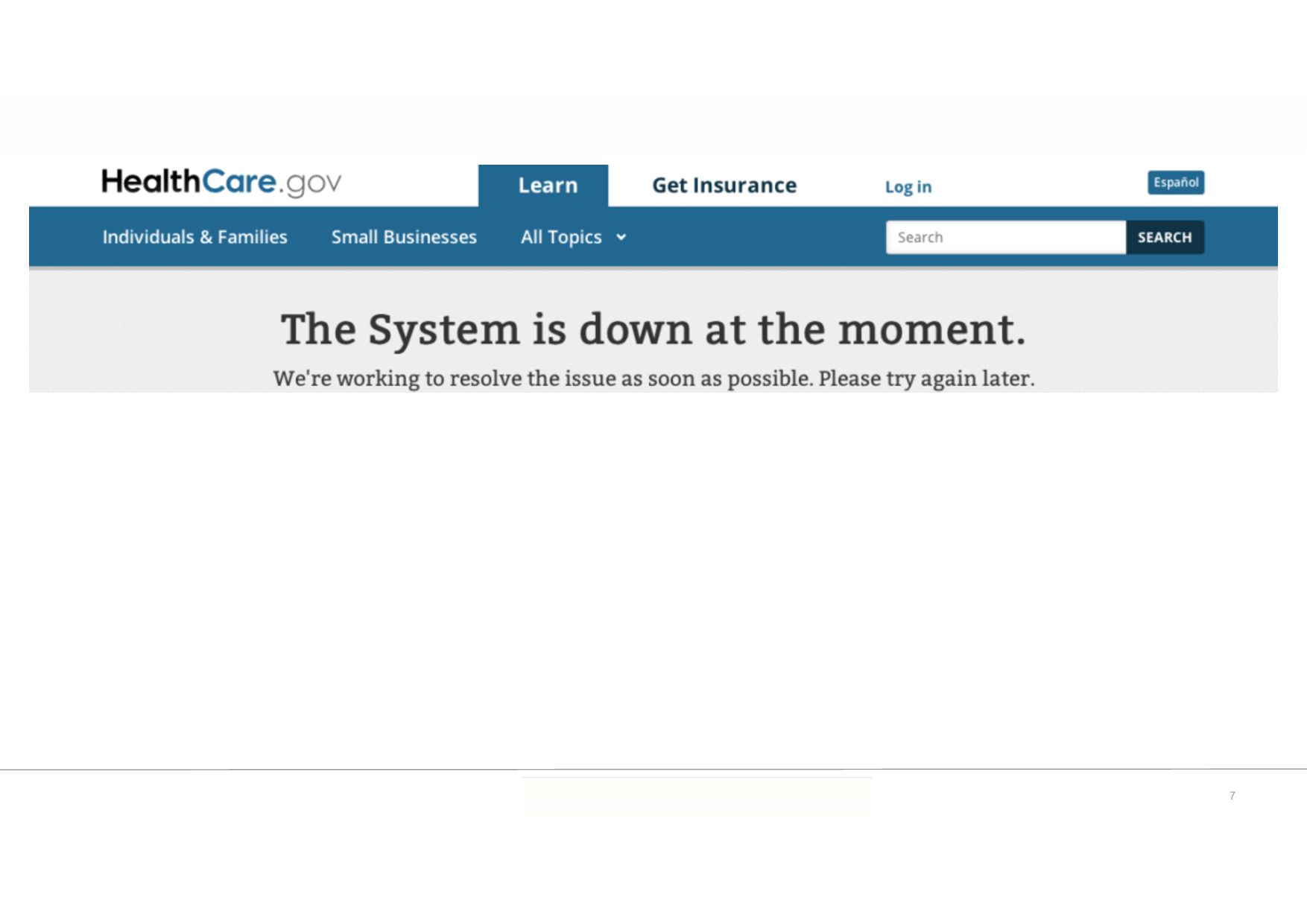
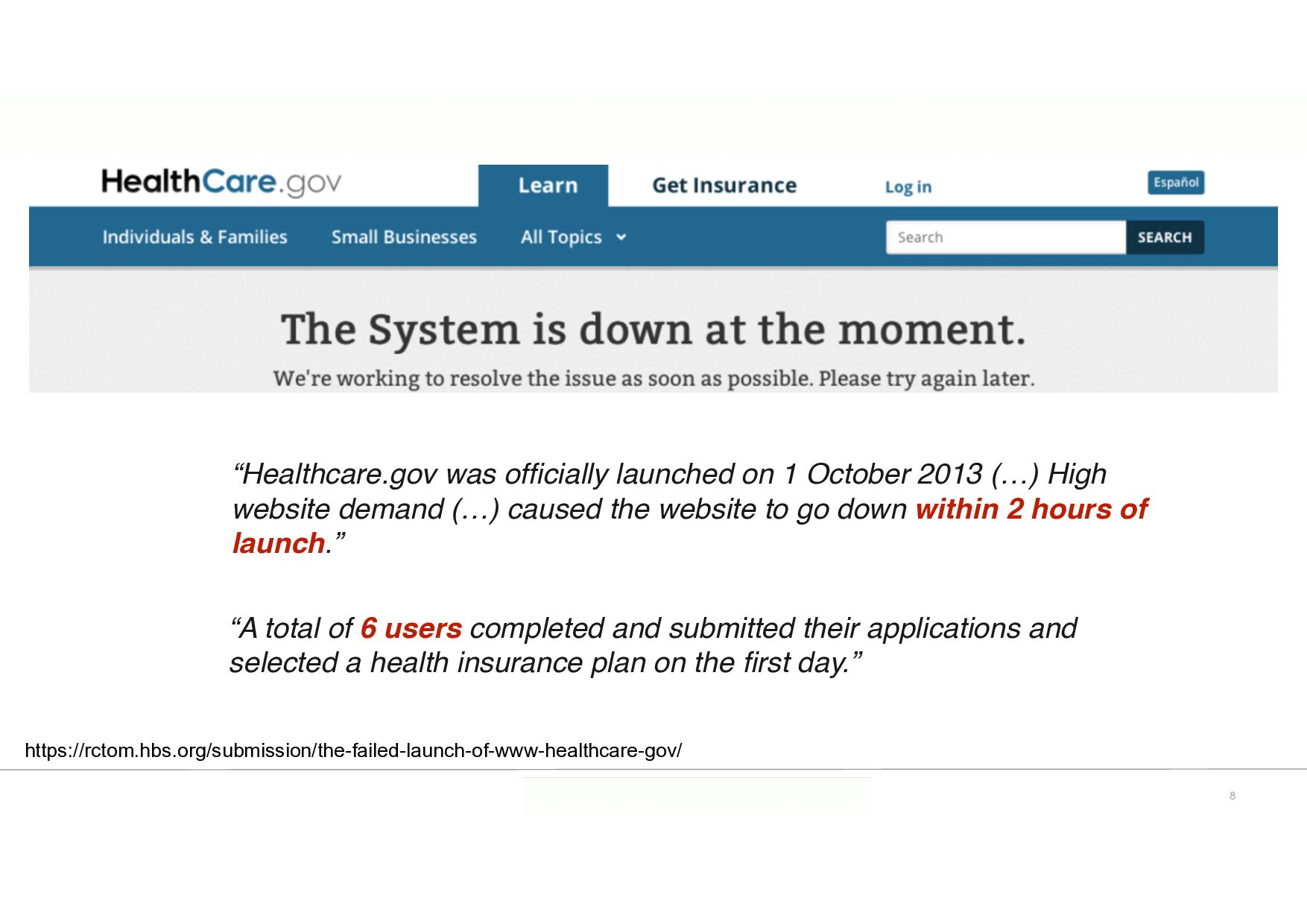
October 2013 (…) High website demand (…) caused the website to go down within 2 hours of launch.” “A total of 6 users completed and submitted their applications and selected a health insurance plan on the fi rst day.” https://rctom.hbs.org/submission/the-failed-launch-of-www-healthcare-gov/
write Benchmark bug finders using static analysis Benchmark generators Costa, Bezemer, Leitner, Andrzejak (2021). What's Wrong with My Benchmark Results? Studying Bad Practices in JMH Benchmarks. IEEE Transactions on Software Engineering Jangali, Tang, Alexandersson, Leitner, Yang, Shang (2022). Automated Generation and Evaluation of JMH Microbenchmark Suites from Unit Tests. IEEE Transactions on Software Engineering Rodriguez-Cancio, Combemale, Baudry (2016). Automatic microbenchmark generation to prevent dead code elimination and constant folding. In ASE '16
time to execute Smart reconfiguration Benchmark selection Laaber, Würsten, Gall, Leitner (2020) Dynamically reconfiguring software microbenchmarks: reducing execution time without sacrificing result quality. In ESEC/FSE 2020 Traini, Cortellessa, Di Pompeo, Tucci (2023) Towards effective assessment of steady state performance in Java software: are we there yet? In Empirical Software Engineering Laaber, Gall, Leitner (2021) Applying test case prioritization to software microbenchmarks. In Empirical Software Engineering
code changes - Identifying bottlenecks - Suggesting improvements before execution! Cito, Leitner, Rinard, Gall (2019). Interactive Production Performance Feedback in the IDE. In International Conference on Software Engineering (ICSE’19)
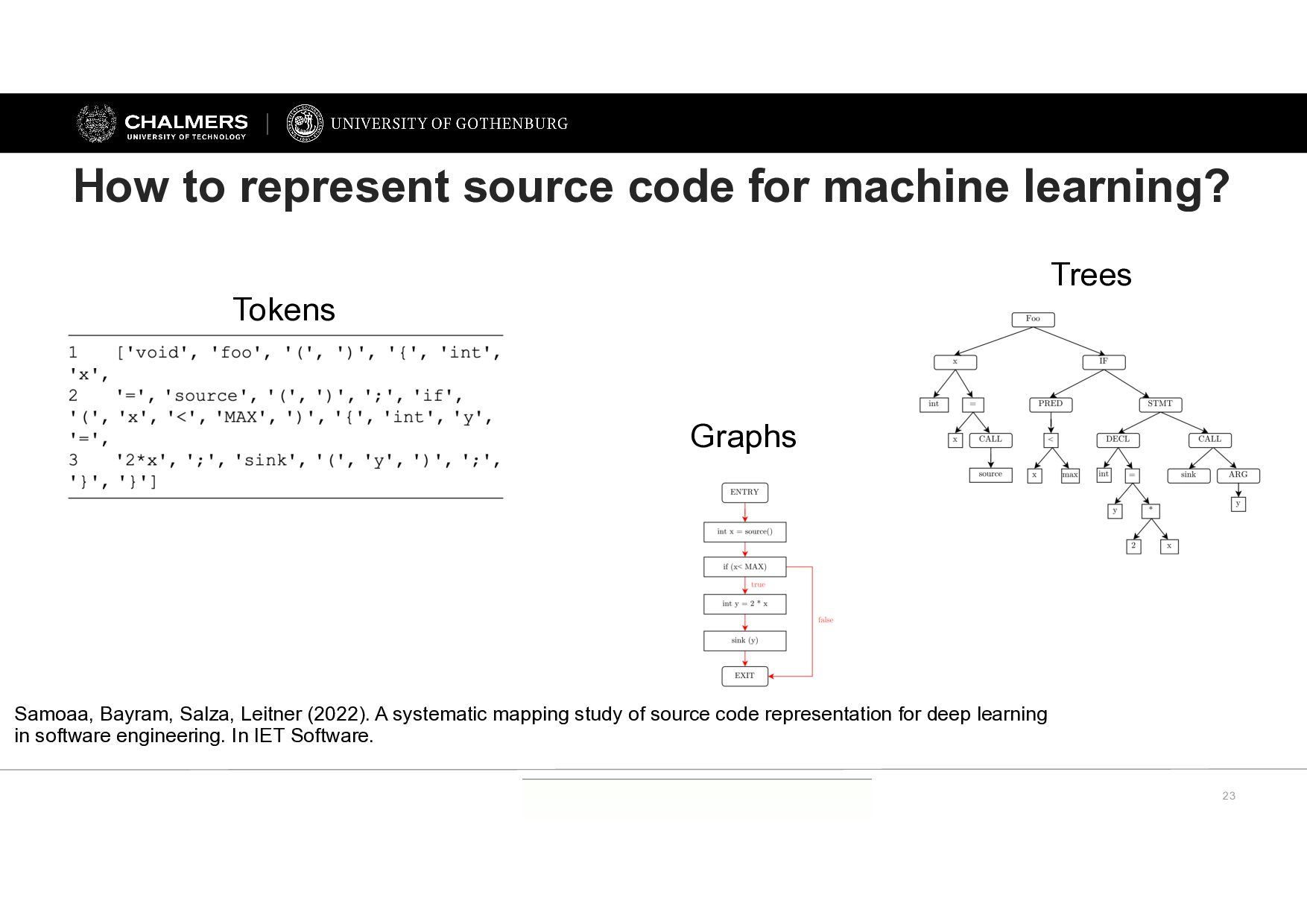
study of source code representation for deep learning in software engineering. In IET Software. How to represent source code for machine learning? Tokens Trees Graphs
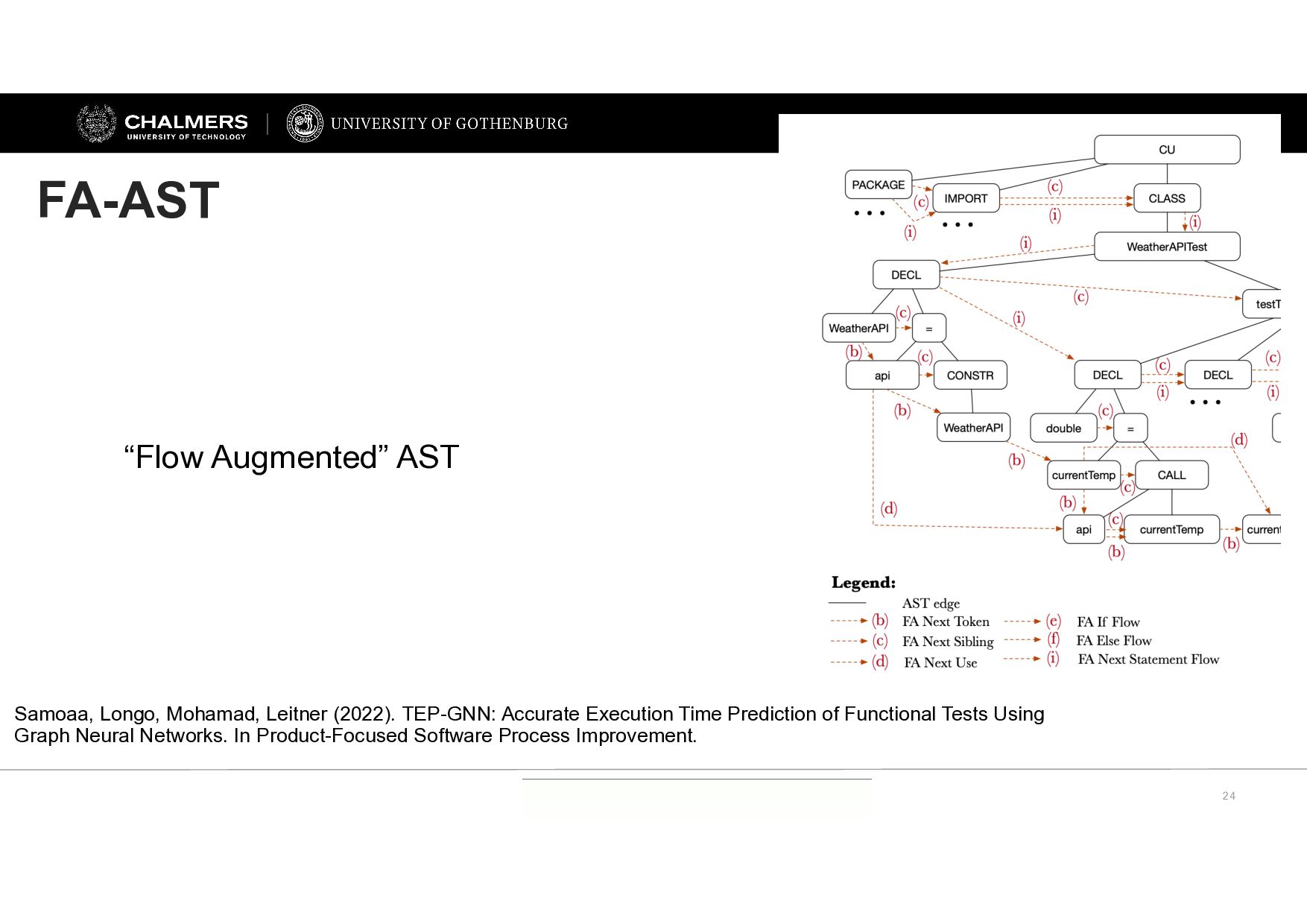
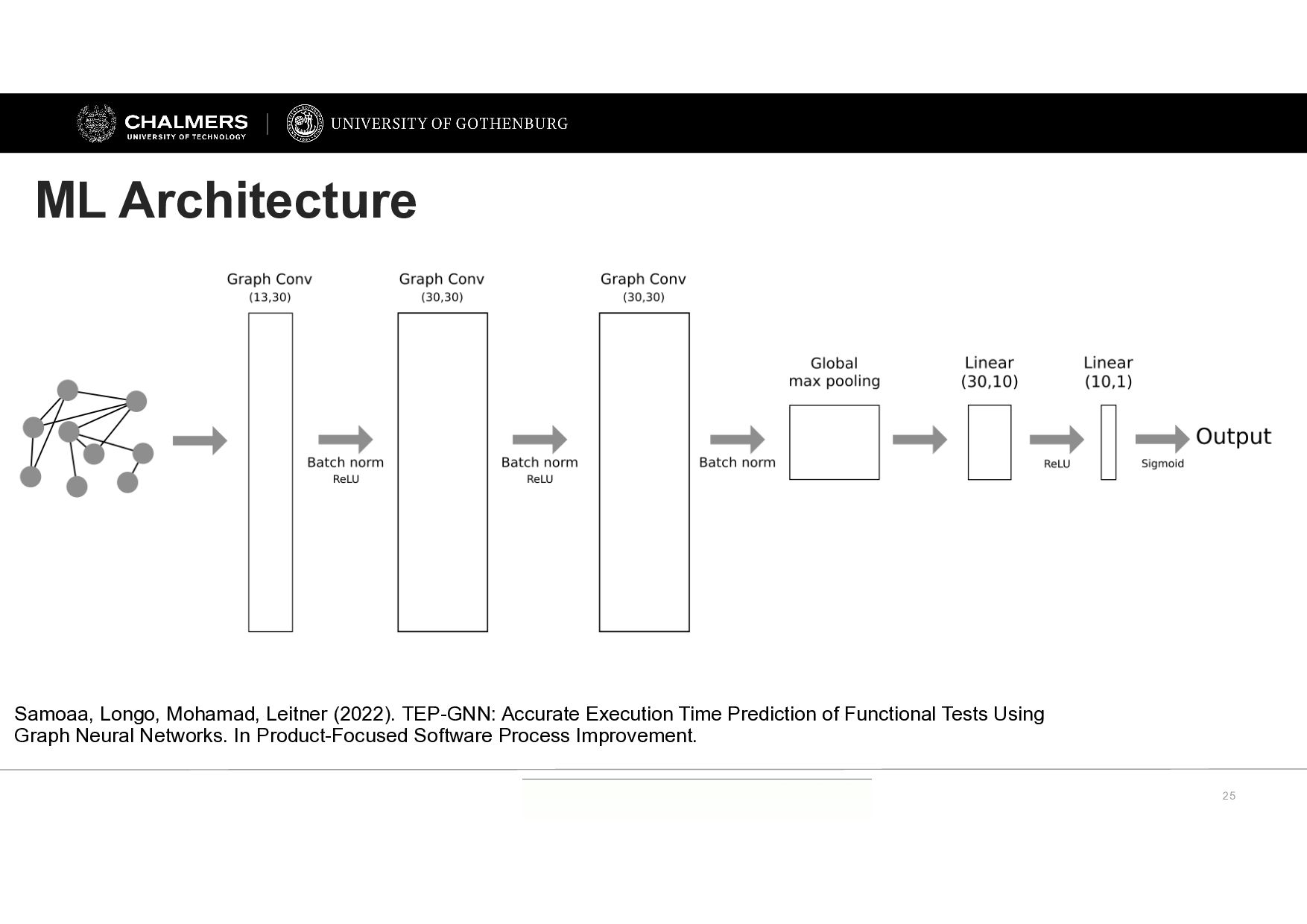
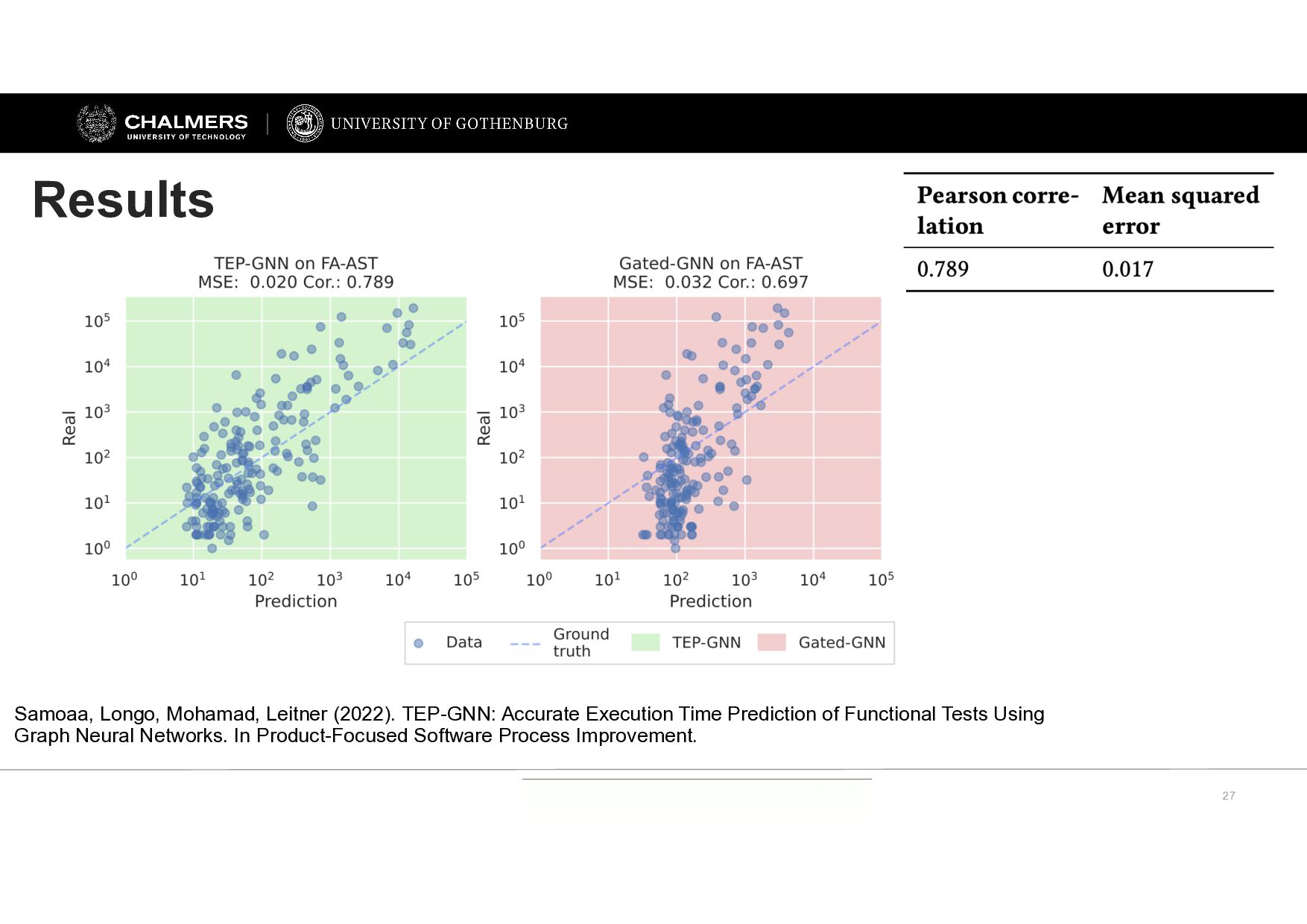
Longo, Mohamad, Leitner (2022). TEP-GNN: Accurate Execution Time Prediction of Functional Tests Using Graph Neural Networks. In Product-Focused Software Process Improvement.
Data Active Learning Samoaa, Aronsson, Longa, Leitner, Chehreghani (2024). A Unified Active Learning Framework for Annotating Graph Data for Regression Tasks. In Journal of Engineering Applications of Artificial Intelligence. Samoaa, Aronsson, Leitner, Chehreghani (2023). Batch Mode Deep Active Learning for Regression on Graph Data. In IEEE International Conference on Big Data (BigData).
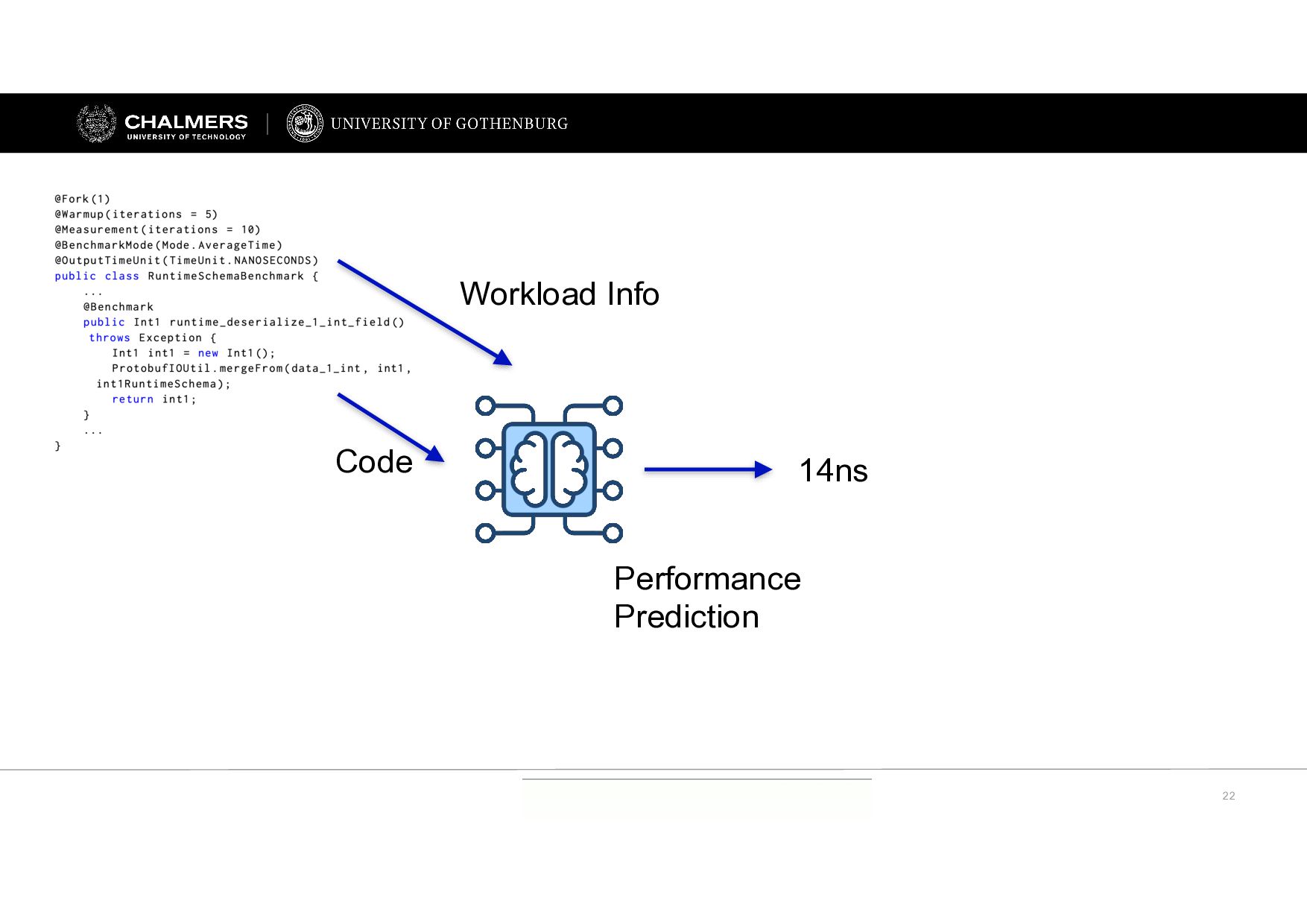
Integrating some runtime information Scenario: Predicting the performance of a (small) code change Rather than predicting the performance of entirely unseen code
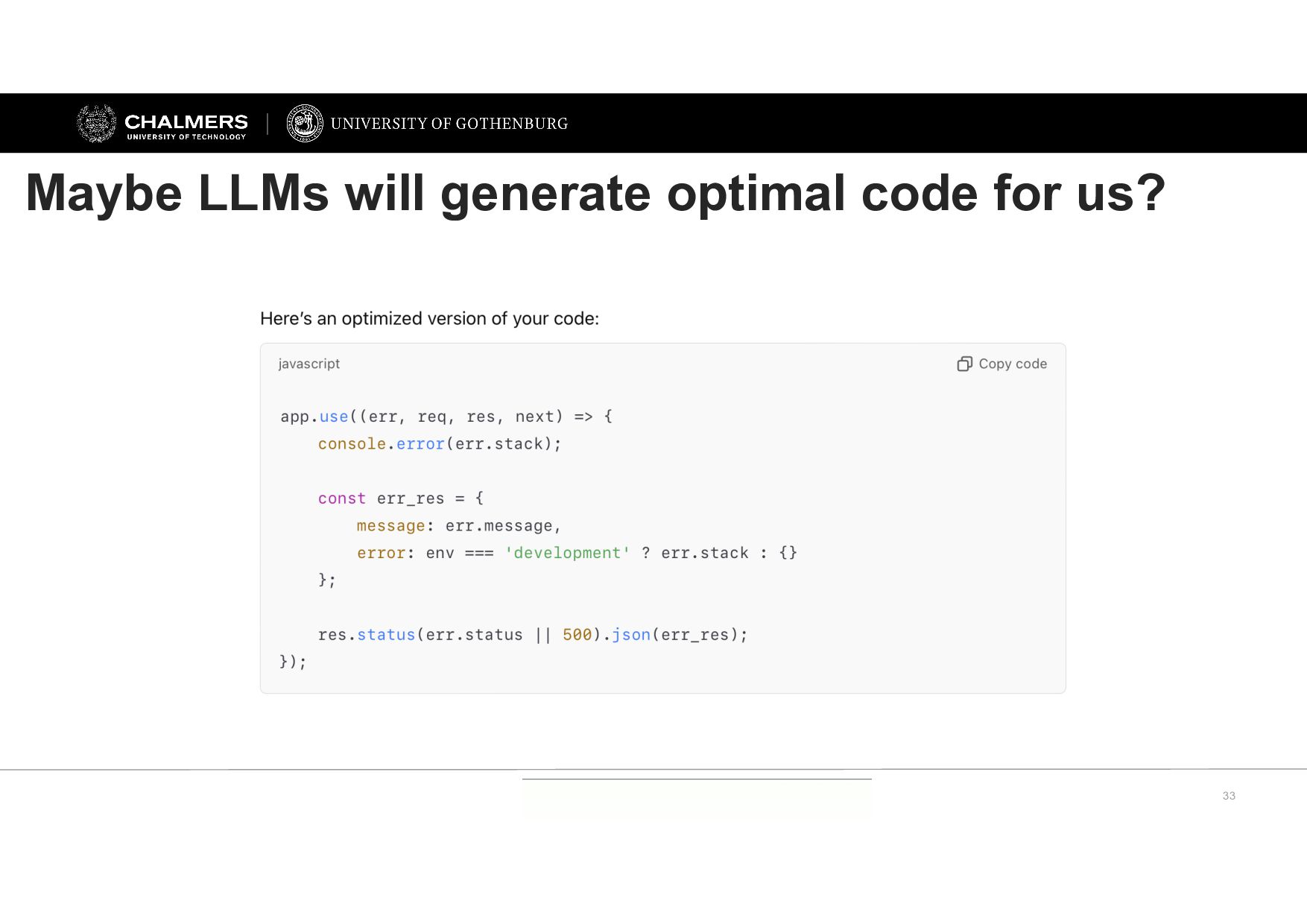
Currently: definitely not In the future: unlikely (at least purely with LLMs) Custom algorithm design is not particularly amenable to pattern learning Liu et al.: Evaluating Language Models for Efficient Code Generation Qiu et al.: How Efficient is LLM-Generated Code? A Rigorous & High-Standard Benchmark Niu et al.: On Evaluating the Efficiency of Source Code Generated by LLMs (all recent work available on arXiv)
with My Benchmark Results? Studying Bad Practices in JMH Benchmarks. IEEE Transactions on Software Engineering, 47(7), pp. 1452-1467 Jangali, Tang, Alexandersson, Leitner, Yang, Shang (2022). Automated Generation and Evaluation of JMH Microbenchmark Suites from Unit Tests. IEEE Transactions on Software Engineering Cito, Leitner, Rinard, Gall (2019). Interactive Production Performance Feedback in the IDE. In Proceedings of the 41st International Conference on Software Engineering (ICSE) Samoaa, Bayram, Salza, Leitner (2022). A systematic mapping study of source code representation for deep learning in software engineering. In IET Software. Samoaa, Longo, Mohamad, Leitner (2022). TEP-GNN: Accurate Execution Time Prediction of Functional Tests Using Graph Neural Networks. In Product-Focused Software Process Improvement. Samoaa, Aronsson, Longa, Leitner, Chehreghani (2024). A Unified Active Learning Framework for Annotating Graph Data for Regression Tasks. In Journal of Engineering Applications of Artificial Intelligence.
![Philipp Leitner Associate Professor [email protected] http://icet-lab.eu Measuring, Predicting, and Improving](https://files.speakerdeck.com/presentations/8643b698900e478e83ec123d059748e4/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
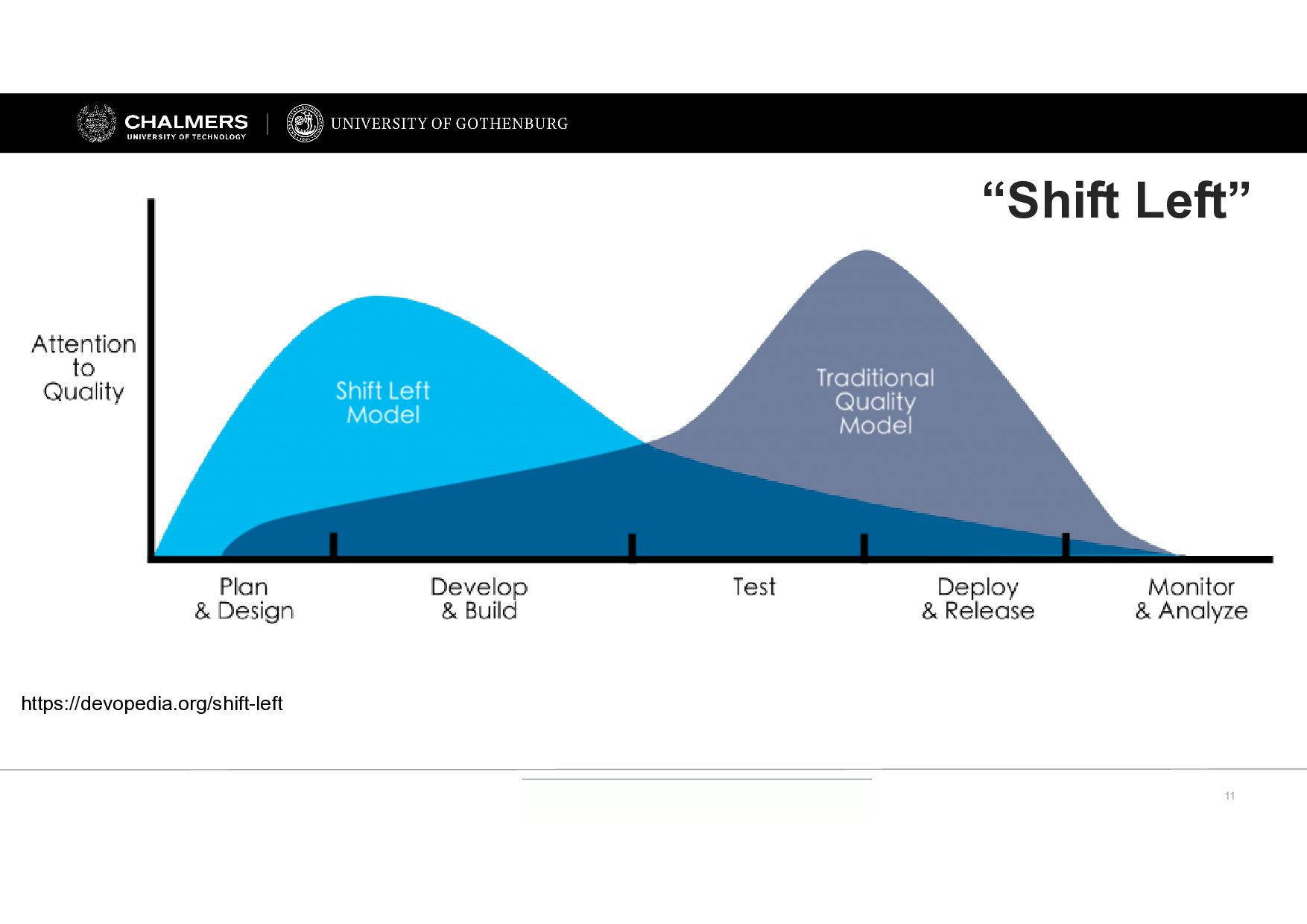{kind=link}
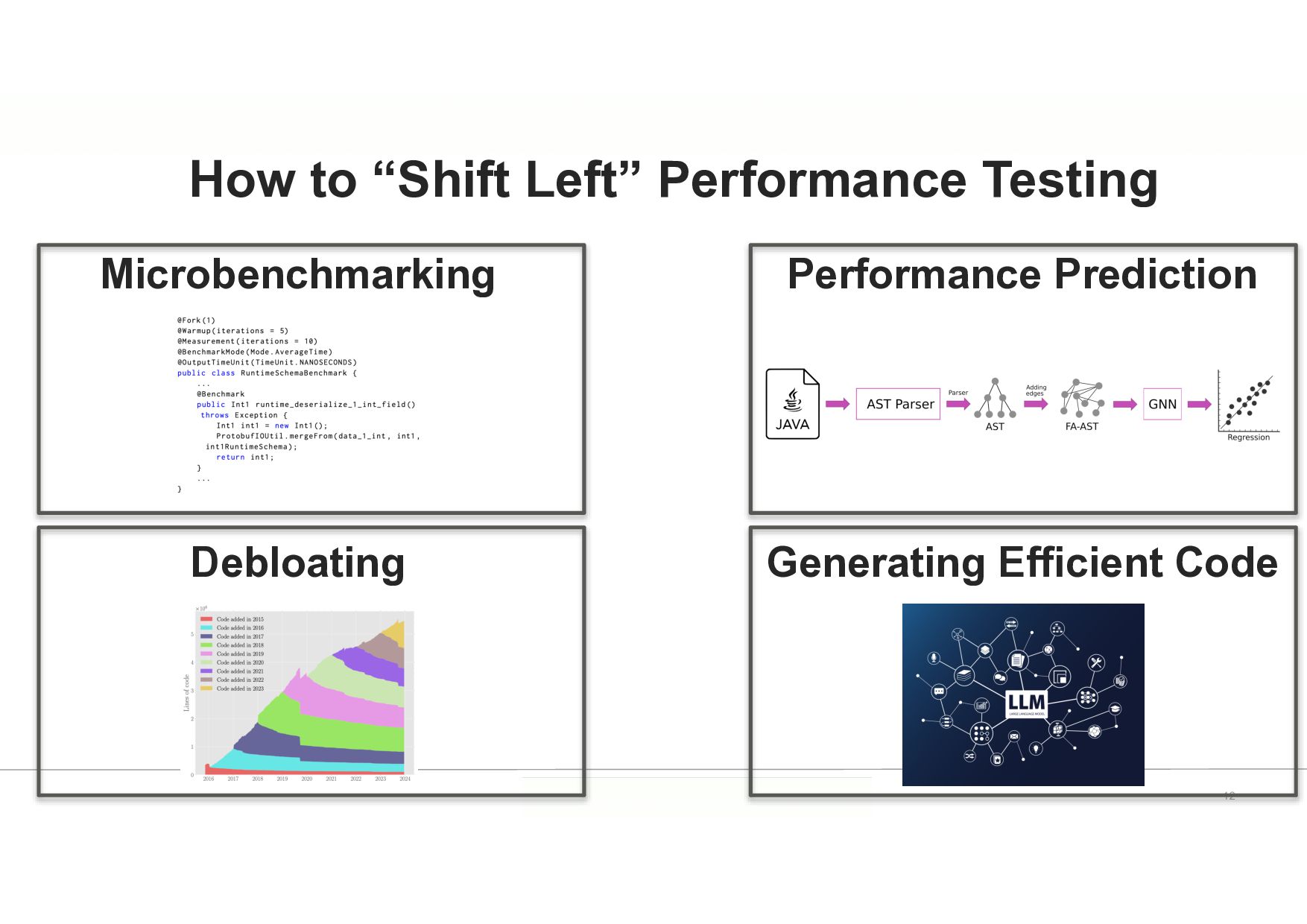{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}