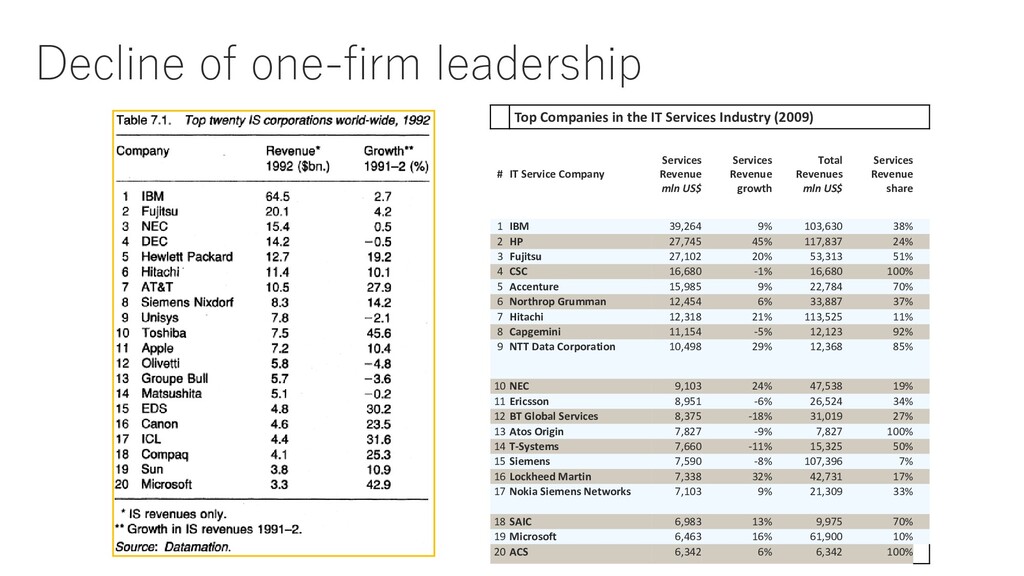
Industry (2009) # IT Service Company Services Revenue mln US$ Services Revenue growth Total Revenues mln US$ Services Revenue share 1 IBM 39,264 9% 103,630 38% 2 HP 27,745 45% 117,837 24% 3 Fujitsu 27,102 20% 53,313 51% 4 CSC 16,680 -1% 16,680 100% 5 Accenture 15,985 9% 22,784 70% 6 Northrop Grumman 12,454 6% 33,887 37% 7 Hitachi 12,318 21% 113,525 11% 8 Capgemini 11,154 -5% 12,123 92% 9 NTT Data Corporation 10,498 29% 12,368 85% 10 NEC 9,103 24% 47,538 19% 11 Ericsson 8,951 -6% 26,524 34% 12 BT Global Services 8,375 -18% 31,019 27% 13 Atos Origin 7,827 -9% 7,827 100% 14 T-Systems 7,660 -11% 15,325 50% 15 Siemens 7,590 -8% 107,396 7% 16 Lockheed Martin 7,338 32% 42,731 17% 17 Nokia Siemens Networks 7,103 9% 21,309 33% 18 SAIC 6,983 13% 9,975 70% 19 Microsoft 6,463 16% 61,900 10% 20 ACS 6,342 6% 6,342 100%
{kind=link}
![今日の内容 • 16:10-16:20 • プレ講義 [録画なし] • 16:20-16:40 • 2.1](https://files.speakerdeck.com/presentations/1853ce2ab1a64d958a1232dd41f68d3a/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Google Colaboratory • [ファイル]-[python3 の新しいノートブック] を選択する](https://files.speakerdeck.com/presentations/1853ce2ab1a64d958a1232dd41f68d3a/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![サンプルファイルの自環境への導入の仕方 Google Colaboratory 編 • [ファイル]-[ドライブにコピーを保存]をクリックする](https://files.speakerdeck.com/presentations/1853ce2ab1a64d958a1232dd41f68d3a/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Google Colaboratory 上で Notebook をコ ピーする [ドライブにコピーを保存] を選択する](https://files.speakerdeck.com/presentations/1853ce2ab1a64d958a1232dd41f68d3a/slide_60.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
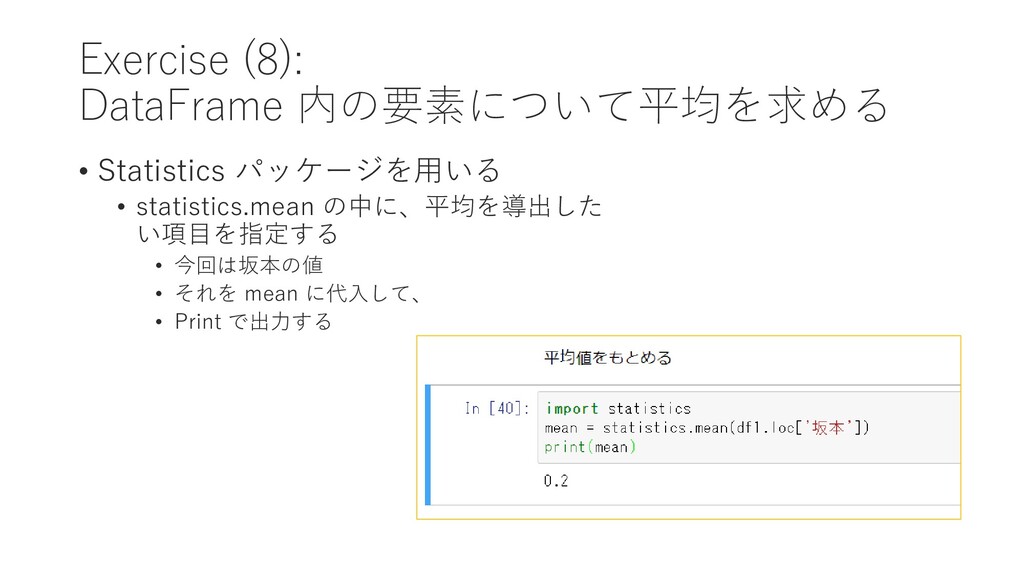{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
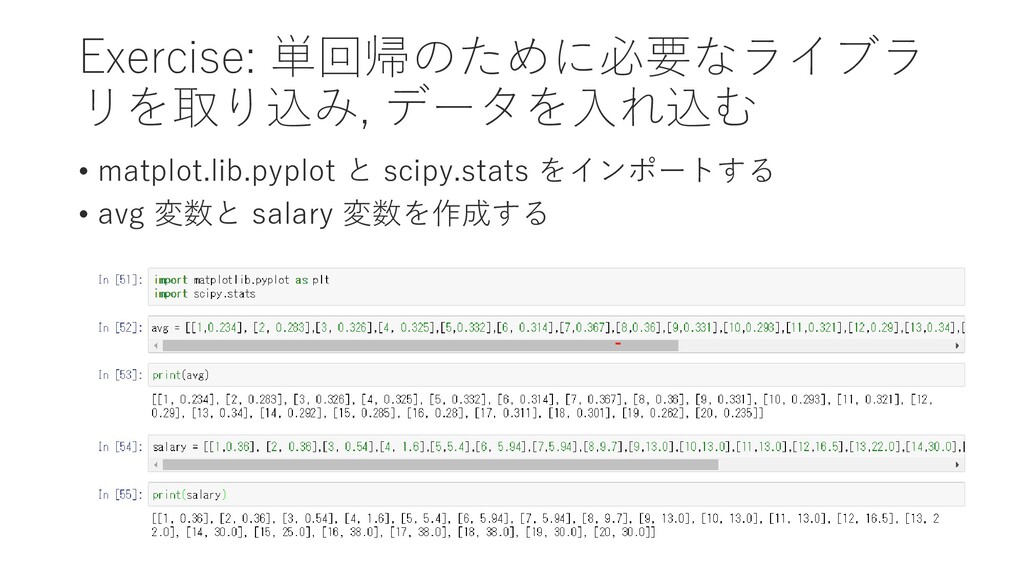{kind=link}
{kind=link}
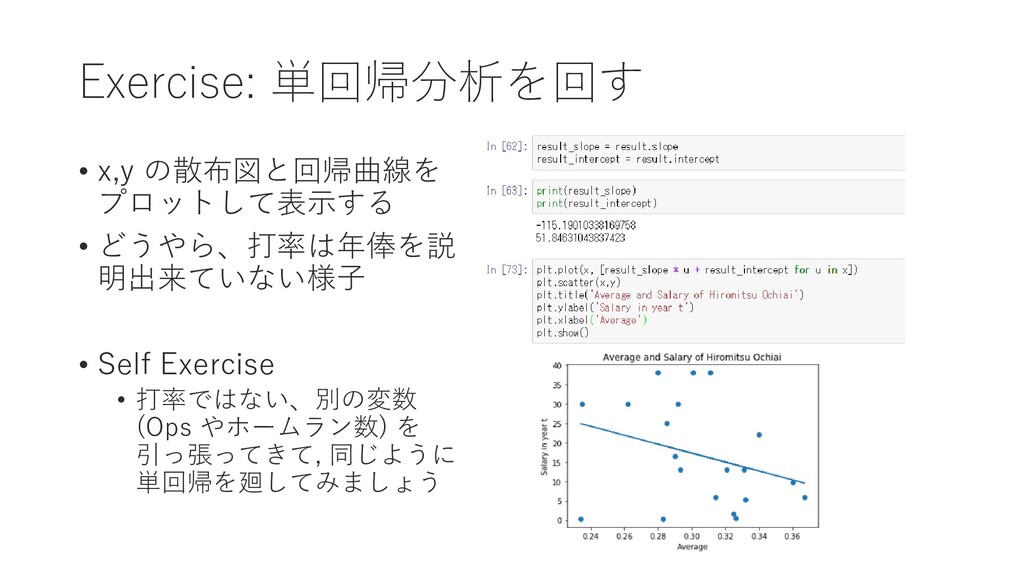{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
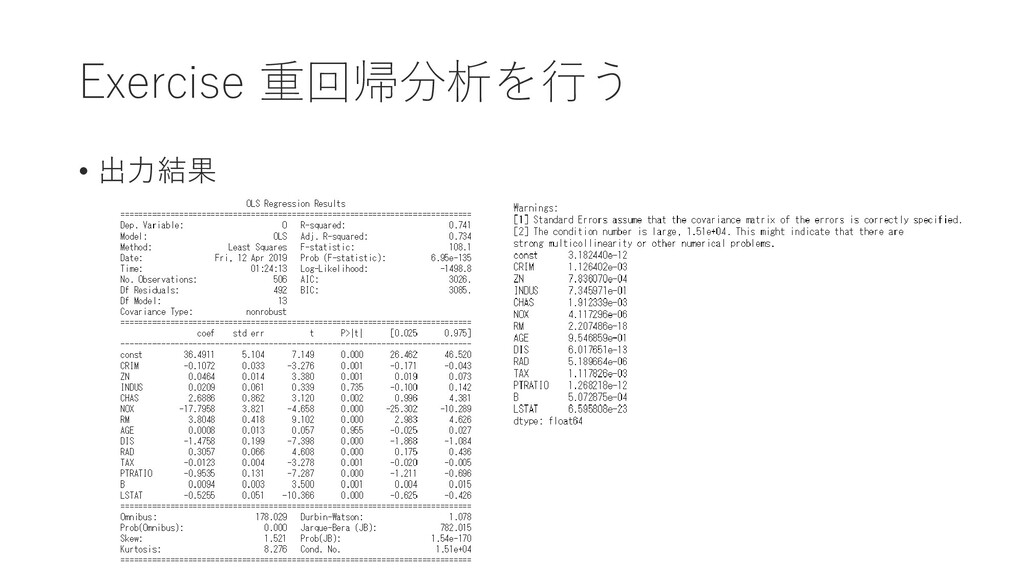{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/1853ce2ab1a64d958a1232dd41f68d3a/slide_100.jpg){kind=link}