Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Unsupervised Context-Sensitive Spelling Correct...
Search
youichiro
August 22, 2017
Technology
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Unsupervised Context-Sensitive Spelling Correction of Clinical Free-Text with Word and Character N-Gram Embeddings
文献紹介(2017年8月22日)
長岡技術科学大学
自然言語処理研究室
youichiro
August 22, 2017
More Decks by youichiro
See All by youichiro
日本語文法誤り訂正における誤り傾向を考慮した擬似誤り生成
youichiro
0
1.6k
分類モデルを用いた日本語学習者の格助詞誤り訂正
youichiro
0
140
Multi-Agent Dual Learning
youichiro
1
200
Automated Essay Scoring with Discourse-Aware Neural Models
youichiro
0
150
Context is Key- Grammatical Error Detection with Contextual Word Representations
youichiro
1
170
勉強勉強会
youichiro
0
110
Confusionset-guided Pointer Networks for Chinese Spelling Check
youichiro
0
220
A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
youichiro
0
200
An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
youichiro
0
230
Other Decks in Technology
See All in Technology
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
1k
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.5k
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
510
「休む」重要さ
smt7174
6
1.6k
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
380
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
450
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
1
270
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
210
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
160
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
13
4.4k
AI時代こそ、スケールしないことをしよう -「作る人」から「なぜ作るか」を考える人へ / Do Things That Don't Scale in the AI Era — From How to Why
kaminashi
1
100
生成 AI 時代にいま一度「問い合わせ」について考えてみる
kazzpapa3
1
130
Featured
See All Featured
Building AI with AI
inesmontani
PRO
1
1.1k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
910
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
How to train your dragon (web standard)
notwaldorf
97
6.7k
Google's AI Overviews - The New Search
badams
0
1.1k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Product Roadmaps are Hard
iamctodd
55
12k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
Transcript
Unsupervised Context-Sensitive Spelling Correction of Clinical Free-Text with Word and
Character N-Gram Embeddings Pieter Fivez, Simon Suster and Walter Daelemans Proceedings of the BioNLP 2017 workshop, pages 143–148. 文献紹介(2017/08/22) 自然言語処理研究室 小川 耀一朗 0
概要 l 臨床テキストのスペル訂正 l 分散表現(neural embeddings)を⽤いることで⽂脈を考 慮した訂正モデルを提案 l 既存のスペル訂正ツールよりも⼤幅に優れている 1
/ 9
目的 Ø 臨床テキスト l 医療現場における診察や治療に関する⽂章 l 専⾨⽤語が多い l 様々な略語、新しい名称が使われている l
10~15%がスペルミス[Patrick et al., 2010] →単純なスペル訂正よりも複雑 2 / 9
目的 Ø noisy channel model l 頻度情報(⾔語モデル)を⽤いて置換候補を選択 l ⽂脈情報を活⽤せず l
⽂脈情報を無視するとパフォーマンスに悪影響 [Flor, 2012] 分散表現を使って⽂脈の⼿がかりを訂正に利⽤ 3 / 9
候補生成 l スペルミスを正しい単語に置換するための候補を⽣成 • 編集距離(Damerau-Levenshtein edit distance)が2以下の単語 • 発⾳情報(Double Metaphone)の編集距離が1以下の単語
を単語辞書(UMLS®SPECIALIST lexicon and Jazzy)から抽出 [goint] → going(1), point(1), joint(1), groin(2) 編集距離:置換、挿⼊、削除、転置の操作を⾏う回数 発⾳情報:⼦⾳だけで発⾳を近似(goint→KNT) 4 / 9
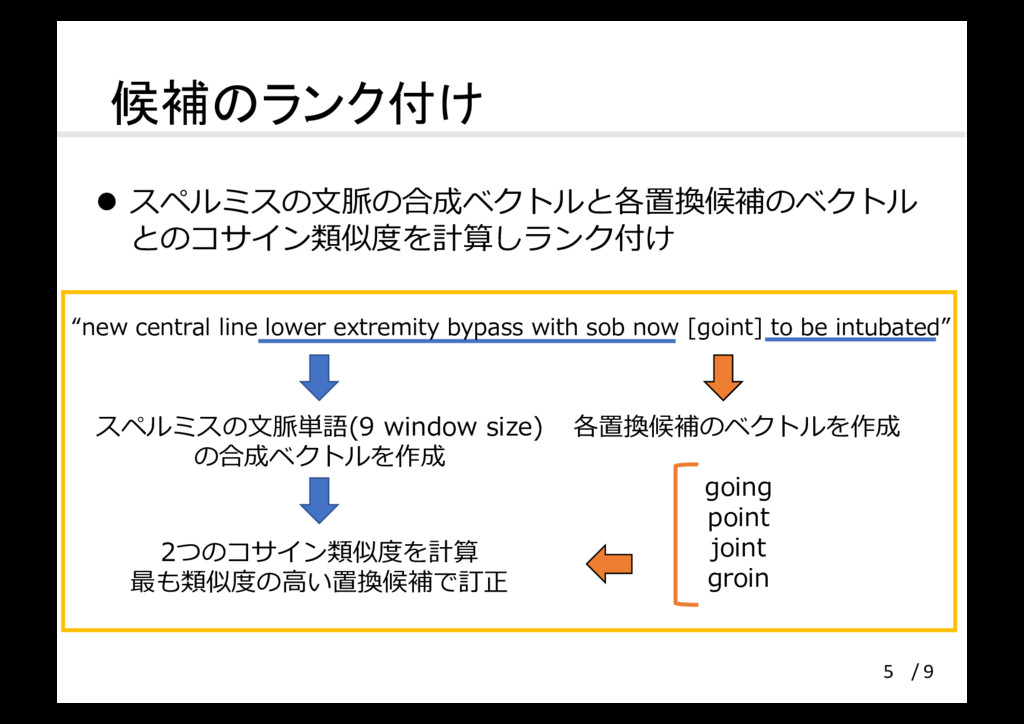
候補のランク付け l スペルミスの⽂脈の合成ベクトルと各置換候補のベクトル とのコサイン類似度を計算しランク付け 5 各置換候補のベクトルを作成 going point joint groin
2つのコサイン類似度を計算 最も類似度の⾼い置換候補で訂正 スペルミスの⽂脈単語(9 window size) の合成ベクトルを作成 “new central line lower extremity bypass with sob now [goint] to be intubated” / 9
実験設定 Ø MIMIC-lll[Johnson et al., 2016] l 医療⽂章のデータベース Ø 分散表現の学習
l fastText(Word2Vecの拡張)のskipgramモデルを使⽤ l MIMIC-lllコーパスから425M語を学習 Ø テストデータ l MIMIC-lllからスペルミス873事例を抽出・アノテート 6 / 9
実験結果 7 Ø 既存の2つのツール、Noisy Channel Modelよりも⾼い正解率を⽰す HunSpell: 公開されているスペルチェッカー Lai et
al.: 従来⼿法 Context: 提案⼿法 Noisy Channel: 従来⼿法を再実装 off-the-shelf: 従来の単語辞書を⽤いて実験 with completed lexicon: ⾼度な医療の専⾨⽤語を単語辞書に追加 / 9
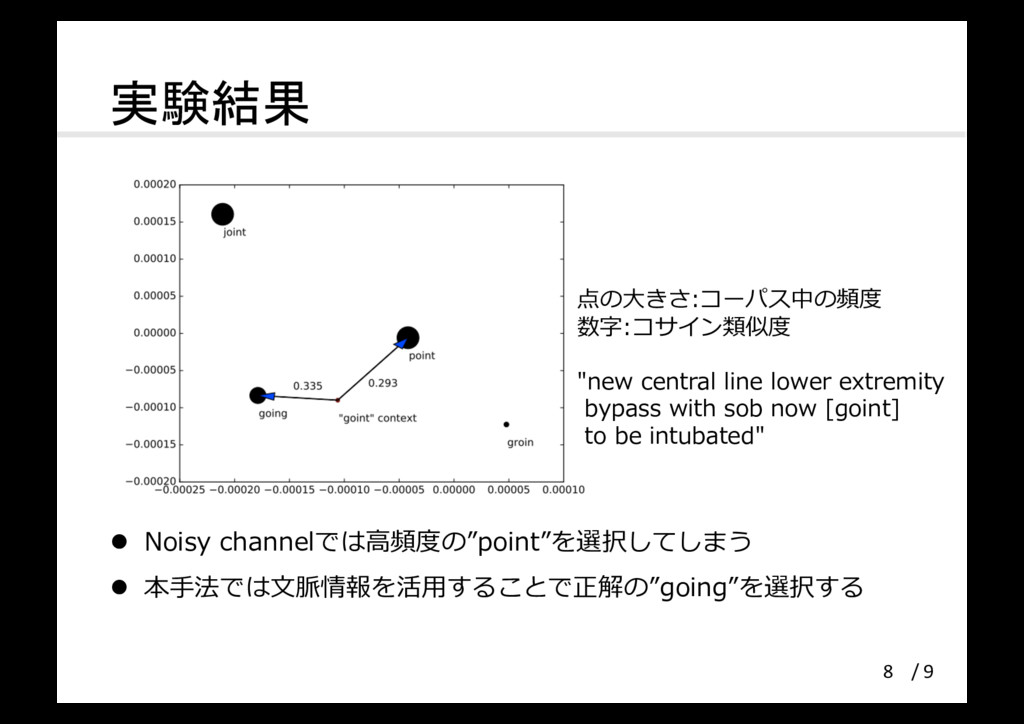
実験結果 l Noisy channelでは⾼頻度の”point”を選択してしまう l 本⼿法では⽂脈情報を活⽤することで正解の”going”を選択する 8 点の⼤きさ:コーパス中の頻度 数字:コサイン類似度 "new
central line lower extremity bypass with sob now [goint] to be intubated" / 9
まとめ l 臨床テキストのスペル訂正⼿法を提案 l 分散表現を⽤いて⽂脈情報を活⽤した訂正が可能となっ た l 既存のツールやNoisy Channel Modelよりも⾼い正解率
を⽰した 9 / 9
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験設定 Ø MIMIC-lll[Johnson et al., 2016] l 医療⽂章のデータベース Ø 分散表現の学習](https://files.speakerdeck.com/presentations/23fd0701f5fa461da6fba9912f443b01/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}