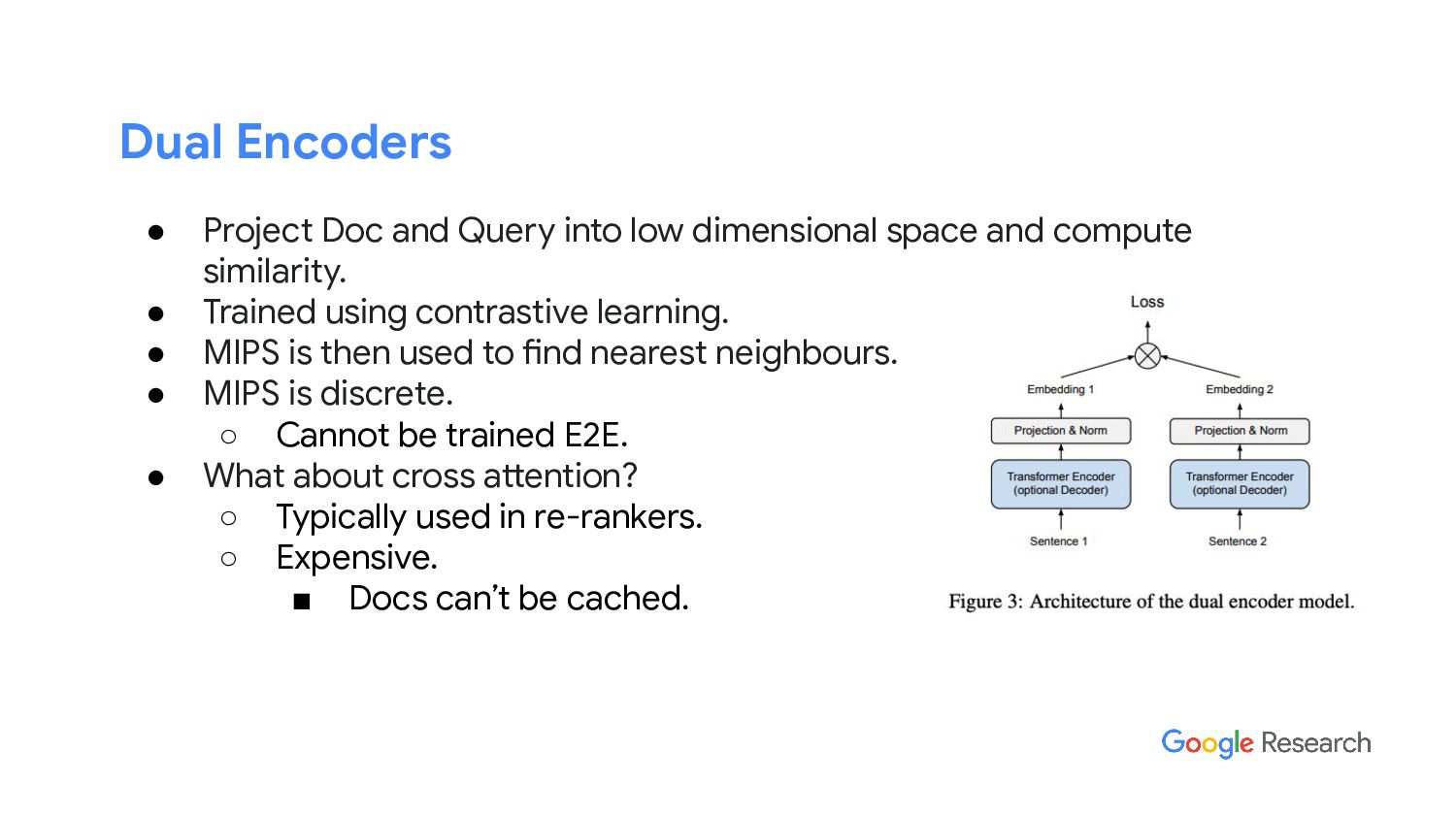
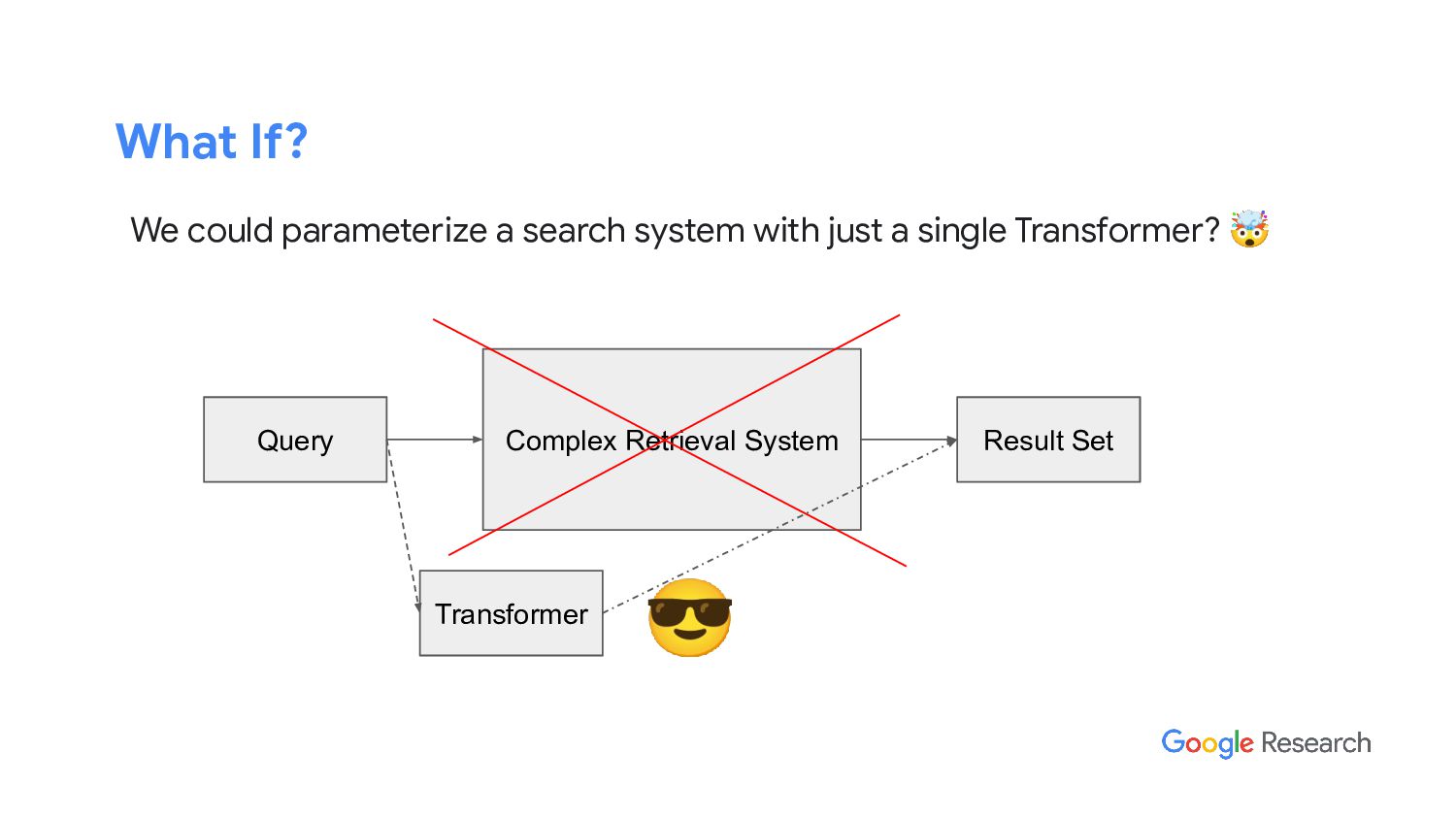
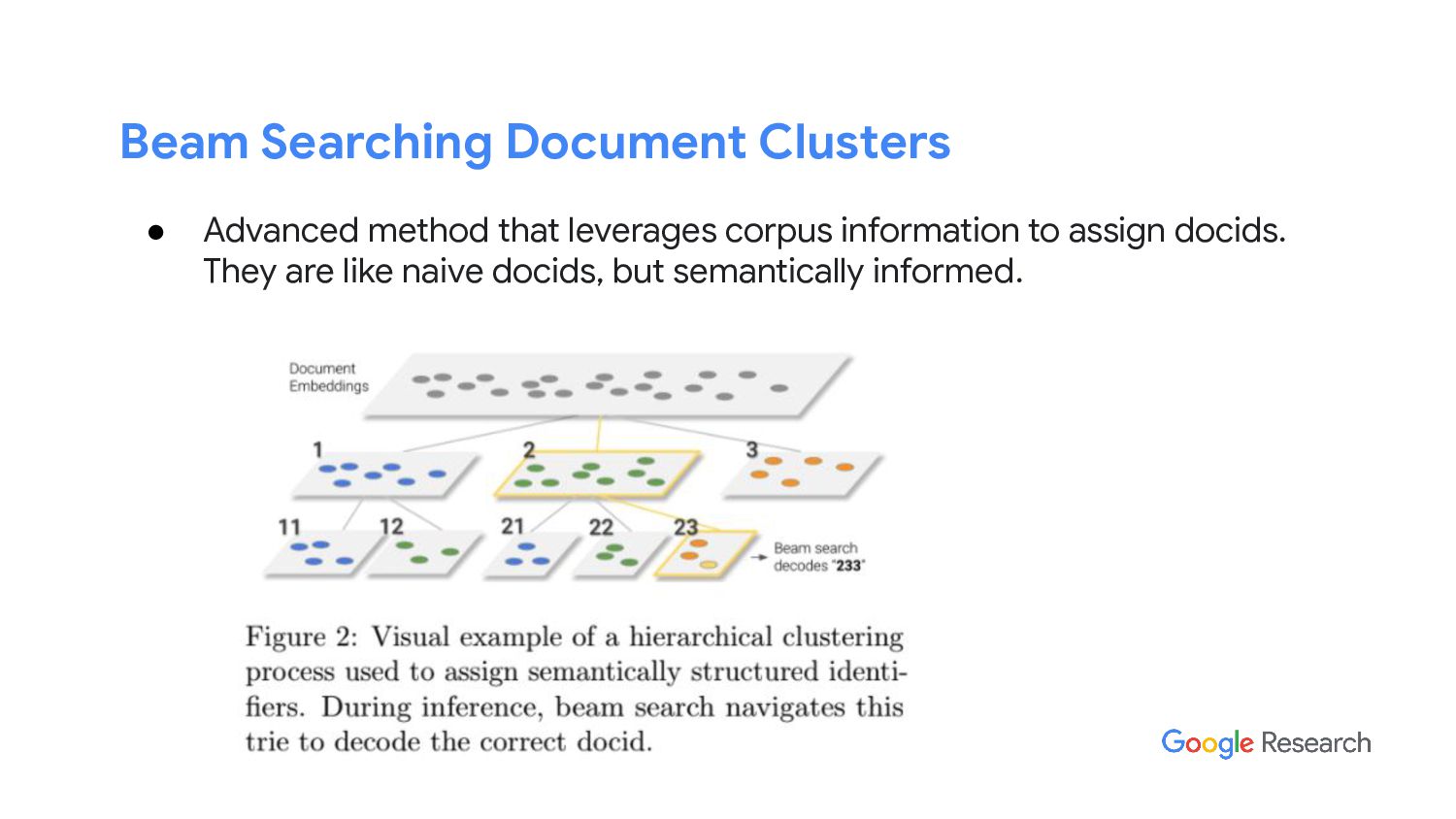
In this talk, I will discuss our latest work from Google AI, the “differentiable search index” (DSI). DSI demonstrates that information retrieval can be accomplished with a single Transformer, in which all information about the corpus is encoded in the parameters of the model. DSI is a new paradigm that learns a text-to-text model that maps string queries directly to relevant docids; in other words, a DSI model answers queries directly using only its parameters, dramatically simplifying the whole retrieval process. We study variations in how documents and their identifiers are represented, variations in training procedures, and the interplay between models and corpus sizes. Experiments demonstrate that given appropriate design choices, DSI significantly outperforms strong baselines such as dual encoder models. Moreover, DSI demonstrates strong generalization capabilities, outperforming a BM25 baseline in a zero-shot setup.
BIO-DATA:
Yi Tay is a Senior Research Scientist and Tech Lead at Google AI. Yi is mainly a ML/NLP researcher with a keen focus on Transformer models. Yi’s research work has earned him the ICLR 2021 best paper award, WSDM 2020 Best paper award (runner-up) and WSDM 2021 Best Paper Award (runner-up). He also sometimes serves as Area Chair or Senior PC for top tier conferences. Before joining Google, Yi earned his PhD from NTU Singapore where he also won the best thesis award. To this date, Yi has published quite a lot of papers but is now more interested in retweets than peer reviewed papers. Homepage: https://vanzytay.github.io/
Slides link (via Speakerdeck): https://speakerdeck.com/wingnus/transformer-memory-as-a-differentiable-search-index
YouTube Video recording: https://youtu.be/27rNqGrTdSI
Related Link: https://wing-nus.github.io/nlp-seminar/speaker-yi
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}