RISIS CORE FACILITY (RCF), is organised around 3 major dimensions and activities: • 1. A front end, focusing on users, the ways they access RISIS, work within RISIS and build RISIS user communities. At the core is the RISIS Core facility (WP4). The core facility supports virtual transnational access (WP8) and is accompanied by all the efforts we do to raise awareness, train researchers and interact with them (WP2) and to help them build active user communities (mobilising D4Science VRE, WP7). • 2. A service layer that helps users organise problem based integration of RISIS datasets (with possibilities to complement with their own datasets) – this entails the data integration and analysis services (WP5) and methodological support for advanced quantitative methods (WP6). • 3. A data layer that gathers the core RISIS datasets that we maintain (WP5) and enlarge (WP9), the datasets of interest for which we insure reliability and harmonisation for integration (WP4), and the new datasets that we develop and will progressively open (WP10). https://www.risis2.eu/project-description/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Jupyter Notebook のインストール(1) • 2. [Download] をクリックする](https://files.speakerdeck.com/presentations/b36d335dae8d4632982d8bcd1e4d2577/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![3-2. 新しいnotebook を作成する • [ファイル]-[python3 の新しいノートブック] を選択する](https://files.speakerdeck.com/presentations/b36d335dae8d4632982d8bcd1e4d2577/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
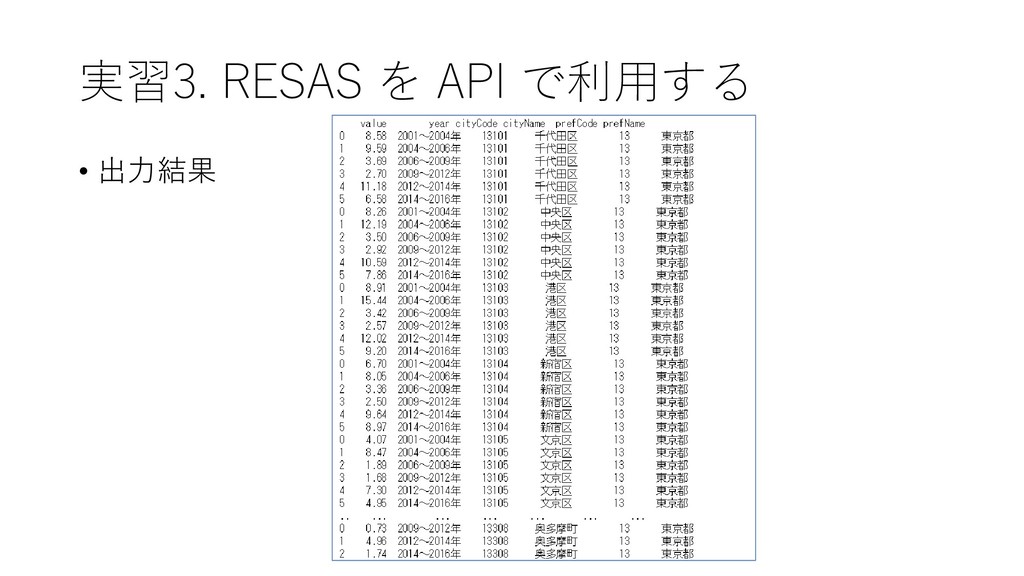
![実習3. RESAS をAPI で利用する • 都道府県ごとの累計企業数を 集計する • 出力結果 s.groupby('prefName')['value'].sum()](https://files.speakerdeck.com/presentations/b36d335dae8d4632982d8bcd1e4d2577/slide_77.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
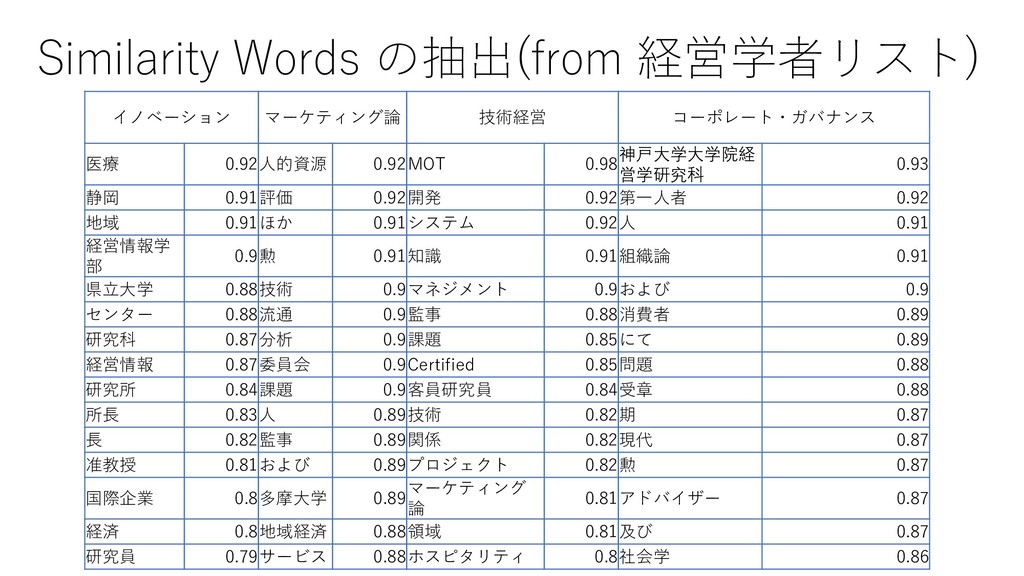{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
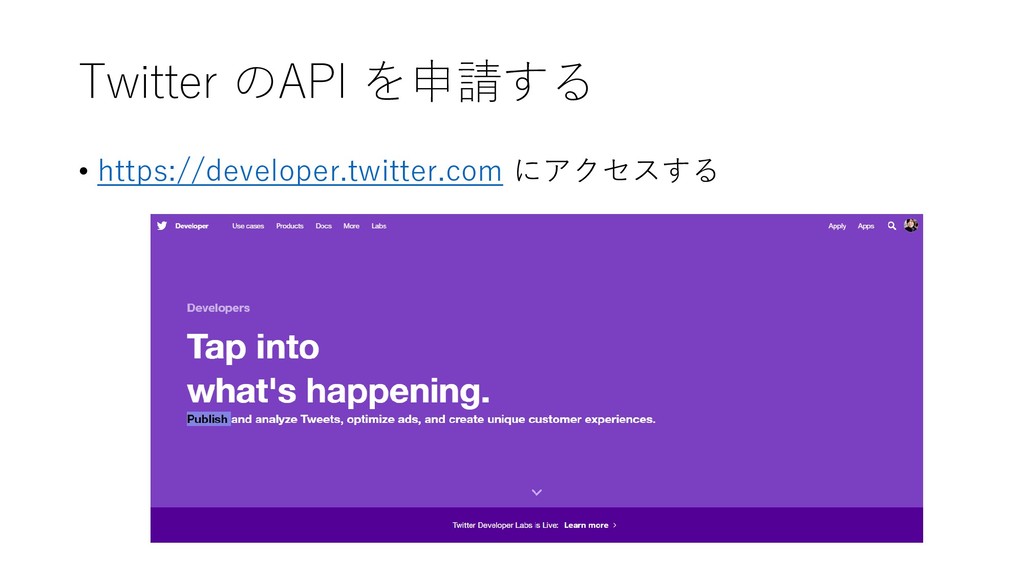{kind=link}
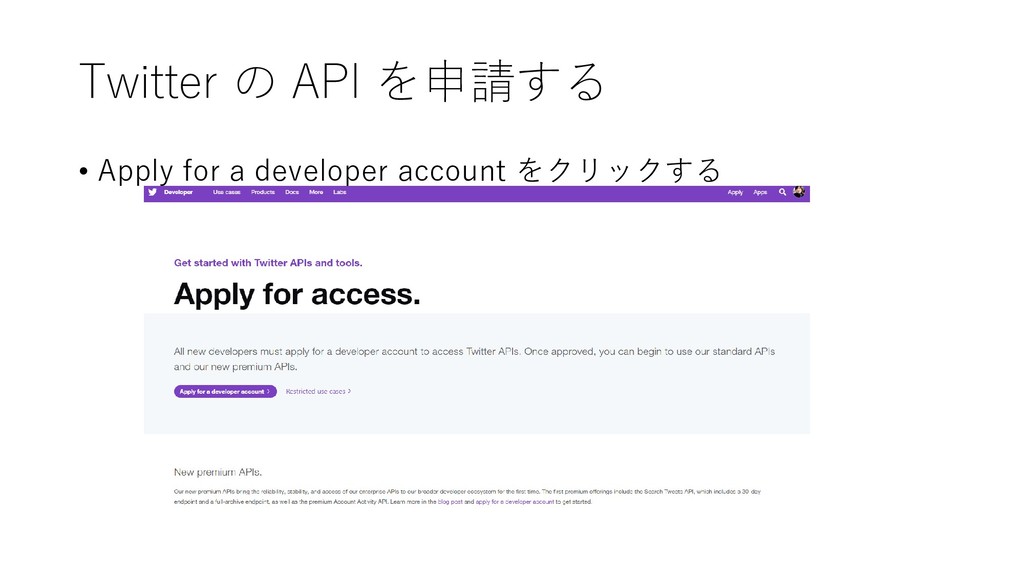{kind=link}
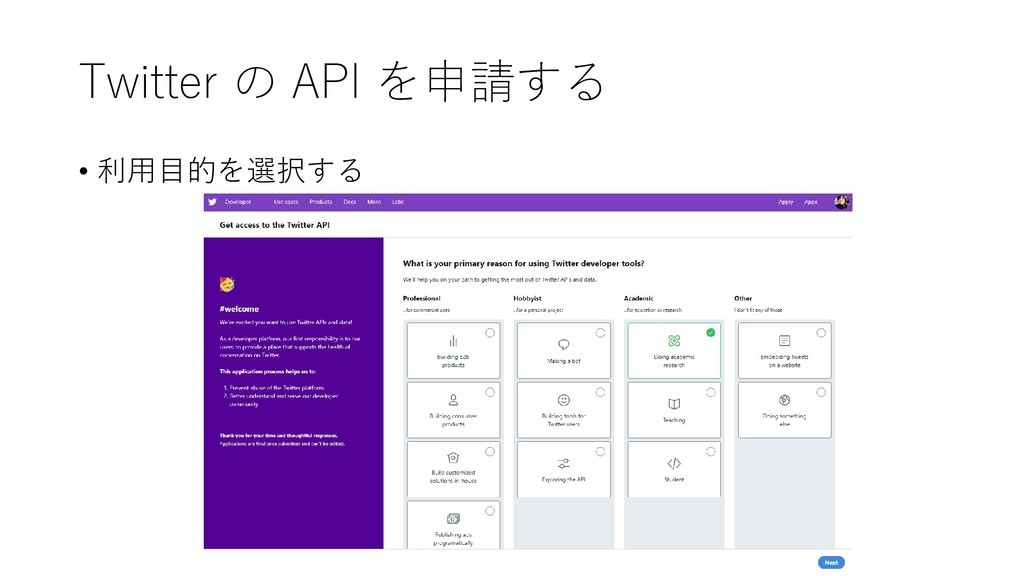{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
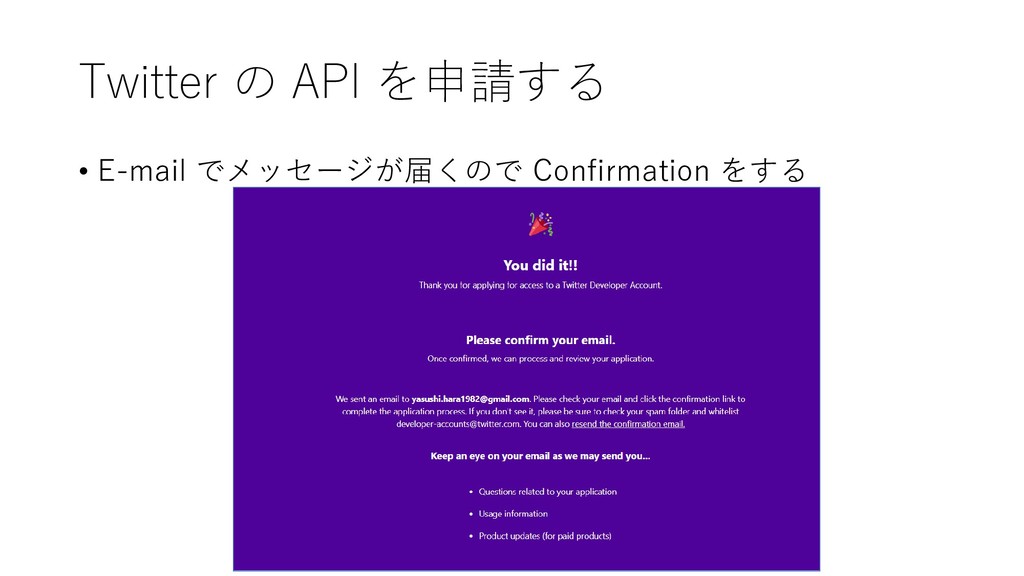{kind=link}
{kind=link}
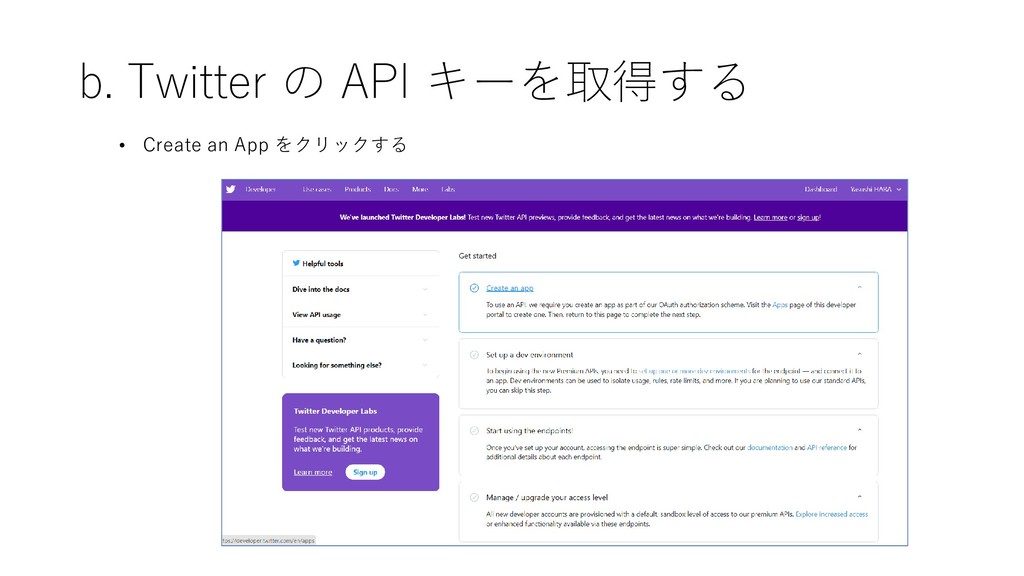{kind=link}
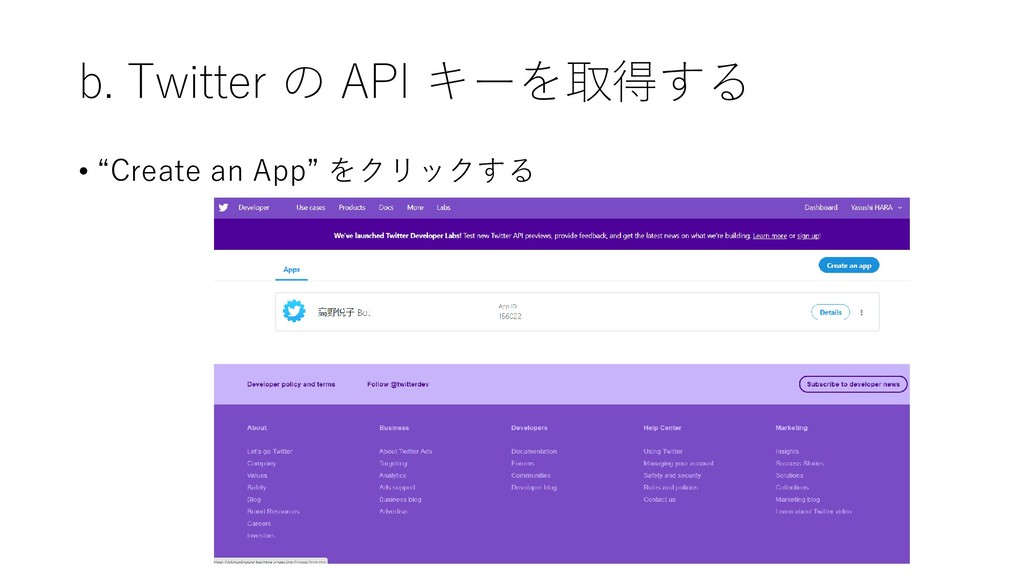{kind=link}
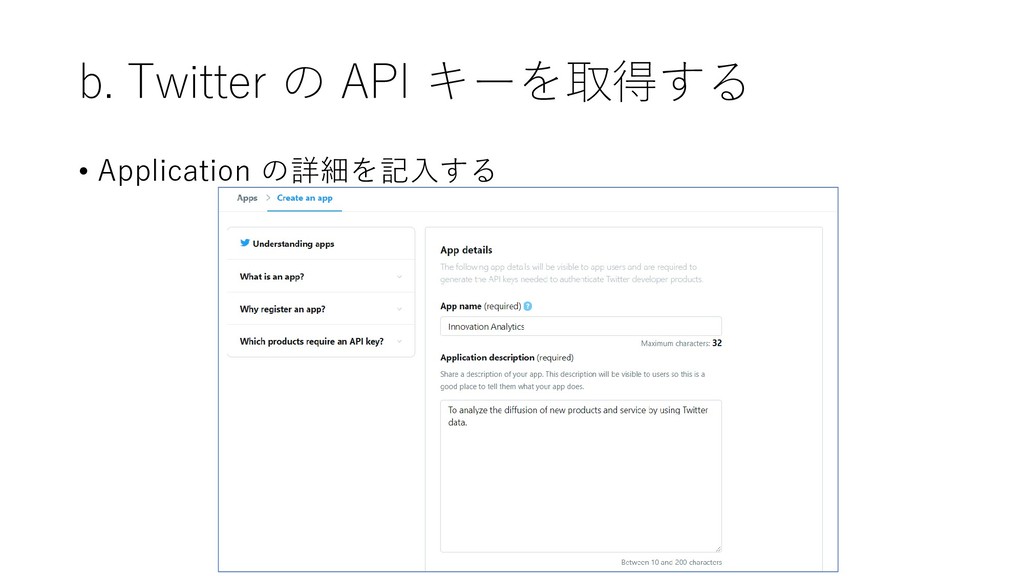{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS [email protected] Twitter: @harayasushi](https://files.speakerdeck.com/presentations/b36d335dae8d4632982d8bcd1e4d2577/slide_177.jpg){kind=link}