Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Grammatical Error Correction with Neural Reinfo...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
youichiro
June 05, 2018
Technology
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Grammatical Error Correction with Neural Reinforcement Learning
長岡技術科学大学
自然言語処理研究室
文献紹介(2018-06-06)
youichiro
June 05, 2018
More Decks by youichiro
See All by youichiro
日本語文法誤り訂正における誤り傾向を考慮した擬似誤り生成
youichiro
0
1.6k
分類モデルを用いた日本語学習者の格助詞誤り訂正
youichiro
0
140
Multi-Agent Dual Learning
youichiro
1
200
Automated Essay Scoring with Discourse-Aware Neural Models
youichiro
0
150
Context is Key- Grammatical Error Detection with Contextual Word Representations
youichiro
1
170
勉強勉強会
youichiro
0
110
Confusionset-guided Pointer Networks for Chinese Spelling Check
youichiro
0
220
A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
youichiro
0
200
An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
youichiro
0
230
Other Decks in Technology
See All in Technology
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
320
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
140
20260720_クラウド女子会×PyLadiesTokyoコラボ Amazon Bedrock ハンズオン用資料
yuuka51
1
110
人とエージェントが高め合う協業設計
kintotechdev
0
750
GoでCコンパイラを作った話
repunit
0
150
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
450
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
2
530
AI時代こそ、スケールしないことをしよう -「作る人」から「なぜ作るか」を考える人へ / Do Things That Don't Scale in the AI Era — From How to Why
kaminashi
1
100
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
320
VPCセキュリティ対応の最新事情
nagisa53
1
270
Featured
See All Featured
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
Believing is Seeing
oripsolob
1
170
Music & Morning Musume
bryan
47
7.3k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Skip the Path - Find Your Career Trail
mkilby
1
170
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Six Lessons from altMBA
skipperchong
29
4.3k
Rails Girls Zürich Keynote
gr2m
96
14k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
Transcript
Grammatical Error Correction with Neural Reinforcement Learning Keisuke Sakaguchi, Matta
Post and Benjamin Van Durme Proceedings of the 8th International Joint Conference on Natural Language Processing, pages 366-372, 2017 ⽂献紹介(2018-06-06) ⻑岡技術科学⼤学 ⾃然⾔語処理研究室 ⼩川 耀⼀朗 1
Abstract l 強化学習を⽤いたニューラルエンコーダ・デコーダモデル l ⽂レベルの最適化が可能 l ⾃動評価・⼈⼿評価において⾼い性能を⽰す 2
Introduction l GEC(Grammatical Error Correction)タスクの動向 Ø token-level → phrase-level →
sentence-level l sentence-level: 流暢性を考慮 Ø ⽂脈による単語選択、コロケーション、単語の並び順 など l 流暢性を考慮したモデル:PBMT, neural encoder- decoder models 3
Introduction l encode-decoder の最適化に maximum likelihood estimation(MLE)が⽤いられてきた l MLEの⽋点 Ø
ある時点で間違った単語を予測すると、それ以降の単語 にも影響を与えてしまう 4
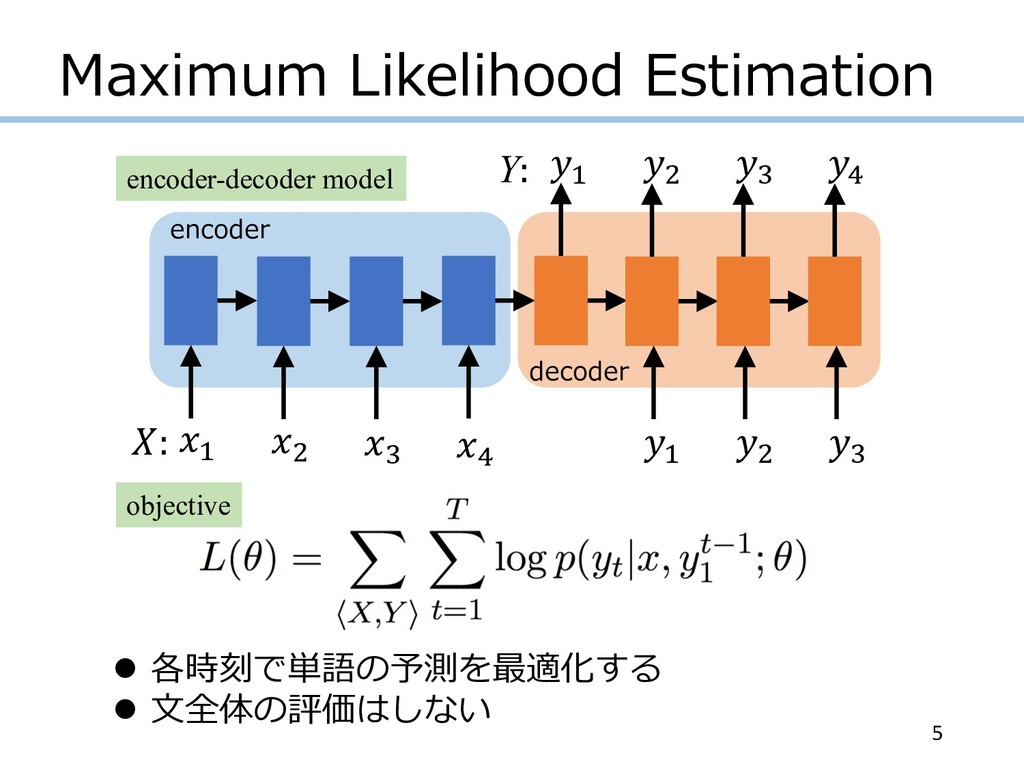
Maximum Likelihood Estimation 5 l 各時刻で単語の予測を最適化する l ⽂全体の評価はしない " #
$ % " # $ % " # $ encoder decoder : Y: encoder-decoder model objective
Neural Reinforcement Leaning l 報酬を最⼤化するようにNRLのパラメータを学習→強化学習 6 (ŷ| ; ): 予測単語列の確率
(ŷ, ): 正解(y)に対する予測(ŷ)の報酬 objective
Reward in GEC: GLEU l 原⽂(S), 出⼒(H), 正解(R)からN-gram適合率を計算する l N(A,
B): AとBのN-gramの重複数 l BP(brevity penalty): 出⼒の⻑さ(h)と正解の⻑さ(r)で決まる 7
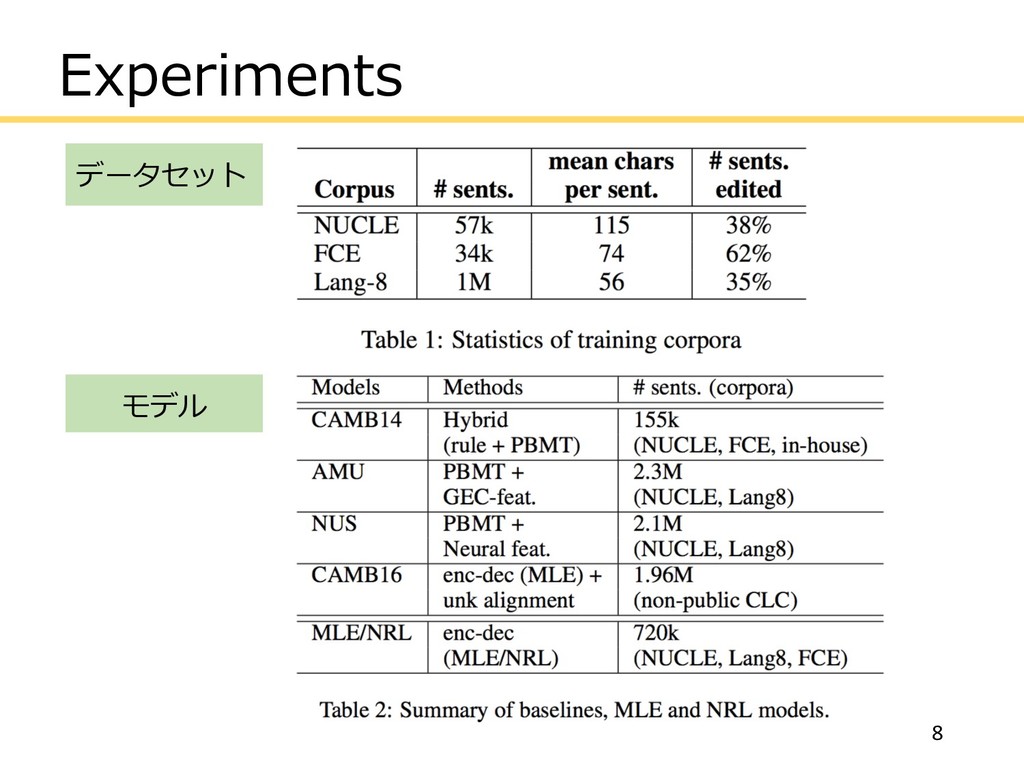
Experiments データセット 8 モデル
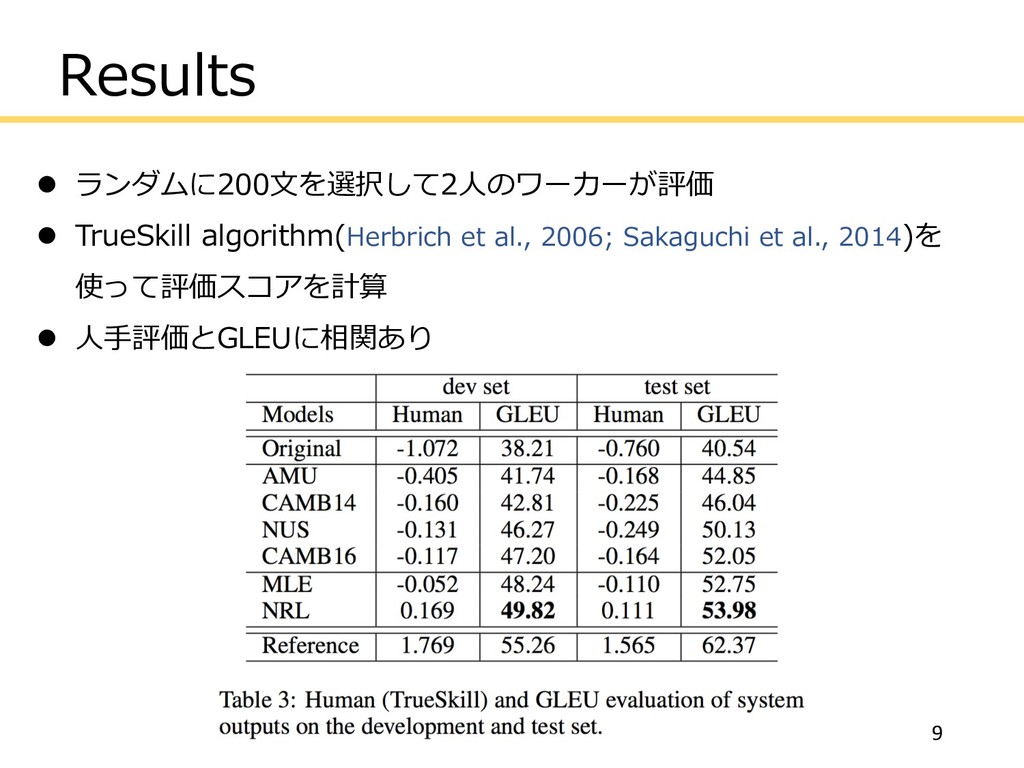
Results l ランダムに200⽂を選択して2⼈のワーカーが評価 l TrueSkill algorithm(Herbrich et al., 2006; Sakaguchi
et al., 2014)を 使って評価スコアを計算 l ⼈⼿評価とGLEUに相関あり 9
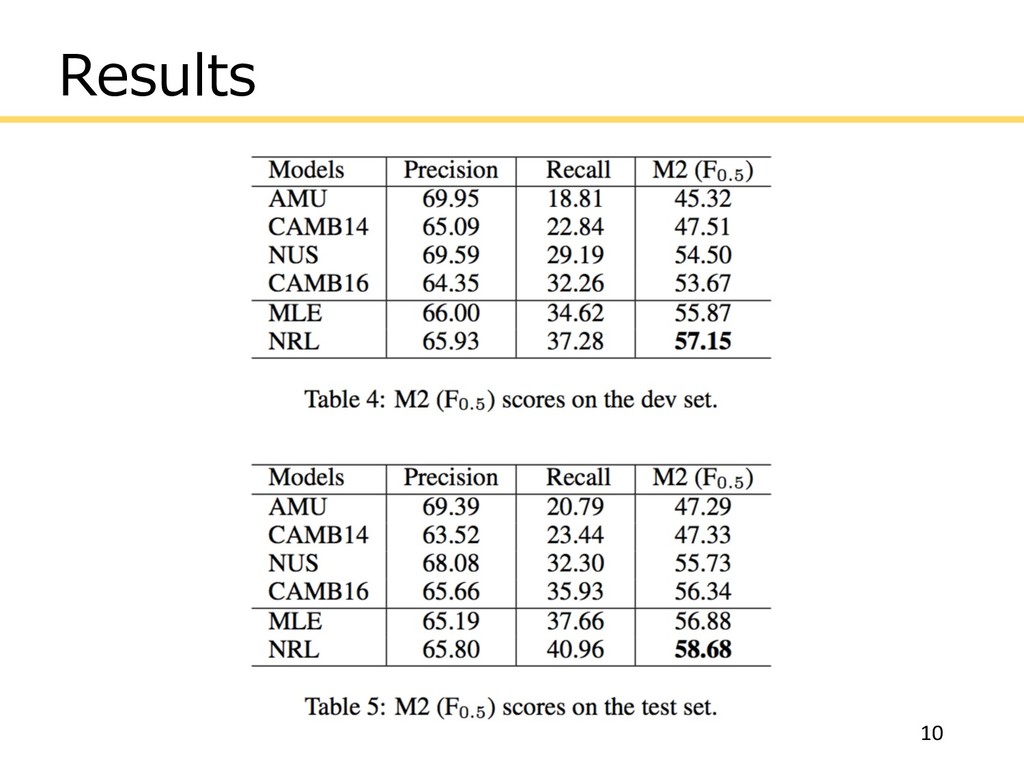
Results 10
Conclusions l 強化学習を⽤いたニューラルエンコーダデコーダモデル l MLEの問題である単語レベルの評価に対して、GLEUを⽤い て⽂レベルの最適化に取り組んだ l ⼈⼿評価・⾃動評価において提案⼿法が優れた性能を⽰し た 11
Extra Ø a 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}