対称行列である→ s(a, b) = s(b, a) ◦ スコアの定義は対数オッズによって定められる アミノ酸aの出現確率 アミノ酸bの出現確率 アミノ酸a,bが配列アライメント で並べられる確率 s(a, b) >=0:類似性の高い組み合わせ s(a, b) <0:類似性の低い組み合わせ 対数オッズ 9
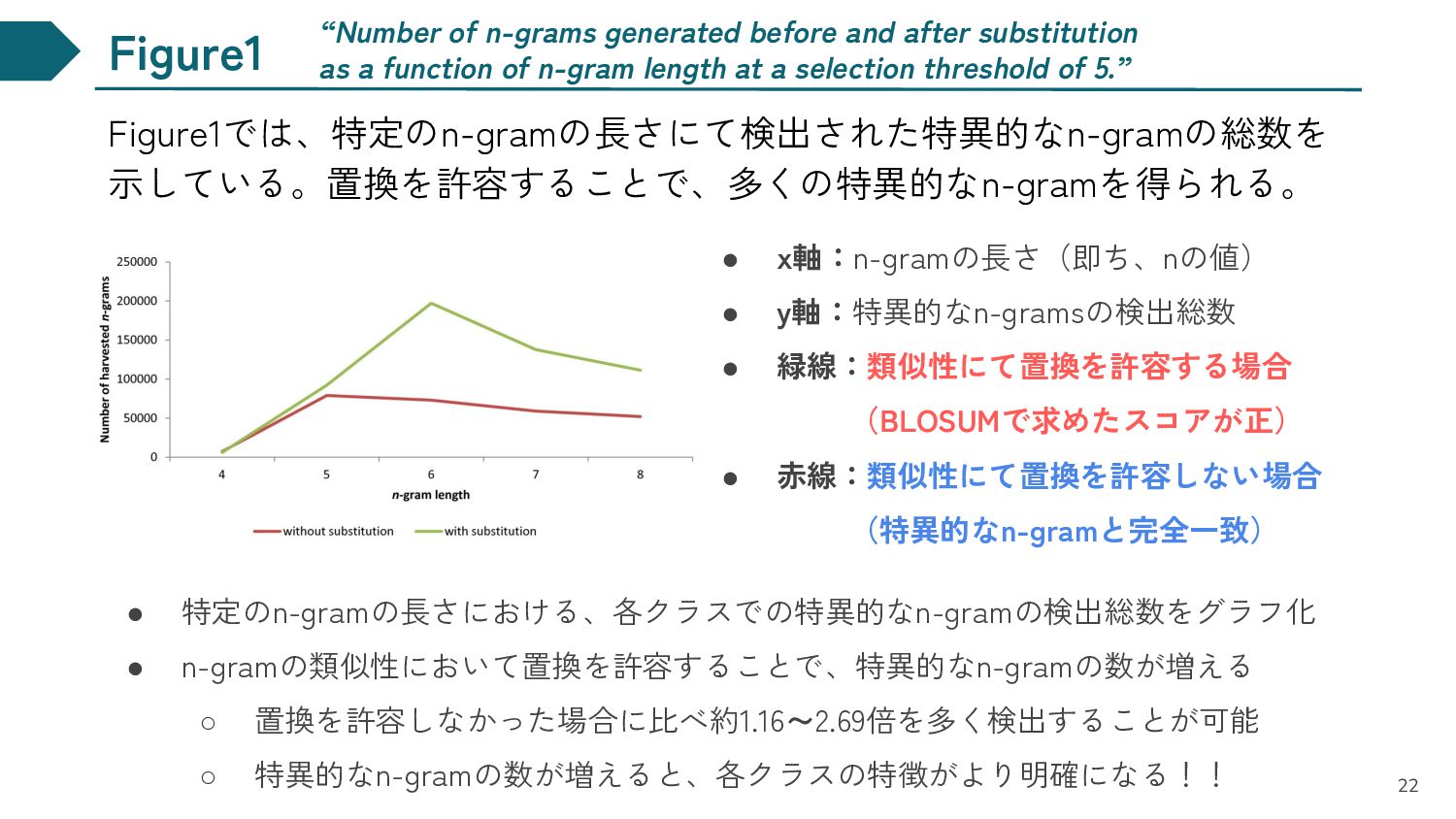
• 赤線:類似性にて置換を許容しない場合 (特異的なn-gramと完全一致) “Number of n-grams generated before and after substitution as a function of n-gram length at a selection threshold of 5.” • 特定のn-gramの長さにおける、各クラスでの特異的なn-gramの検出総数をグラフ化 • n-gramの類似性において置換を許容することで、特異的なn-gramの数が増える ◦ 置換を許容しなかった場合に比べ約1.16~2.69倍を多く検出することが可能 ◦ 特異的なn-gramの数が増えると、各クラスの特徴がより明確になる!! 22
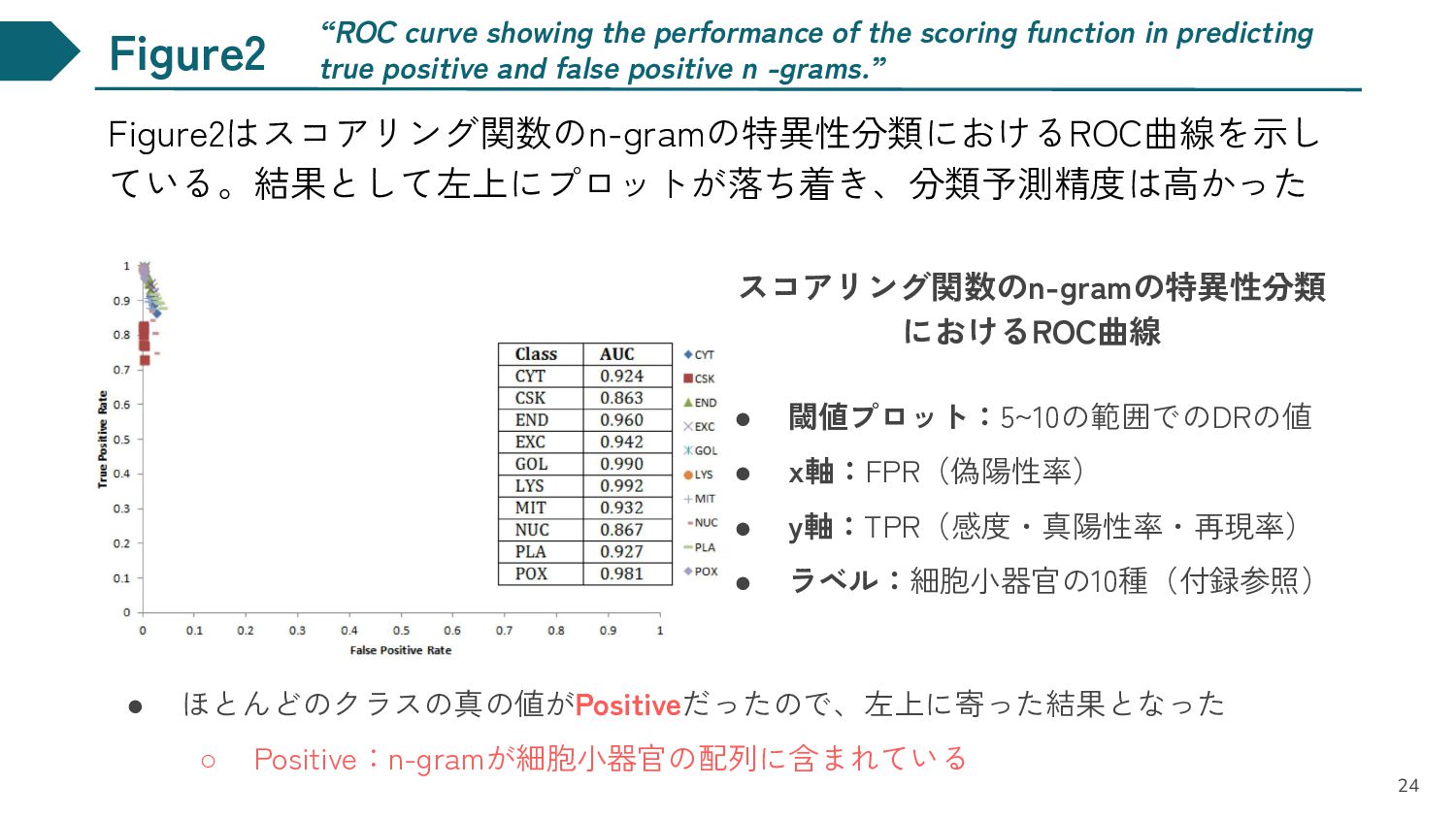
y軸:TPR(感度・真陽性率・再現率) • ラベル:細胞小器官の10種(付録参照) “ROC curve showing the performance of the scoring function in predicting true positive and false positive n -grams.” • ほとんどのクラスの真の値がPositiveだったので、左上に寄った結果となった ◦ Positive:n-gramが細胞小器官の配列に含まれている 24
and non-discriminative regions masked with ‘X’.” • 特異的なn-gramの部分を赤文字、特異性を見出せなかった部分は黒文字でXと記載 • 異なるタンパク質ファミリーの中で特定のパターンが共有されているかが確認可能 • タンパク質の機能注釈や、新たなタンパク質の分類に有用である 26
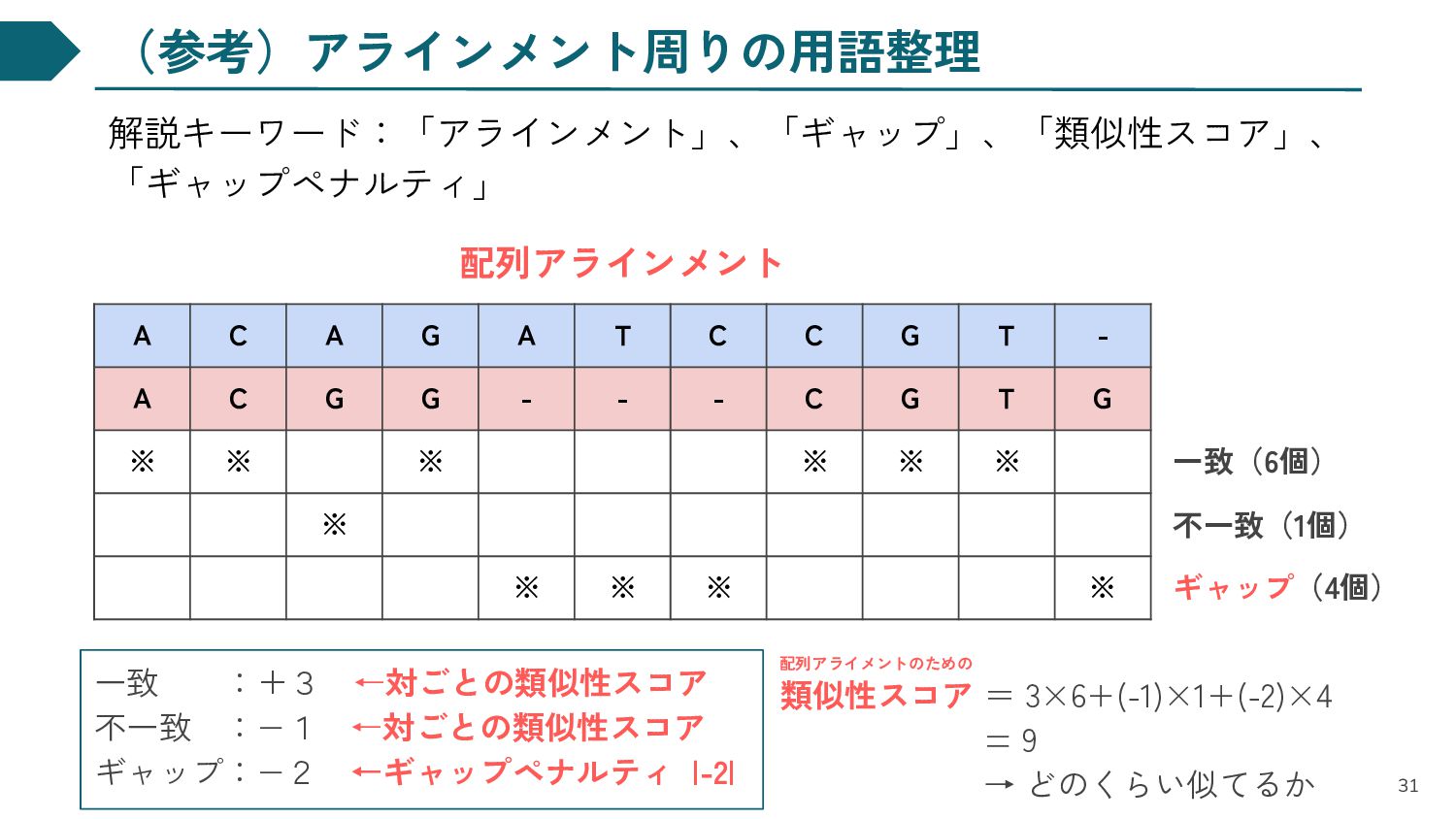
C G T - A C G G - - - C G T G ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ 一致(6個) 不一致(1個) ギャップ(4個) 一致 :+3 ←対ごとの類似性スコア 不一致 :−1 ←対ごとの類似性スコア ギャップ:−2 ←ギャップペナルティ |-2| 類似性スコア = 3×6+(-1)×1+(-2)×4 = 9 → どのくらい似てるか 配列アラインメント 配列アライメントのための 31
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}