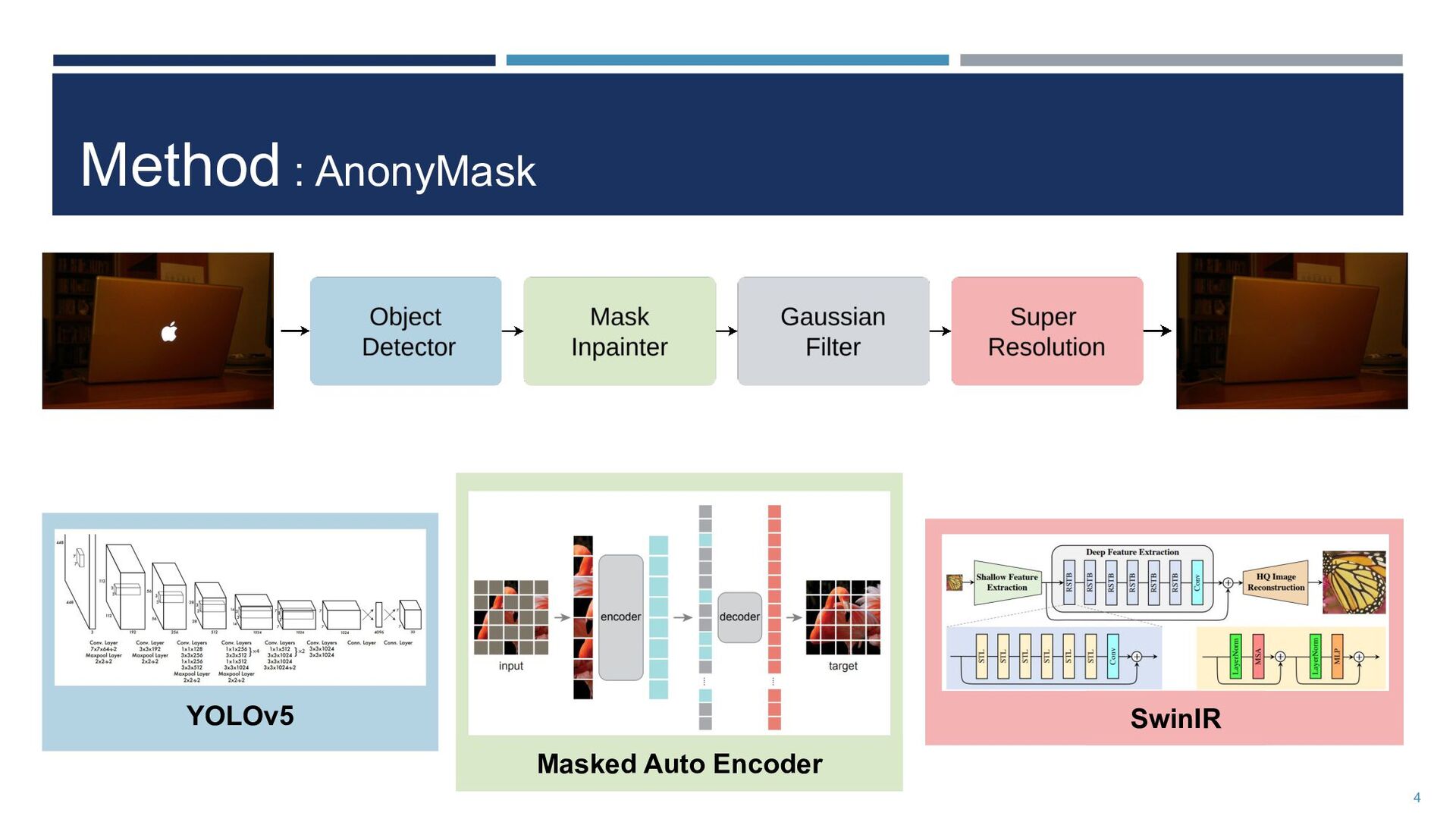
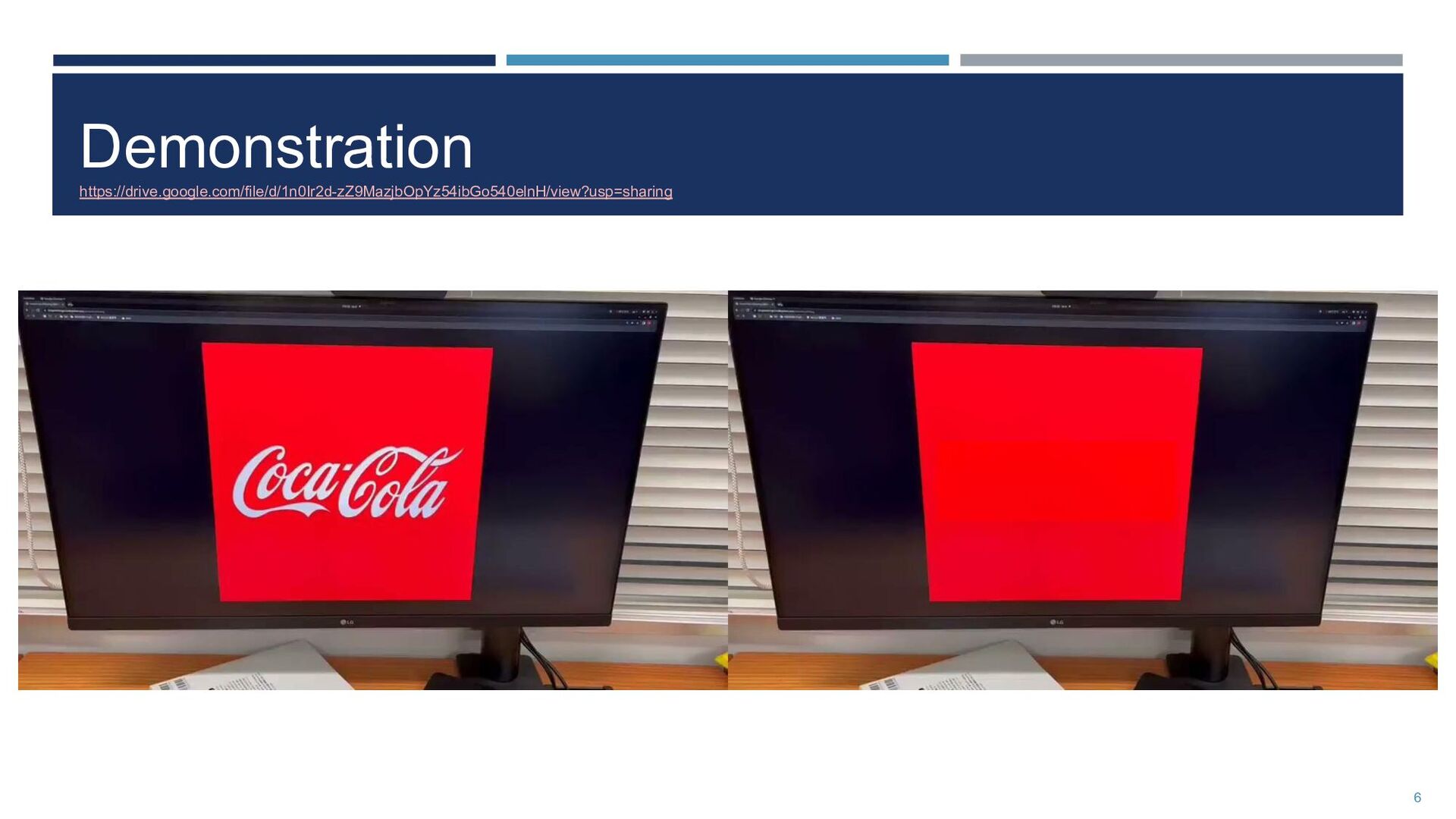
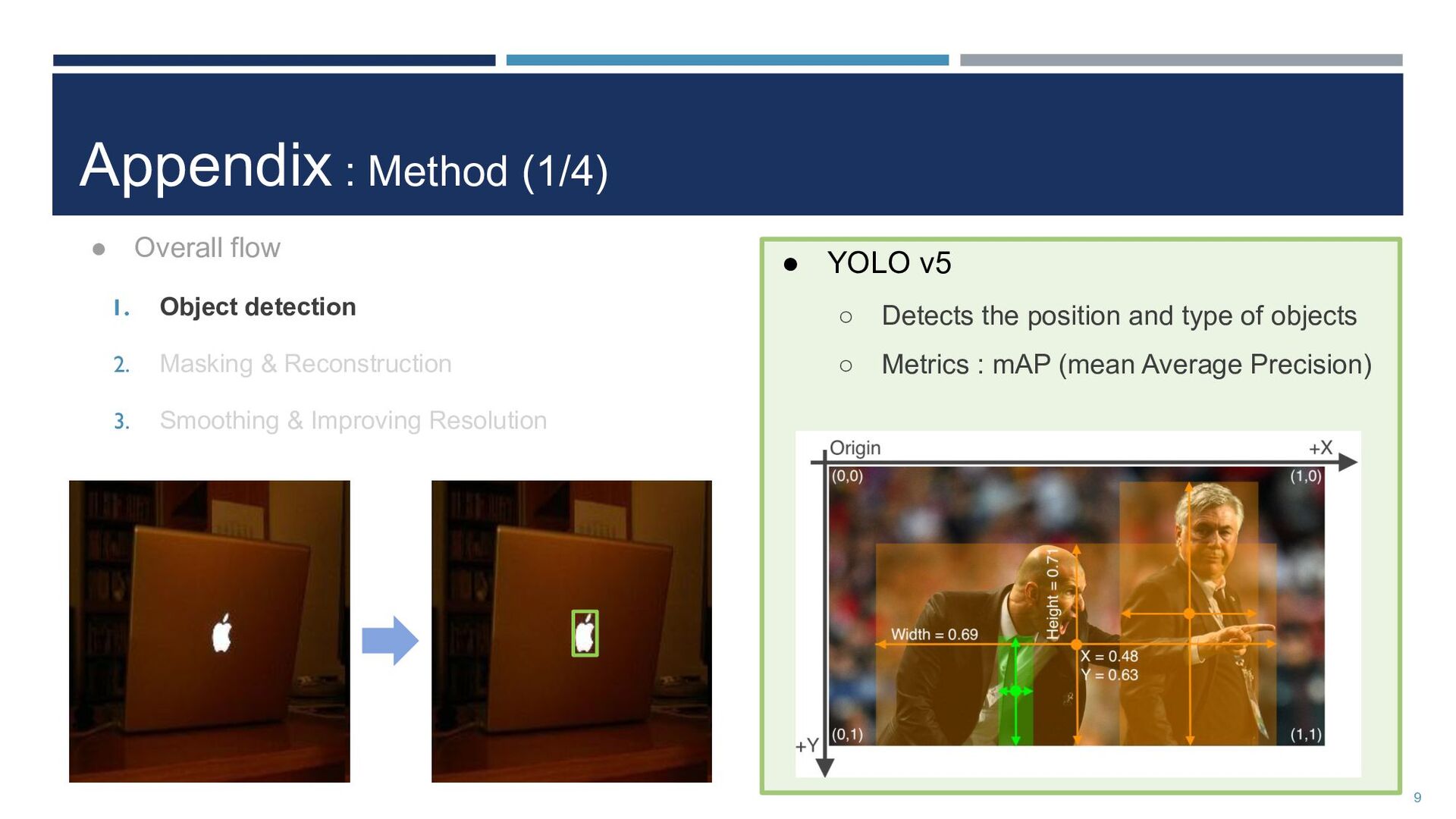
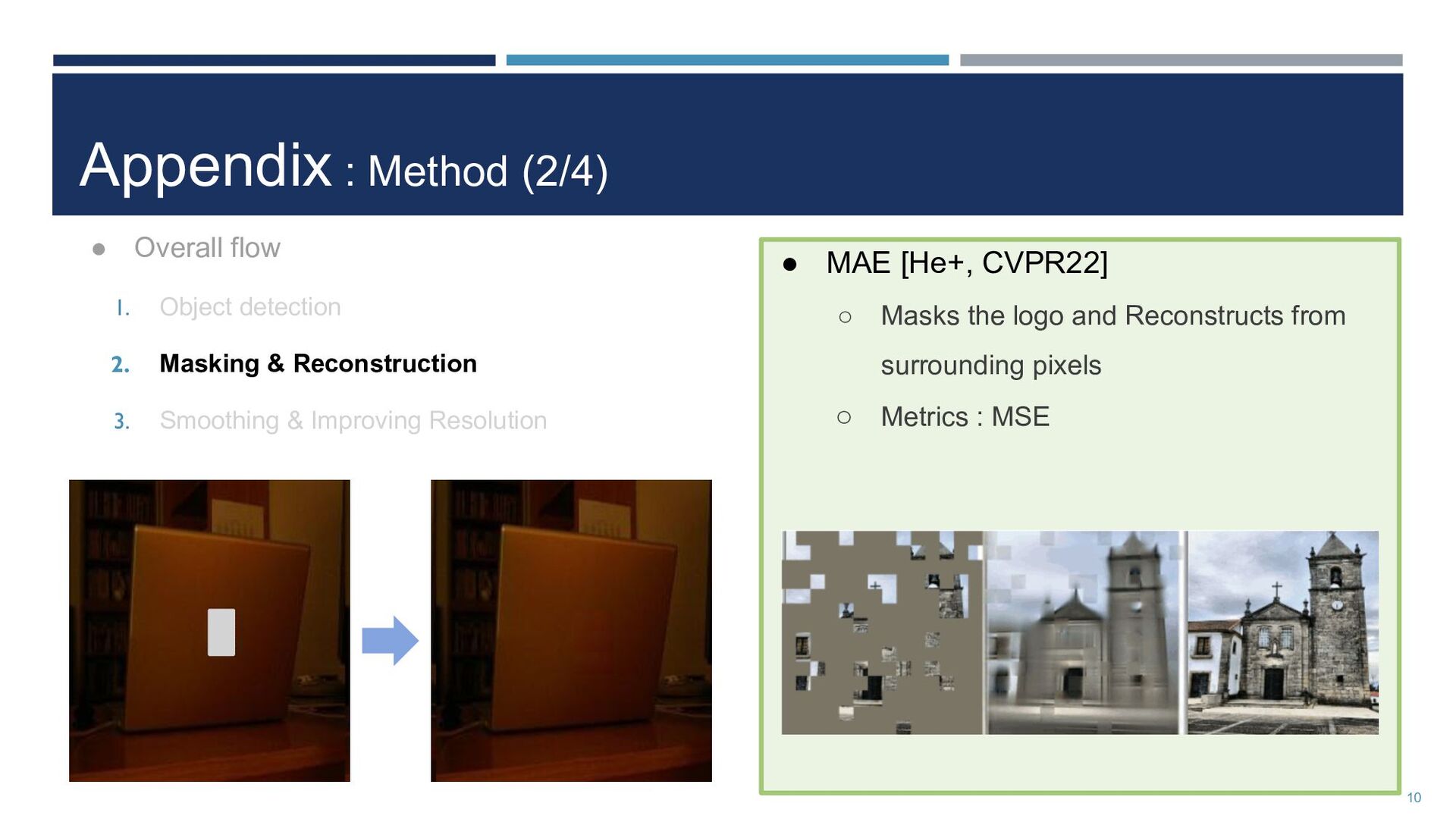
cost to hide the logos ◦ Existing approaches result in unnatural images! • Our product : AnonyMask ◦ Detects the logo by the object detection model ◦ Masks it out and repaints masked region naturally 2
logo classes • Object-level Annotations Our split : https://hangsu0730.github.io/qmul-openlogo/ #Examples Training set 18752 Validation set 4165 Test set 4166
“Masked autoencoders are scalable vision learners,” CVPR, pp.16000–16009, 2022. 2. J. Liang, J. Cao, G. Sun, et al., “Swinir: Image restoration using swin transformer,” CVPR, pp.1833–1844, 2021. 3. G. Jocher, A. Chaurasia, A. Stoken, et al., “ultralytics/yolov5: v6.1 - TensorRT, TensorFlow Edge TPU and OpenVINO Export and Inference,” 2022. https://doi.org/10.5281/zenodo.6222936 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Quantitative Result Recall Precision F-Score [email protected] [email protected]:0.95 val. 0.656 0.789](https://files.speakerdeck.com/presentations/802614d63d9d446dabefaff9d2ee6e6b/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
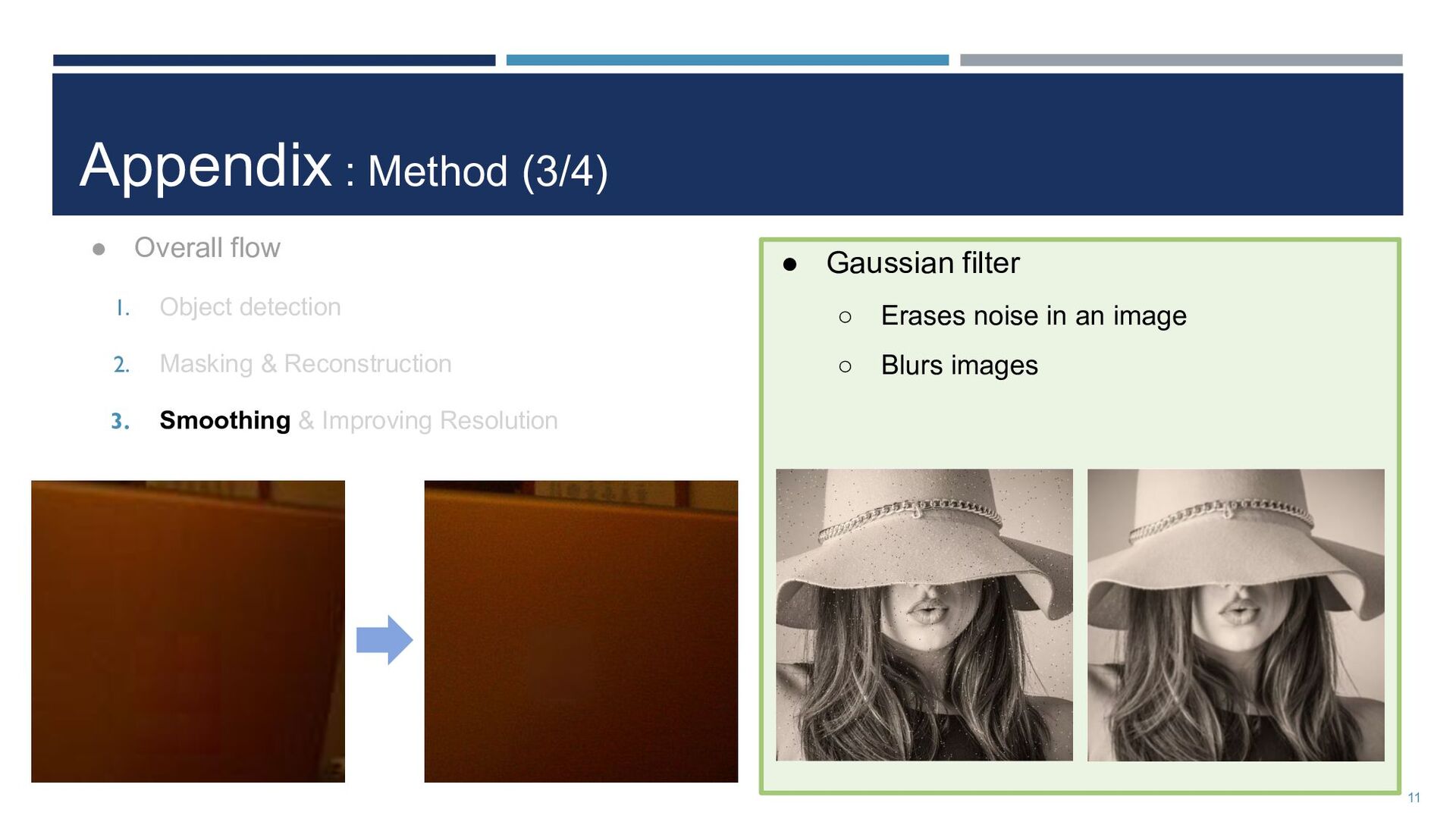{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
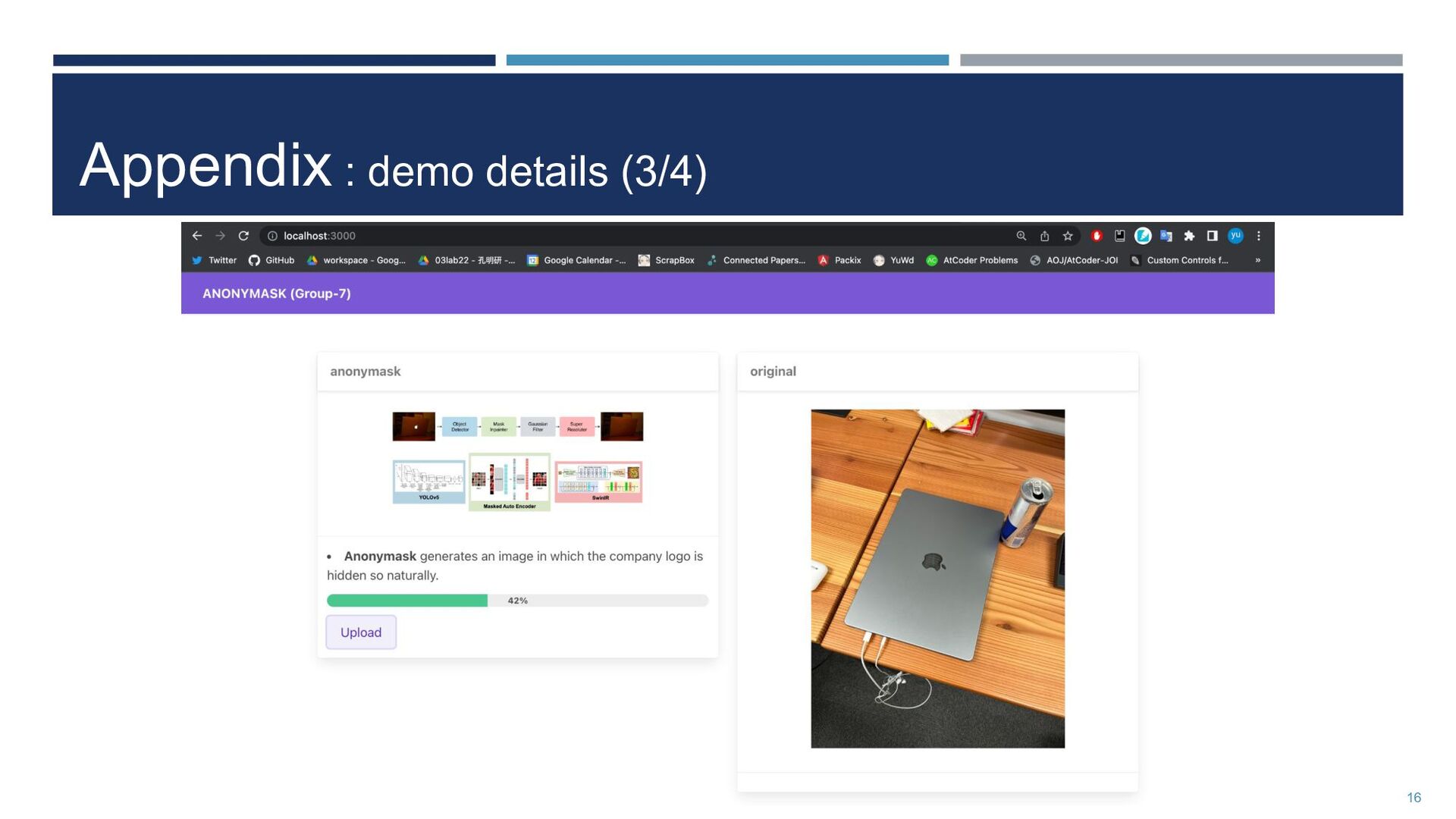{kind=link}
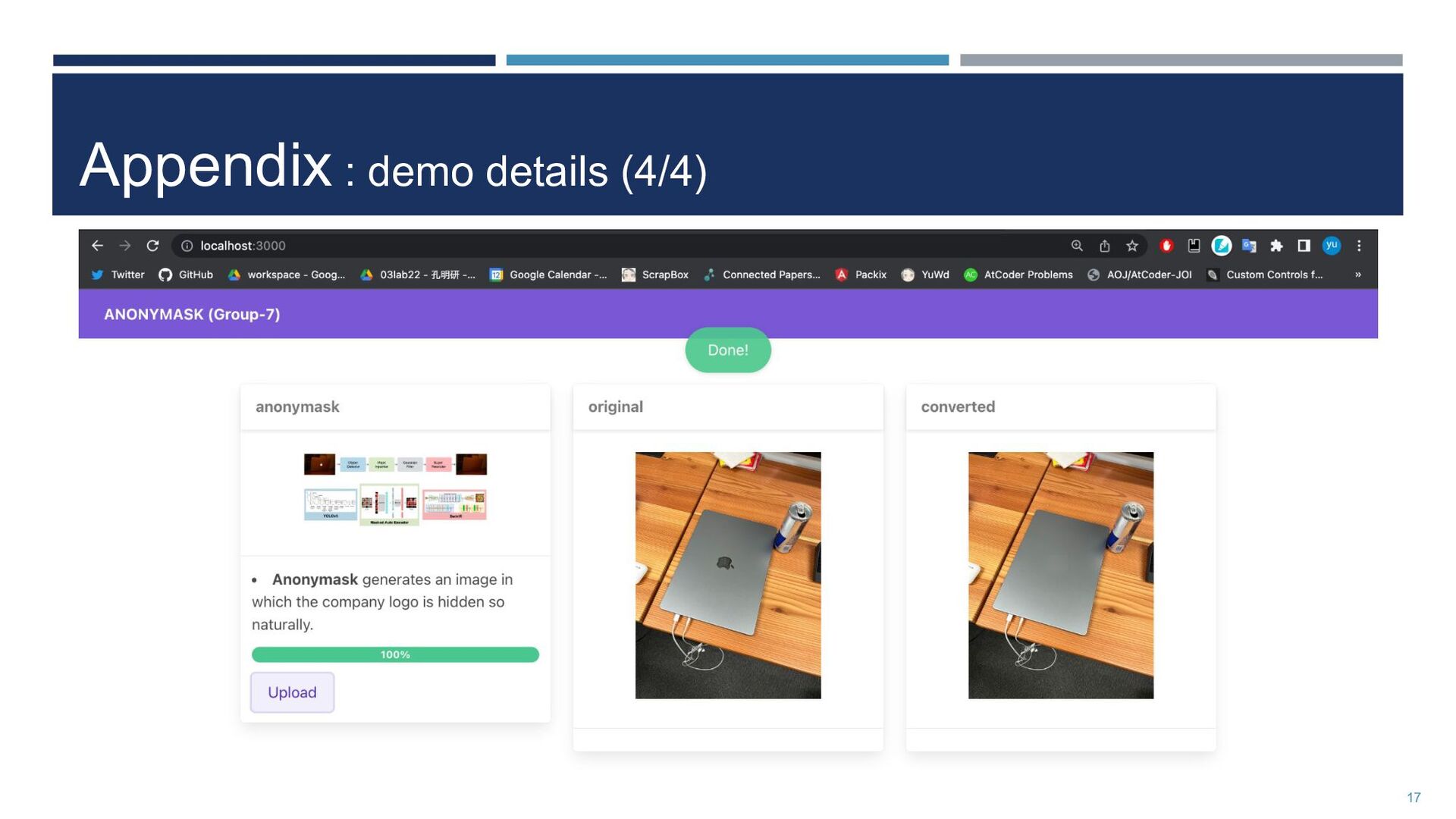{kind=link}
{kind=link}