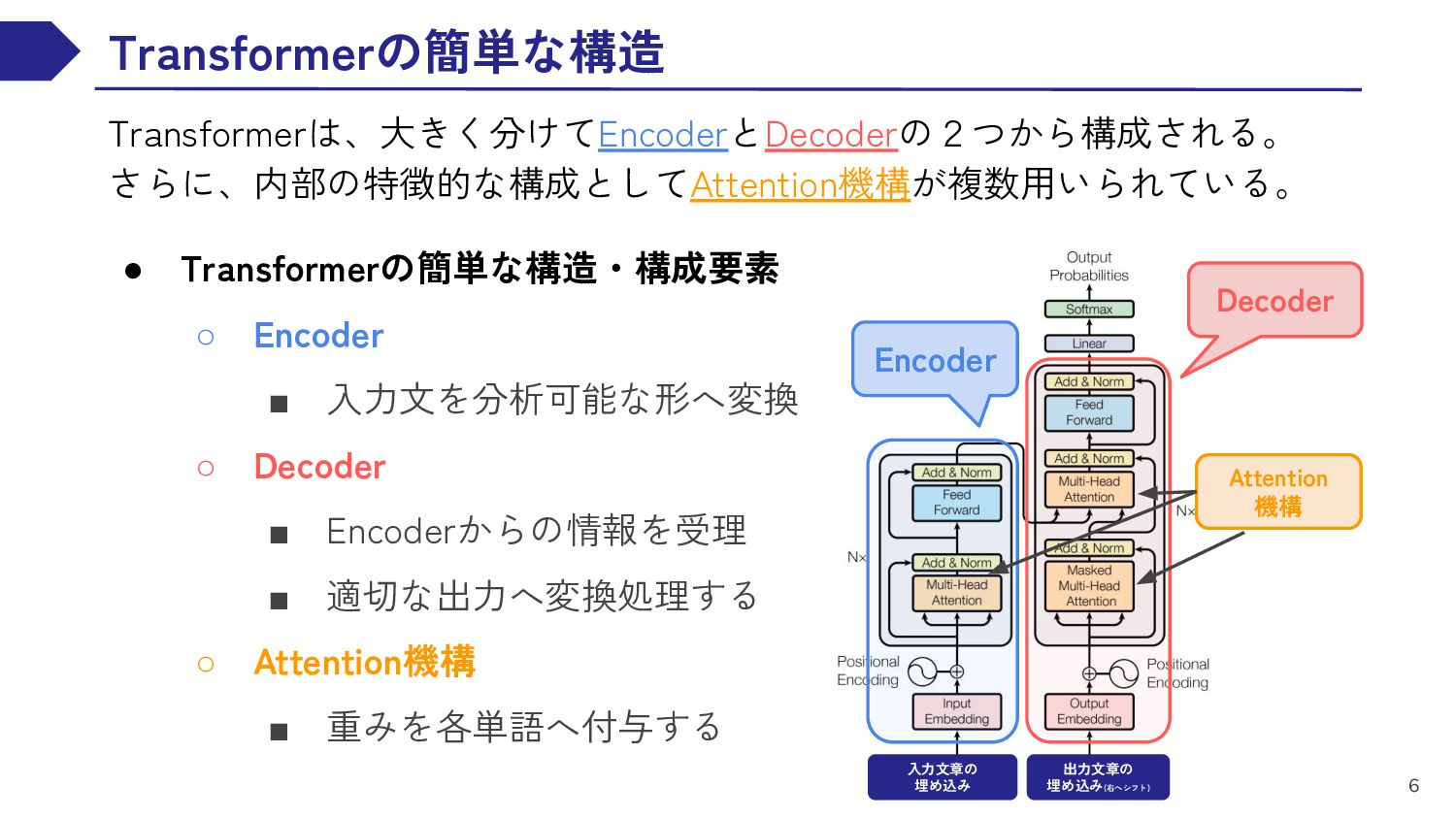
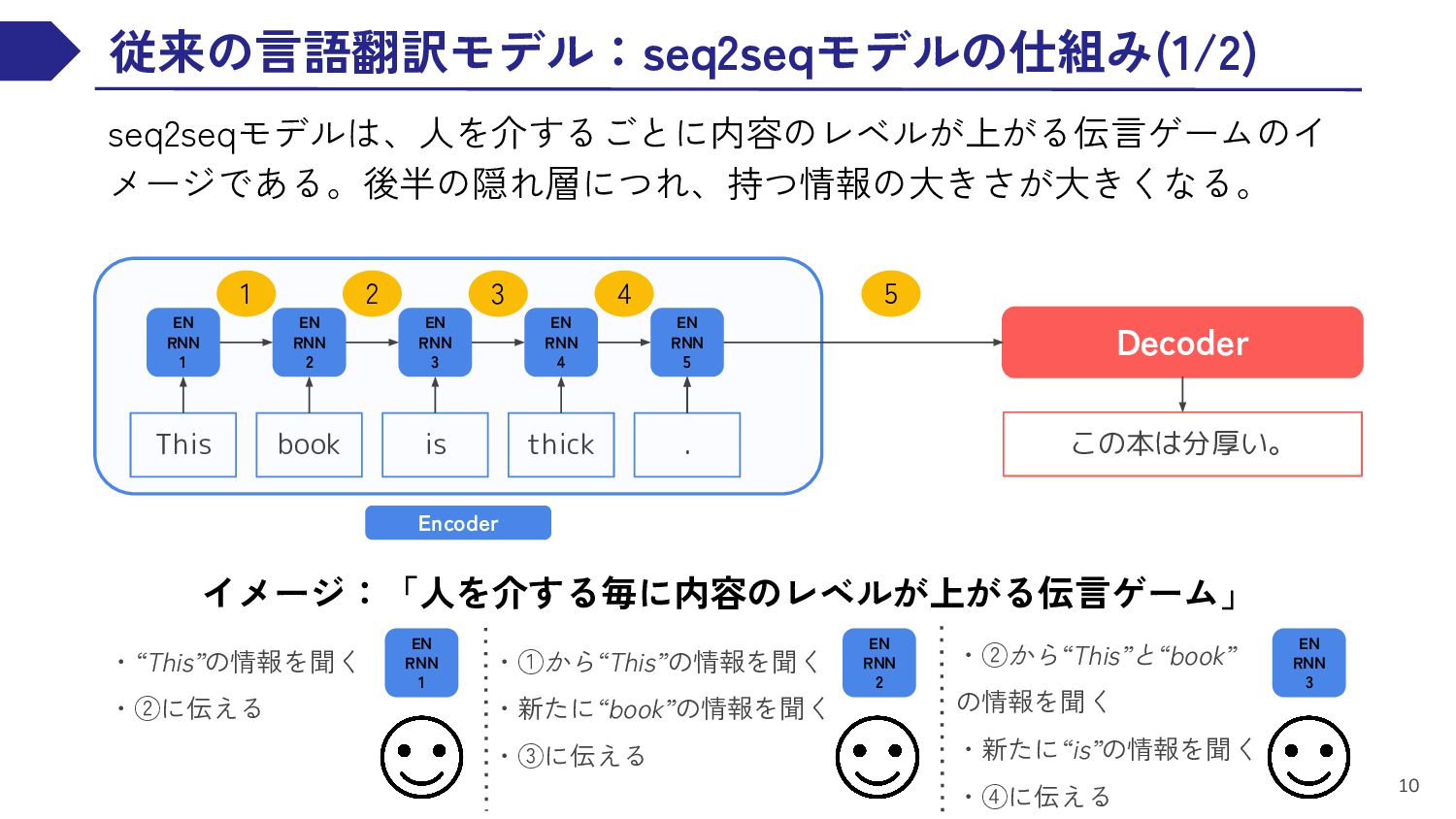
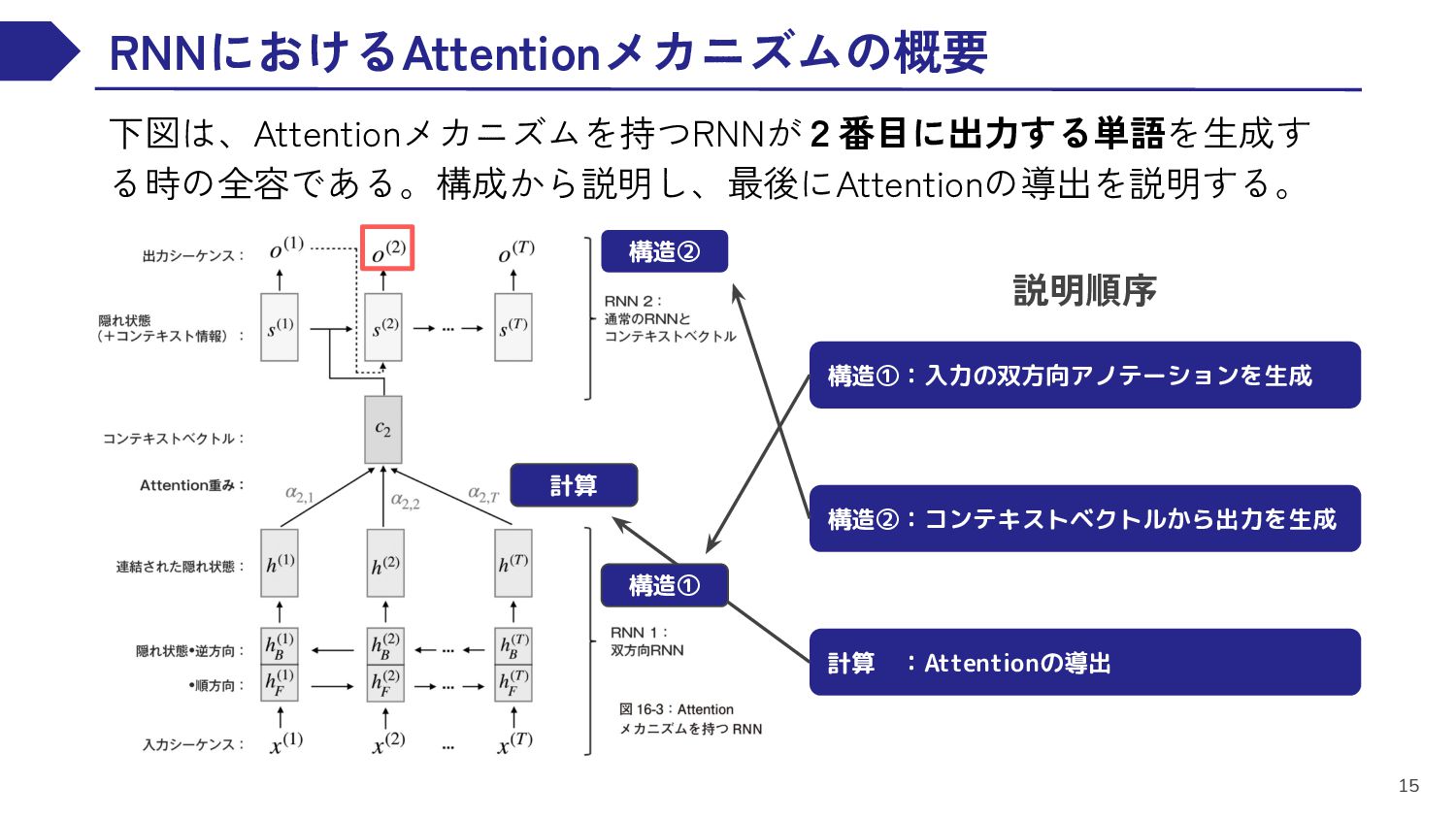
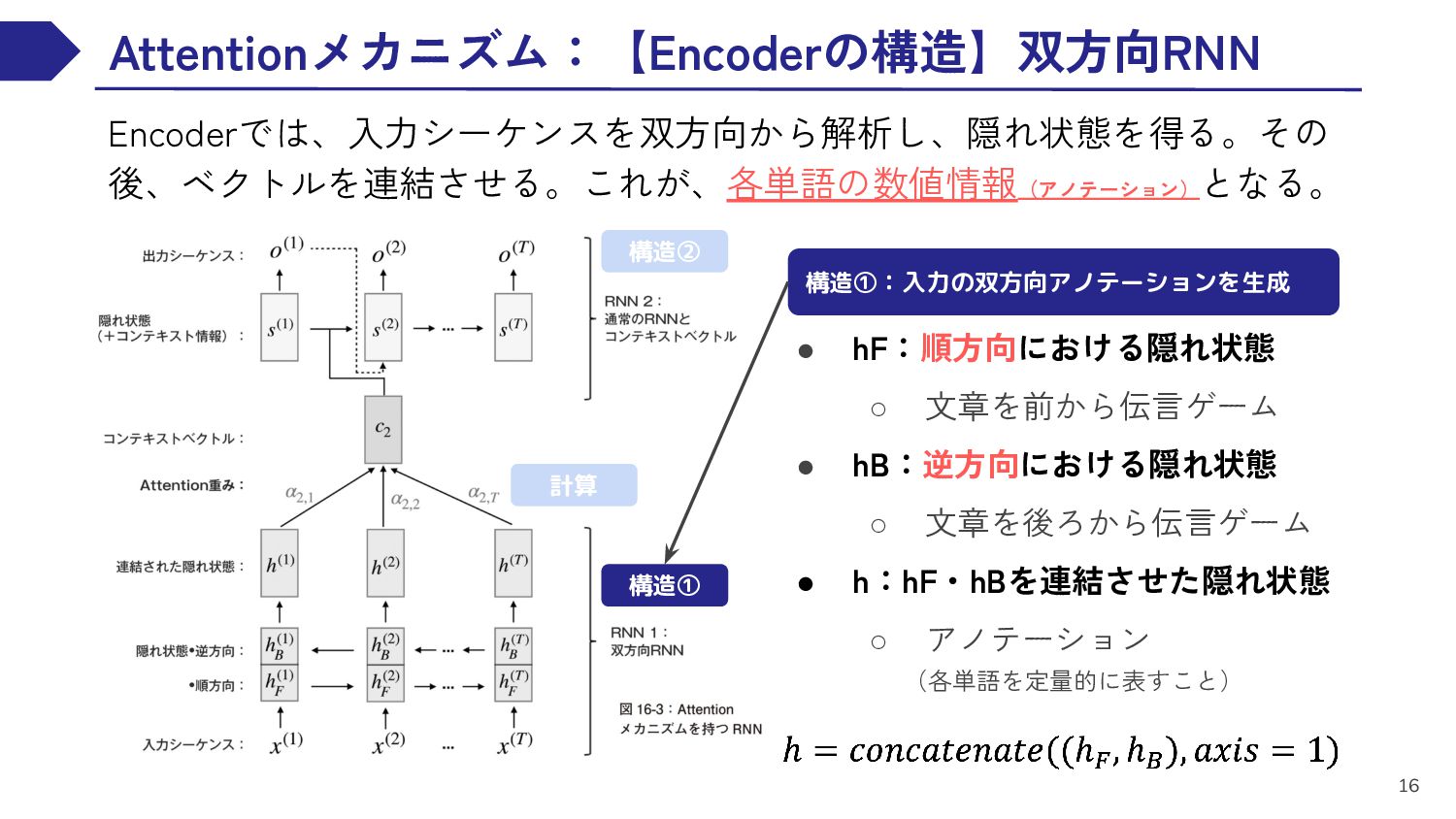
EN RNN This book is thick EN RNN . DE RNN DE RNN DE RNN DE RNN この 本 は 分厚い DE RNN 。 DE RNN <EOS> <BOS> この 本 は 分厚い 。 1 2 3 4 5 Encoder Decoder 入力文を分析可能な形へ変換 Encoderからの情報を受理 適切な出力へ変換処理
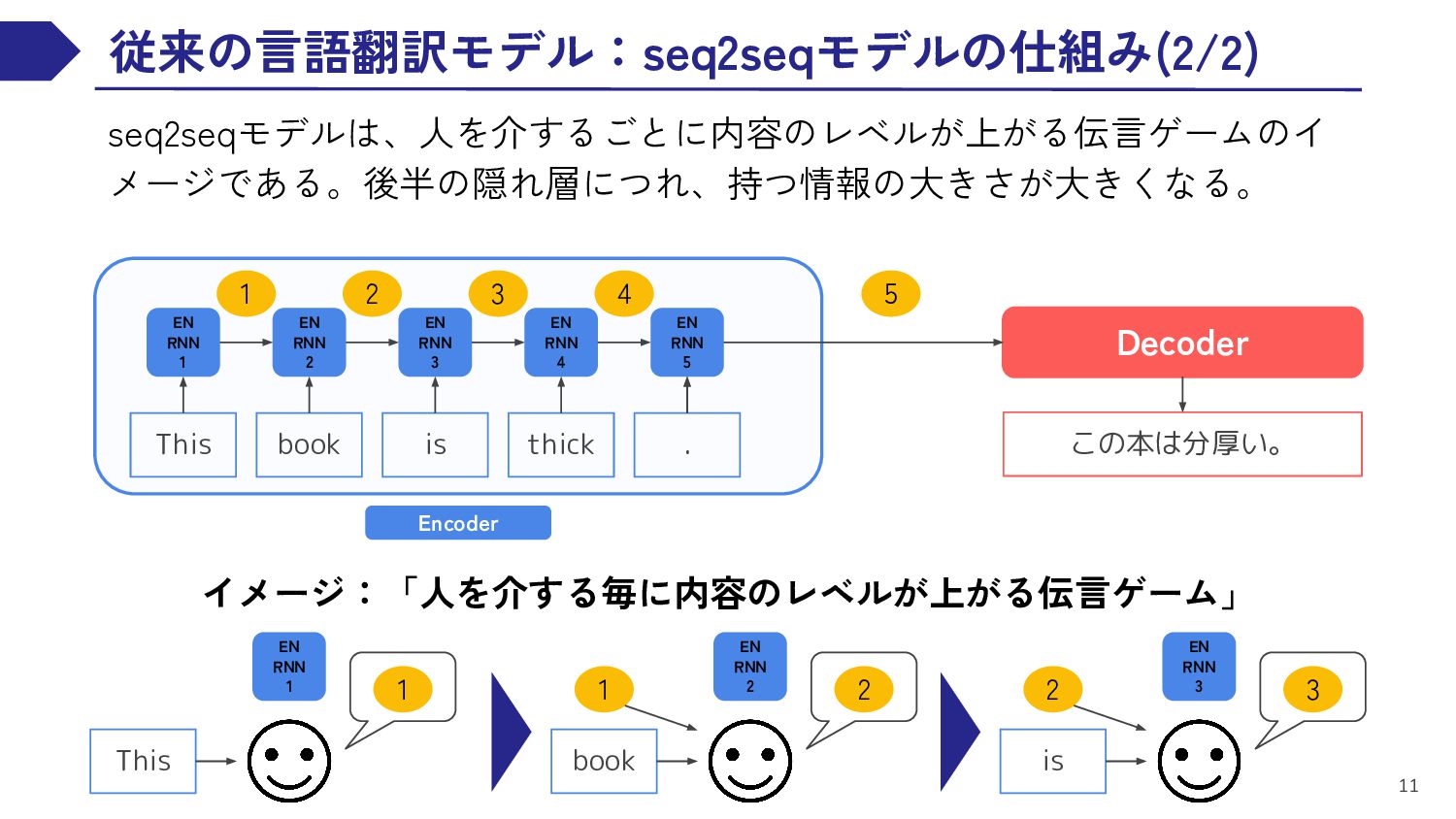
EN RNN 3 EN RNN 4 This book is thick EN RNN 5 . 1 2 3 4 5 Decoder ・“This”の情報を聞く ・②に伝える この本は分厚い。 Encoder ・①から“This”の情報を聞く ・新たに“book”の情報を聞く ・③に伝える ・②から“This”と“book” の情報を聞く ・新たに“is”の情報を聞く ・④に伝える EN RNN 1 EN RNN 2 EN RNN 3 イメージ:「人を介する毎に内容のレベルが上がる伝言ゲーム」
EN RNN 3 EN RNN 4 This book is thick EN RNN 5 . 1 2 3 4 5 Decoder この本は分厚い。 Encoder EN RNN 1 This 1 EN RNN 2 book 2 1 EN RNN 3 is 3 2 イメージ:「人を介する毎に内容のレベルが上がる伝言ゲーム」
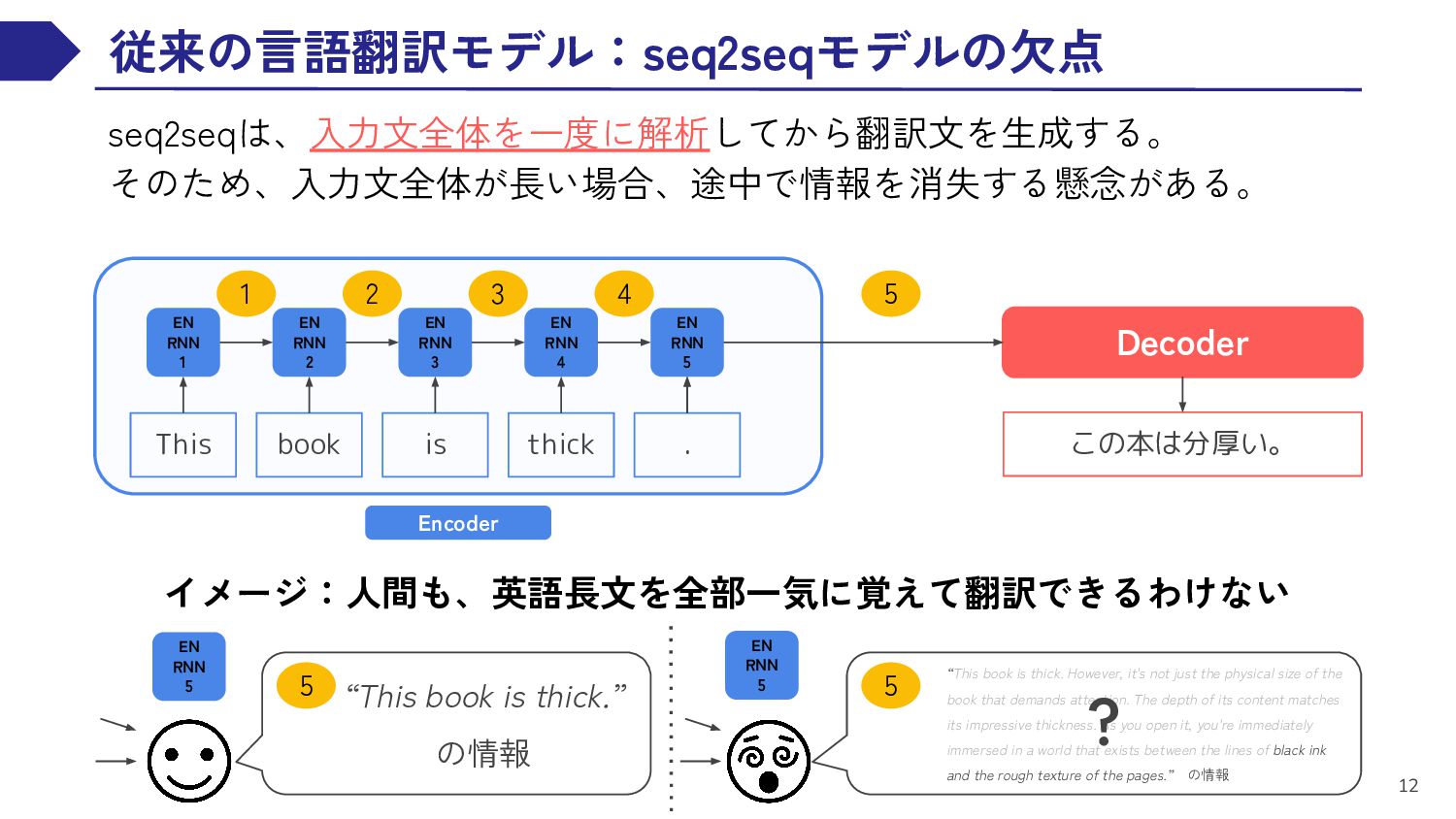
EN RNN 3 EN RNN 4 This book is thick EN RNN 5 . 1 2 3 4 5 Decoder イメージ:人間も、英語長文を全部一気に覚えて翻訳できるわけない この本は分厚い。 Encoder EN RNN 5 5 “This book is thick.” の情報 EN RNN 5 5 “This book is thick. However, it's not just the physical size of the book that demands attention. The depth of its content matches its impressive thickness. As you open it, you're immediately immersed in a world that exists between the lines of black ink and the rough texture of the pages.” の情報 ?
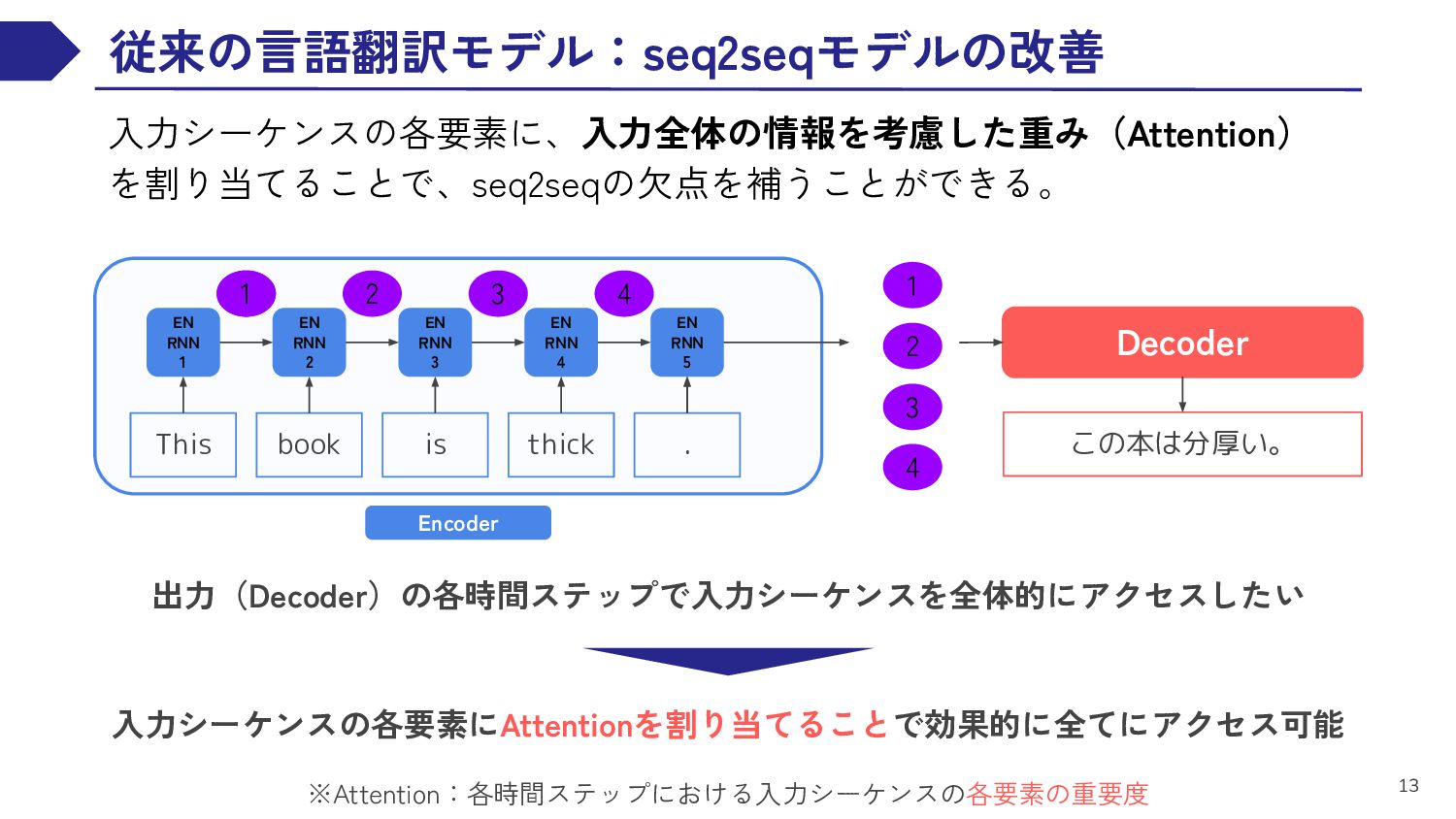
EN RNN 3 EN RNN 4 This book is thick EN RNN 5 . 1 2 3 4 Decoder 出力(Decoder)の各時間ステップで入力シーケンスを全体的にアクセスしたい この本は分厚い。 Encoder 入力シーケンスの各要素にAttentionを割り当てることで効果的に全てにアクセス可能 1 1 3 4 2 ※Attention:各時間ステップにおける入力シーケンスの各要素の重要度
not just the physical size of the book that demands attention. The depth of its content matches its impressive thickness. As you open it, you're immediately immersed in a world that exists between the lines of black ink and the rough texture of the pages.” ※Attention:各時間ステップにおける入力シーケンスの各要素の重要度 〜Attentionのイメージ〜 「この文字を理解したい時は、ここら辺の文字に注目(Attention)しろ!」
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
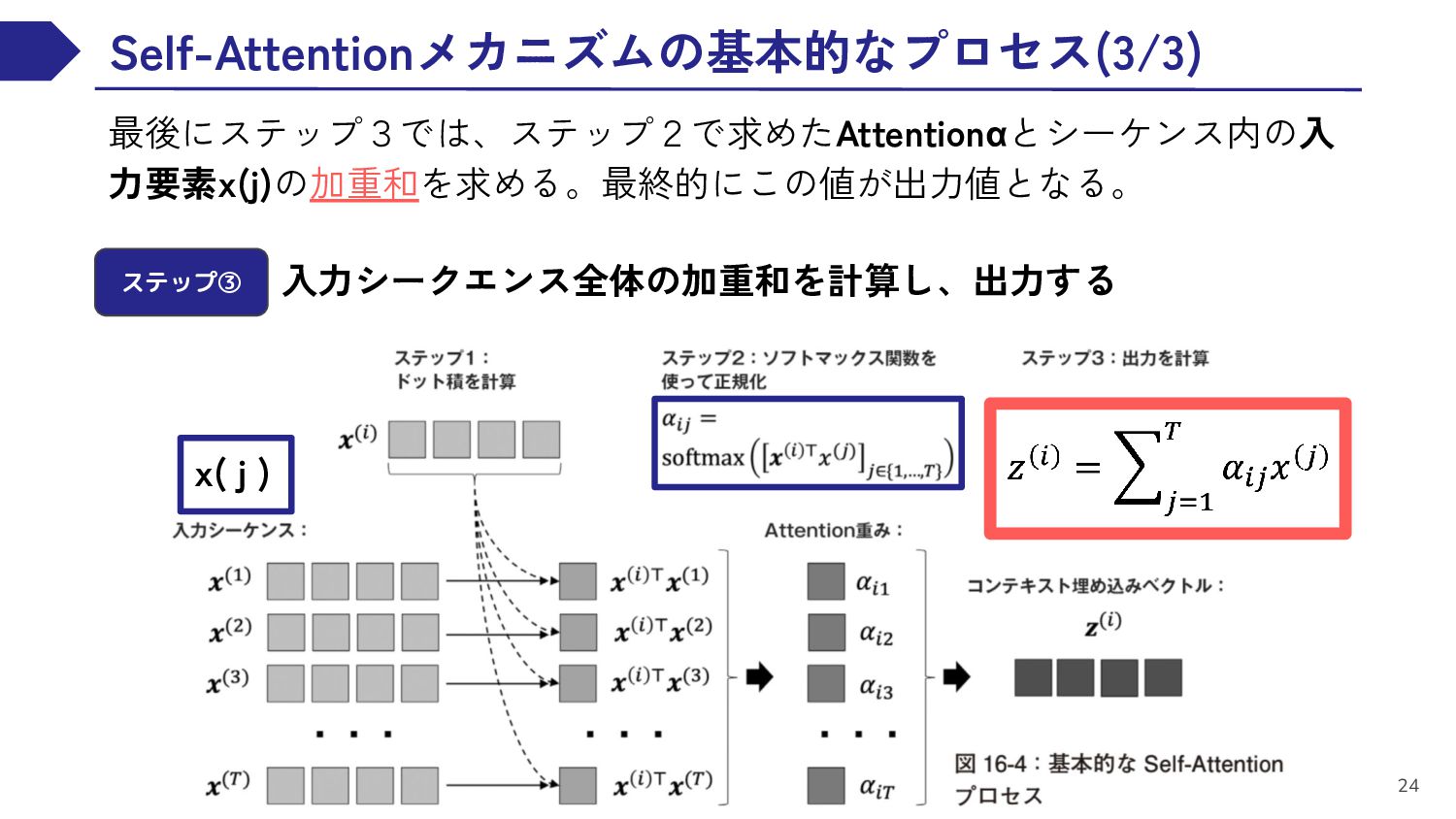{kind=link}
{kind=link}
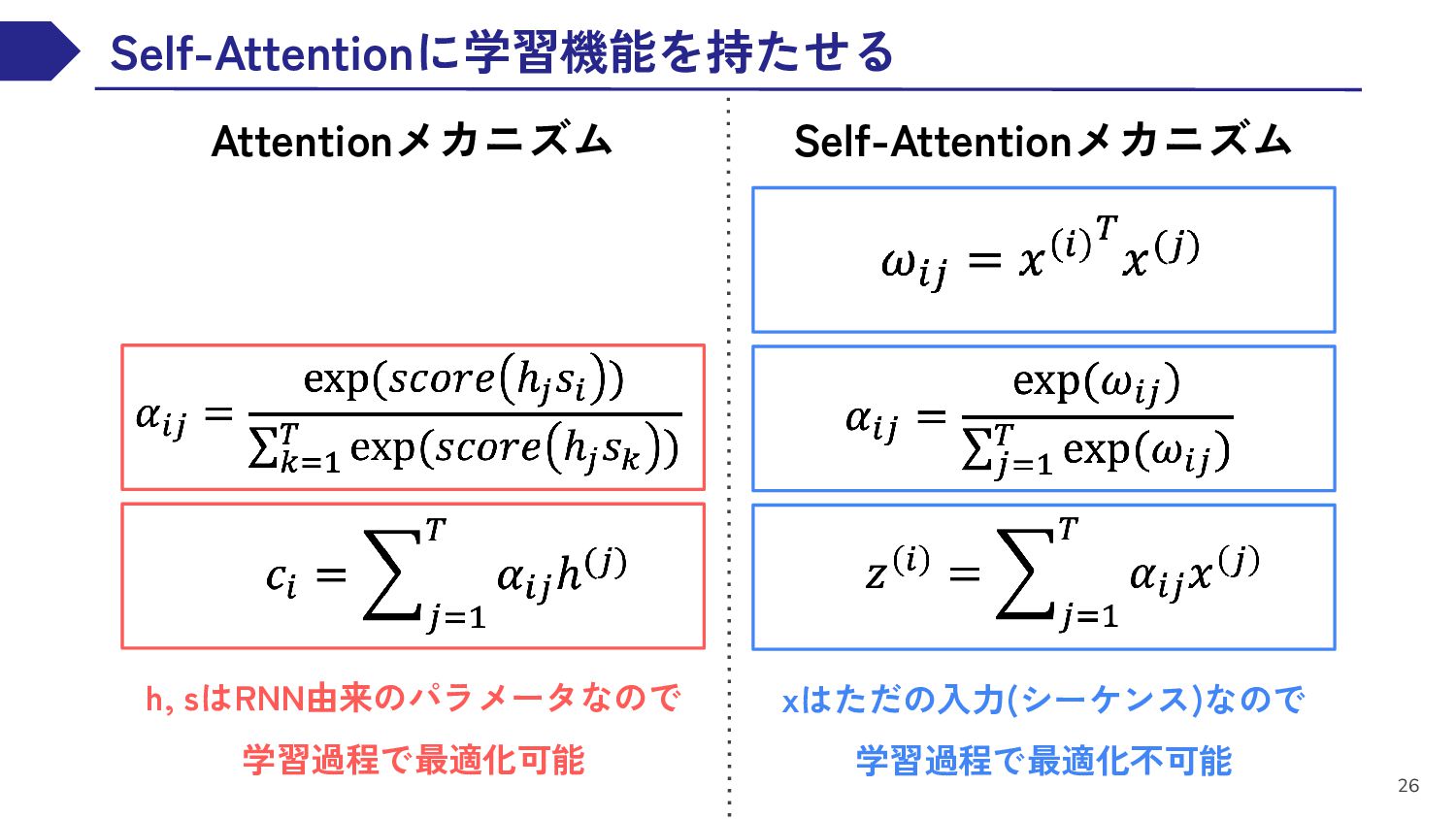{kind=link}
{kind=link}
{kind=link}
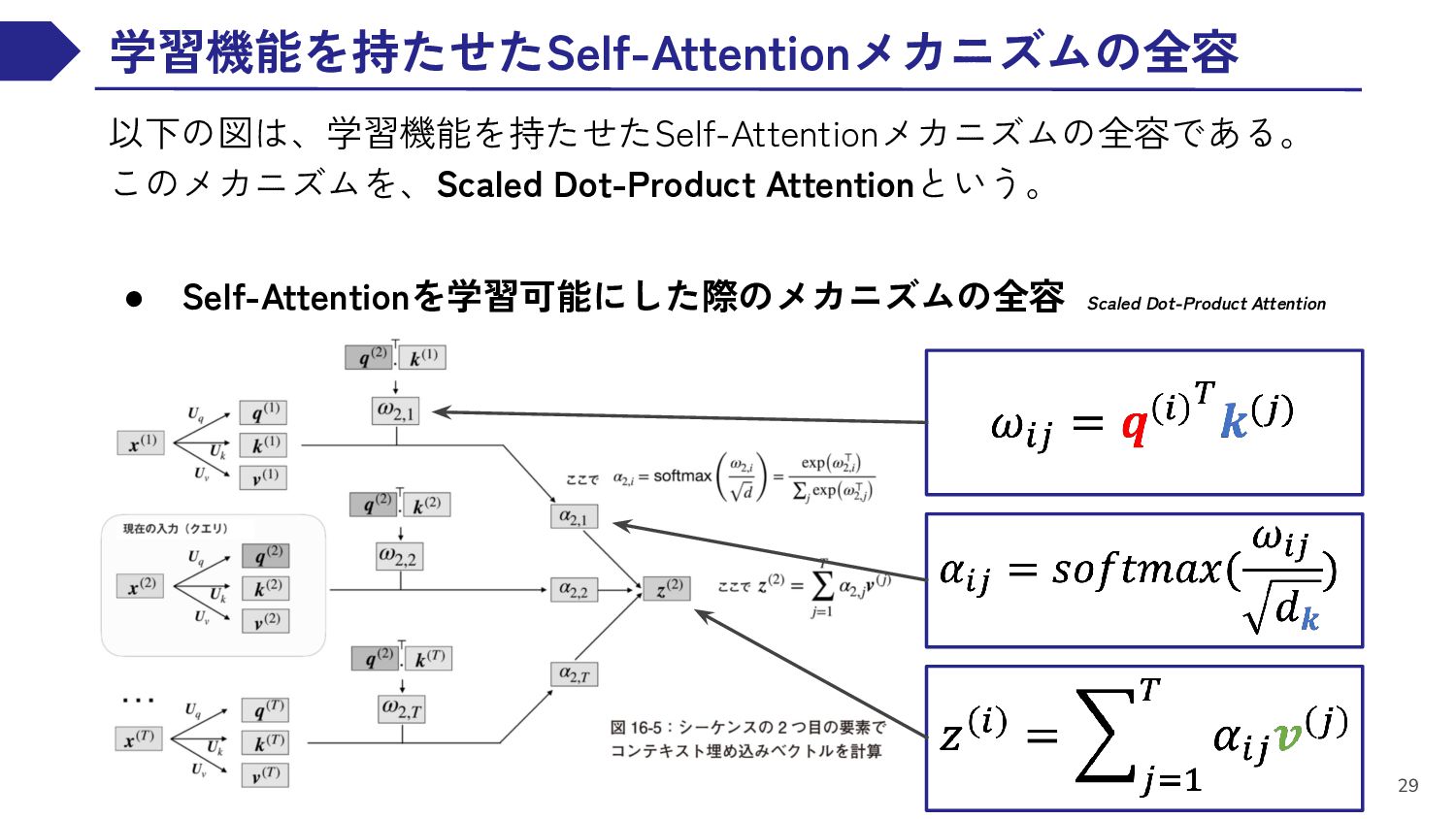{kind=link}
{kind=link}
{kind=link}
{kind=link}
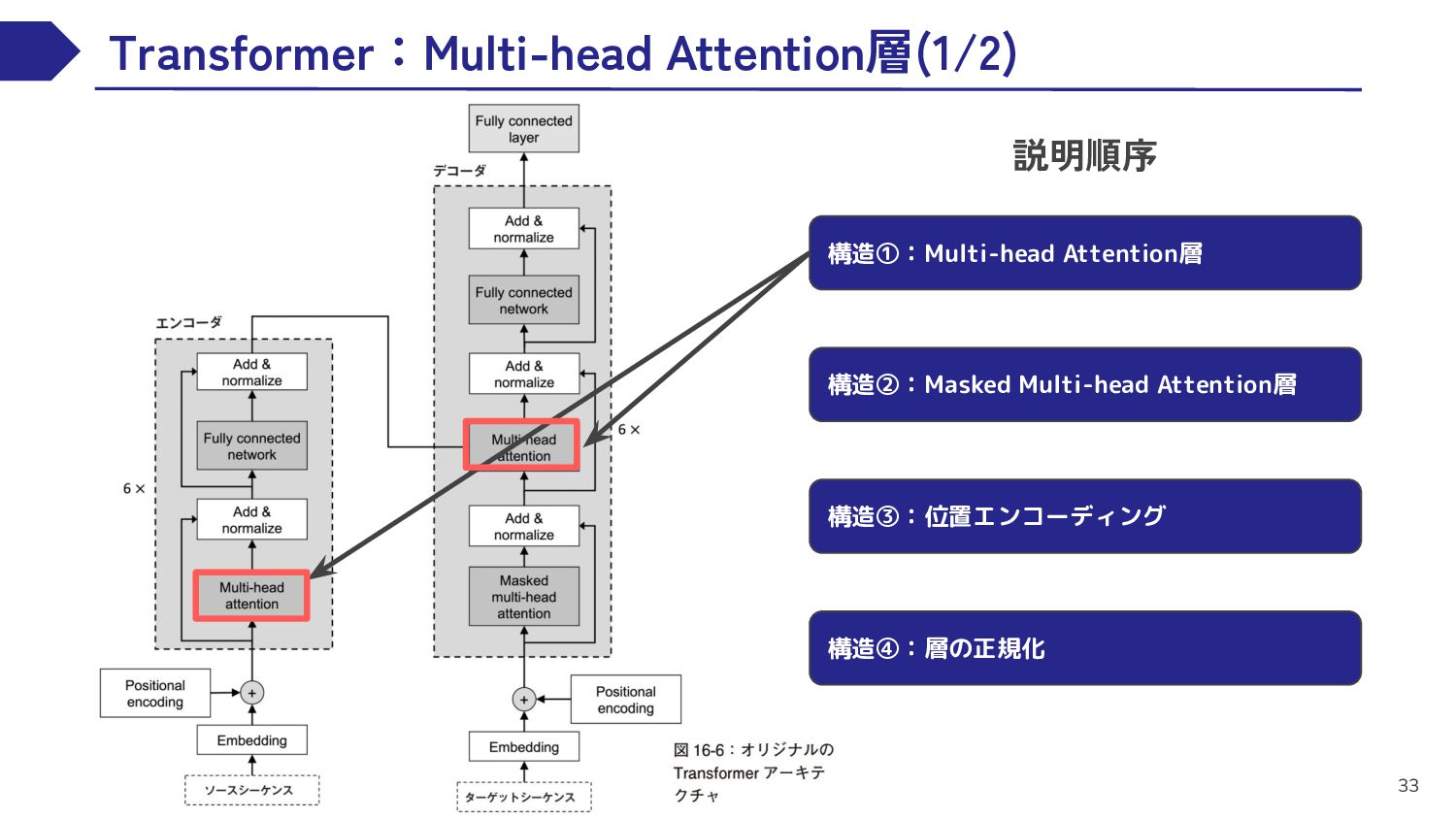{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
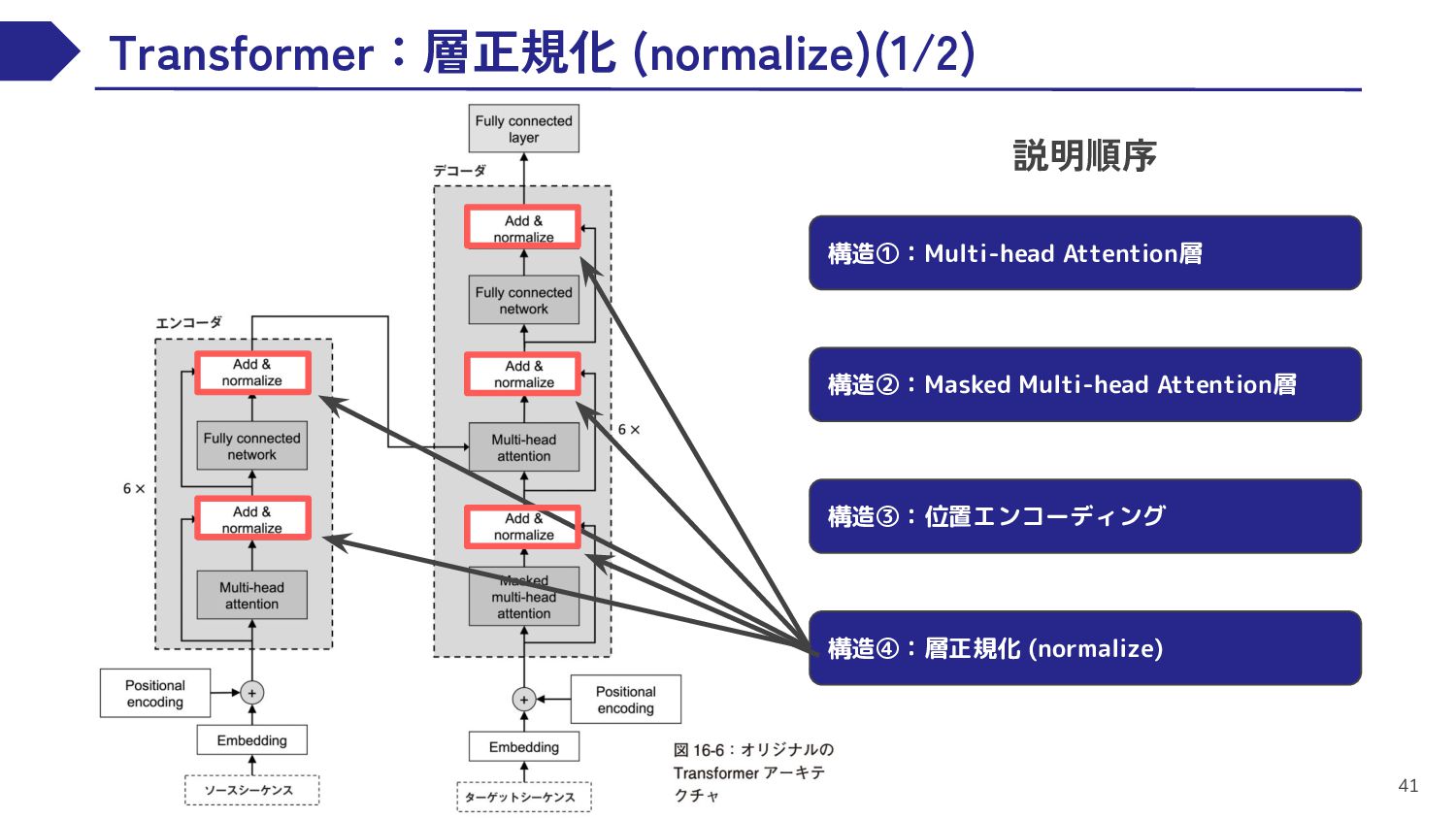{kind=link}
{kind=link}
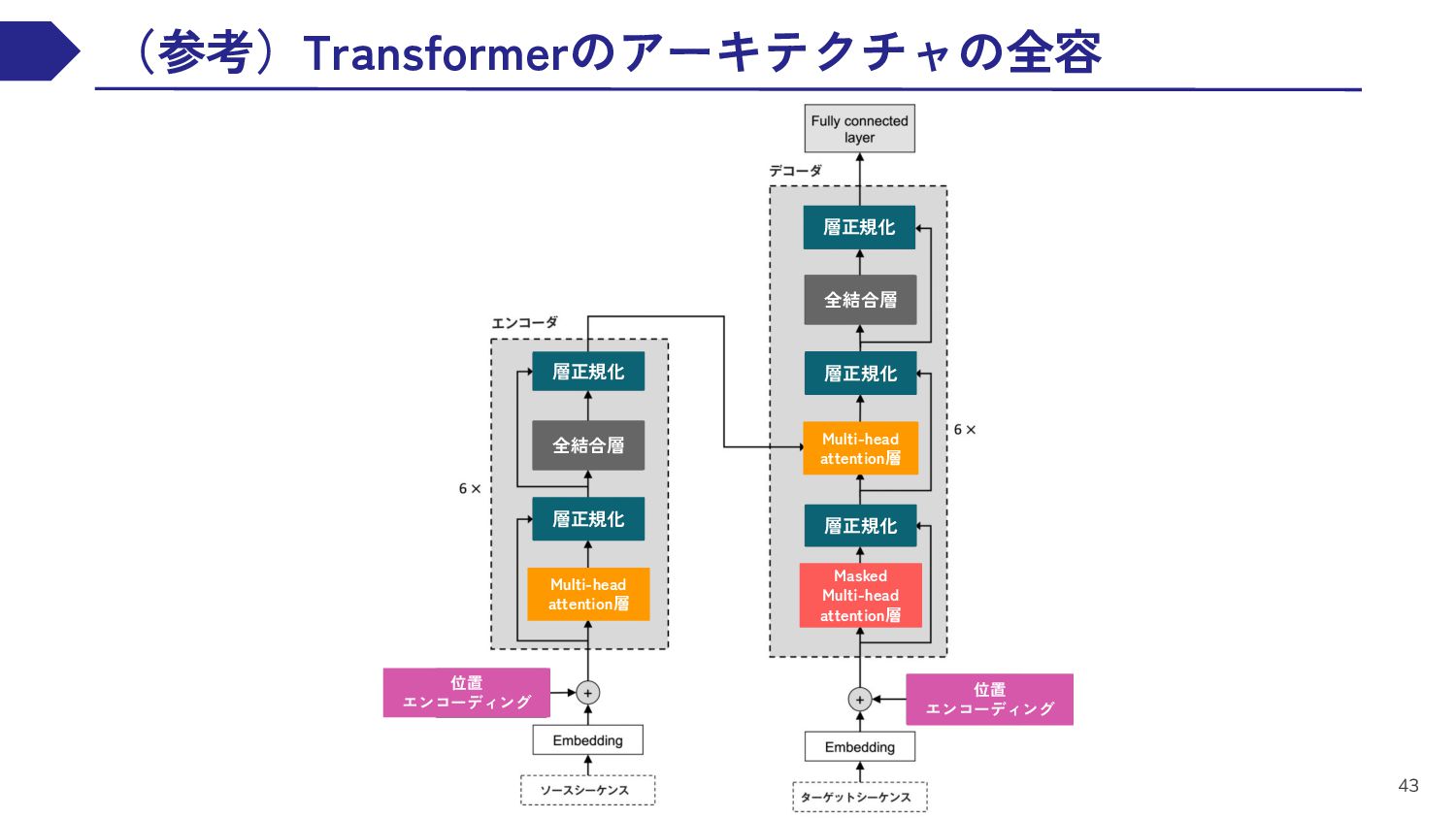{kind=link}
{kind=link}