Assessing the Feasibility of Web-Request Prediction Models on Mobile Platforms
Presentation slides of our paper "Assessing the Feasibility of Web-Request Prediction Models on Mobile Platforms" at MOBILESoft 2021.
Presentation: https://youtu.be/91b3juLFbeU
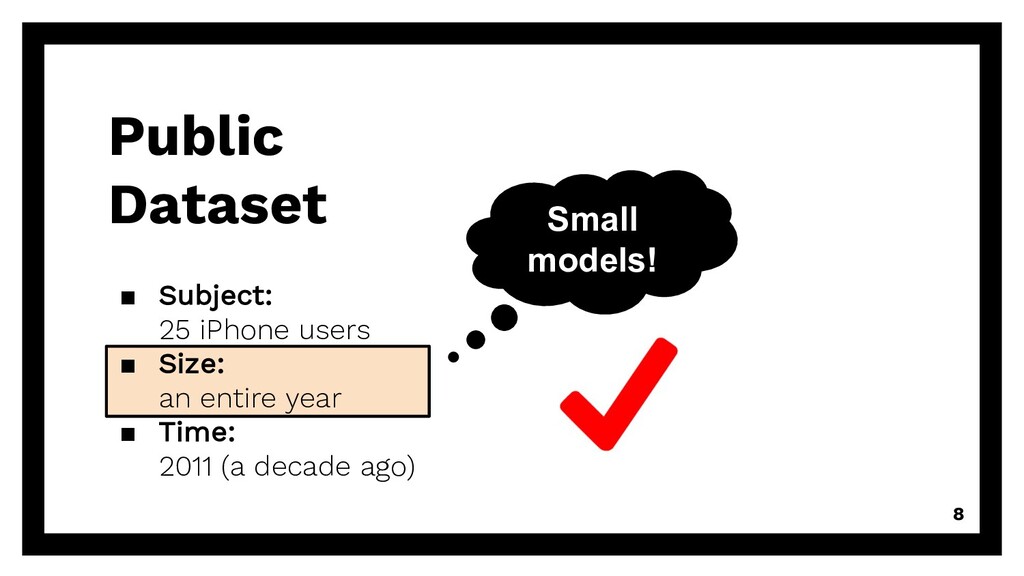
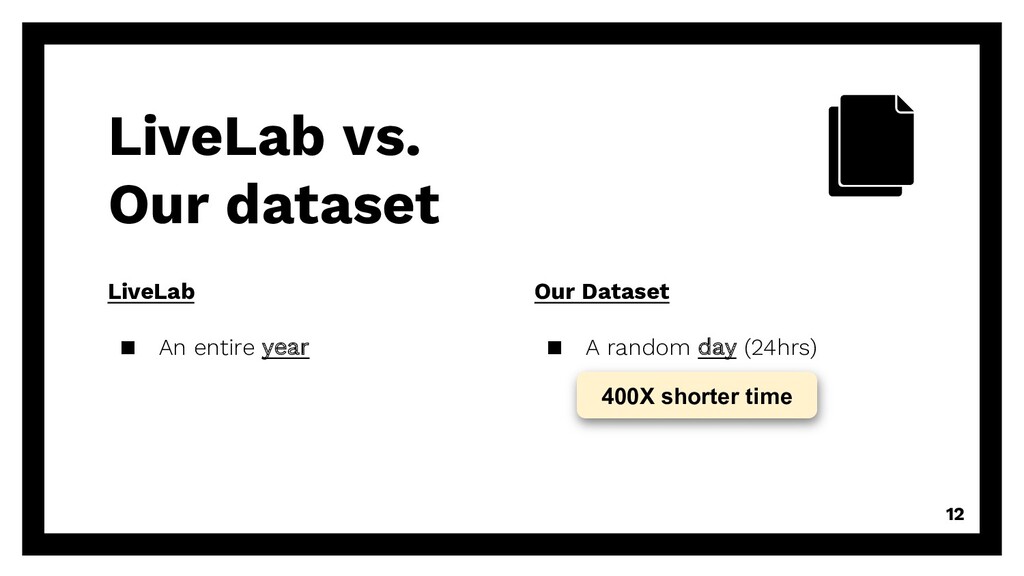
wireless networks and smartphone users in the field. SIGMETRICS Performance Evaluation Review. 2011 ▪ Subject: 25 iPhone users ▪ Size: an entire year ▪ Time: 2011 (a decade ago)
Rice university ▪ Hire participants LiveLab vs. Our dataset Our Dataset ▪ A random day (24hrs) ▪ 10K+ diverse mobile users at BUPT university ▪ No contact with users 14
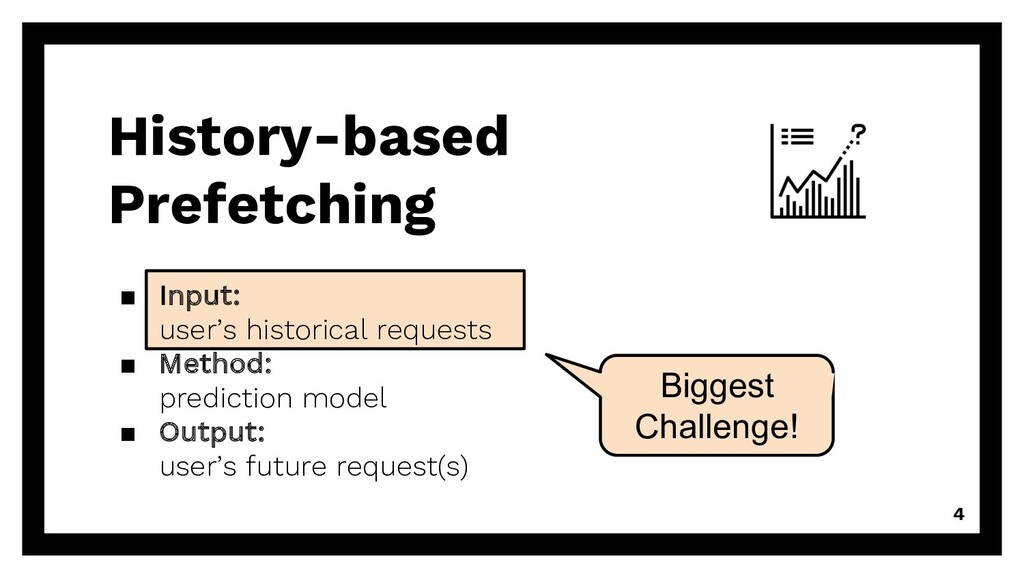
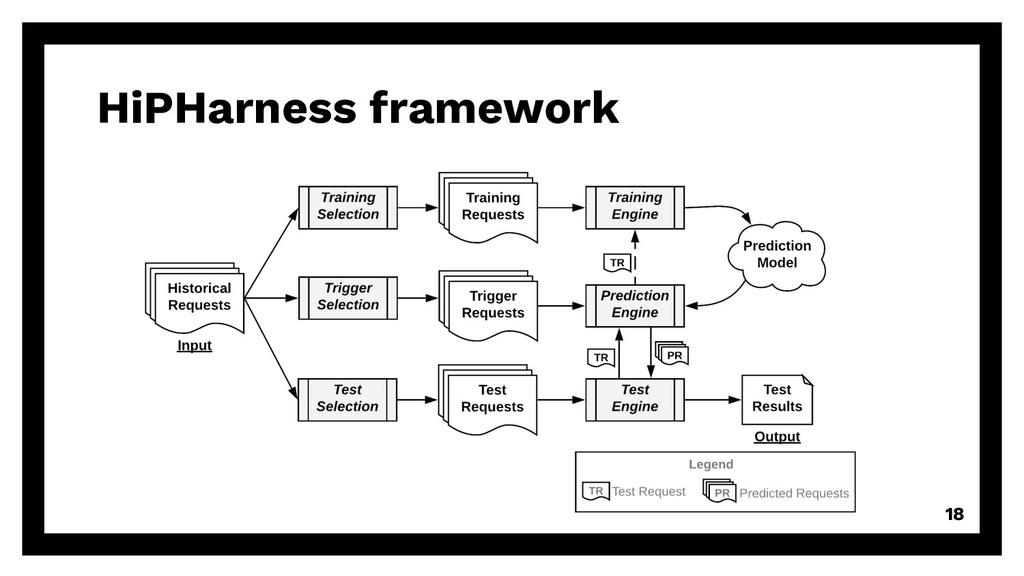
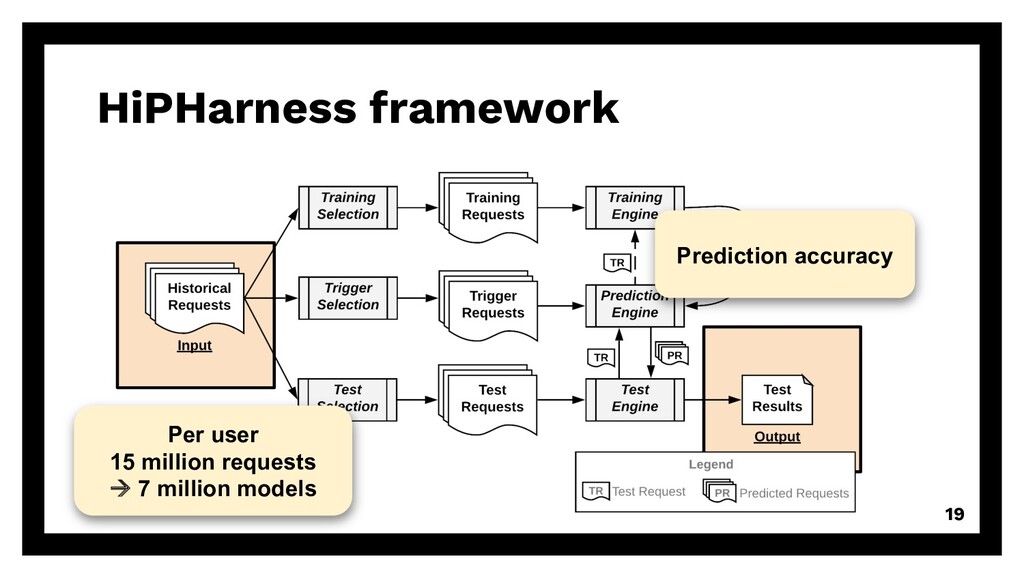
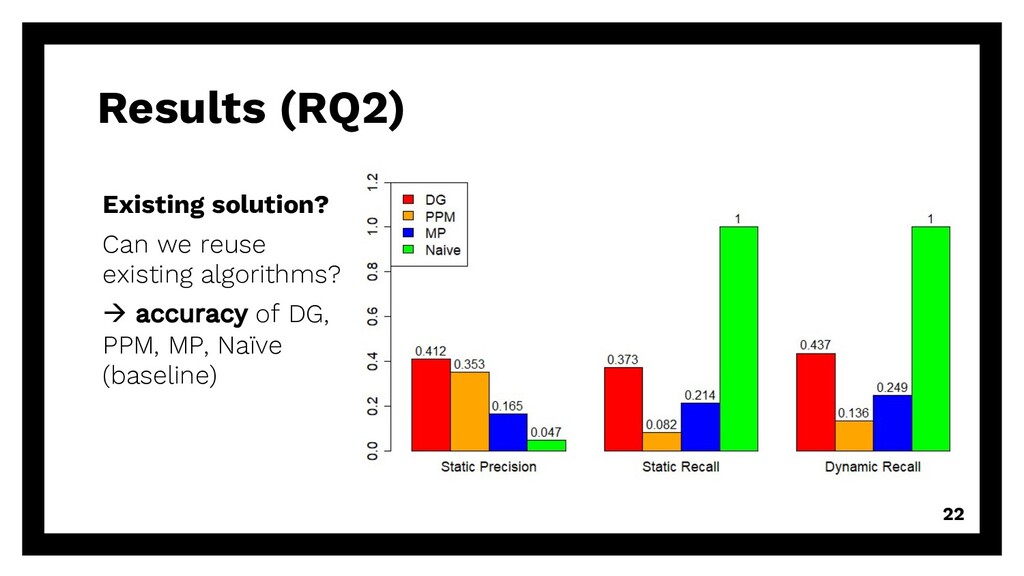
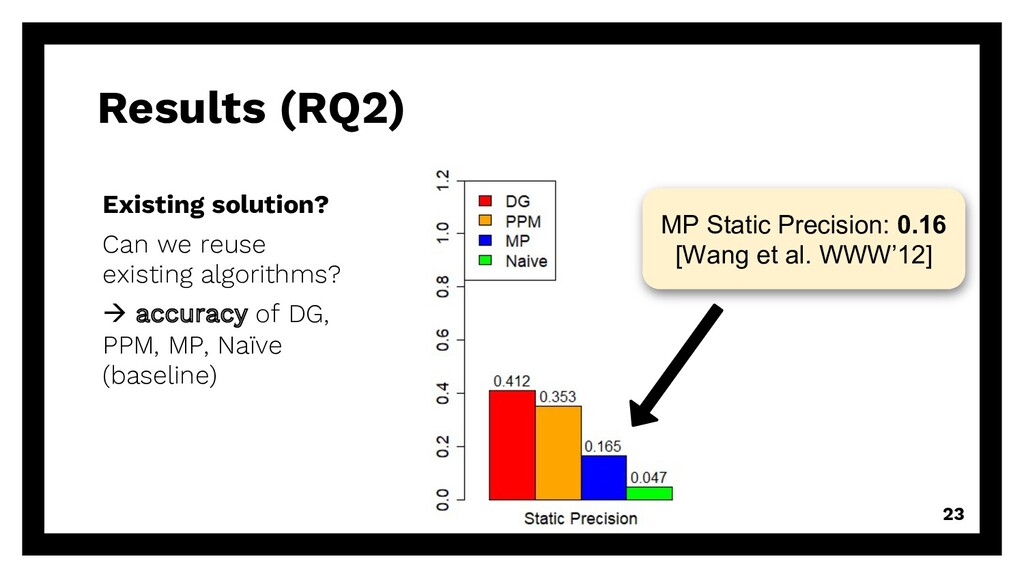
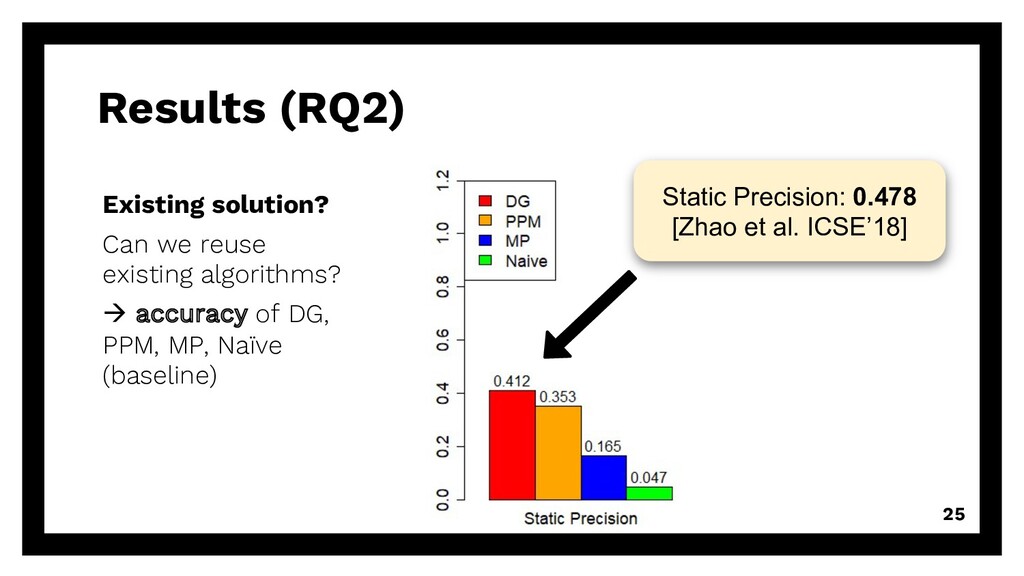
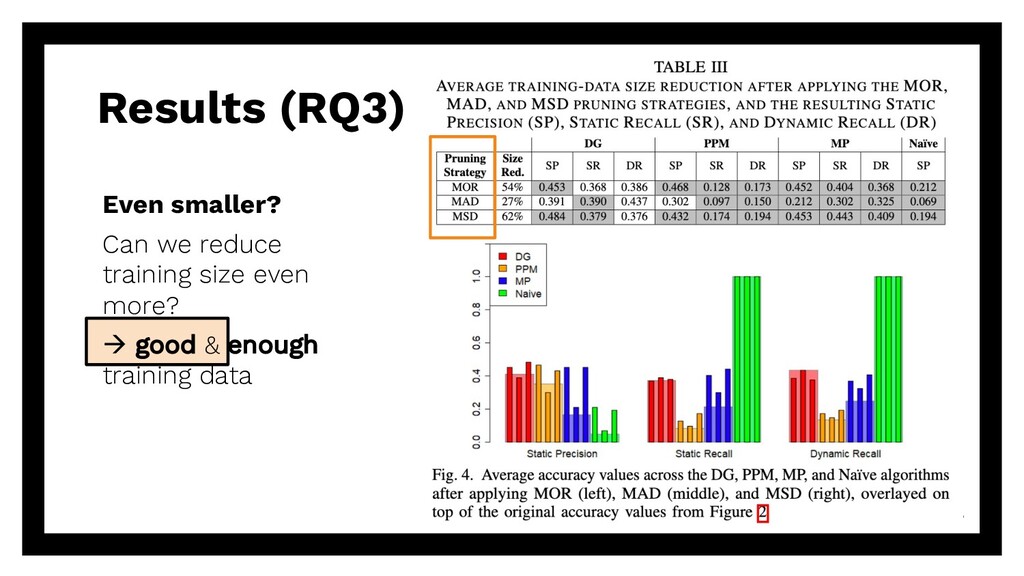
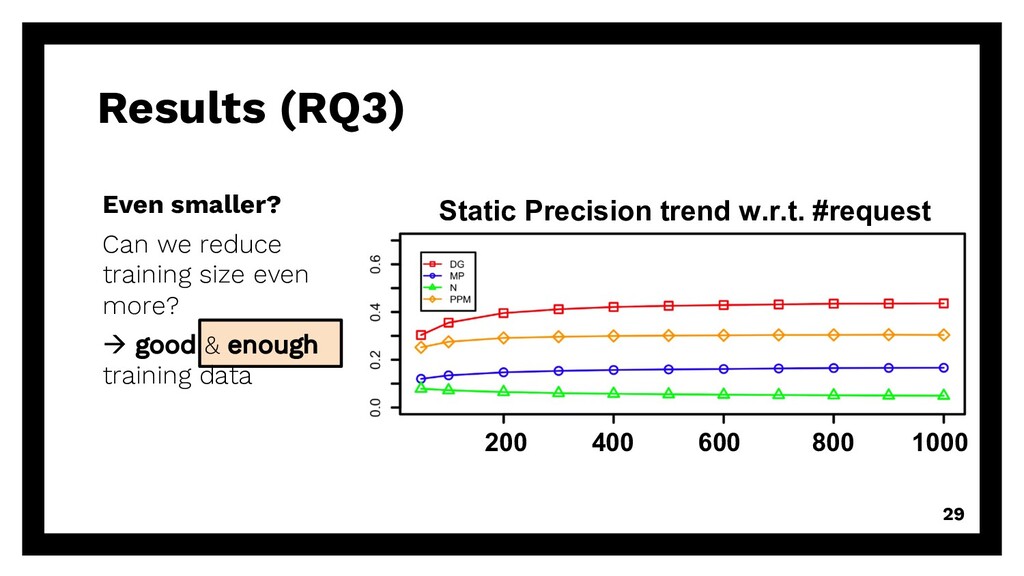
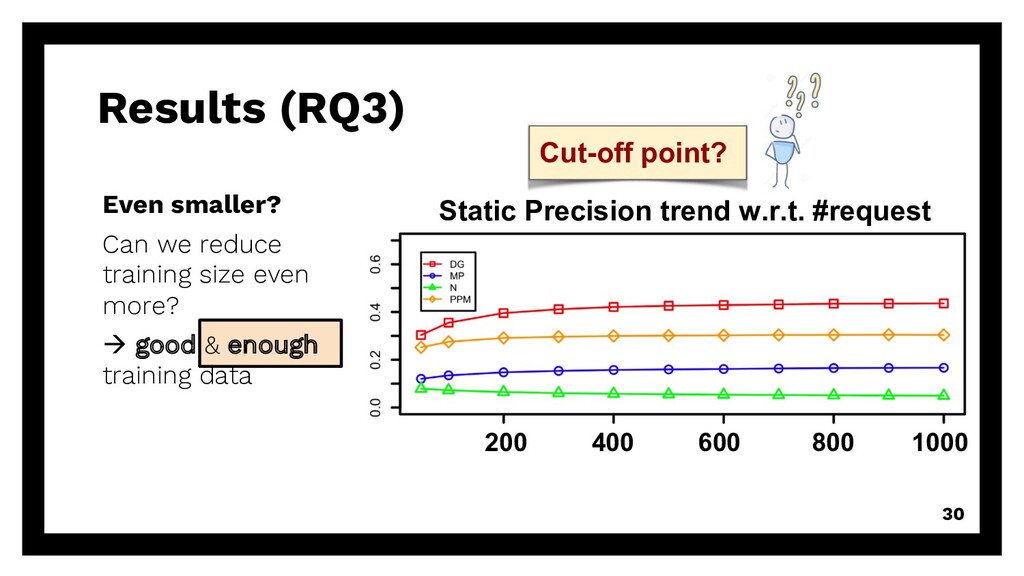
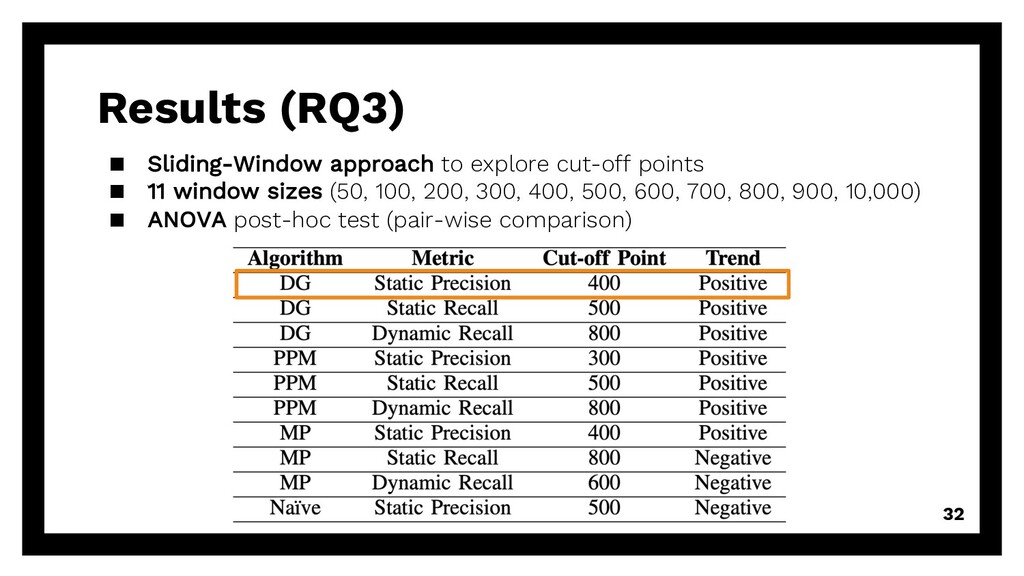
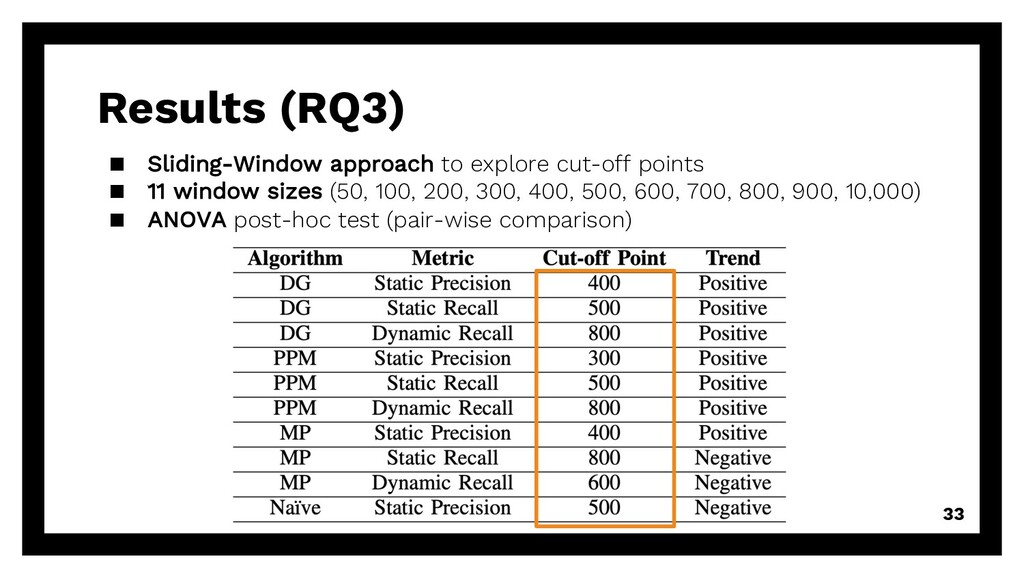
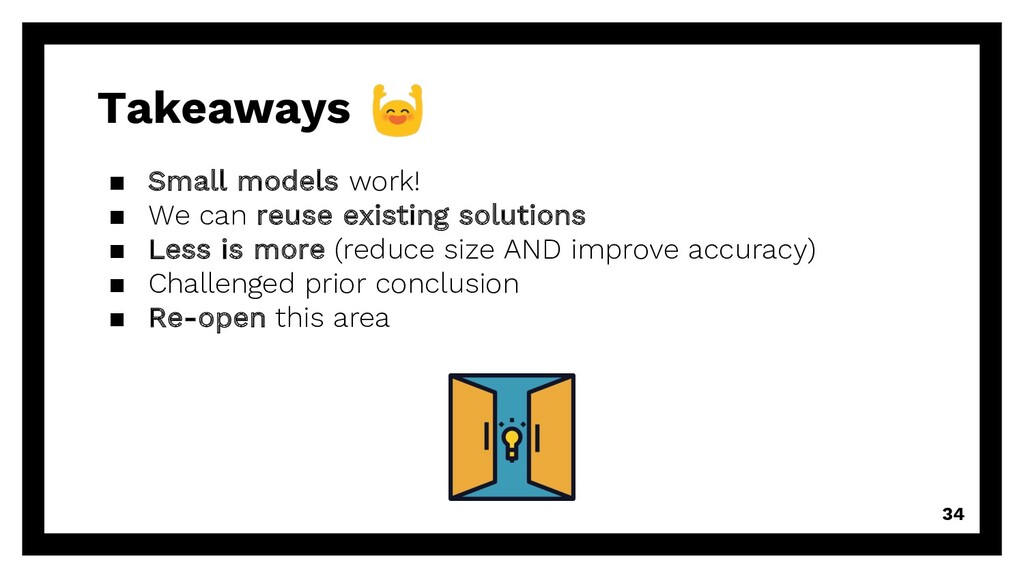
repetitive requests Existing solution? Can we reuse existing algorithms? à accuracy of DG, PPM, MP, Naïve (baseline) Even smaller? Can we reduce training size even more? à good & enough training data 15
repetitive requests Existing solution? Can we reuse existing algorithms? à accuracy of DG, PPM, MP, Naïve (baseline) Even smaller? Can we reduce training size even more? à good & enough training data 16
repetitive requests Existing solution? Can we reuse existing algorithms? à accuracy of DG, PPM, MP, Naïve (baseline) Even smaller? Can we reduce training size even more? à good & enough training data 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! 36 Any questions? [email protected] @yixue_zhao https://people.cs.umass.edu/~yixuezhao/](https://files.speakerdeck.com/presentations/9cafe21285e24c2fb723f2dfaa86915a/slide_35.jpg){kind=link}