add add add add add add mul mul mul mul mul mul mul mul setp setp setp setp setp setp setp setp bra L1 bra L1 bra L1 bra L1 bra L1 bra L1 bra L1 bra L1 sub sub sub bra L2 bra L2 bra L2 add add add add add mov mov mov mov mov mov mov mov thread time L1 L2 9
{kind=link}
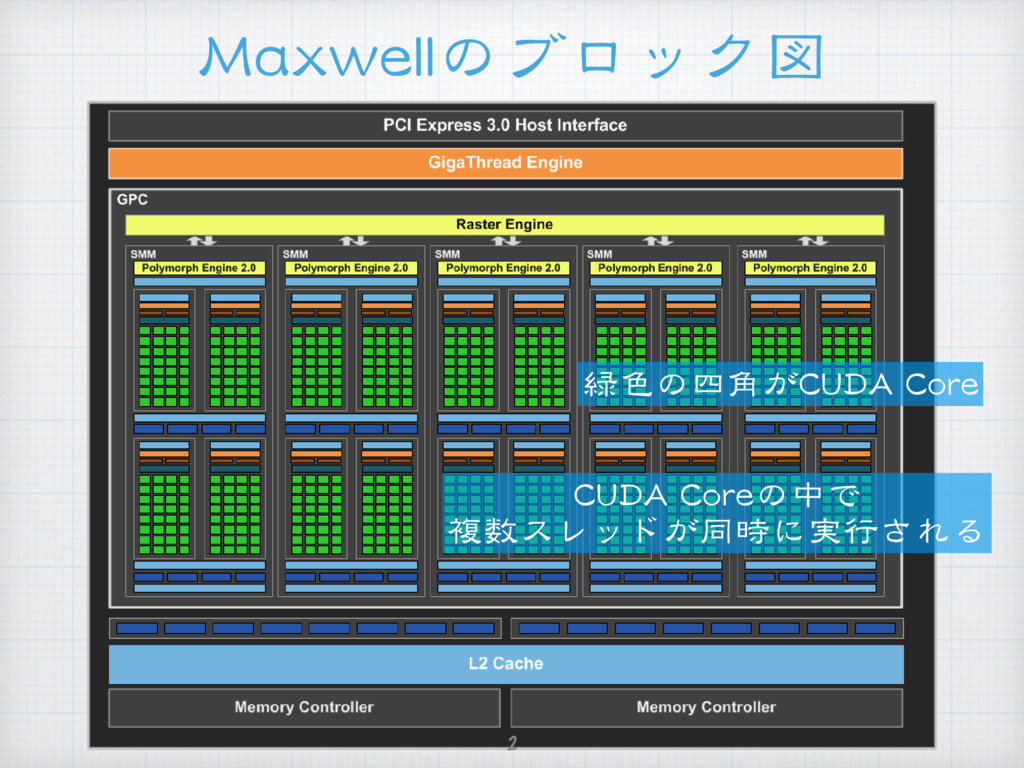{kind=link}
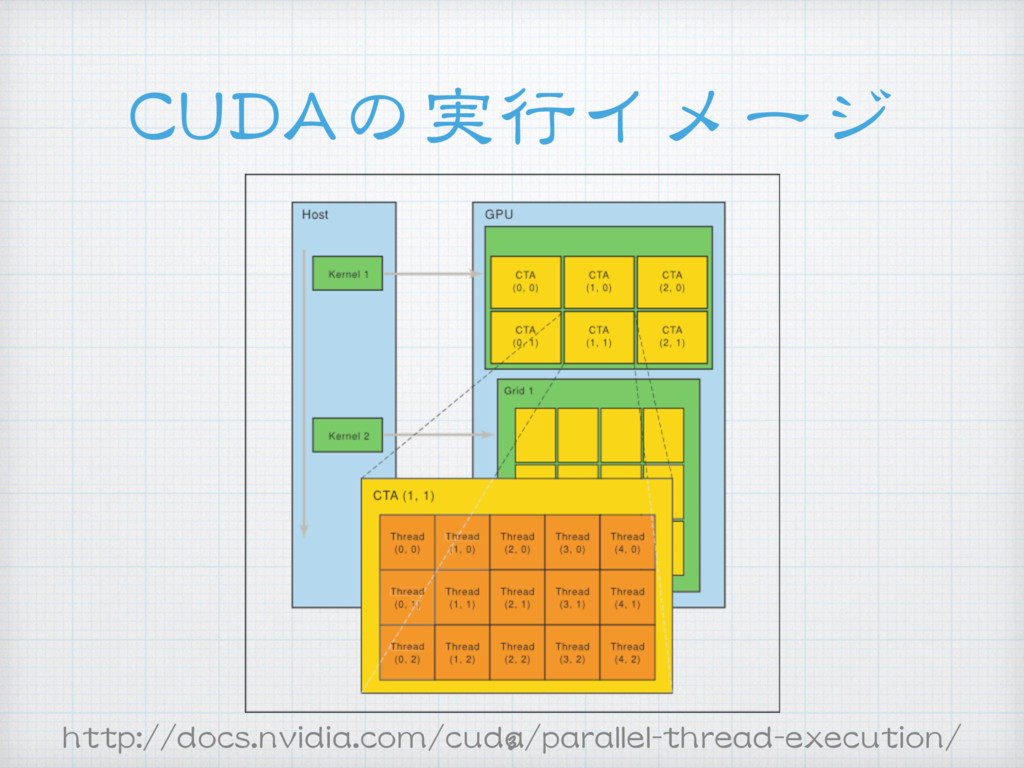{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
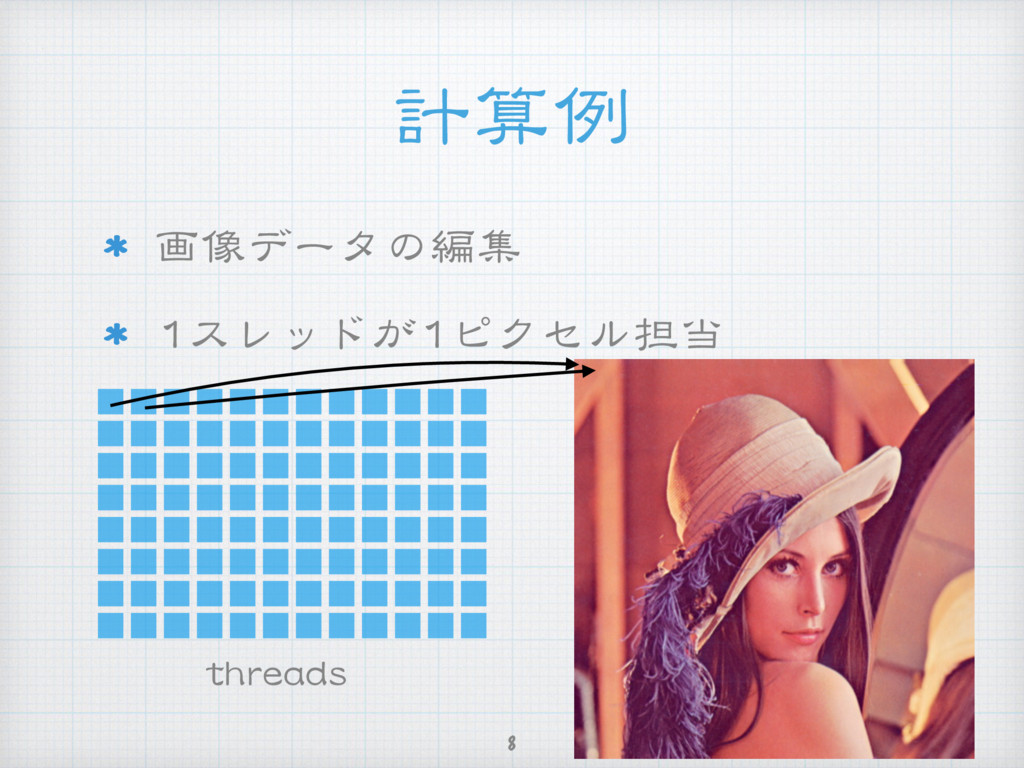{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
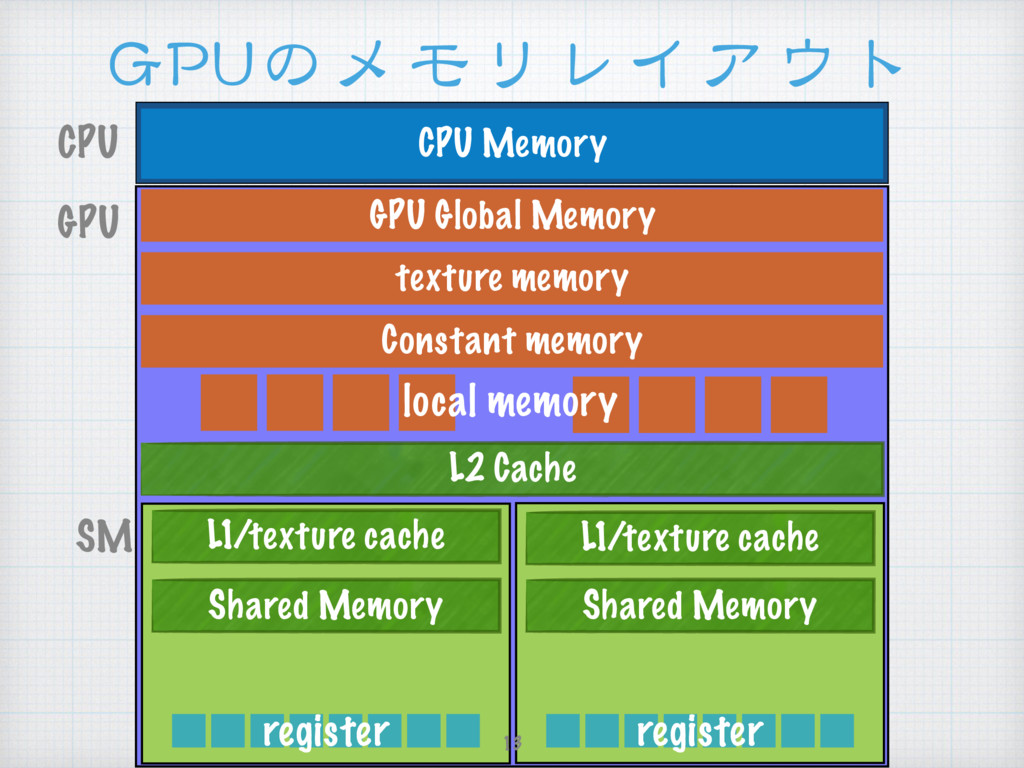{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![コンスタントメモリへの データ転送 __constant__ int foo; __constant__ int bar[100]; int func()](https://files.speakerdeck.com/presentations/9461939df11b4125bfadcdaba7a733c6/slide_17.jpg){kind=link}
{kind=link}
{kind=link}