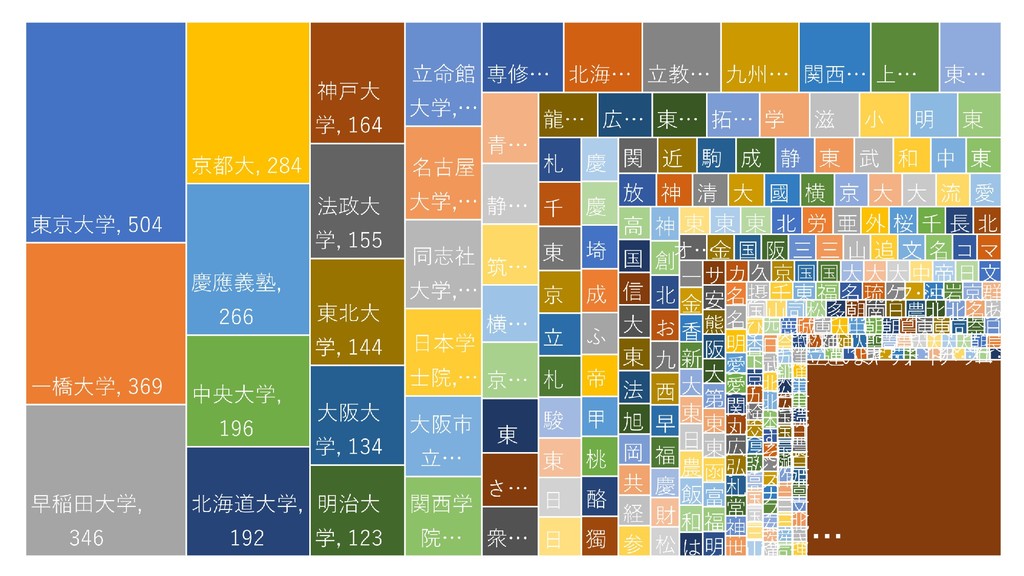
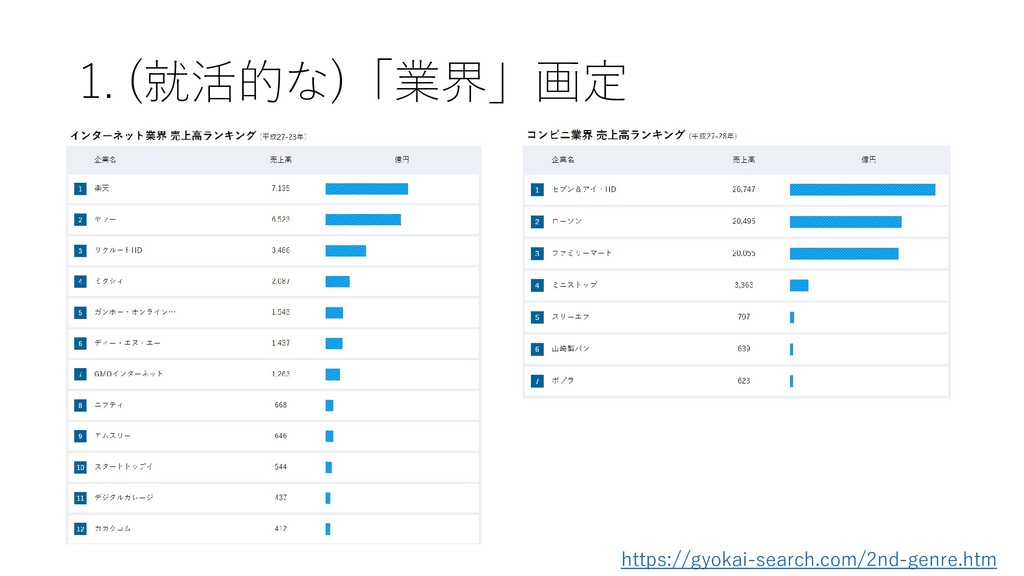
• D. 建設業 • E. 製造業 • F. 電気・ガス・熱供給・水道業 • G. 情報通信業 • H. 運輸業,郵便業 • I. 卸売業,小売業 • J. 金融業,保険業 • K. 不動産業,物品賃貸業 • L. 学術研究,専門・技術サービス業 • M. 宿泊業,飲食サービス業 • N. 生活関連サービス業,娯楽業 • O. 教育,学習支援業 • P. 医療,福祉 • Q. 複合サービス事業 • R. サービス業(他に分類されないもの) • S. 公務(他に分類されるものを除く) • T. 分類不能の産業 http://www.soumu.go.jp/toukei_toukatsu/index/seido/ sangyo/02toukatsu01_03000022.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![3. KHCoder に定点調査の自由記述データ を読み込む • KHCoder を開く • [プロジェクト] –[新規]](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_21.jpg){kind=link}
![3. KHCoder にデータを読み込む • [参照]をクリックして, 分析対 象ファイルを選ぶ • 分析対象とする列について[詳 細]](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_22.jpg){kind=link}
![4. データ分析前の処理をする • [前処理] – [テキストのチェッ ク]をクリックする • OKをクリックする 2019/7/3](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_23.jpg){kind=link}
![4. データ分析前の処理をする • 修正が必要である旨メッセージが表示される • [画面に表示] をクリックして, 問題点をチェックする • “テキストの自動修正”](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_24.jpg){kind=link}
![4. データ分析前の処理をする • 問題点が修正される. • [閉じる]をクリックする. 2019/7/3 26](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_25.jpg){kind=link}
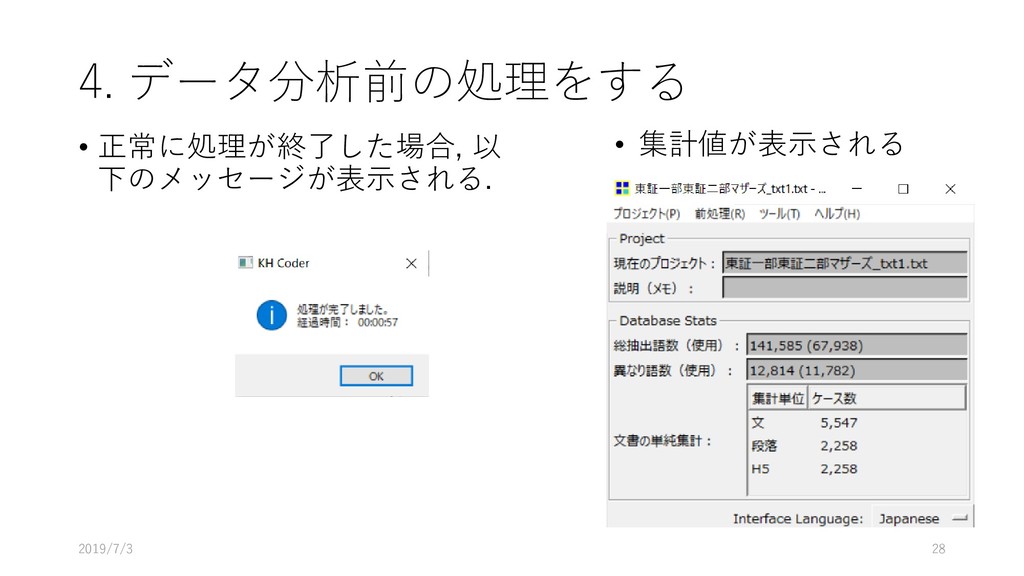
![4. データ分析前の処理をする • [前処理] – [前処理の実行] を選択する • OKをクリックする 2019/7/3](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_26.jpg){kind=link}
{kind=link}
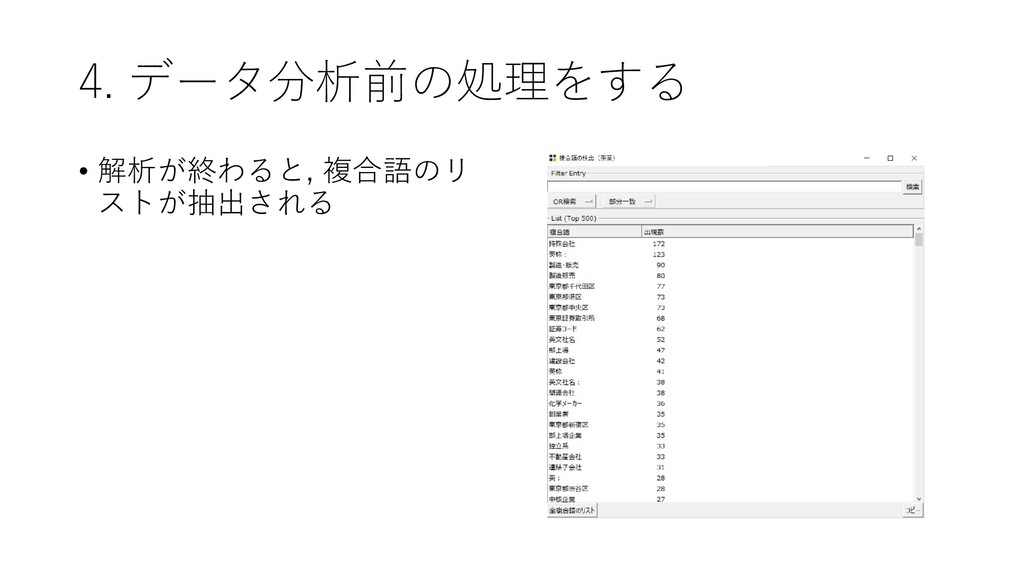
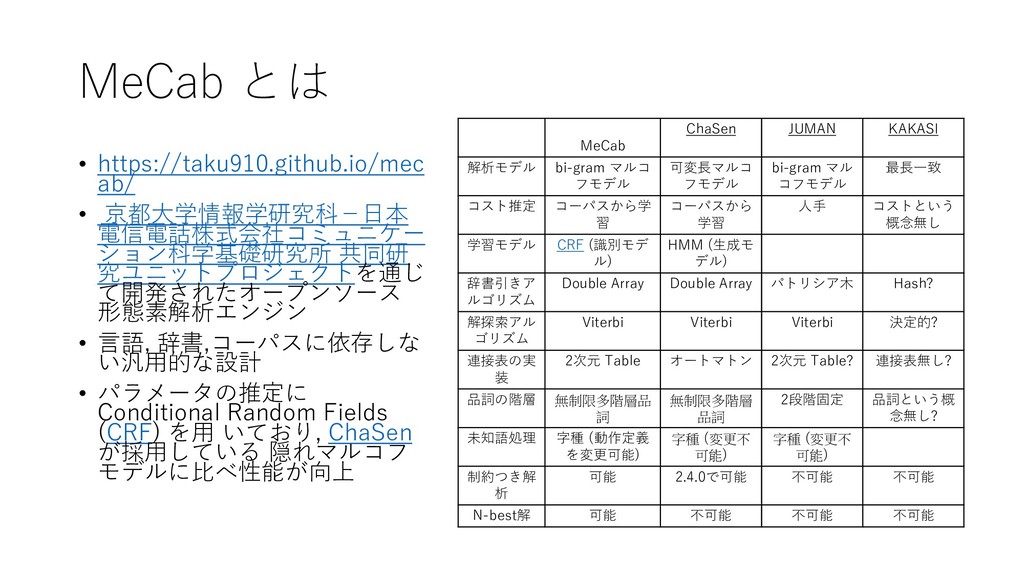
![4. データ分析前の処理をする • 複合語の検出を行う • [前処理]-[複合語の検出]-[茶筌 を利用]をクリックする](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_28.jpg){kind=link}
{kind=link}
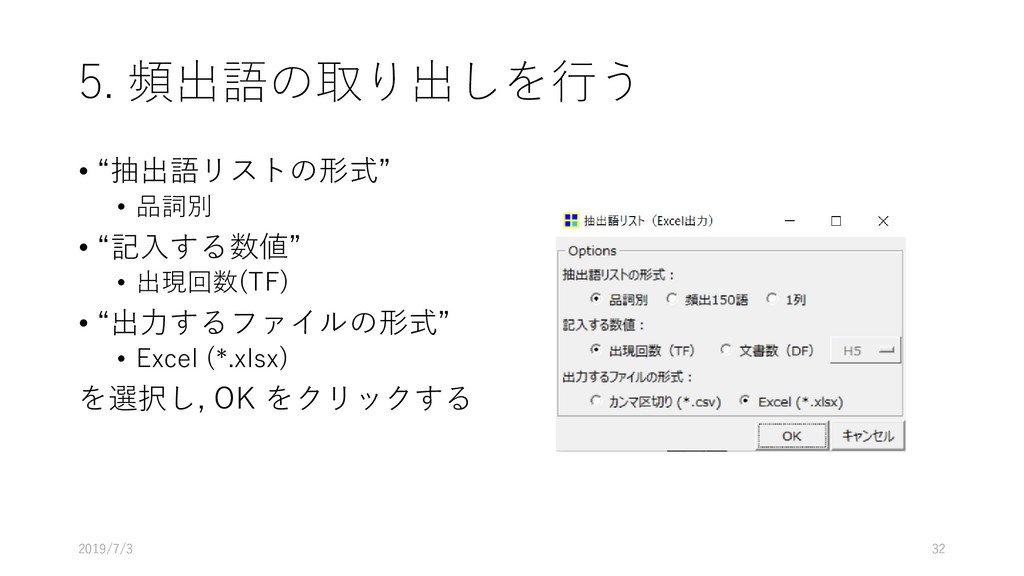
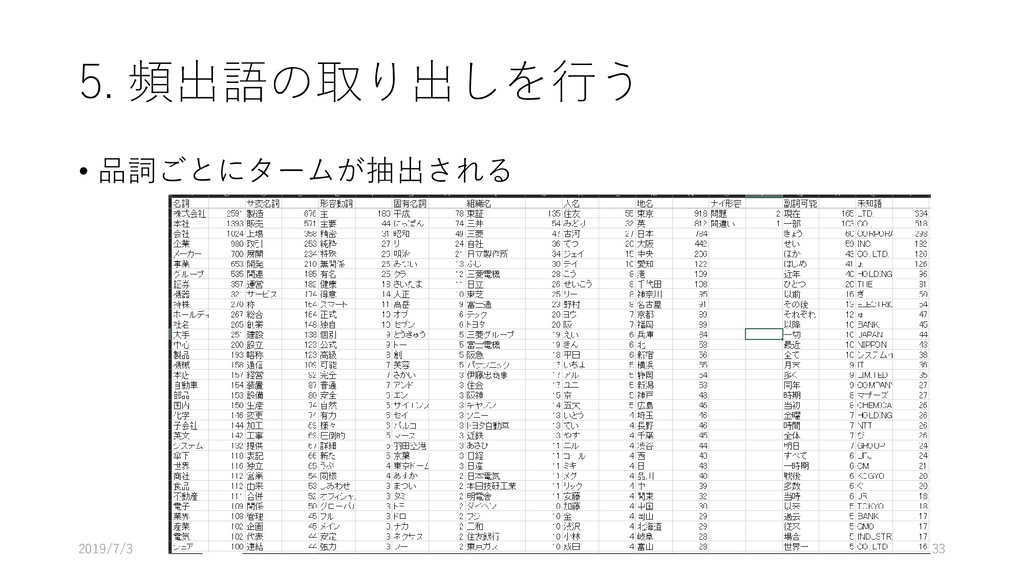
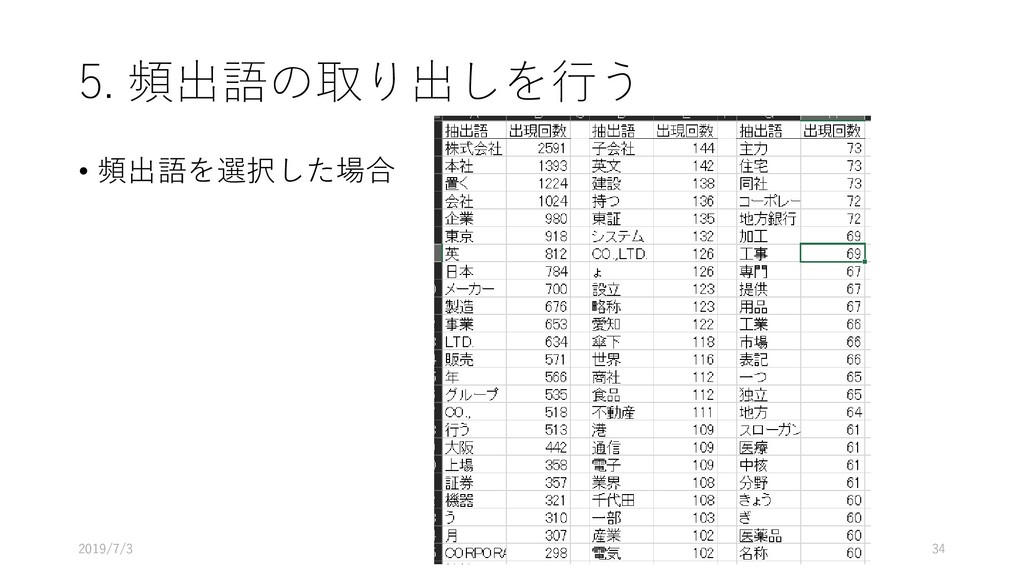
![5. 頻出語の取り出しを行う • [ツール]-[抽出語]-[抽出語 リスト(Excel)]を選択する 2019/7/3 31](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
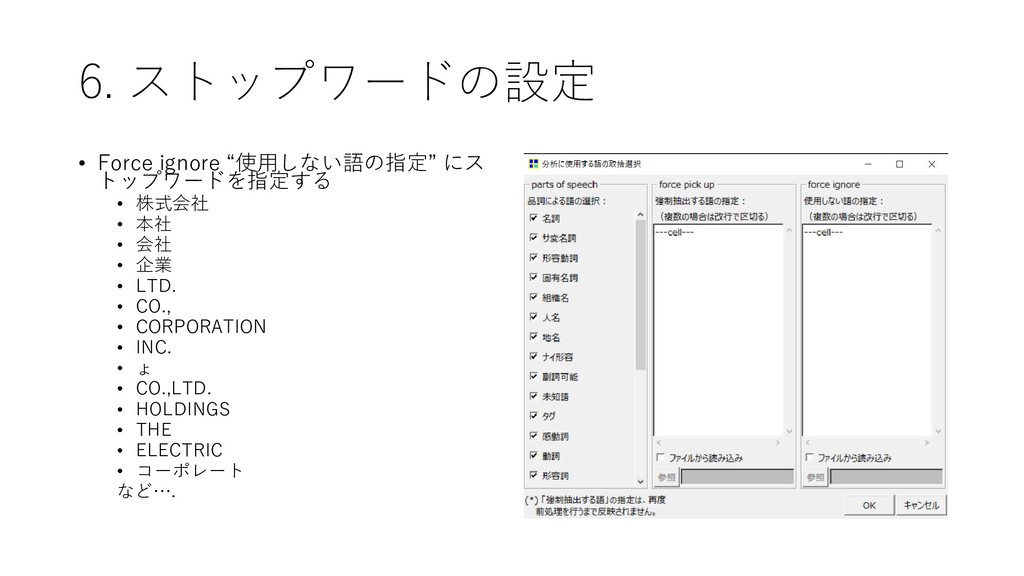{kind=link}
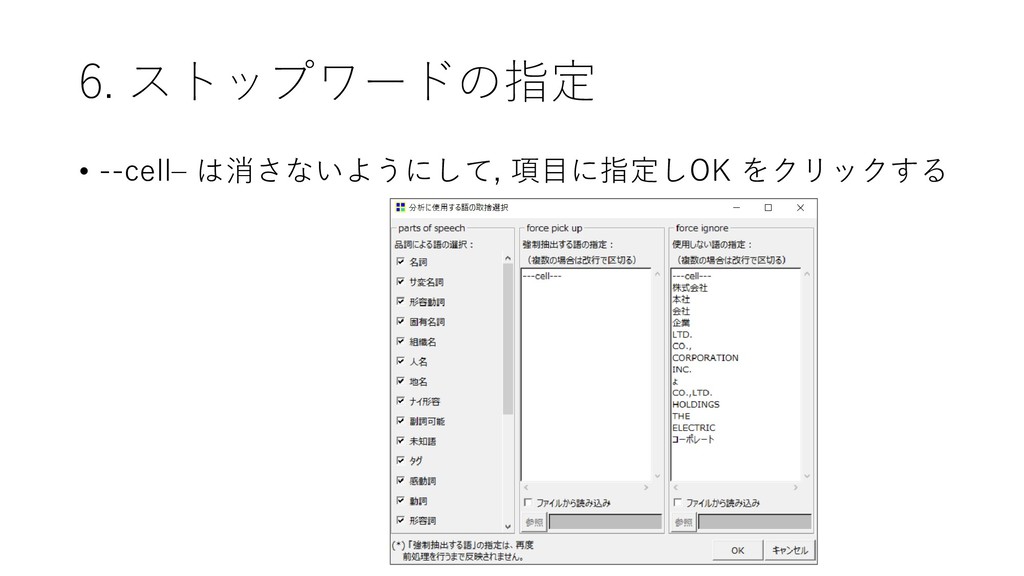{kind=link}
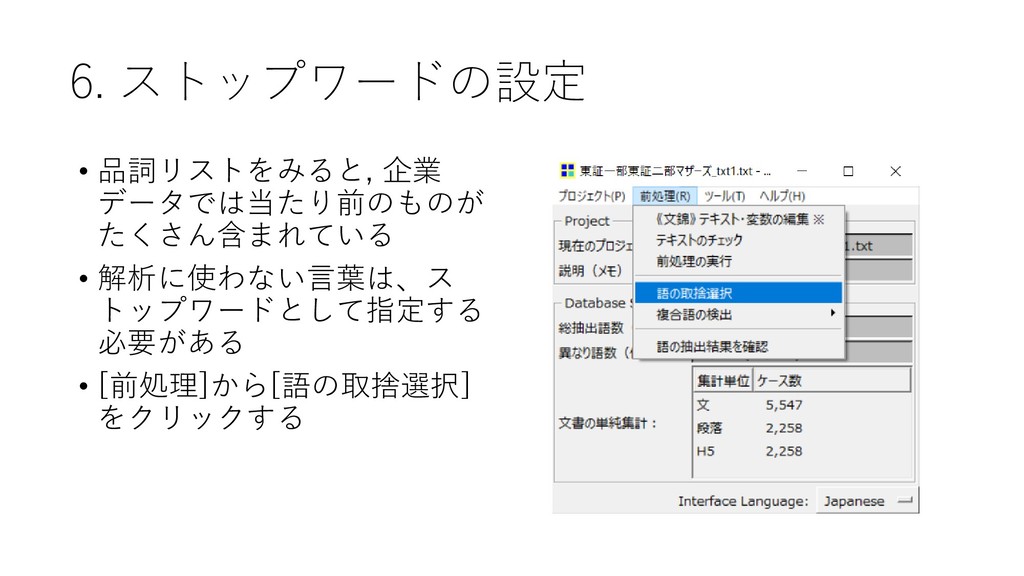
![6. 共起ネットワークを書く • [ツール]-[抽出語]-[共起 ネットワーク]を選択する 2019/7/3 38](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_37.jpg){kind=link}
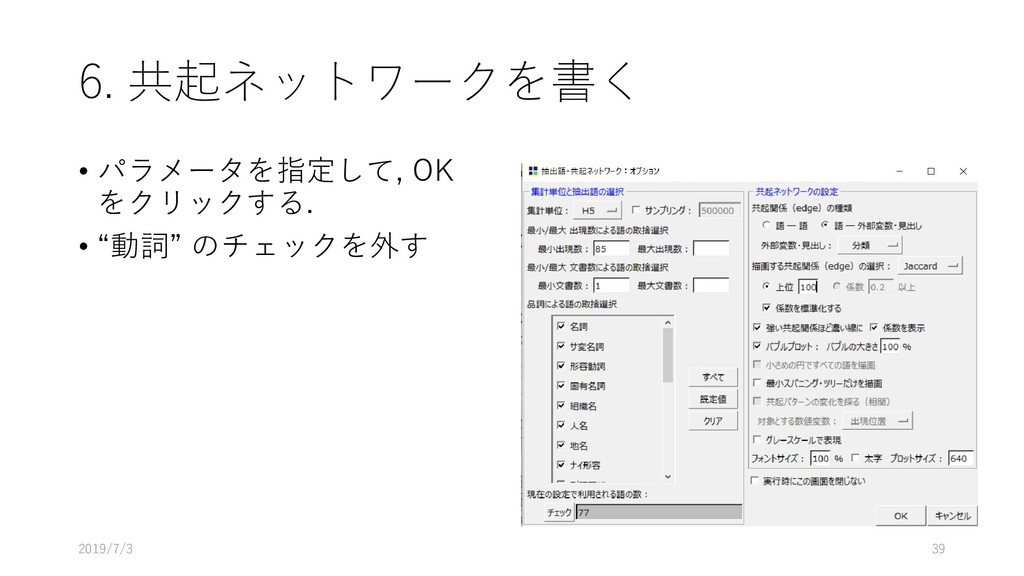{kind=link}
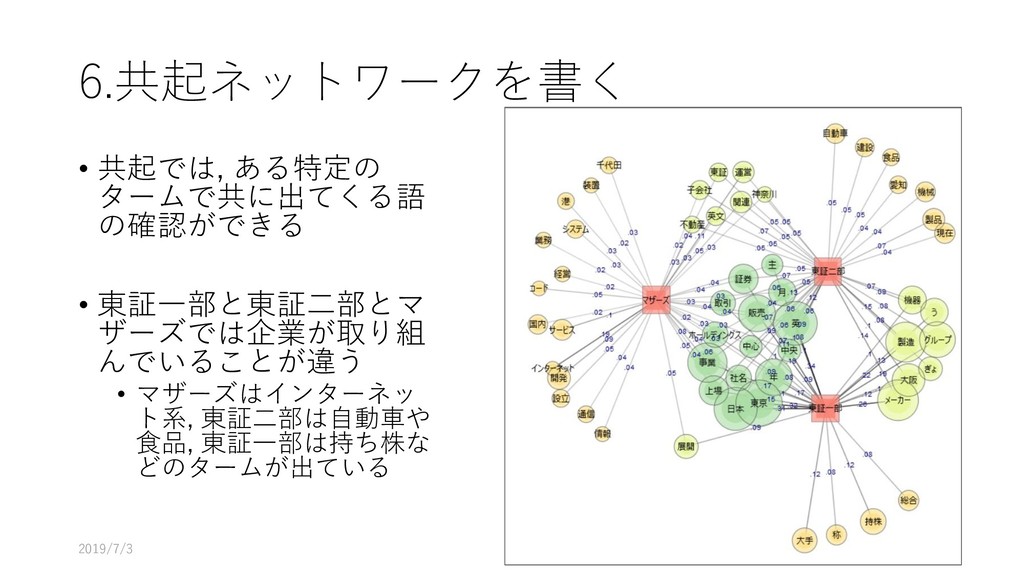{kind=link}
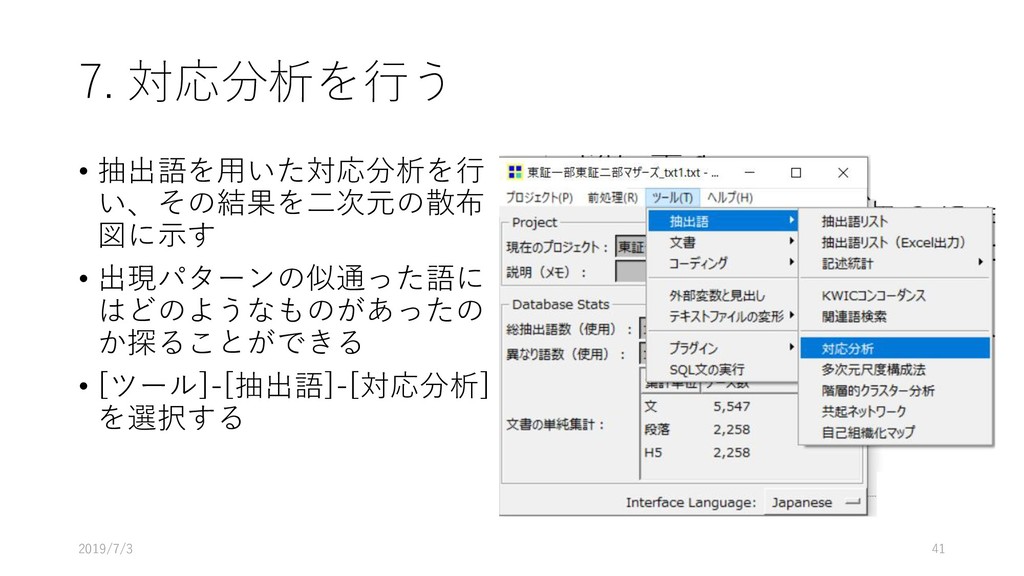{kind=link}
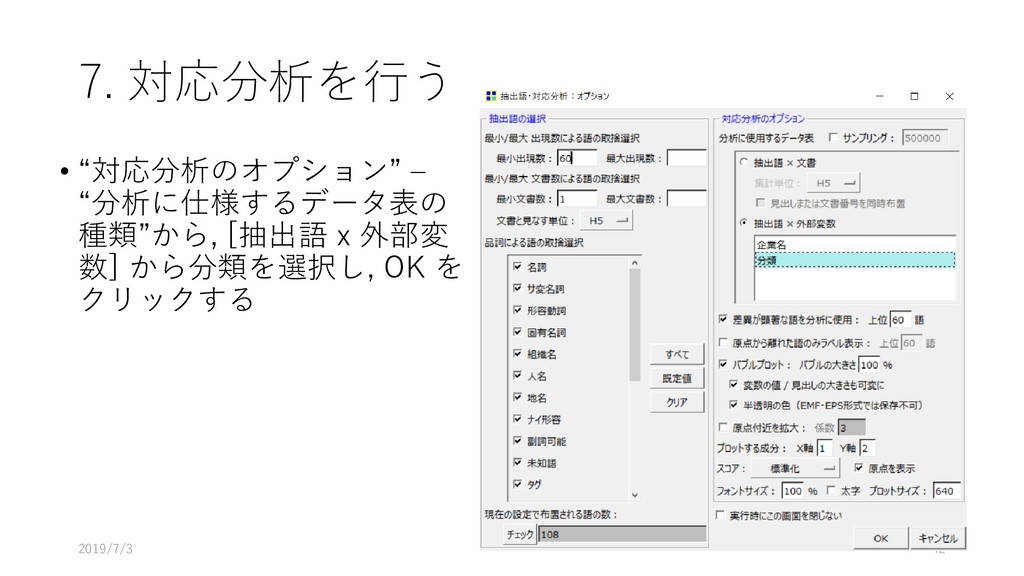{kind=link}
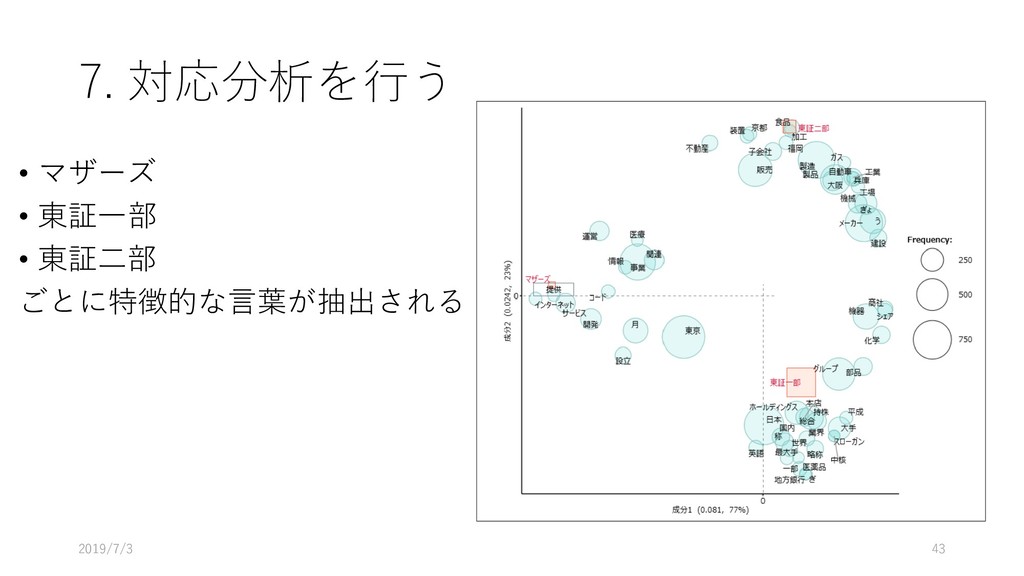{kind=link}
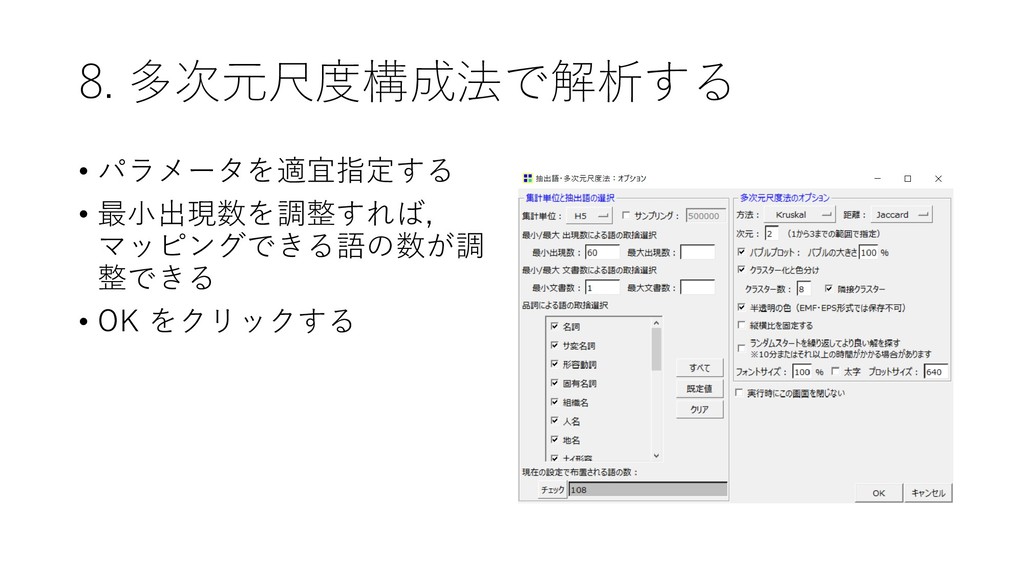
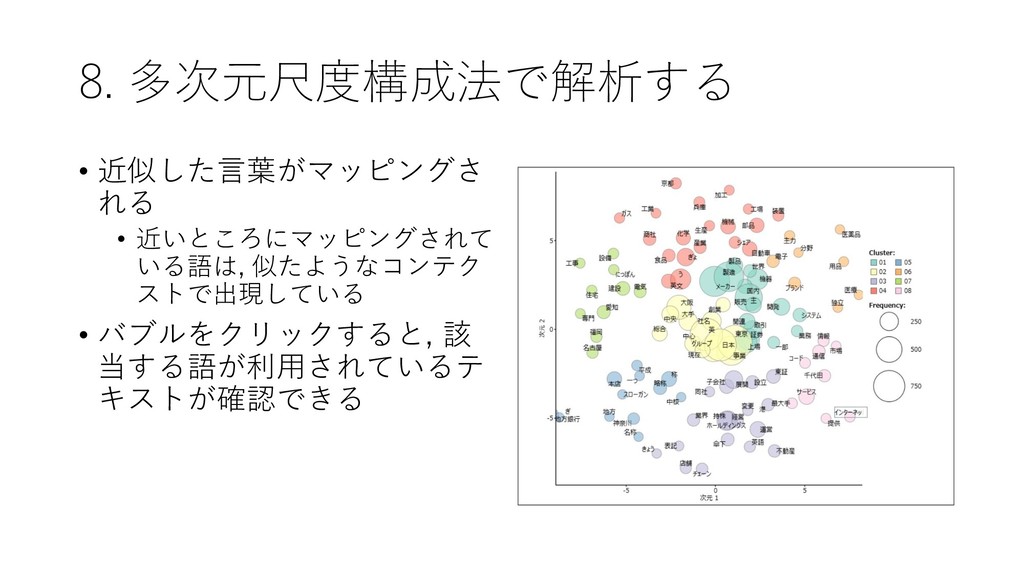
![8. 多次元尺度構成法で解析する • 近接している語のパターンを 解析できる • [ツール]-[抽出語]-[多次元尺 度構成法]を選択する](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
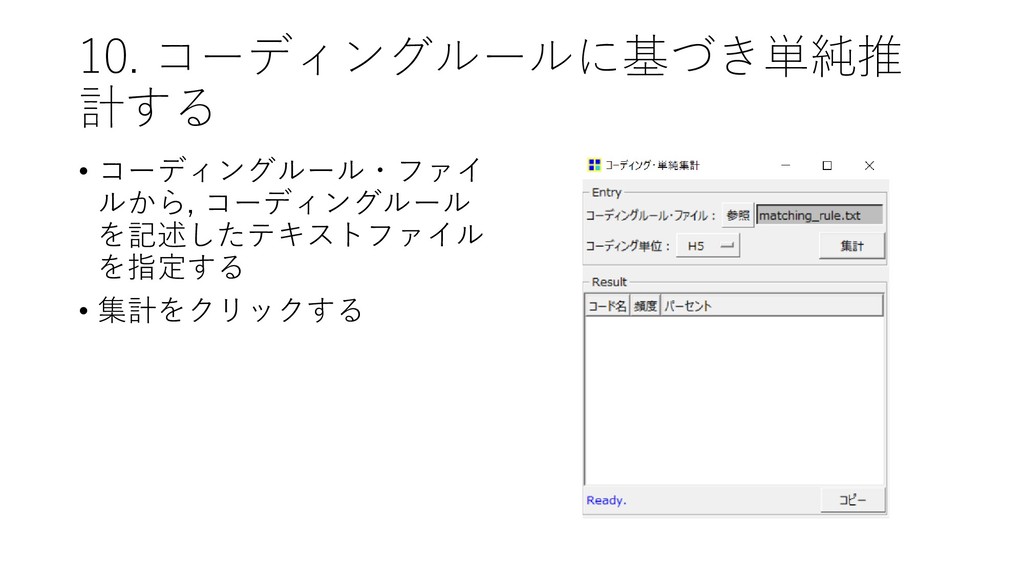
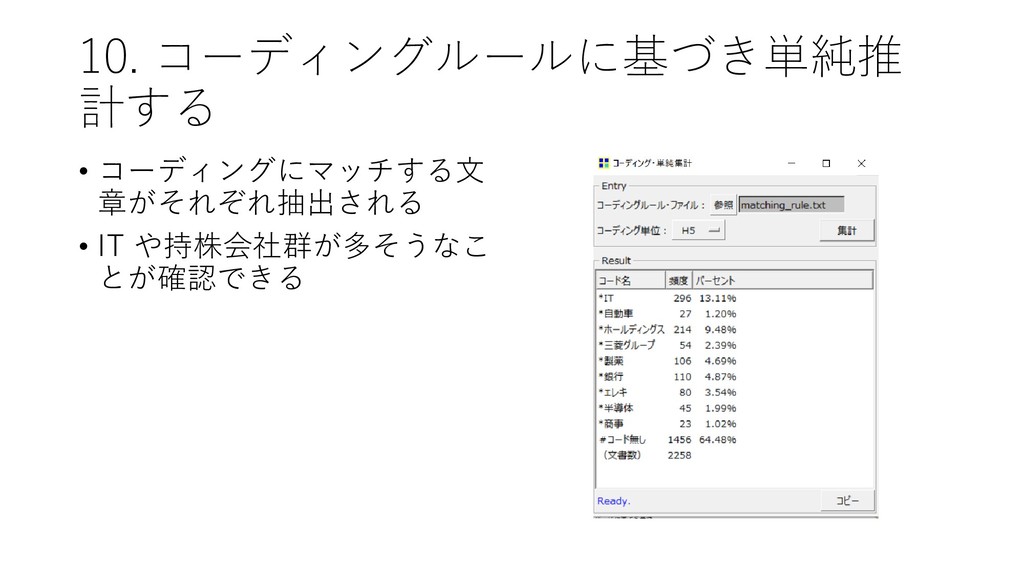
![10. コーディングルールに基づき単純推 計する • [ツール]-[コーディング]-[単 純推計] をクリックする](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_48.jpg){kind=link}
{kind=link}
{kind=link}
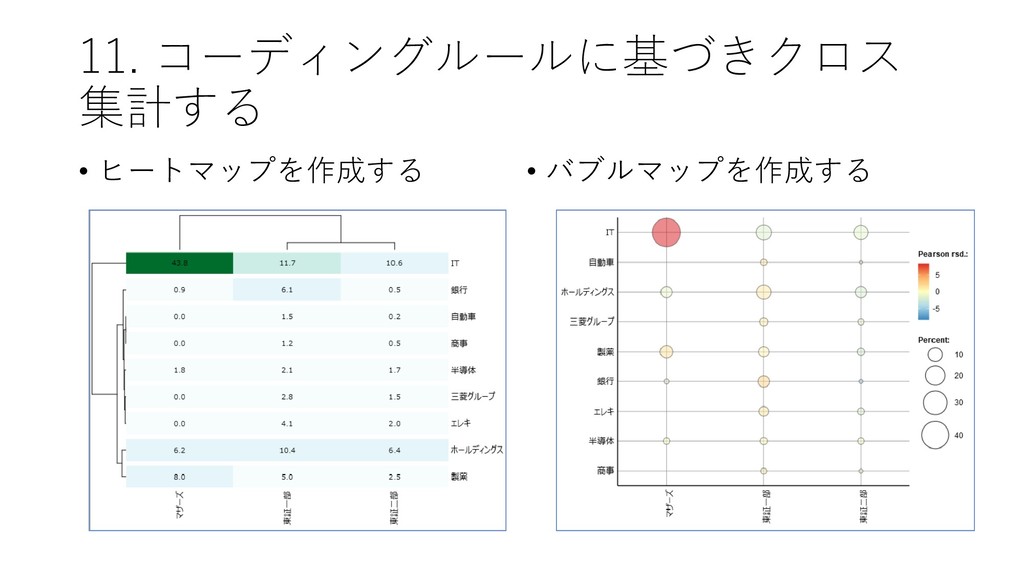
![11. コーディングルールに基づきクロス 集計する • [ツール]-[コーディング]-[ク ロス集計] をクリックする](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_51.jpg){kind=link}
![11. コーディングルールに基づきクロス 集計する • クロス集計[分類]を選択した上で, [集計] をクリックする • マザーズはITの割合が高いことが確認できる](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_52.jpg){kind=link}
{kind=link}
![12. Jacaard 係数に基づき類似度行列を導 出する • [ツール]-[コーディング]-[類 似度行列]をクリックする](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_54.jpg){kind=link}
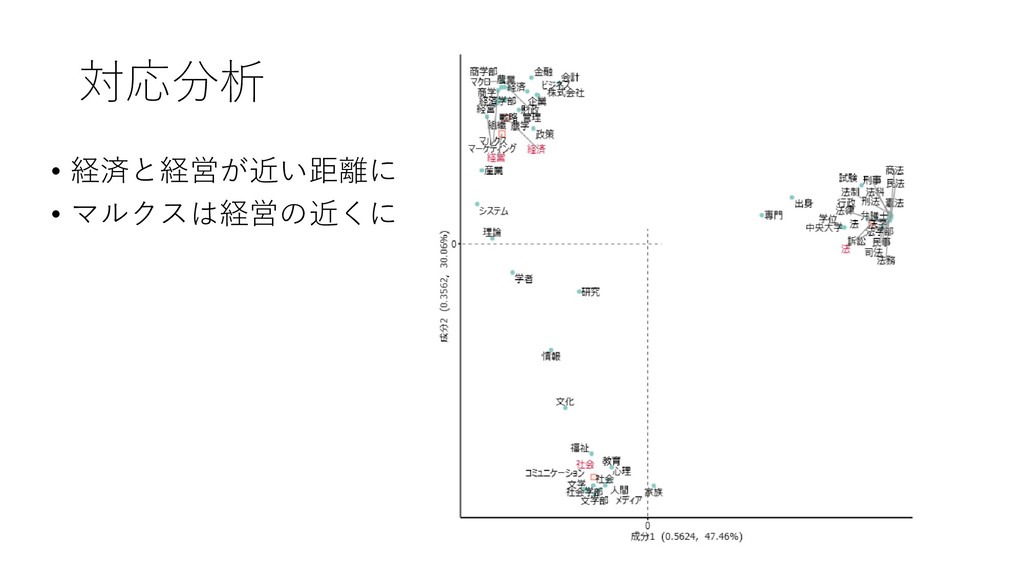
![13. コーディングルールに基づき対応分 析を行う • [ツール]-[コーディング]-[対 応分析]をクリックする](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_55.jpg){kind=link}
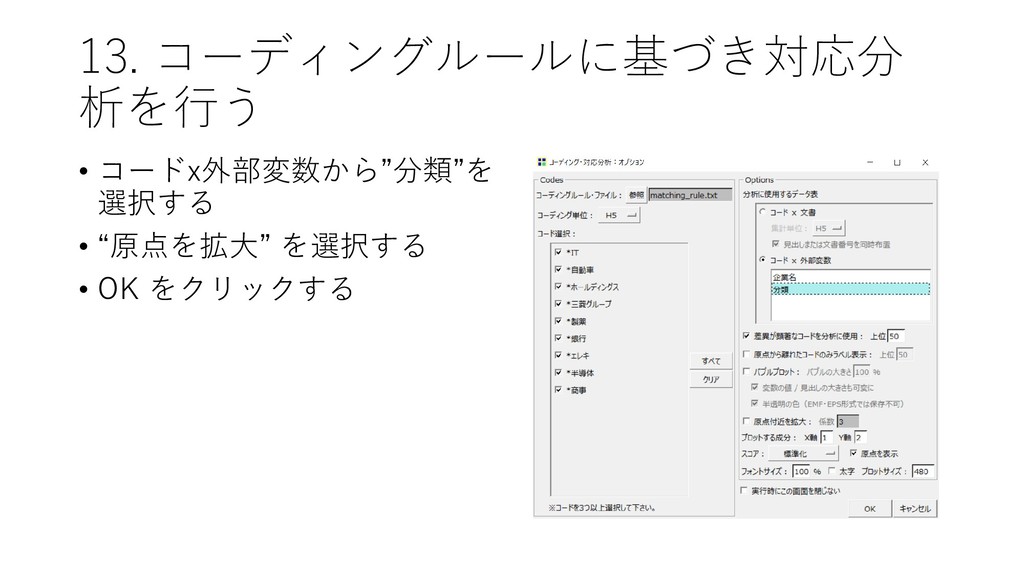{kind=link}
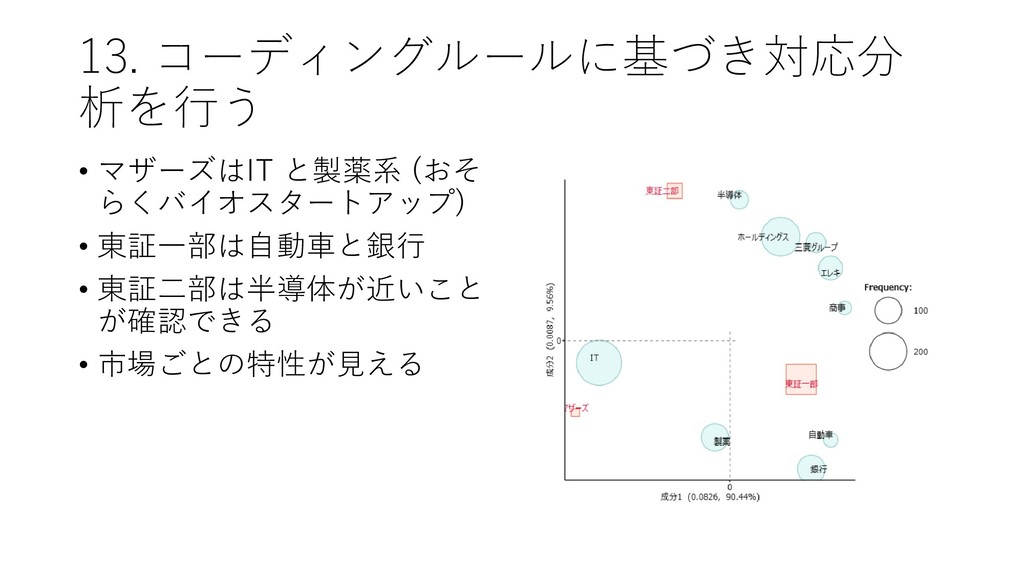{kind=link}
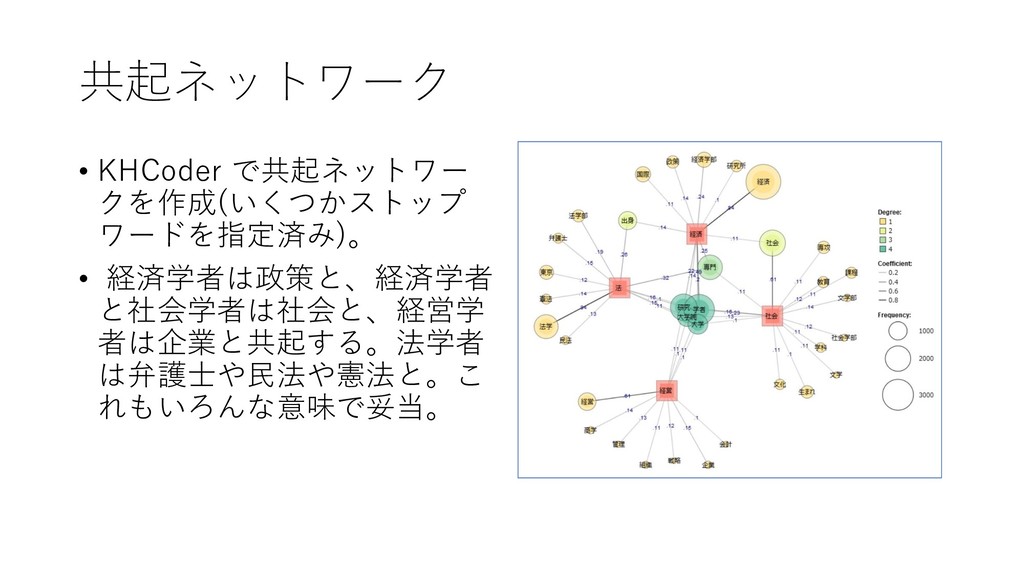
![14. コーディングルールに基づき共起 ネットワーク分析を行う • [ツール]-[コーディング]-[共 起ネットワーク] をクリック する](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_58.jpg){kind=link}
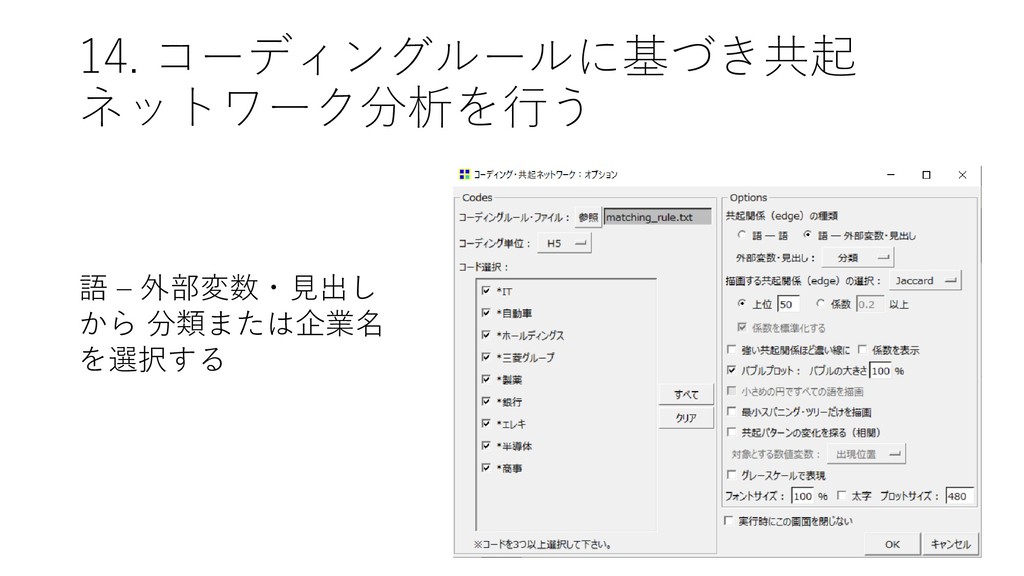{kind=link}
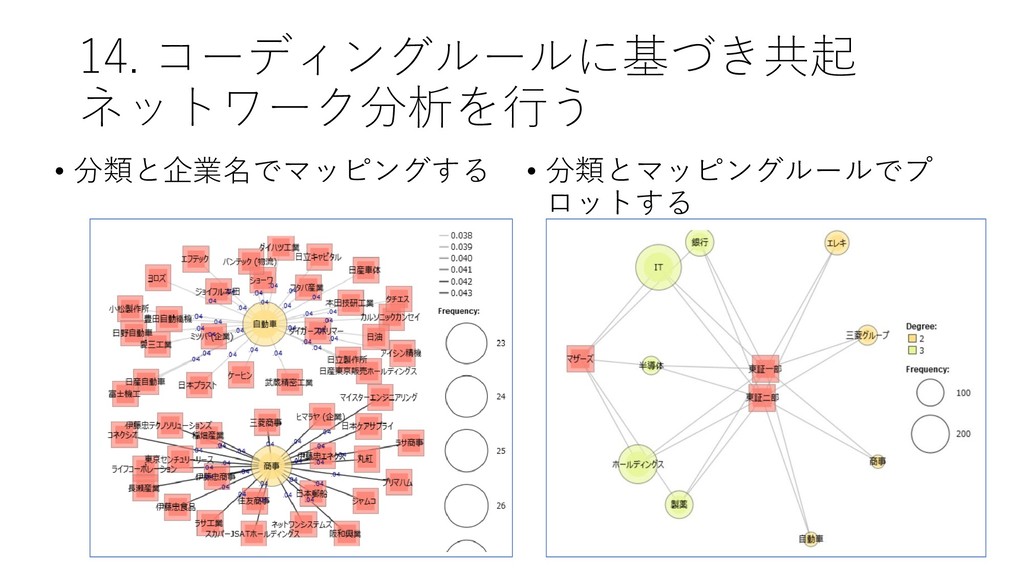{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/45a6037d0b0642458fab516a3f9e0e41/slide_149.jpg){kind=link}