Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
A primer to elasticsearch
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Felix Gilcher
July 20, 2016
Technology
1
240
A primer to elasticsearch
My talk at the berlin digitalocean meetup on july 13th, 2016
Felix Gilcher
July 20, 2016
Tweet
Share
Other Decks in Technology
See All in Technology
Agent Skils
dip_tech
PRO
0
120
CDK対応したAWS DevOps Agentを試そう_20260201
masakiokuda
1
370
FinTech SREのAWSサービス活用/Leveraging AWS Services in FinTech SRE
maaaato
0
130
こんなところでも(地味に)活躍するImage Modeさんを知ってるかい?- Image Mode for OpenShift -
tsukaman
1
160
AIエージェントに必要なのはデータではなく文脈だった/ai-agent-context-graph-mybest
jonnojun
1
220
SRE Enabling戦記 - 急成長する組織にSREを浸透させる戦いの歴史
markie1009
0
150
茨城の思い出を振り返る ~CDKのセキュリティを添えて~ / 20260201 Mitsutoshi Matsuo
shift_evolve
PRO
1
360
Bill One急成長の舞台裏 開発組織が直面した失敗と教訓
sansantech
PRO
2
390
ClickHouseはどのように大規模データを活用したAIエージェントを全社展開しているのか
mikimatsumoto
0
260
生成AIを活用した音声文字起こしシステムの2つの構築パターンについて
miu_crescent
PRO
3
210
【Ubie】AIを活用した広告アセット「爆速」生成事例 | AI_Ops_Community_Vol.2
yoshiki_0316
1
110
Webhook best practices for rock solid and resilient deployments
glaforge
2
300
Featured
See All Featured
Odyssey Design
rkendrick25
PRO
1
500
Building a Modern Day E-commerce SEO Strategy
aleyda
45
8.7k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.6k
The browser strikes back
jonoalderson
0
390
Typedesign – Prime Four
hannesfritz
42
2.9k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
98
Visualization
eitanlees
150
17k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
130
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
1
300
Prompt Engineering for Job Search
mfonobong
0
160
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Utilizing Notion as your number one productivity tool
mfonobong
3
220
Transcript
ELASTICSEARCH AN INTRODUCTION 1 — © 2016 asquera gmbh, creative
commons cc by
WHOAMI $ cat .profile GIT_AUTHOR_NAME=Felix Gilcher
[email protected]
TM_COMPANY=Asquera GmbH TWITTER_HANDLE=xylakant
GITHUB_HANDLE=xylakant 2 — © 2016 asquera gmbh, creative commons cc by
backend developer/ops person elasticsearch user since 0.10.something co-founder of the
Search UG Berlin 3 — © 2016 asquera gmbh, creative commons cc by
SCOPE 4 — © 2016 asquera gmbh, creative commons cc
by
An overview of what ES does do, doesn't do and
the relevant google keywords for further research 5 — © 2016 asquera gmbh, creative commons cc by
To the daily practitioners: I’ll gloss over a lot of
points. 6 — © 2016 asquera gmbh, creative commons cc by
THE LK OF ELK 7 — © 2016 asquera gmbh,
creative commons cc by
LOGSTASH 8 — © 2016 asquera gmbh, creative commons cc
by
logstash is worker that takes individual input events, processes them
in isolation and writes them to a data sink 9 — © 2016 asquera gmbh, creative commons cc by
input events often are log lines 10 — © 2016
asquera gmbh, creative commons cc by
the data sink often is Elasticsearch, but others are possible:
kafka, influxdb, graphite 11 — © 2016 asquera gmbh, creative commons cc by
parts of logstash will move to ES ingest nodes with
5.0 12 — © 2016 asquera gmbh, creative commons cc by
KIBANA 13 — © 2016 asquera gmbh, creative commons cc
by
Kibana visualizes the result of single Elasticsearch queries 14 —
© 2016 asquera gmbh, creative commons cc by
WHAT IS ELASTICSEARCH? a distributed json datastore based on apache
lucene 15 — © 2016 asquera gmbh, creative commons cc by
WHAT IS IT GOOD FOR? full text search timeline data
distributed datastore for json docs companion datastore to another NoSQL store 16 — © 2016 asquera gmbh, creative commons cc by
WHAT IS IT NOT GOOD FOR? primary datastore anything that
requires transactions volatile data very heavy write loads across datacenter boundaries 17 — © 2016 asquera gmbh, creative commons cc by
CAVEAT EMPTOR 18 — © 2016 asquera gmbh, creative commons
cc by
READ AND UNDERSTAND https://aphyr.com/posts/323-jepsen-elasticsearch-1-5-0 https://www.elastic.co/guide/en/elasticsearch/resiliency/current/ index.html https://www.elastic.co/guide/en/elasticsearch/guide/current/ _don_8217_t_touch_these_settings.html 19 —
© 2016 asquera gmbh, creative commons cc by
SO, HOW EXACTLY IS LUCENE DIFFERENT FROM MYSQL? 20 —
© 2016 asquera gmbh, creative commons cc by
DISTRIBUTED 21 — © 2016 asquera gmbh, creative commons cc
by
documents are collected in indices 22 — © 2016 asquera
gmbh, creative commons cc by
indices are split in shards 23 — © 2016 asquera
gmbh, creative commons cc by
shards are distributed and replicated in a cluster 24 —
© 2016 asquera gmbh, creative commons cc by
cluster nodes can be added and removed at any time,
shards will be redistributed 25 — © 2016 asquera gmbh, creative commons cc by
cluster can tolerate failure of individual nodes as long as
shard replicas are available 26 — © 2016 asquera gmbh, creative commons cc by
JSON DATASTORE 27 — © 2016 asquera gmbh, creative commons
cc by
documents are json all api interactions are json 28 —
© 2016 asquera gmbh, creative commons cc by
WRITE ONCE DATASTRUCTURES Lucene segments are written once and never
touched again. No in-place modification of documents. Update operations are insert + delete. 29 — © 2016 asquera gmbh, creative commons cc by
SHARDED OPERATION 30 — © 2016 asquera gmbh, creative commons
cc by
queries cannot refer to other documents in other shards: no
joins, no distinct queries 31 — © 2016 asquera gmbh, creative commons cc by
limited support for parent-child-relationships 32 — © 2016 asquera gmbh,
creative commons cc by
INVERTED INDEX 33 — © 2016 asquera gmbh, creative commons
cc by
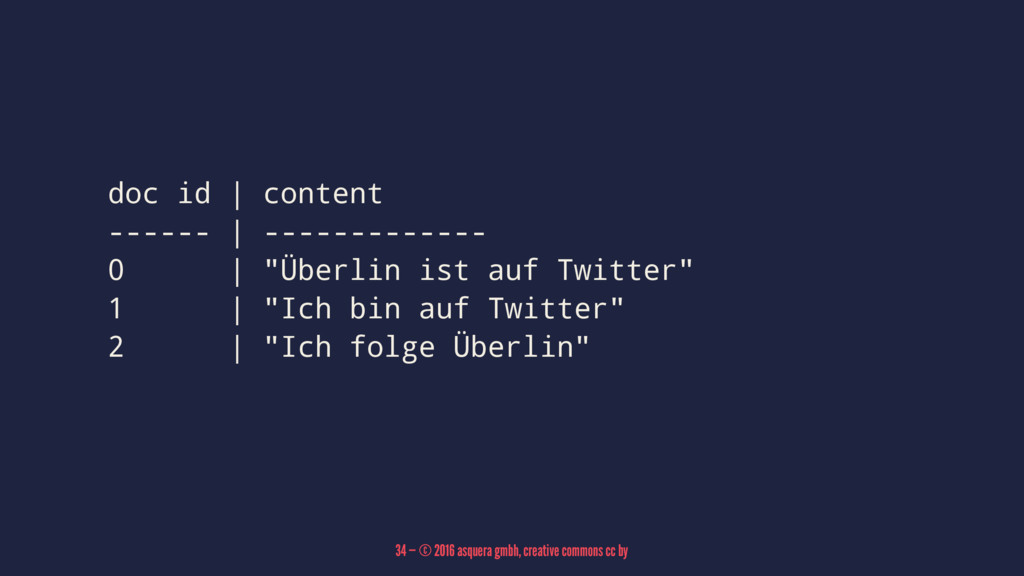
doc id | content ------ | ------------- 0 | "Überlin
ist auf Twitter" 1 | "Ich bin auf Twitter" 2 | "Ich folge Überlin" 34 — © 2016 asquera gmbh, creative commons cc by
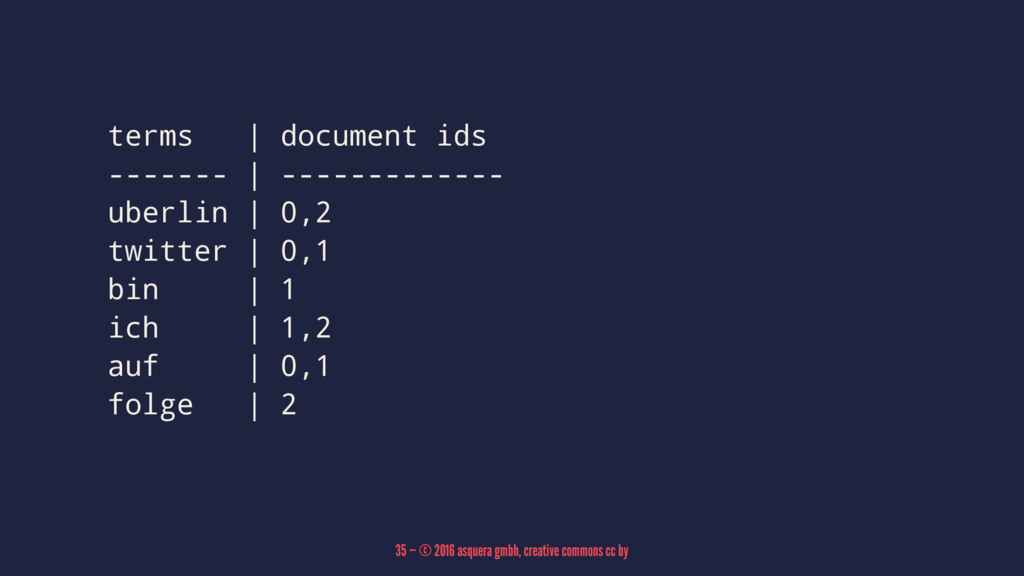
terms | document ids ------- | ------------- uberlin | 0,2
twitter | 0,1 bin | 1 ich | 1,2 auf | 0,1 folge | 2 35 — © 2016 asquera gmbh, creative commons cc by
ANALYSIS 36 — © 2016 asquera gmbh, creative commons cc
by
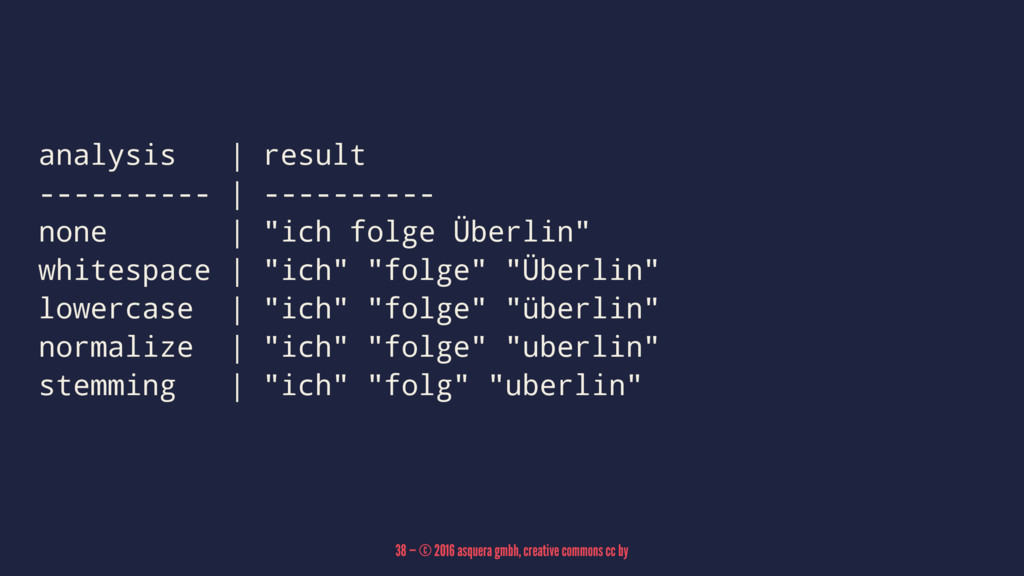
Analysis determines which terms end up at the left side
of the table in the first place. 37 — © 2016 asquera gmbh, creative commons cc by
analysis | result ---------- | ---------- none | "ich folge
Überlin" whitespace | "ich" "folge" "Überlin" lowercase | "ich" "folge" "überlin" normalize | "ich" "folge" "uberlin" stemming | "ich" "folg" "uberlin" 38 — © 2016 asquera gmbh, creative commons cc by
This step happens both on indexing and queries 39 —
© 2016 asquera gmbh, creative commons cc by
Manipulating analysis is the basis for manipulating matches. 40 —
© 2016 asquera gmbh, creative commons cc by
Ü 41 — © 2016 asquera gmbh, creative commons cc
by
Does your system comfortably speak Unicode? 42 — © 2016
asquera gmbh, creative commons cc by
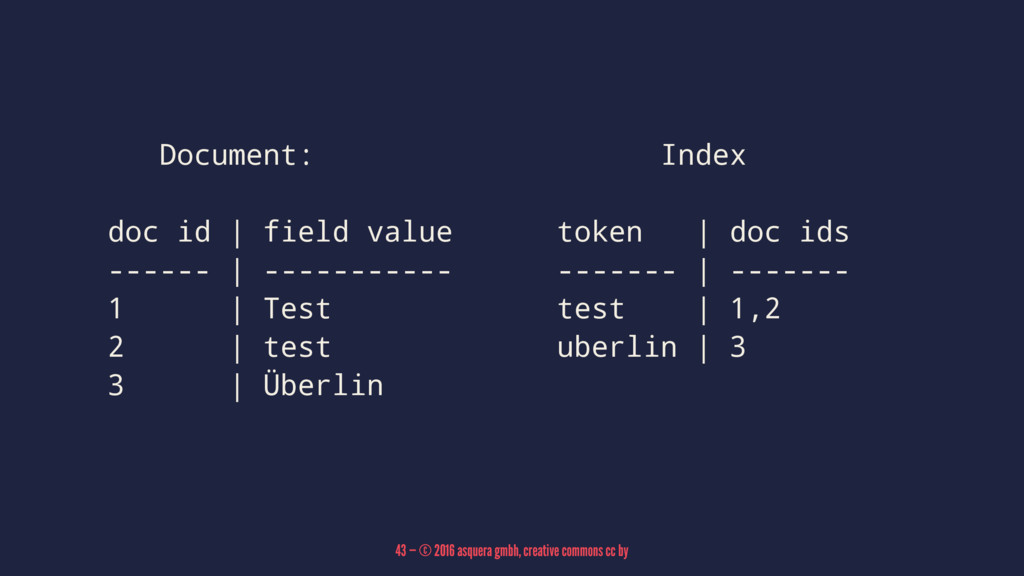
Document: Index doc id | field value token | doc
ids ------ | ----------- ------- | ------- 1 | Test test | 1,2 2 | test uberlin | 3 3 | Überlin 43 — © 2016 asquera gmbh, creative commons cc by
MONGODB 44 — © 2016 asquera gmbh, creative commons cc
by
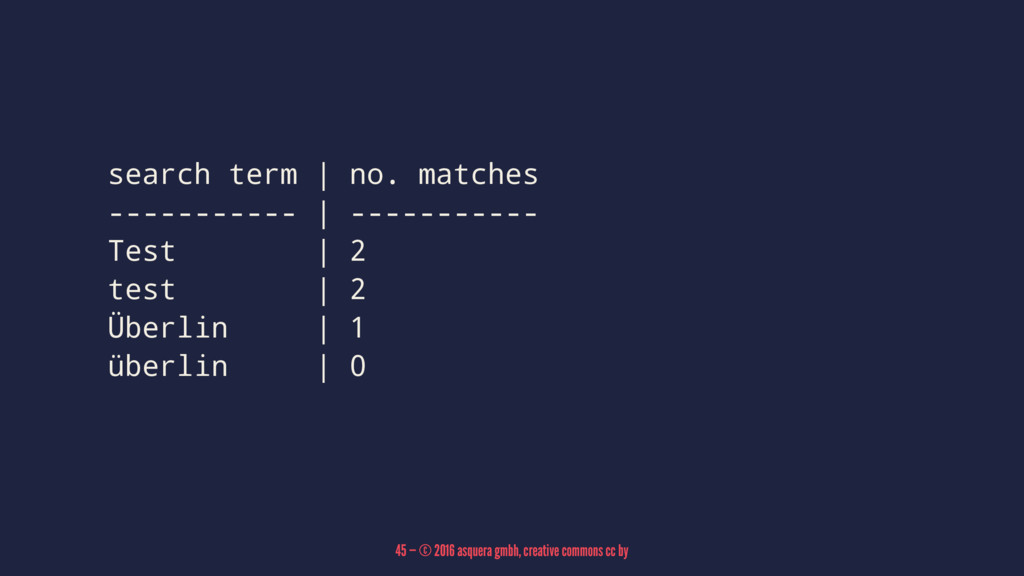
search term | no. matches ----------- | ----------- Test |
2 test | 2 Überlin | 1 überlin | 0 45 — © 2016 asquera gmbh, creative commons cc by
This particular issue has been fixed in 3.2, but others
remain, stopwords, ... 46 — © 2016 asquera gmbh, creative commons cc by
The recommendation is to preprocess the input yourself 47 —
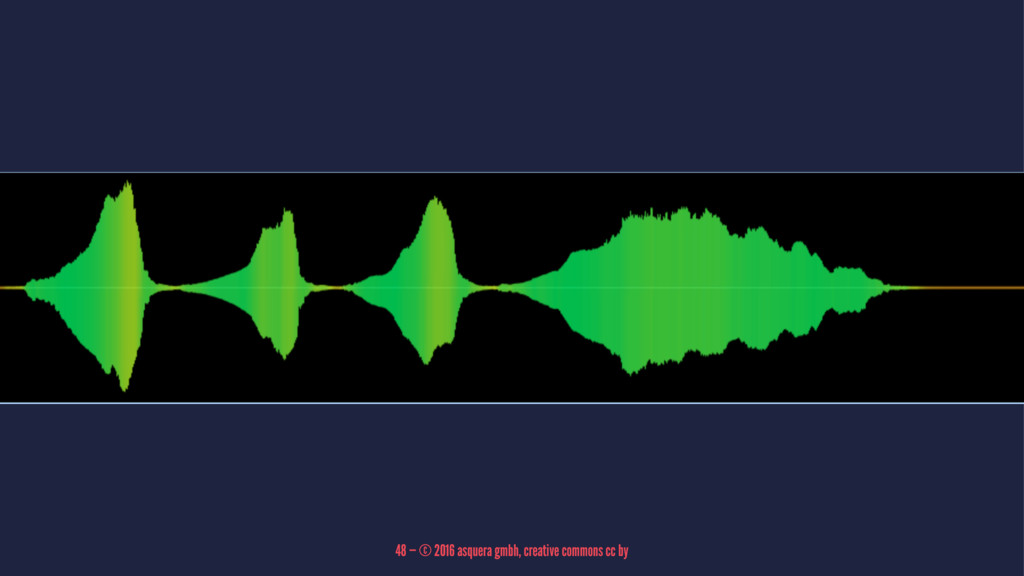
© 2016 asquera gmbh, creative commons cc by
48 — © 2016 asquera gmbh, creative commons cc by
"\u0055\u0308" "\u0075\u0308" 49 — © 2016 asquera gmbh, creative commons
cc by
"\u0055\u0308" => Ü "\u0075\u0308" => ü 50 — © 2016
asquera gmbh, creative commons cc by
PostgreSQL handles UCS-2 level 1, not UTF. 51 — ©
2016 asquera gmbh, creative commons cc by
“we should really reject combining chars, but can’t do that
w/o breaking BC.” 52 — © 2016 asquera gmbh, creative commons cc by
:sigh: SOFTWARE 53 — © 2016 asquera gmbh, creative commons
cc by
If you use PostgreSQL and text manipulation, you probably have
a bug in the hiding there. 54 — © 2016 asquera gmbh, creative commons cc by
don't ask me about MySQL full text search 55 —
© 2016 asquera gmbh, creative commons cc by
Elasticsearch handles all of this gracefully and much much more.
56 — © 2016 asquera gmbh, creative commons cc by
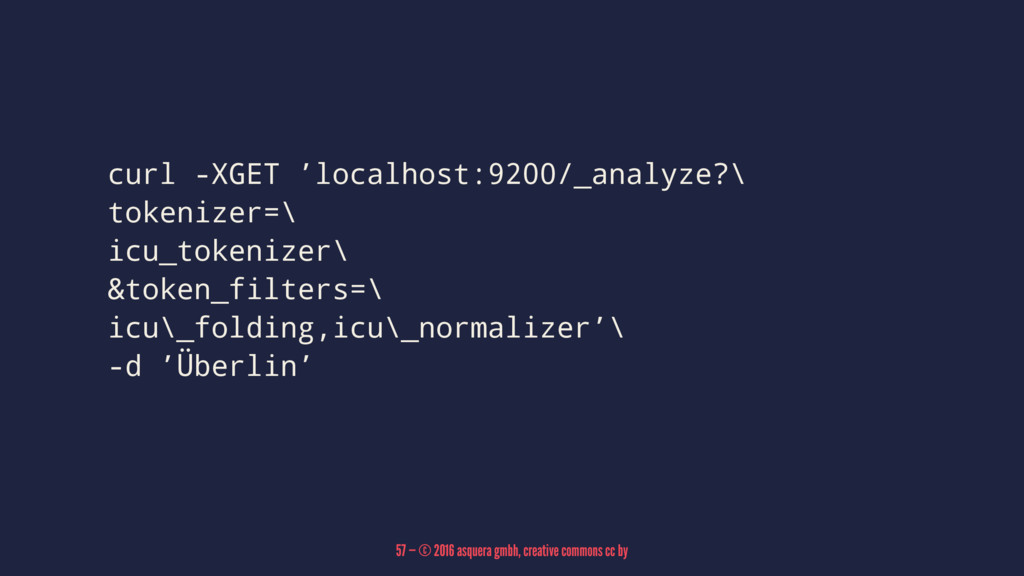
curl -XGET ’localhost:9200/_analyze?\ tokenizer=\ icu_tokenizer\ &token_filters=\ icu\_folding,icu\_normalizer’\ -d ’Überlin’ 57
— © 2016 asquera gmbh, creative commons cc by
TF/IDF 58 — © 2016 asquera gmbh, creative commons cc
by
59 — © 2016 asquera gmbh, creative commons cc by
TERM FREQUENCY / INVERSE DOCUMENT FREQUENCY 60 — © 2016
asquera gmbh, creative commons cc by
Basic idea: rank documents based on terms matched. 61 —
© 2016 asquera gmbh, creative commons cc by
TERM FREQUENCY terms that are frequent in a document get
higher scores. 62 — © 2016 asquera gmbh, creative commons cc by
INVERSE DOCUMENT FREQUENCY Terms that are frequent in the whole
Corpus get lower scores 63 — © 2016 asquera gmbh, creative commons cc by
SCORING 64 — © 2016 asquera gmbh, creative commons cc
by
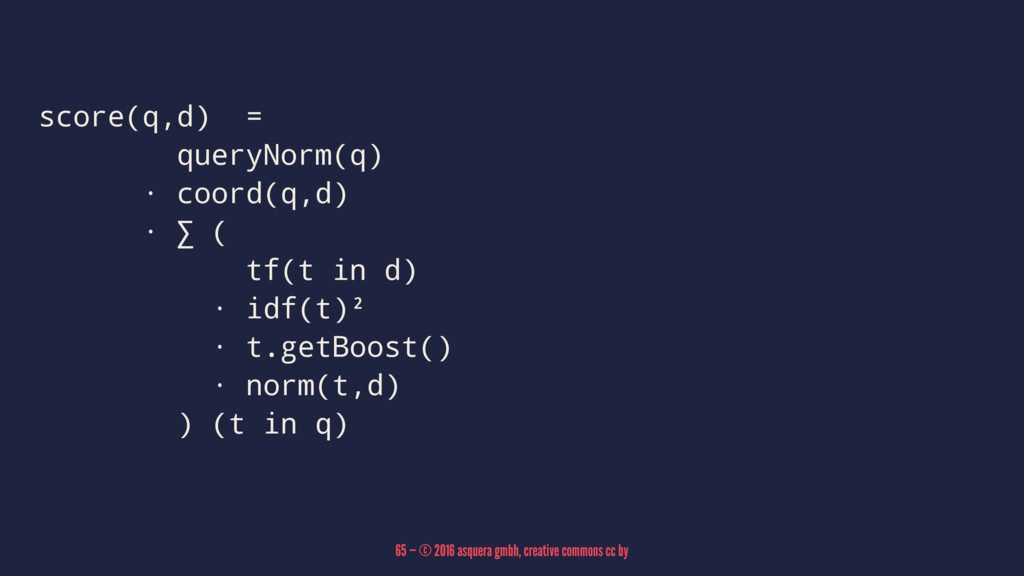
score(q,d) = queryNorm(q) · coord(q,d) · ∑ ( tf(t in
d) · idf(t)² · t.getBoost() · norm(t,d) ) (t in q) 65 — © 2016 asquera gmbh, creative commons cc by
Search is all about relevance and combinations thereof. 66 —
© 2016 asquera gmbh, creative commons cc by
Was the match in the title or the body of
a document? 67 — © 2016 asquera gmbh, creative commons cc by
Many systems can weight matches on fields differently. 68 —
© 2016 asquera gmbh, creative commons cc by
But many systems only support changing weights at index time.
(PostgreSQL, MongoDB) 69 — © 2016 asquera gmbh, creative commons cc by
With Elasticsearch, weights can be changed at query time. 70
— © 2016 asquera gmbh, creative commons cc by
Scores can be manipulated at query time based on geo-coordinates,
recency, manual boosting, ... 71 — © 2016 asquera gmbh, creative commons cc by
PHRASE SEARCH AND STOPWORDS doc id | content ------ |
------------- 1 | "Ich bin auf Twitter" 2 | "Ich folge Überlin" 72 — © 2016 asquera gmbh, creative commons cc by
INDEXED WITH GERMAN STOPWORDS terms | document ids ------- |
------------- bin | 1 twitter | 1 uberlin | 2 folge | 2 73 — © 2016 asquera gmbh, creative commons cc by
SCORING TAKES TIME AND EXPERIMENTATION 74 — © 2016 asquera
gmbh, creative commons cc by
Search systems are not binary. Faults in the system degrade
the quality of the system, rarely break it. 75 — © 2016 asquera gmbh, creative commons cc by
Building a relevance model is usually the biggest part of
a natural language search. 76 — © 2016 asquera gmbh, creative commons cc by
requires careful balancing of multiple, sometimes contradictory, demands to achieve
the best result 77 — © 2016 asquera gmbh, creative commons cc by
WHERE TO GO FROM HERE 78 — © 2016 asquera
gmbh, creative commons cc by
THANK YOU 79 — © 2016 asquera gmbh, creative commons
cc by
IMAGE CREDITS page 58: Taken from Britta Webers presentation at
ES UG Berlin, Wednesday, October 30, 13 80 — © 2016 asquera gmbh, creative commons cc by
{kind=link}
![WHOAMI $ cat .profile GIT_AUTHOR_NAME=Felix Gilcher [email protected] TM_COMPANY=Asquera GmbH TWITTER_HANDLE=xylakant](https://files.speakerdeck.com/presentations/3ab1381647fa492b97235df51965db0f/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}