Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Gunosy研究会]Personalized Collaborative Clustering
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
ysekky
April 10, 2014
Research
1.5k
1
Share
[Gunosy研究会]Personalized Collaborative Clustering
ysekky
April 10, 2014
More Decks by ysekky
See All by ysekky
スタートアップの開発サイクルに学ぶ 研究活動の進め方 / research practices inspired by startup business strategy
ysekky
0
2.4k
[論文紹介] A Method to Anonymize Business Metrics to Publishing Implicit Feedback Datasets (Recsys2020) / recsys20-reading-gunosy-datapub
ysekky
3
2.9k
JSAI2020 OS-12 広告とAI オープニング / JSAI2020-OS-12-ads-and-ai-opening
ysekky
0
2.2k
JSAI2020インダストリアルセッション - Gunosyにおける研究開発 / jsai2020-gunosy-rd-examples
ysekky
1
820
ウェブサービス事業者における研究開発インターン[株式会社Gunosy] - テキストアナリティクスシンポジウム2019 / research-intern-case-study-at-gunosy
ysekky
0
3k
Gunosyにおけるニュース記事推薦/ news-recommendation-in-gunosy-webdbf2019
ysekky
1
1.6k
DEIM2019技術報告セッション - Gunosyの研究開発 / deim-2019-sponsor-session-gunosy-research
ysekky
0
1.3k
Analysis of Bias in Gathering Information Between User Attributes in News Application (ABCCS 2018)
ysekky
1
2.5k
世代による政治ニュース記事の閲覧傾向の違いの分析 - JSAI2018 / Analysis of differences in viewing behavior of politics news by age
ysekky
0
4.1k
Other Decks in Research
See All in Research
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
620
FUSE-RSVLM: Feature Fusion Vision-Language Model for Remote Sensing
satai
3
840
羽田新ルート運用6年の検証
1manken
0
160
Ghost in the 7‑Zip: The Shadow of Residential Proxies Creeping into Your Life
nttcom
0
840
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
210
コーディングエージェントとABNを再考
hf149
2
700
Any-Optical-Model: A Universal Foundation Model for Optical Remote Sensing
satai
3
800
Data Visualization Tools in the Age of AI
flekschas
0
150
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
110
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
460
2026 東京科学大 情報通信系 研究室紹介 (すずかけ台)
icttitech
0
3.7k
衛星×エッジAI勉強会 衛星上におけるAI処理制約とそ取組について
satai
4
530
Featured
See All Featured
My Coaching Mixtape
mlcsv
0
140
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
190
We Have a Design System, Now What?
morganepeng
55
8.2k
Google's AI Overviews - The New Search
badams
0
1k
Crafting Experiences
bethany
1
170
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
580
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.5k
Believing is Seeing
oripsolob
1
140
Making the Leap to Tech Lead
cromwellryan
135
9.9k
エンジニアに許された特別な時間の終わり
watany
107
250k
Transcript
論文紹介: Personalized Collabora0ve Clustering Yisong Yue, Ching Wang, Khalid
El-‐Arini, Carlos Guestrin WWW 2014 Yoshifumi Seki@Gunosy研究会 2014.04.02
クラスタリングの基準は人によって異なる スポーツ系 時代劇系 ホモ 萌え
目的 • クラスタリングをユーザごとに最適化したい – あるアイテムをどのように分類するかはユーザに よって異なる – ユーザごとにモデルをつくろうとするとユーザごと に多くのデータ量が必要になる
• あるユーザにとってのアイテム同士の類似度 を他のユーザのクラスタも含めて推測する – 協調フィルタリングのように定式化する
やっていること • アイテムの特徴量と、ユーザごとのアイテム 間類似度計算行列を、教師データから学習 する – 教師データはユーザが何と何を同一クラスタとし て、何と何を同一クラスタとしなかったか – アイテムの特徴量はD次元で共通化。
– 類似度計算行列をユーザごとに設計することで ユーザごとにクラスタリングの基準を変える
教師データ • 対象 – M人のユーザ (u1 ~ uM)
• 各ユーザがCm個のクラスタを持つ – N個のアイテム • クラスタ – y = {ym} (1): 各ユーザごとのクラスタ集合 • ym = {Ym^1,…, Ym^Cm} (2): ユーザmのクラスタ集合 • Ym^i: ユーザmのクラスタiのアイテム集合 • 表現方法 – y_{m,i,j} • ユーザmにおいてアイテムi, jが同じクラスタ=> 1 • アイテムi, jが同じクラスタにない=> -‐1
定式化 • F(m, i, Ym^c) = mean{F(m, i, j) :
j∈Ym^c} (3) – F: 類似度計算関数 – アイテムiとクラスタcの類似度はそのクラスタに属 するアイテムとの類似度の平均 • c_mi = argmax F(m, I, Ym^c) (4) – 類似度が最も大きいものを所属クラスタとする • p(i|m, ym) – c_mi if F(m, I, Ym^{c_mi}) > 0 – 新しいクラスタ or クラスタに属しない if otherwise
学習 X: 各アイテムの特徴ベクトル。D次元 Um: ユーザmの類似度計算用行列. D*D b: パラメータ 具体的な最適化式は論文のAppendixを参照
求めたいもの 最適化するもの 正規化項 誤差項
実験 • 250のパリの観光地を218人のユーザにクラ スタリングをさせた – 1ユーザあたり4.5個のクラスタができた – 18.7個のアイテムが1クラスタにはある •
125ユーザでパラメータ調整, 50ユーザでバリ デーション, 43ユーザで評価
実験 • Hold 50% – 50%のアイテムをクラスタ済みのものとして残りの50%を 予測 –
目的: 一般的な精度検証 • Hold 25% per Cluster – 25%のアイテムを各クラスタから除いてモデルをつくって 評価 – 目的: 各クラスタのデータを欠損させた時の検証 • Hold One Cluster – 一つのクラスタを取り除いて評価する – 目的: クラスタの情報がない中で他のユーザの情報から 再現できるかの検証
比較手法 • Feature-‐based Model – zは各item固有のfeature, Vはfeatureの次元数分 ある。Vとbを学習する •
Transeformed Feature-‐based Model – VはD次元, Sにより次元圧縮をする • Augmented LCC Model
Features • Feature1 – 建物のWikipediaの記事から獲得したTF-‐IDFスコ ア • Feature2
– クラウドソーシングでつけたタグ – 39種から付けさせた
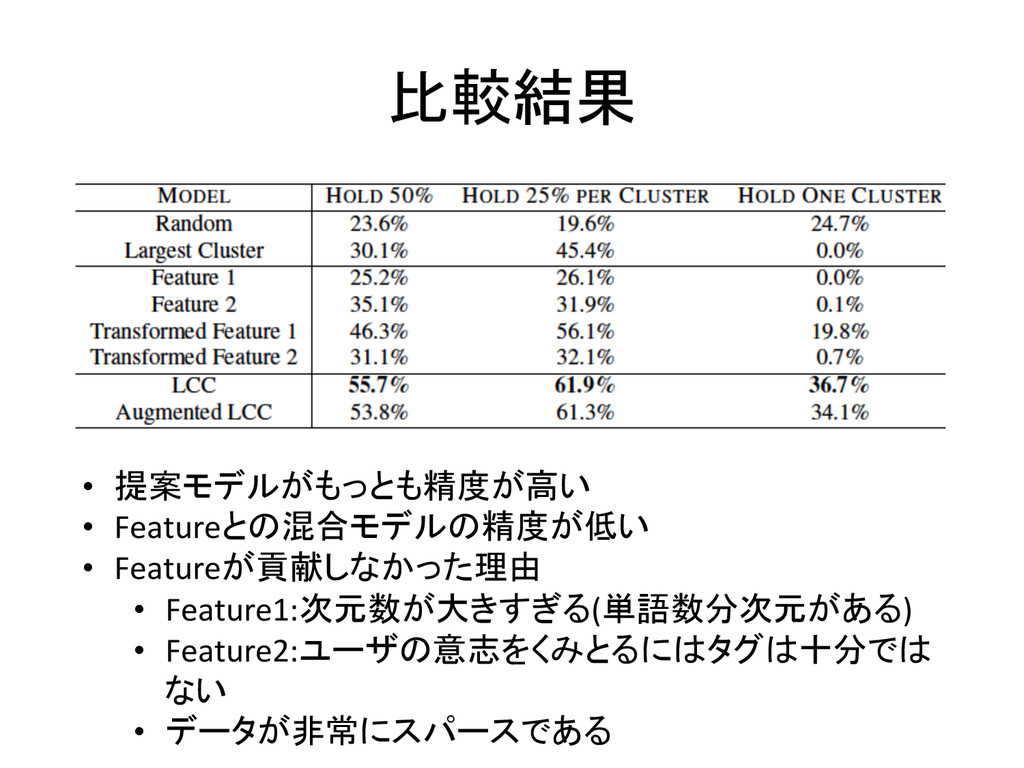
比較結果 • 提案モデルがもっとも精度が高い • Featureとの混合モデルの精度が低い • Featureが貢献しなかった理由
• Feature1:次元数が大きすぎる(単語数分次元がある) • Feature2:ユーザの意志をくみとるにはタグは十分では ない • データが非常にスパースである
パラメータの学習 • 目標としている精度に対してチューニングすると、その 精度に最適化される • そのためタスクに応じてパラメータチューニングの方法 は変えるべき
逐次的に学習させる
まとめ • ユーザごとのクラスタリングを他のユーザの情報と組みあ わせて潜在変数を学習することで最適化することができて いる – 未知のクラスタを推定できるのは非常に興味深い •
ただ協調フィルタリングと同等の課題は抱えていると考え られる – 新規アイテムや新規ユーザには活用できない、各アイテムに 十分な評価データがないといけないなど協調フィルタリングと 同じような課題はある – コンテンツ情報とのハイブリッドはシンプルな方法では無理。工 夫が必要。 • アイテム数やクラスタ数が大きくなるととてもつらくなりそう
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}