We optimize Replenishment and Pricing for the Retail industry with Predictive Analytics • Contributor to Apache {Arrow, Parquet} • Work in Python, Cython, C++11 and SQL
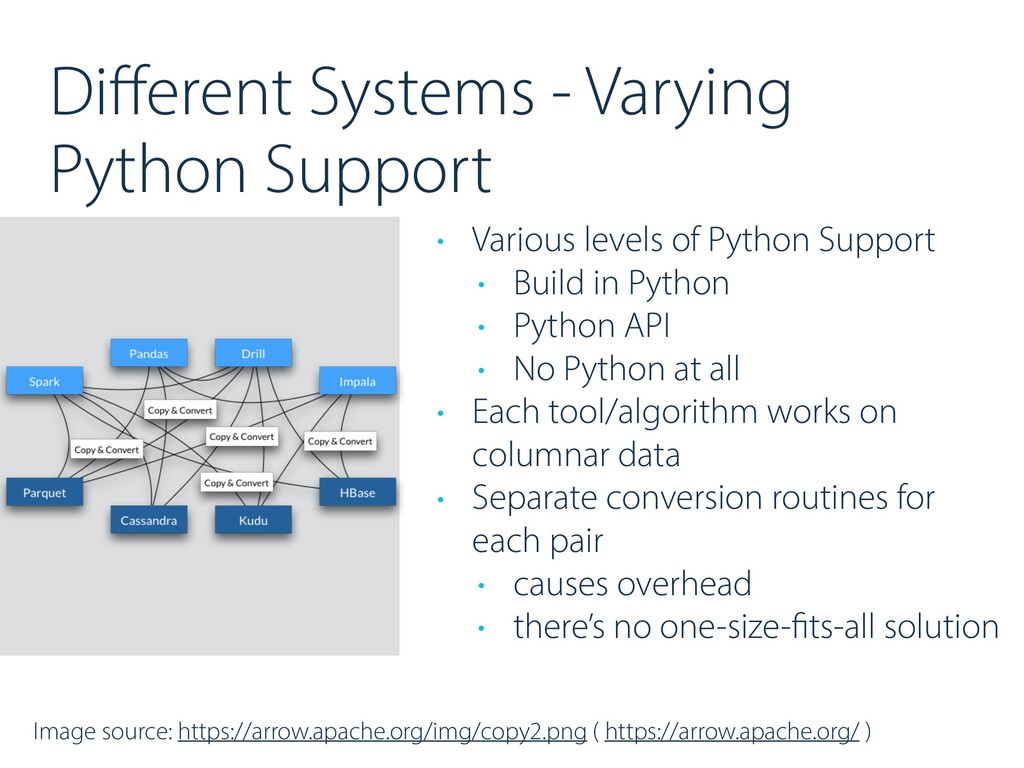
Python Support • Build in Python • Python API • No Python at all • Each tool/algorithm works on columnar data • Separate conversion routines for each pair • causes overhead • there’s no one-size-fits-all solution Image source: https://arrow.apache.org/img/copy2.png ( https://arrow.apache.org/ )
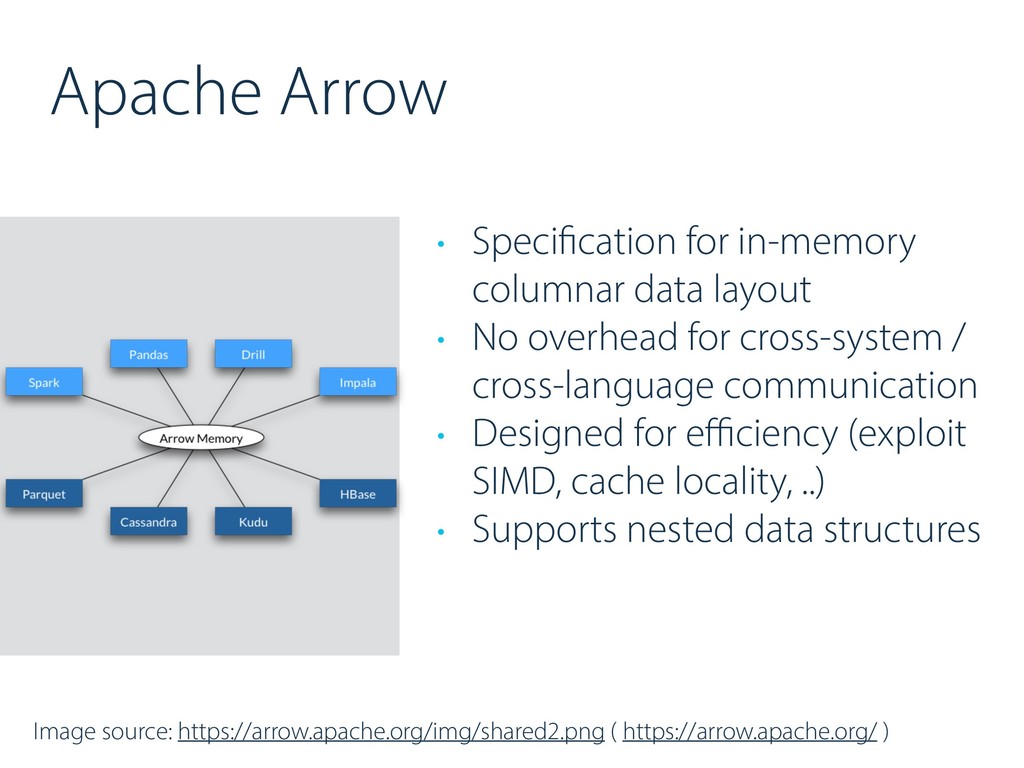
No overhead for cross-system / cross-language communication • Designed for efficiency (exploit SIMD, cache locality, ..) • Supports nested data structures Image source: https://arrow.apache.org/img/shared2.png ( https://arrow.apache.org/ )
dataset from an MPP database and analyze it in Pandas • Run a query in the DB • Pass it in columnar form to the DB driver • The OBDC layer transform it into row-wise form • Pandas makes it columnar again • Ugly real-life solution: export as CSV, bypass ODBC • In future: Use Arrow as interface between the DB and Pandas
Not only a specification: also includes C++ / Java / Python / .. code. • Arrow structures / classes • RPC (upcoming) & IPC (alpha) support • Conversion code for Parquet, Pandas, .. • Combined effort from developer of over 13 major OSS projects • Impala, Kudu, Spark, Cassandra, Drill, Pandas, R, .. • Spec: https://github.com/apache/arrow/blob/master/format/Layout.md
data frame storage • Read performance close to raw disk I/O • by Wes McKinney (Python) and Hadley Wickham (R) • Julia Support in progress Arrow Arrays Feather Metadata (flatbuffers)
• Inspired from Google Dremel paper • space and query efficient • multiple encodings • predicate pushdown • column-wise compression • many tools use Parquet as the default input format • very popular in the JVM/Hadoop-based world
groups • all with the same number of column chunks • n pages per column chunk • Benefits: • pre-partitioned for fast distributed access • statistics in the metadata for predicate pushdown Blogpost by Julien Le Dem: https://blog.twitter.com/2013/dremel-made- simple-with-parquet File Row Group Column Chunk Page
today with Python: • sqlContext.read.parquet(“..“).toPandas() • Needs to pass through Spark, very slow • Native Python support on its way: • Parquet I/O to Arrow • Arrow provides NumPy conversion
data • Java (beta) • C++ (in progress) • Python (in progress) • Planned: • Julia • R Parquet columnar on-disk storage • Java (mature) • C++ (in progress) • Python (in progress) • Planned: • Julia • R
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Get Involved! • [email protected] & [email protected] • https://apachearrowslackin.herokuapp.com/ • https://arrow.apache.org/](https://files.speakerdeck.com/presentations/cdf9695ff5114e1895f31b137d54d5ee/slide_15.jpg){kind=link}
{kind=link}