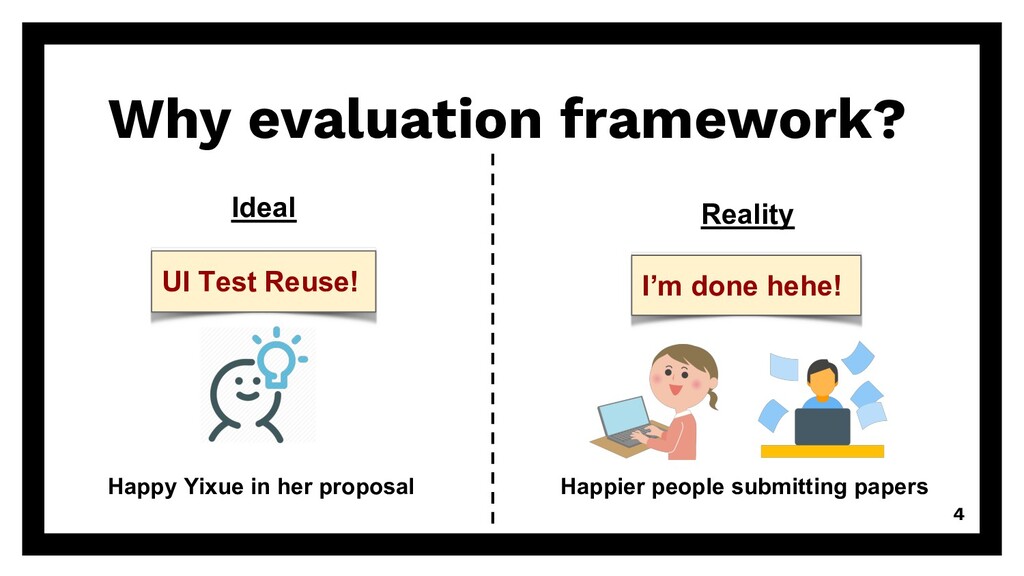
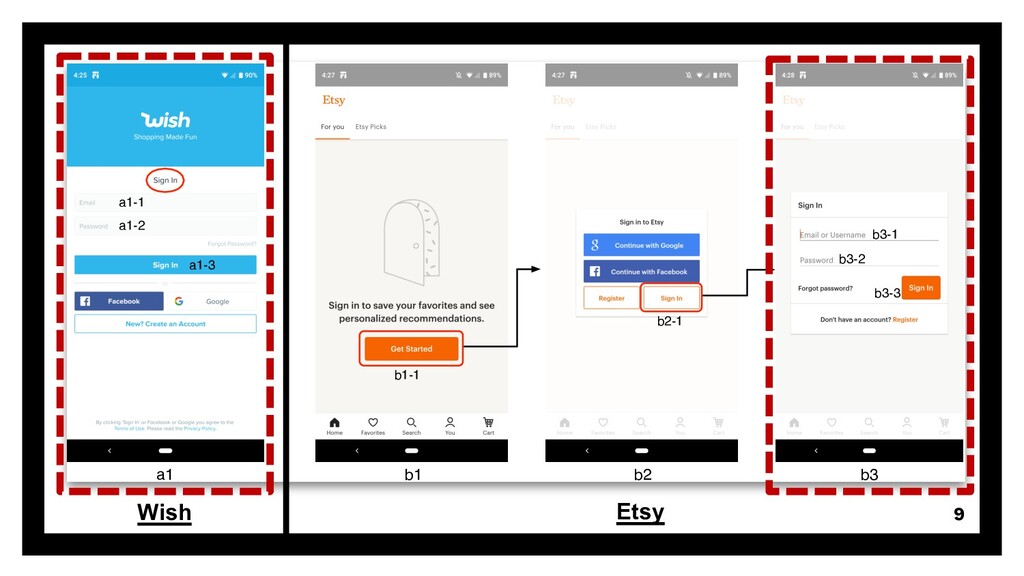
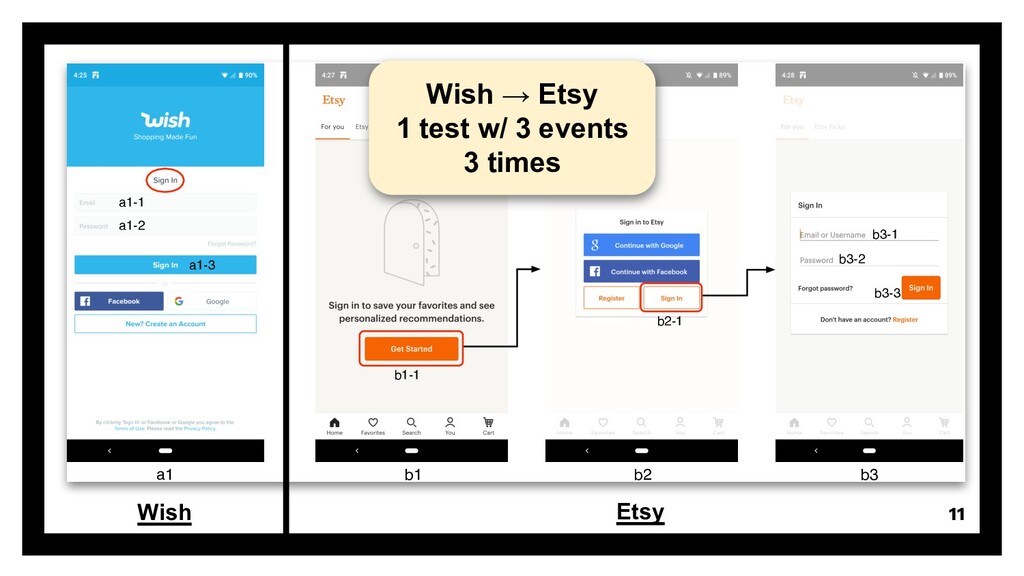
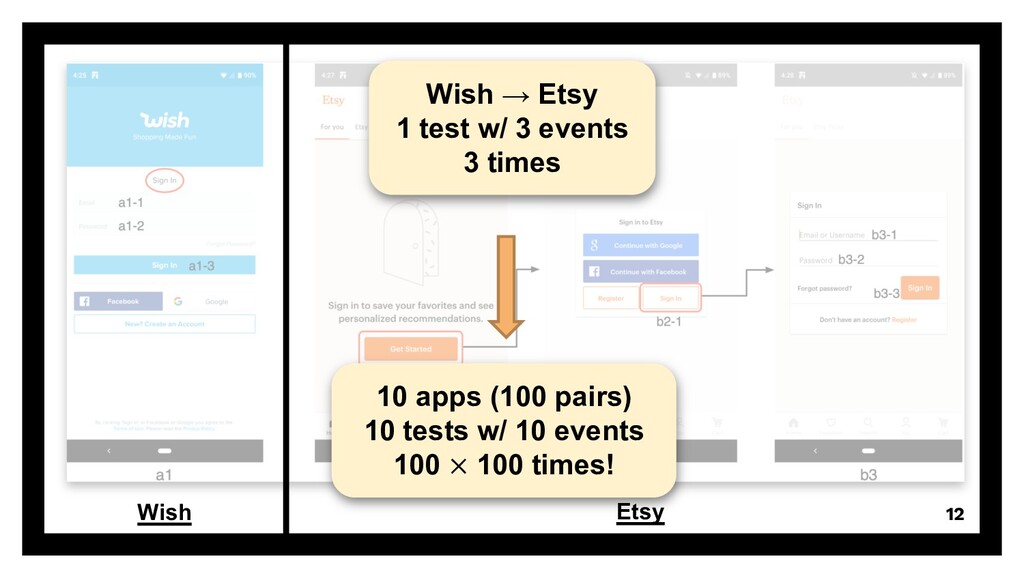
Presentation slides of the paper "FrUITeR: A Framework for Evaluating UI Test Reuse" at the ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE) 2020.
Presentation link: https://youtu.be/zVWpT5aLyQo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
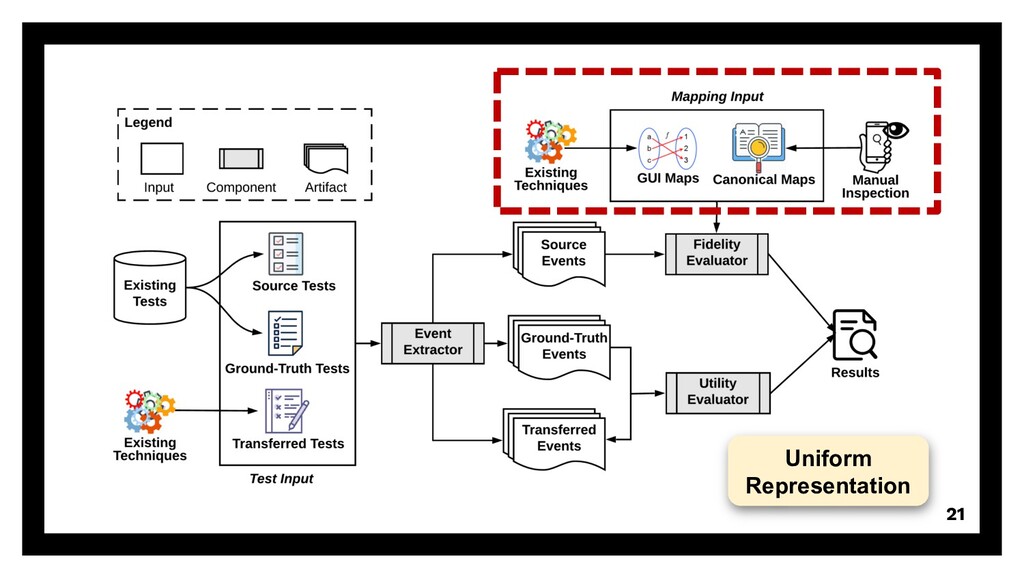{kind=link}
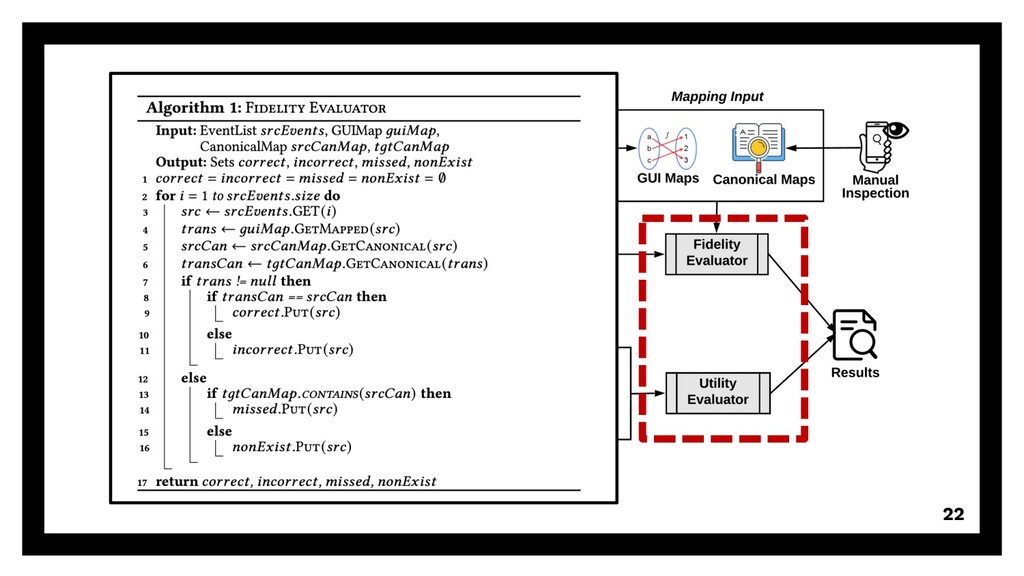{kind=link}
{kind=link}
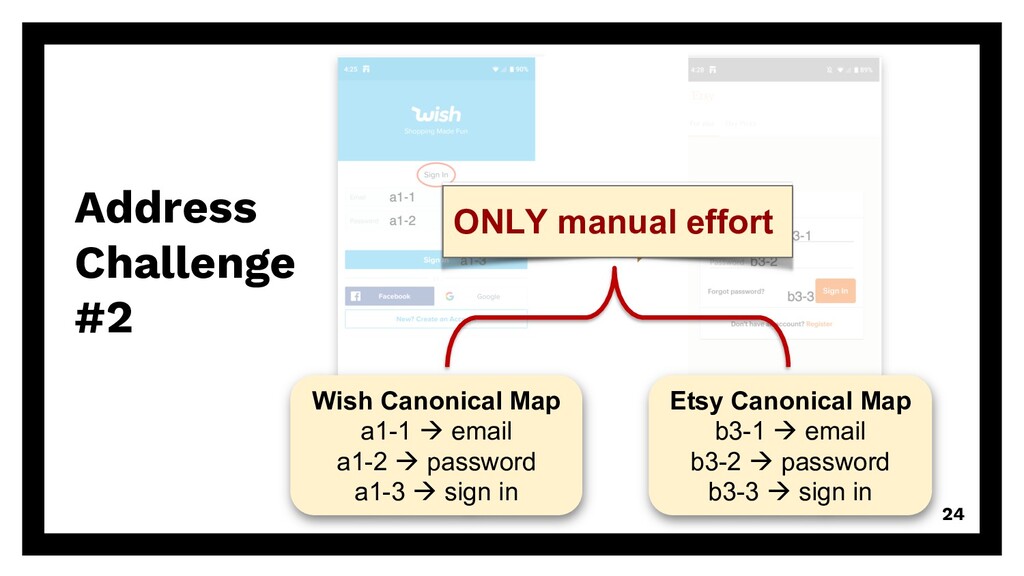{kind=link}
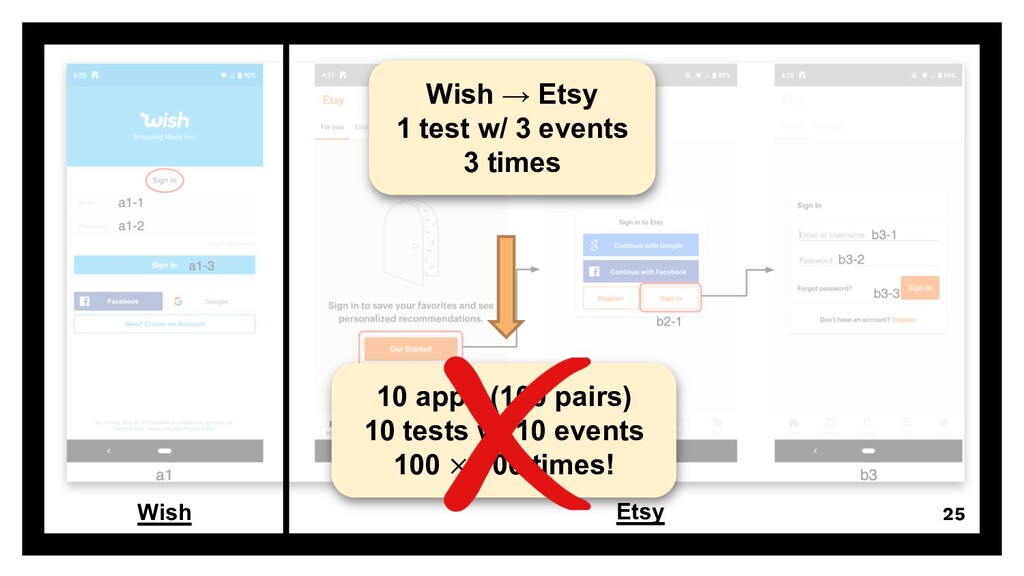{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Any questions? [email protected] @yixue_zhao https://softarch.usc.edu/~yixue/](https://files.speakerdeck.com/presentations/0322d0bb610742deabea86cd99a3d8a1/slide_32.jpg){kind=link}