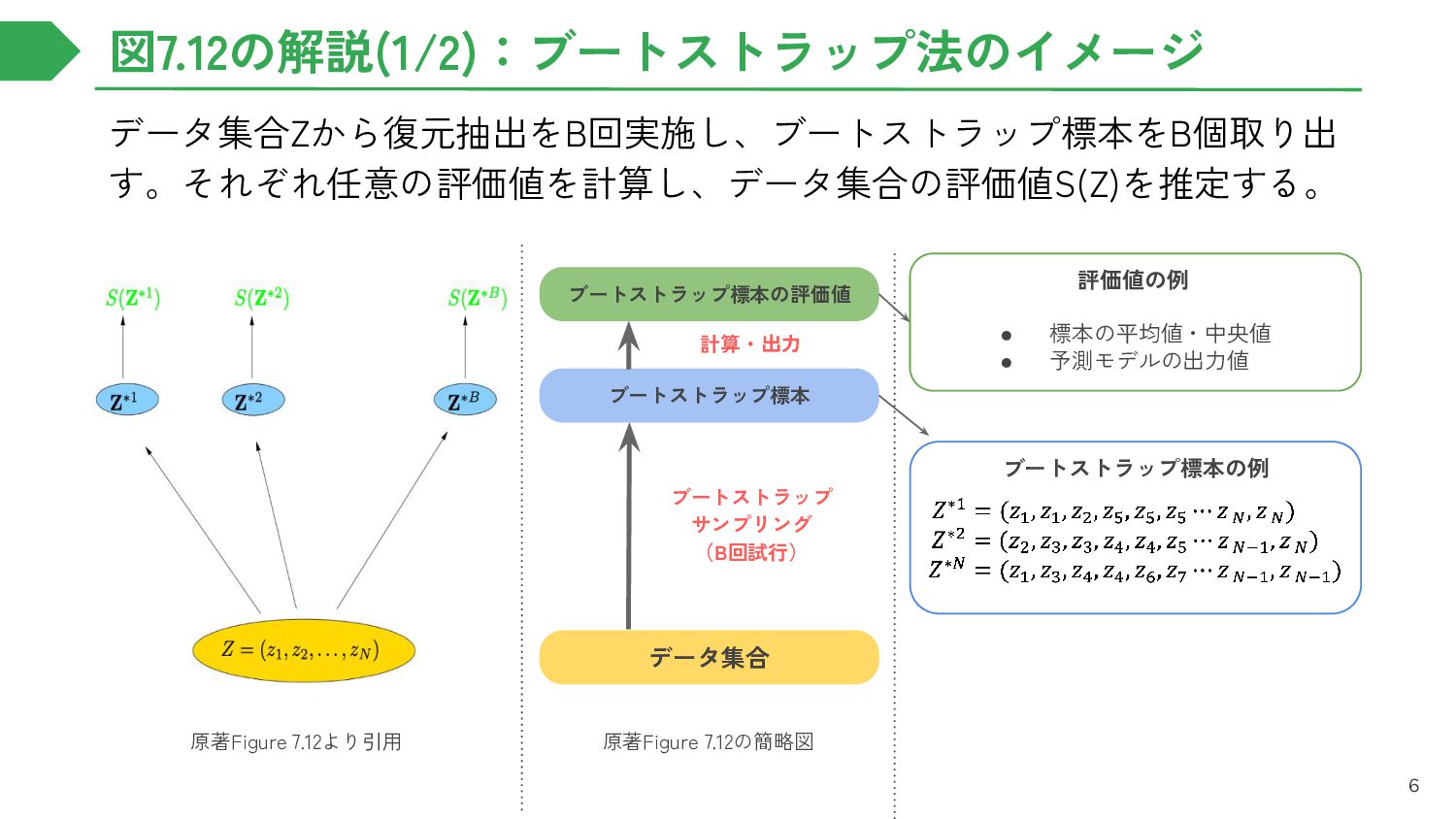
C D D サンプルデータ (n=10) A B A A B C B B D D A C B B C D C D D D B B B B C C C C D D ブートストラップ標本① (n=10) ブートストラップ標本② (n=10) ブートストラップ標本③ (n=10) サンプルデータの袋から10回復元抽出を実施する ・・・ ・・・ サンプルデータを何回も集めるのは非常に面倒なので、1回得られたサンプルデータから何回もデータを 集めれば、それっぽいデータセットが何個も作れる!!(サンプルデータが正規分布でない時に有効) 5
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
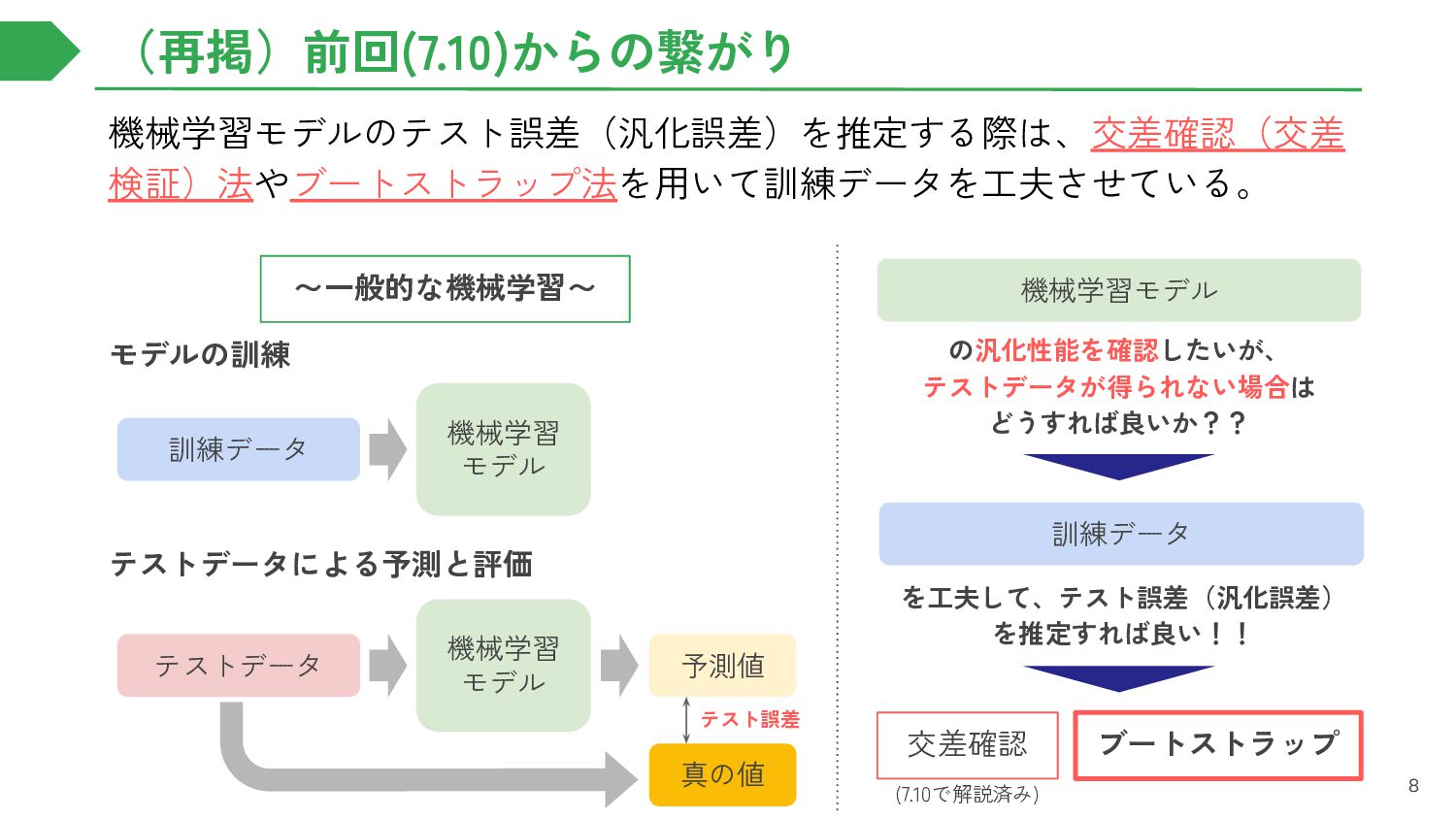{kind=link}
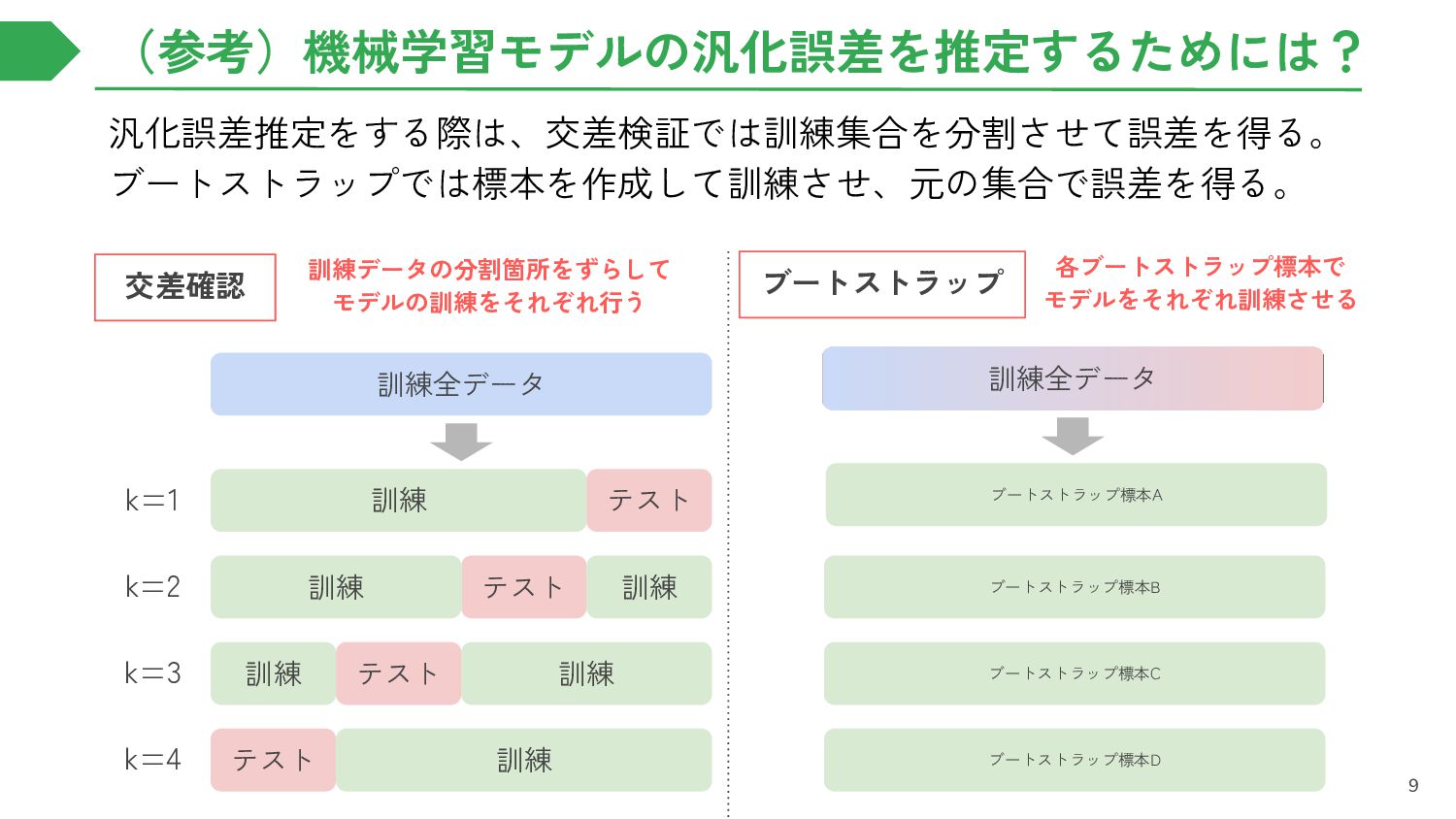{kind=link}
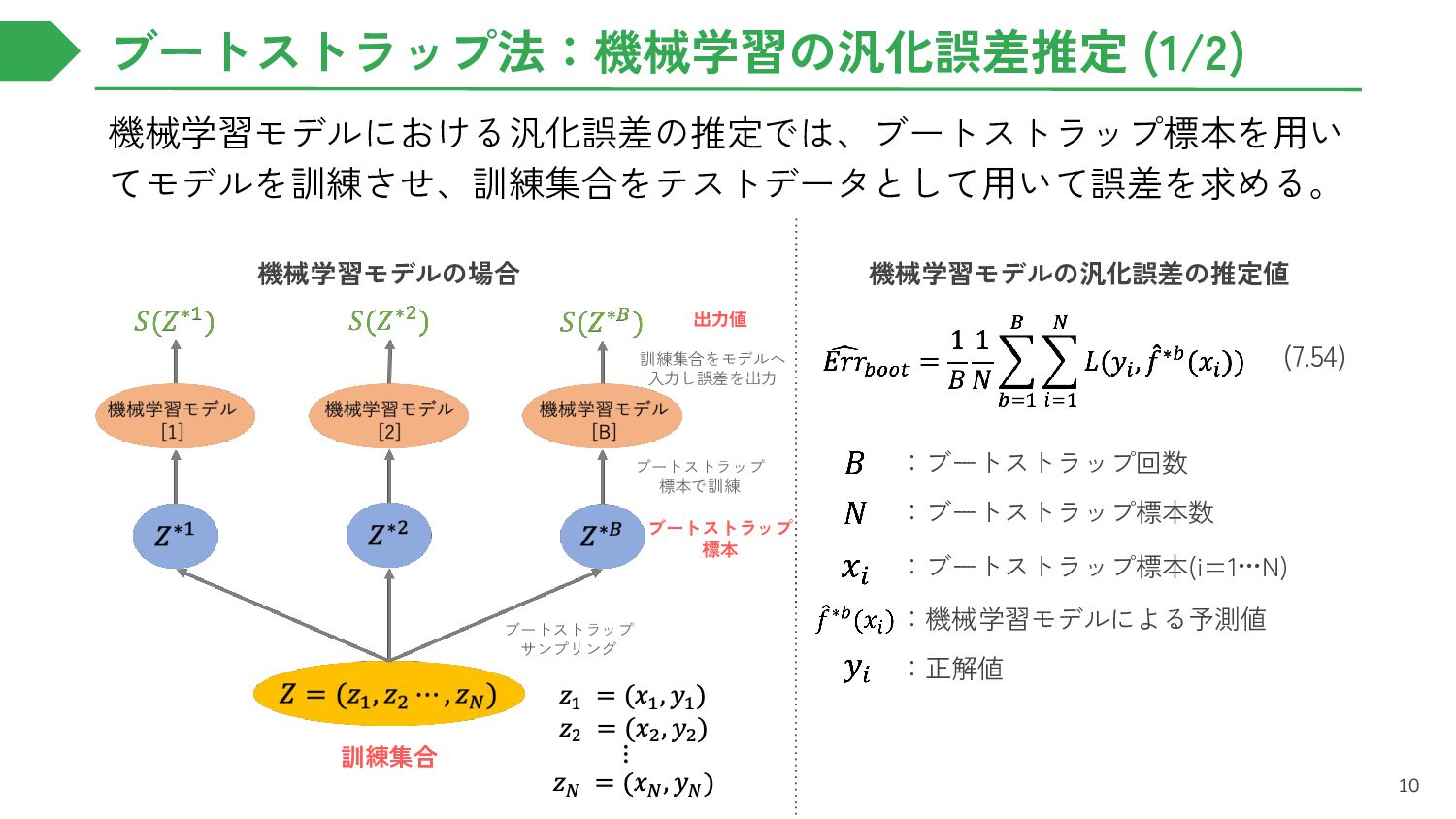{kind=link}
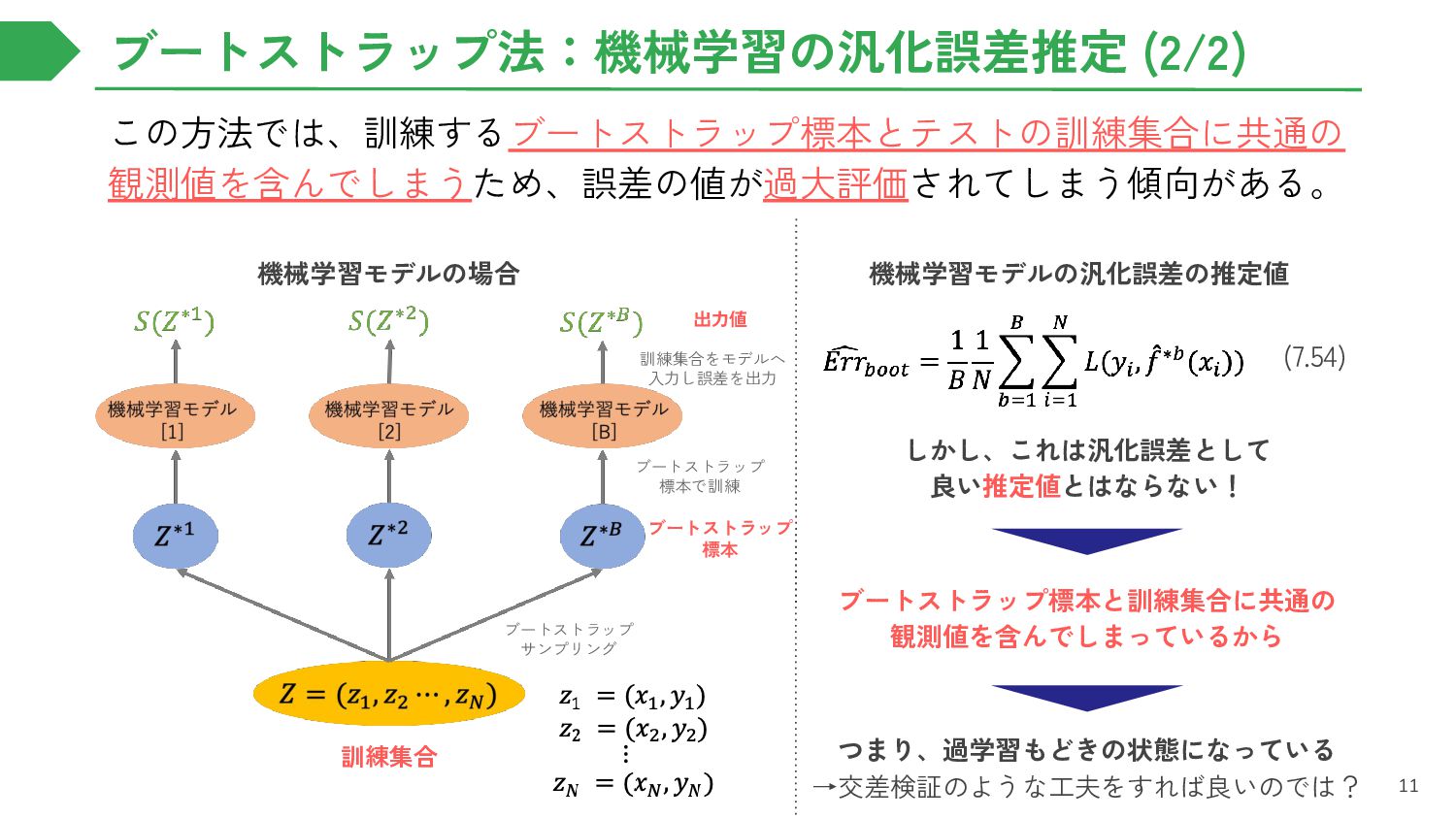{kind=link}
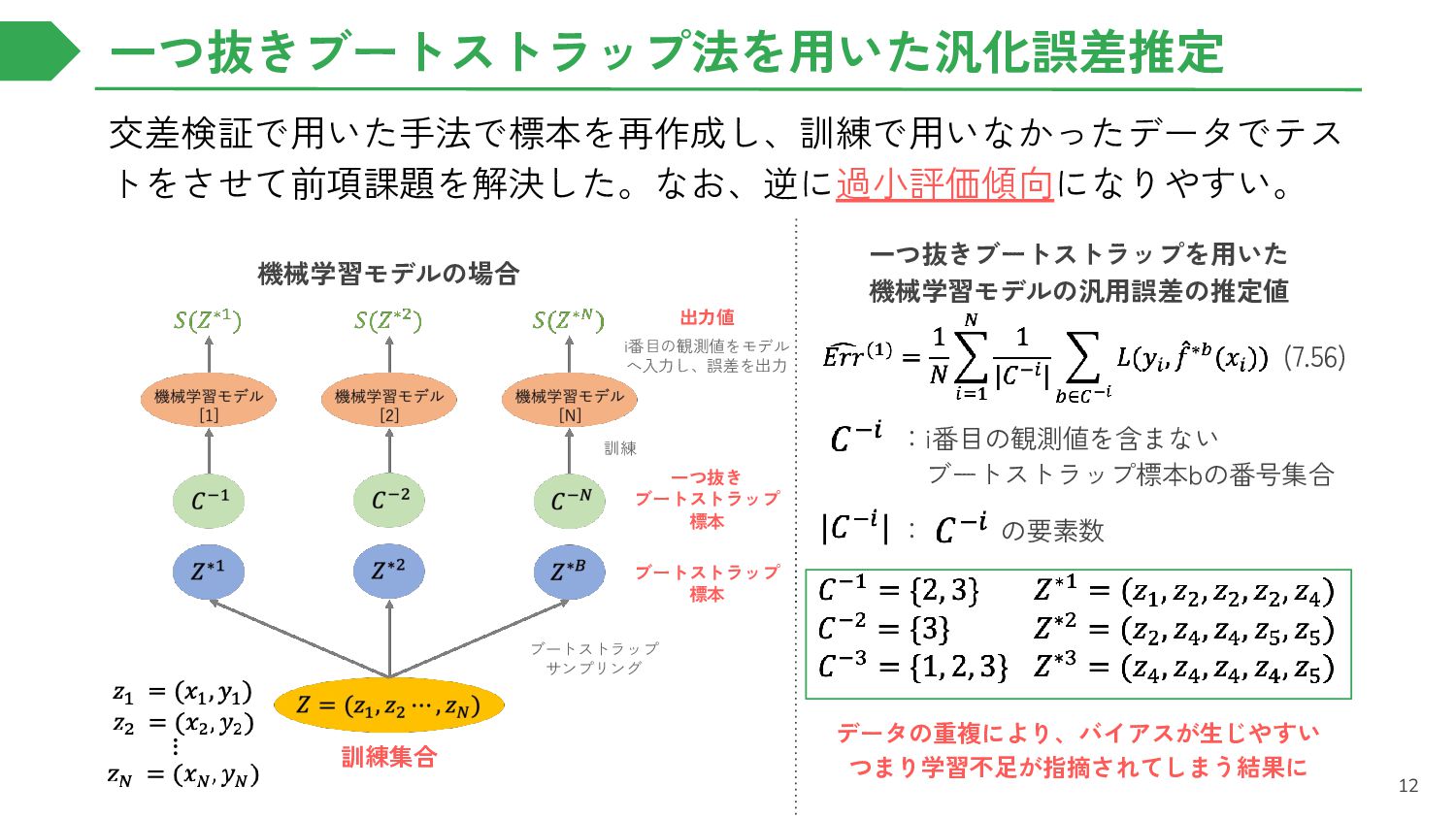{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
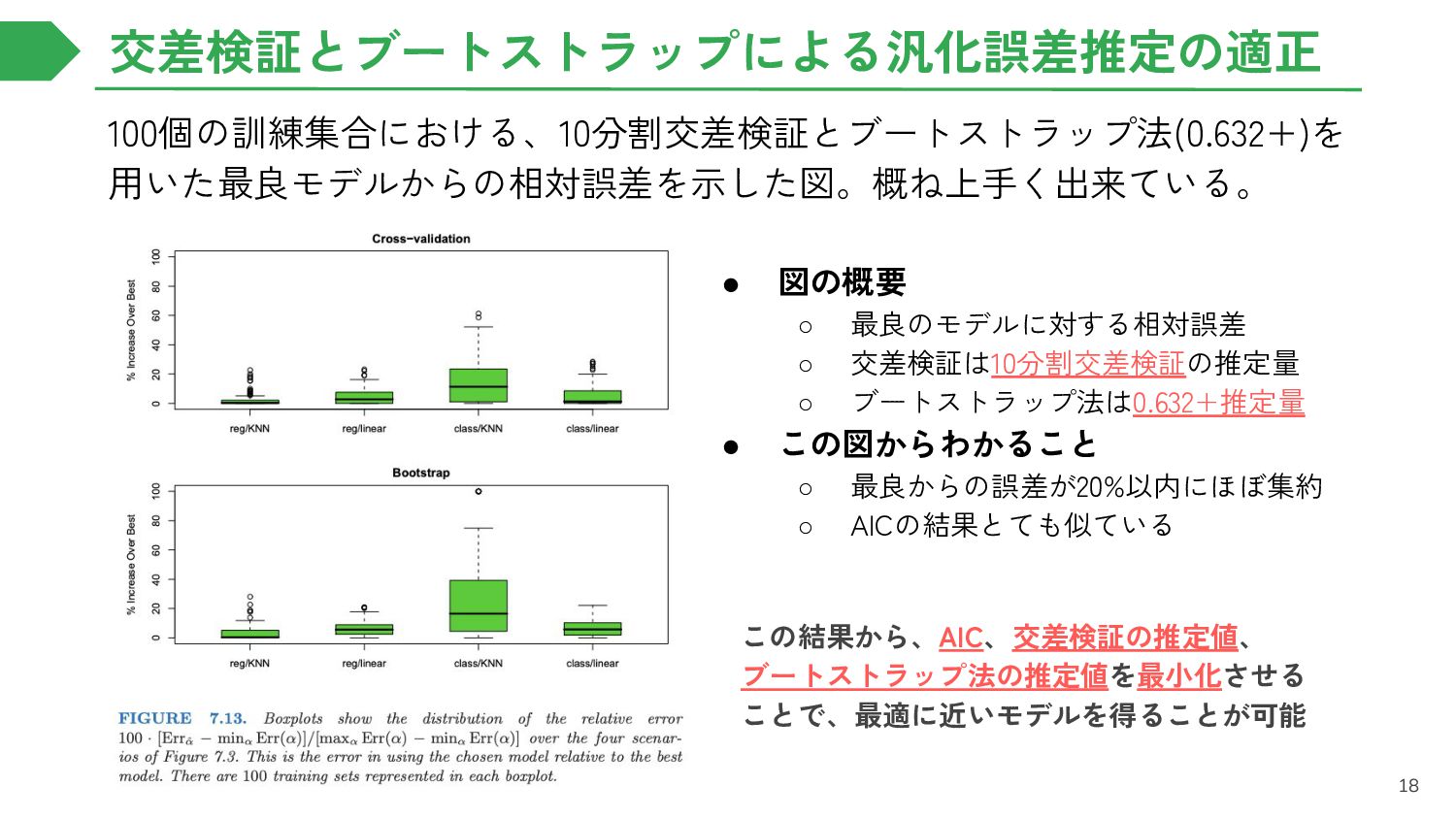{kind=link}
{kind=link}
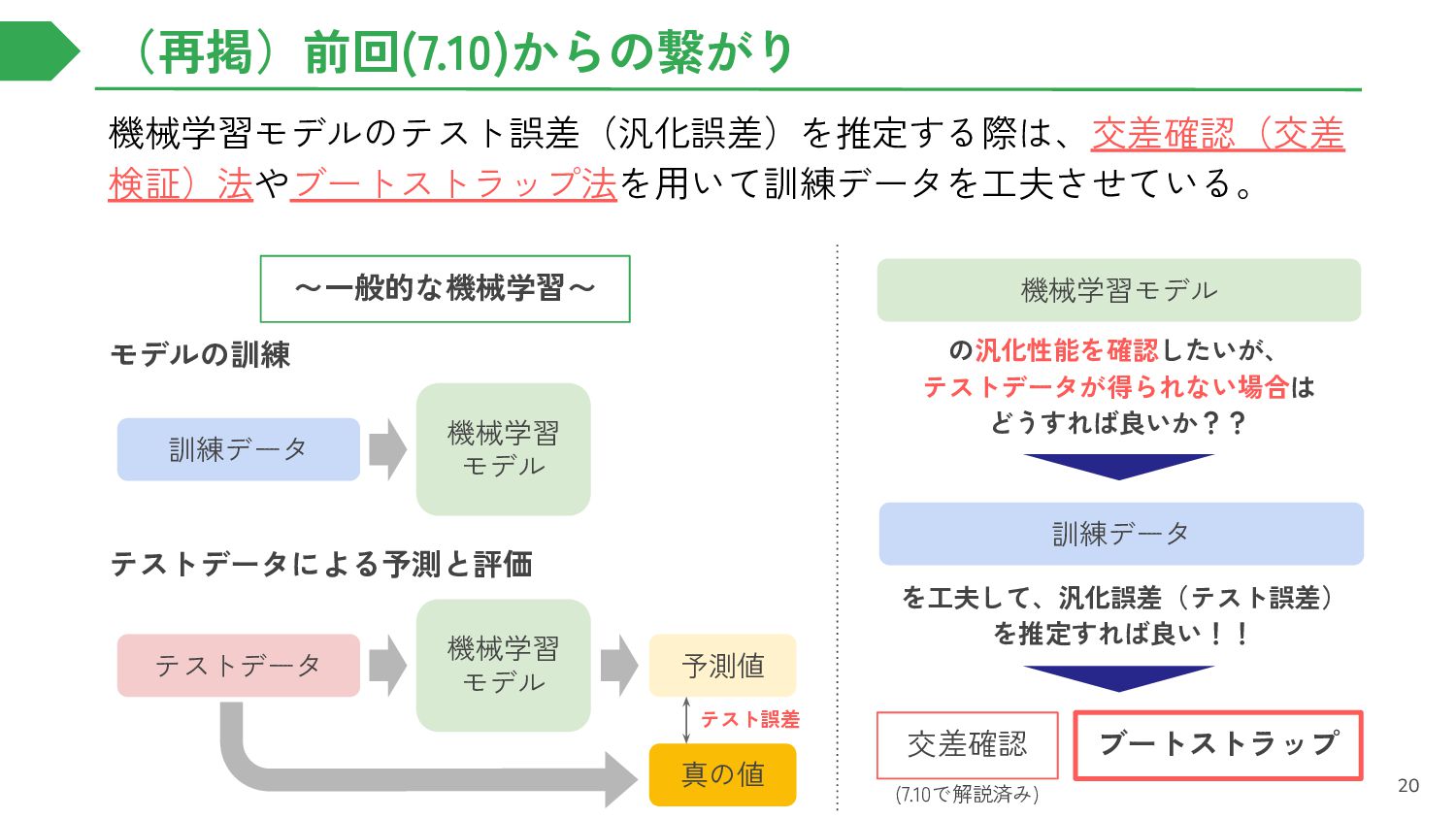{kind=link}
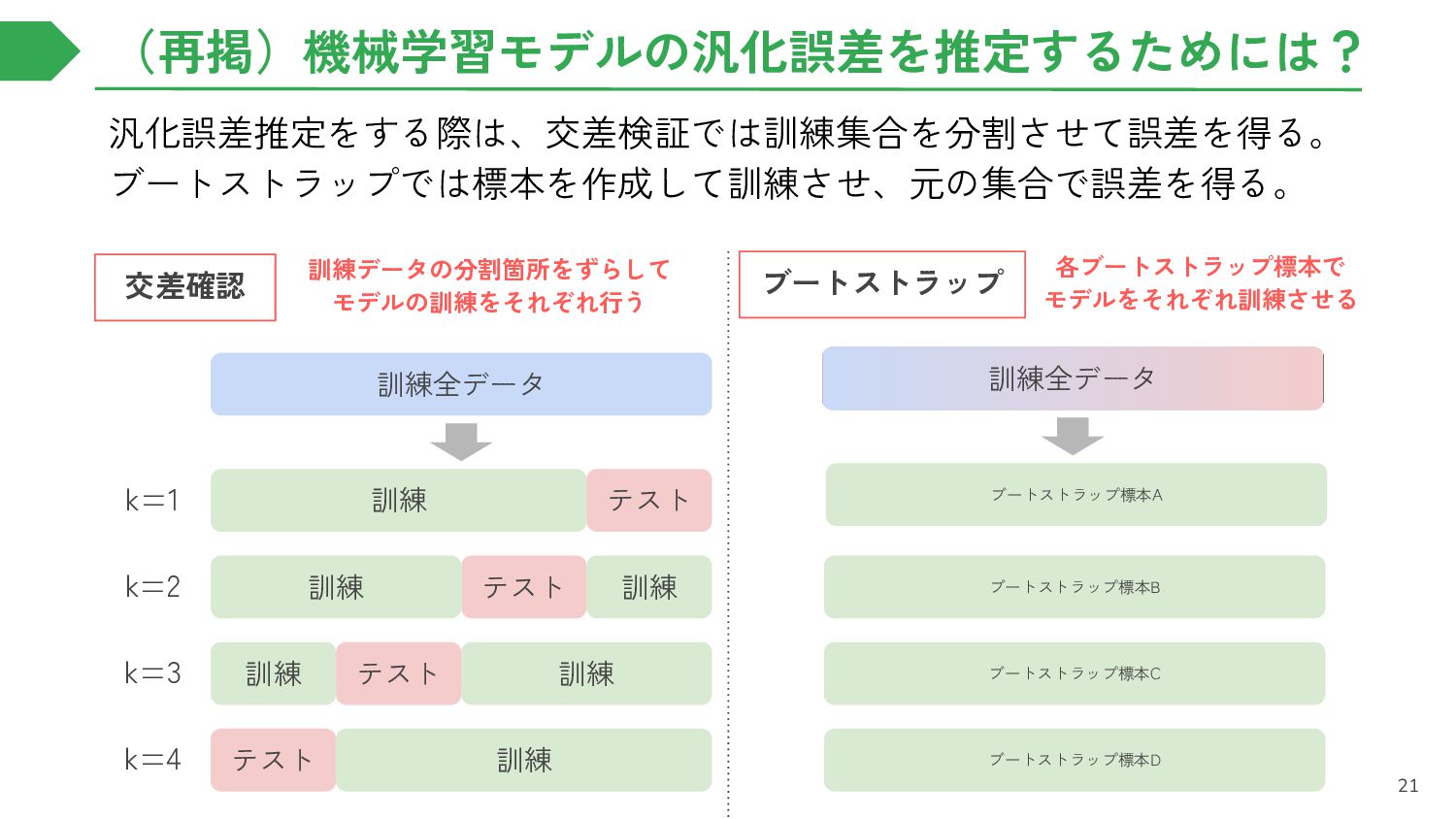{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}